
데이터베이스 인덱스(Database Index)는 데이터베이스 내의 테이블에 대한 성능 향상을 위해 사용되는 데이터 구조이다. 인덱스는 테이블의 특정 열(또는 열의 조합)에 대한 검색 속도를 향상시키기 위해 사용된다.
정도만 알고는 application level에서 index를 제대로 활용하기 힘들다. 무엇이든 그렇지만 index를 잘 활용하기 위해서는 index의 원리를 이해해야 한다. 기본적인 원리를 정리해보자.
index scan vs full scan
index가 아닌 column으로 select 쿼리를 날리면 무지성으로 Disk에 있는 해당 테이블을 뒤진다. 이것을 full scan이라고 한다. 반면 index가 설정된 column이라면 Tree로 된 index table을 통해 데이터가 있는 위치를 알아내서 찾아가게 된다. Tree로 B tree 계열의 자료구조가 많이 사용되지만 DB마다 혹은 데이터의 특성마다 다른 자료구조를 사용한다. 이에 대한 자세한 것은 다음에 다뤄보도록 하자. 아무튼 Tree 구조를 통해 위치를 알아내기 때문에 일반적으로 더 빠르다.
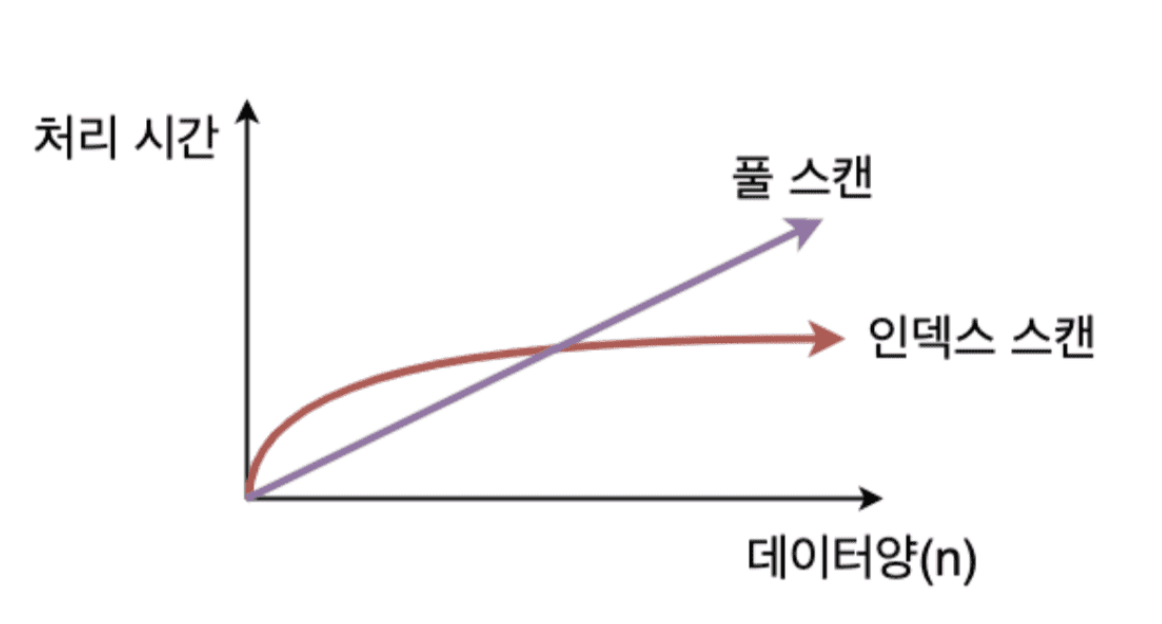
(참고) 아래 그림처럼 항상 더 빠른 것은 아니다. 데이터가 많지 않다면 Tree 자료구조에서 얻는 시간적인 효율보다 (tree를 가져오고 => tree를 뒤지고) 이 overhead가 커질 수도 있다.
Clustered index vs Non clustered index
index는 clustered index와 non clustered index로 나누어진다.
clustered index는 한 테이블 당 하나만 존재할 수 있다. 대부분의 db에서 default로 primary key로 설정되어 있다. 물론 use case에 따라 변경할 수 있다. table마다 하나밖에 존재할 수 없는 이유는 cluster key 기준으로 실제로(물리적으로) 데이터가 정렬되어 있기 때문이다.
반면 non clustered index는 한 테이블에도 여러 개를 지정할 수 있다. 하지만 clustered index보다는 성능 향상을 더 끌어내지 못한다.
왜 그런지 이해해보자
Clustered index
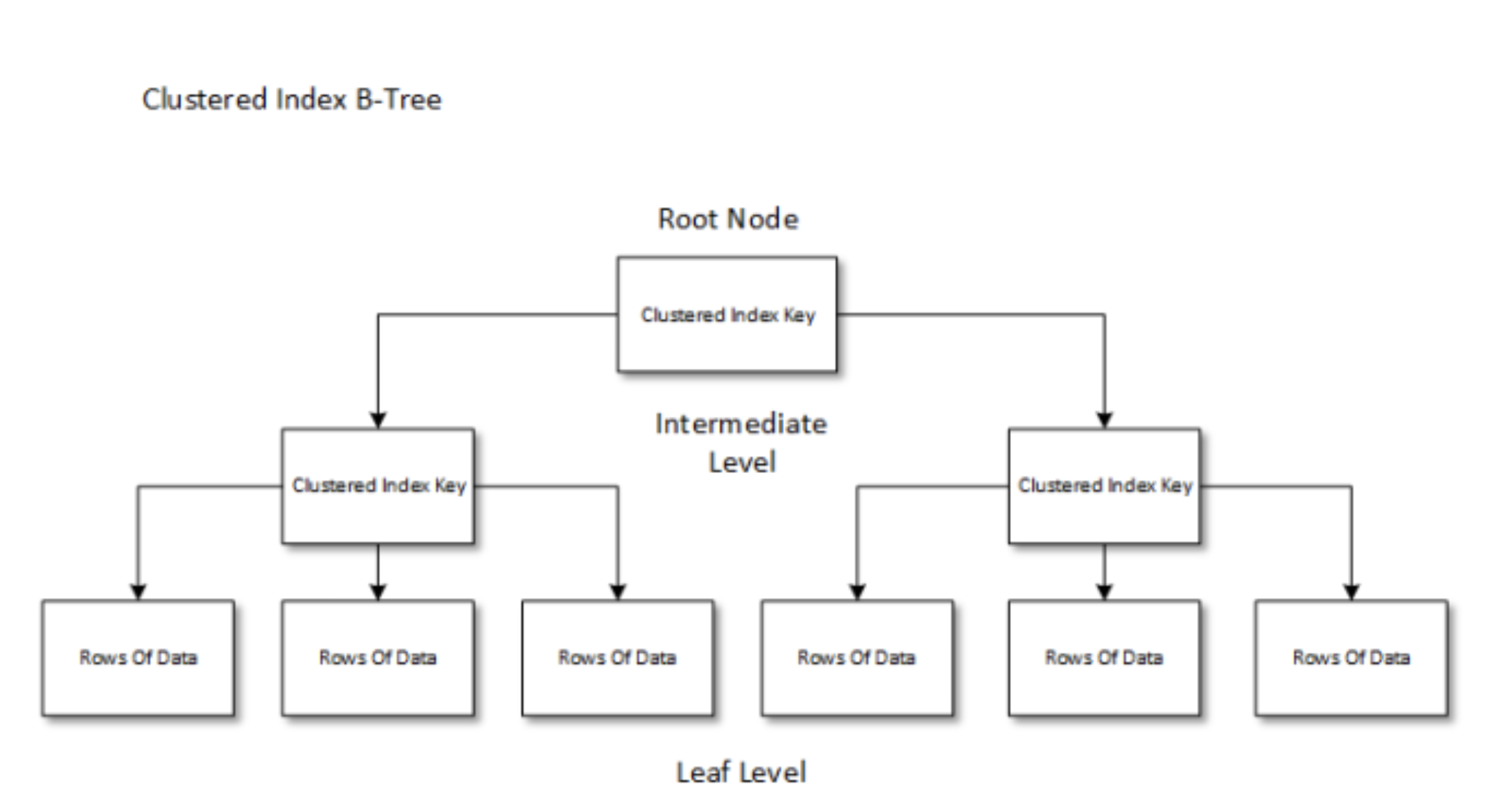
- Clustered index column을 key로 하는 table(tree)이 있다. 가장 끝에 있는 Leaf node는 실제 데이터가 있는 page이다. 이 데이터 page에는 data가 index column 기준으로 정렬되어 있다. 이것이 non clustered index와의 가장 큰 차이점이다.
Non clustered index
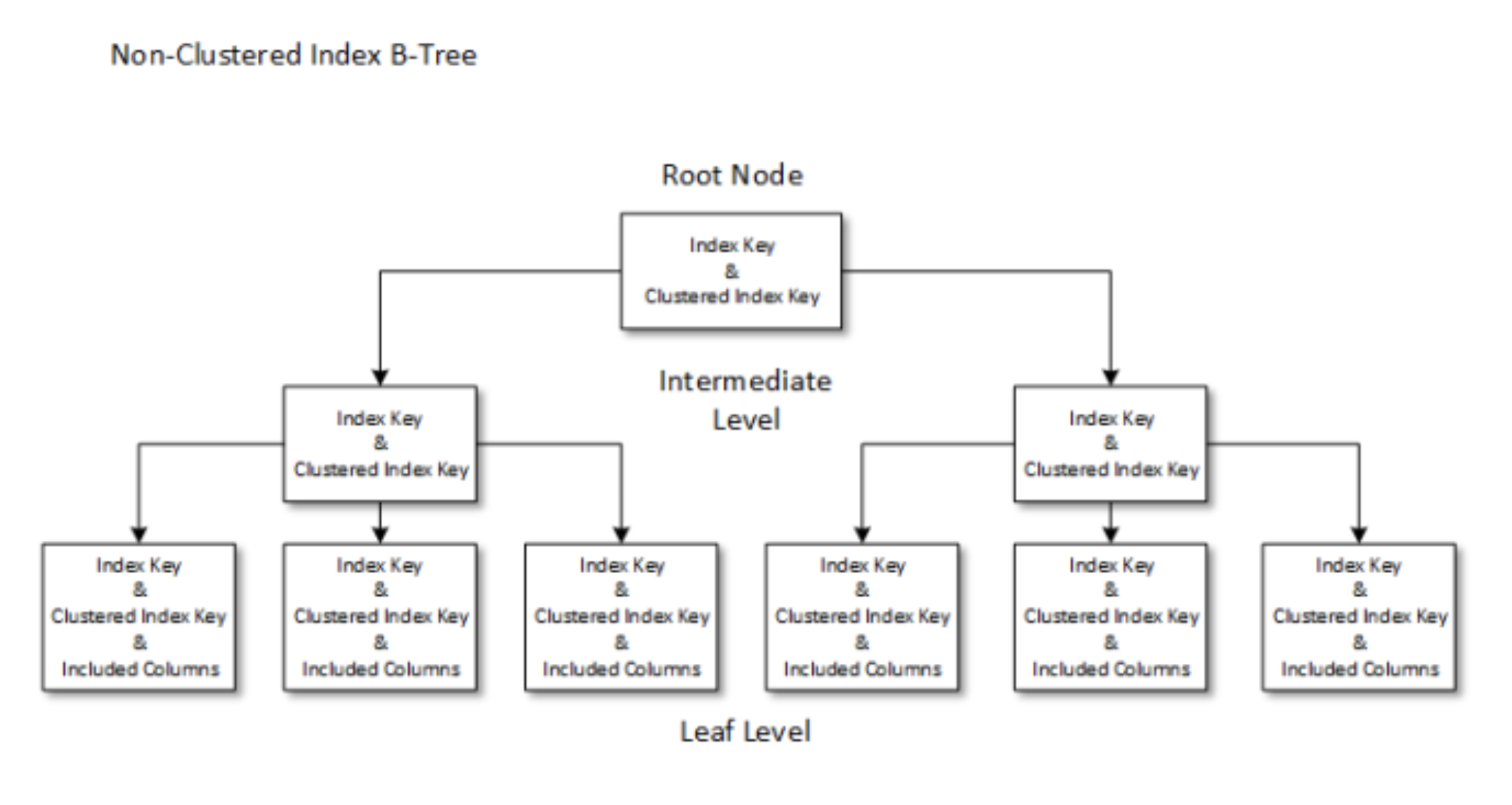
- Clustered index와는 다르게 각 데이터는 clustered index key를 갖고 있다. non clustered index table을 통해 clustered index를 찾는 것이다. clustered index를 통해 cluster index를 찾고 clustered index table을 뒤져 데이터를 찾는 것이다. 어쨌든 clustered index를 통해 찾기 떄문에 당연히 clustered index보다 느리다.
- 그림을 보면 included columns라는 것도 있는데 이는 설정하기에 따라 clustered index table을 뒤져 찾는 과정을 생략하기 위해 특정 컬럼들을 non clustered table에 함께 저장하는 것이다.
참고
https://matthewmcgiffen.com/2017/06/12/what-is-an-index/
https://logicalread.com/dont-drink-kool-aid/
