본 내용은 기업인턴과정에서 발생했던 내용을 정리한 내용입니다.
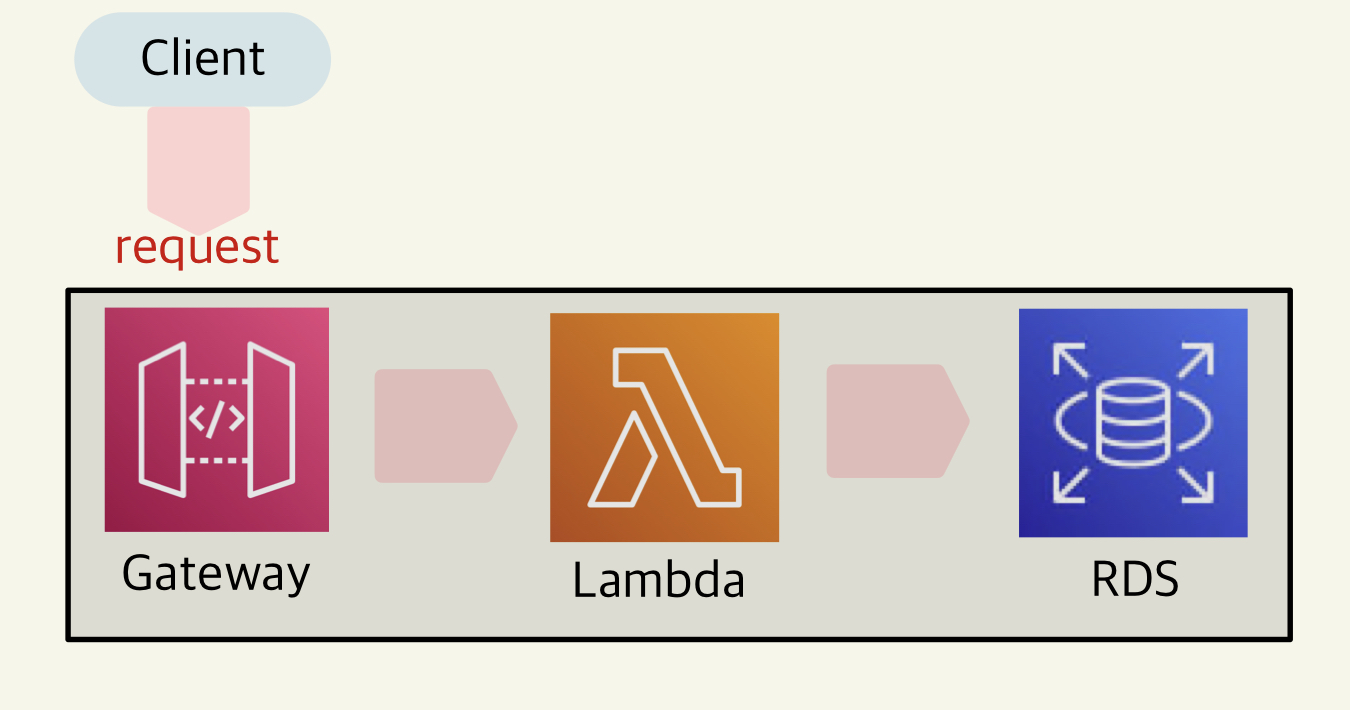
1. 과제 내용
- AWS_lambda와 AWS_RDS, AWS_Gateway 활용해라
- Thread를 활용해서 1만개의 request를 발생시켜 AWS_lambda를 통해 AWS_RDS에 저장하라
- AWS_RDS는 postgresQL을 사용하라
- 1만개의 request를 발생시키면 1만개 전체다 RDS에 저장되지 않을것인데 그것을 확인해봐라
2. 용어 정리
1. AWS_API gateway
- 백엔드 HTTP 엔드포인트, AWS Lambda 함수 또는 기타 AWS 서비스를 노출하기 위한 RESTful애플리케이션 프로그래밍 인터페이스(API)의 생성, 배포 및 관리.
- AWS Lambda 함수 또는 기타 AWS 서비스를 노출하기 위한 WebSocket API의 생성, 배포 및 관리.
- 프런트 엔드 HTTP 및 WebSocket 엔드포인트를 통해 노출된 API 메서드 호출
참고 : AWS_API gateway 공식문서
2. AWS_Lambda
- Amazon Web Services에서 제공하는 서비리스 컴퓨팅 서비스
- 서버리스 컴퓨팅은 애플리케이션을 실행하기 위한 별도의 서버 셋업 없이 곧바로 코드를 실행해주는 서비스를 의미하며, 고정 비용 없이 사용 시간에 대해서만 비용이 발생
- Linux 기반의 가상화 컨테이너기술중 Docker는 application기준으로 컨테이너를 만든다면, AWS_lambda는 가장 최소기준, 바로 메소드 기준으로 컨테이너를 만들어 제공한다.
- AWS_lambda는 데이터의 양에 따라 쓰레드를 늘렸다가 줄였다가를 자유롭게 하는데 무료는 50개가 최대
- AWS_lambda는 Python, Ruby, Java, Node.js, C#, PowerShell, Go 총 7가지 언어를 지원하고 있다.
참고 : https://www.44bits.io/ko/keyword/aws-lambda
3. AWS_RDS
- Relational Database Service
- AWS 클라우드에서 관계형 데이터베이스를 더 쉽게 설치, 운영 및 확장할 수 있는 웹 서비스
참고 : AWS_RDS 공식문서
3. 목표1 : lambda 와 RDS 연결
- lambda와 RDS 연결을 하기위해 연결해주는 라이브러리를 lambda에 올려야한다.
1) lambda functions 생성 : arm64(아키텍처) / python 3.9(런타임)으로 생성
2) 우리는 postgresQL을 사용하기때문에 관련 라이브러리인 psycopg2 라이브러리를 사용
3) lambda에 외부 라이브러리를 사용하기 위한 방법으로 두가지가 존재
- lambda 에 라이브러리를 직접 업로드하는 방식

-
layer를 이용하는 방식
- layer란? 기본적으로 AWS_lambda에서 제공하는 내장 모듈을 제외하고 외장모듈(라이브러리, 패키지)를 사용할때 쓴다.
- layer만드는 법
https://docs.aws.amazon.com/ko_kr/lambda/latest/dg/configuration-layers.html#configuration-layers-create
- layer란? 기본적으로 AWS_lambda에서 제공하는 내장 모듈을 제외하고 외장모듈(라이브러리, 패키지)를 사용할때 쓴다.
-
layer를 이용하는 방식으로 먼저 접근
1)
pip install psycopg2 -t .명령어로 pip install이후 zip파일로 만들어 layer에 올려서 적용⇒ import error
2) psycopg2 라이브러리말고 psycopg2-binary, aws_psycopg2 라이브러리가 존재
(a)의 방식과 동일하게 진행⇒ psycopg2-binary, aws_psycopg2 둘다실패
3) (1),(2) 방식을 lambda에 아키텍처를 바꿔가면서 시도
- lambda x86(아키텍처) / python 3.9(런타임) : 실패
- lambda x86(아키텍처) / python 3.8(런타임) : 실패
- lambda arm64(아키텍처) / python 3.8(런타임) : 실패
- lambda x86(아키텍처) / python 3.7(런타임) : 실패
- lambda arm64(아키텍처) / python 3.7(런타임) : 생성안됨
(python 3.7 이하의 버전은 지원x) - lambda x86(아키텍처) / python 3.6(런타임) : 실패
⇒ 결론 : psycopg2 라이브러리는 layer방식으로는 정상적으로 import가 안됨을 확인
-
라이브러리를 직접 업로드하는 방식으로 시도
1) c - (1), (2), (3)방식과 동일하지만 바로 직접업로드 하는방식 진행
⇒ import error
-
pip install의 다른접근
- m1 맥북에서 pip install 로 만든 zip파일이 문제가 될수 있다고 판단.
- 자료 검색도중 라이브러리를 zip파일로 만드는 과정도 lambda함수의 아키텍처나 런타임이 비슷한 환경에서 만들어야 된다는 정보 확인
- lambda x86(아키텍처) / python 3.9(런타임)를 사용할 lambda funstion으로 기준을 잡고 이 기준에 맞게 pip install 할 수 있는 방법 조사
pip3.9 install --platform=manylinux1_x86_64 --only-binary=:all: psycopg2-binary -t .명령어를 통해 pip install 진행- layer 업로드 방식으로 진행 ⇒ import error
- 직접 라이브러리 업로드 방식 ⇒ import 성공
- layer 업로드 방식으로 진행 ⇒ import error
-
psycopg2라이브러리와 AWS_lambda 에서의 결론
- RDS를 postgresQL로 사용하고, RDS와 연결하기

위해 필요한 라이브러리인 psycopg2는 layer방식으로는 진행이 안되며, arm64(apple M1)방식으로는 동작하지 않으며, 직접 라이브러리를 업로드 하는 방식으로 진행해야 가능하다.
4. 목표2 : lambda 함수 정의
-
RDS에 database와 table 생성
-
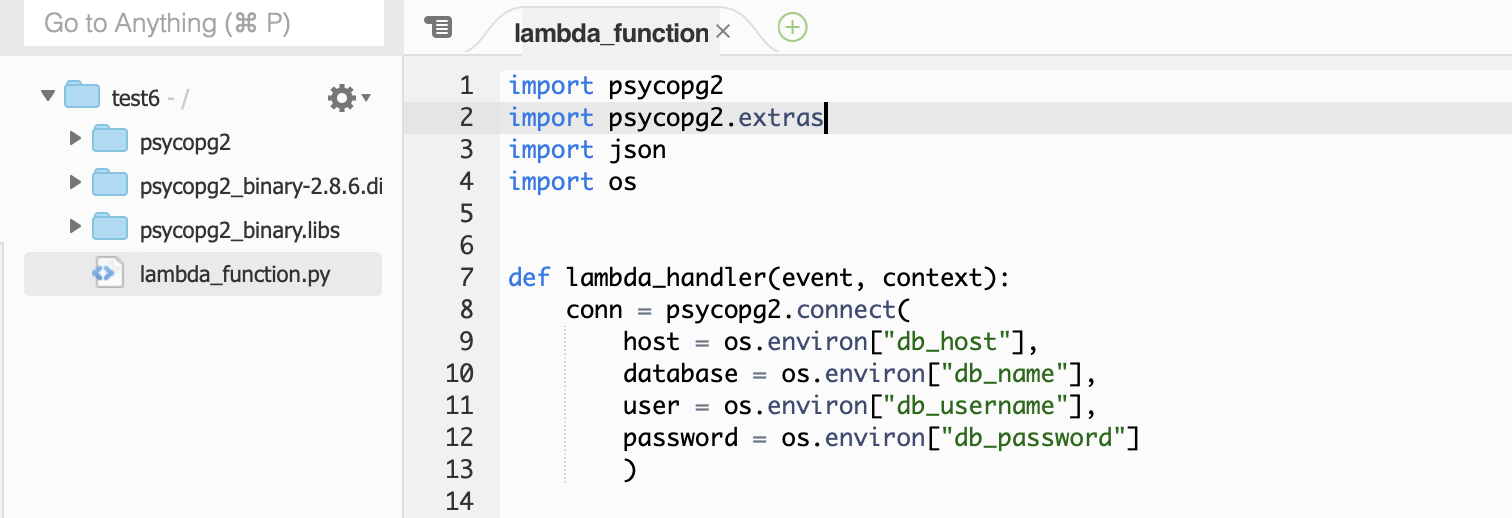
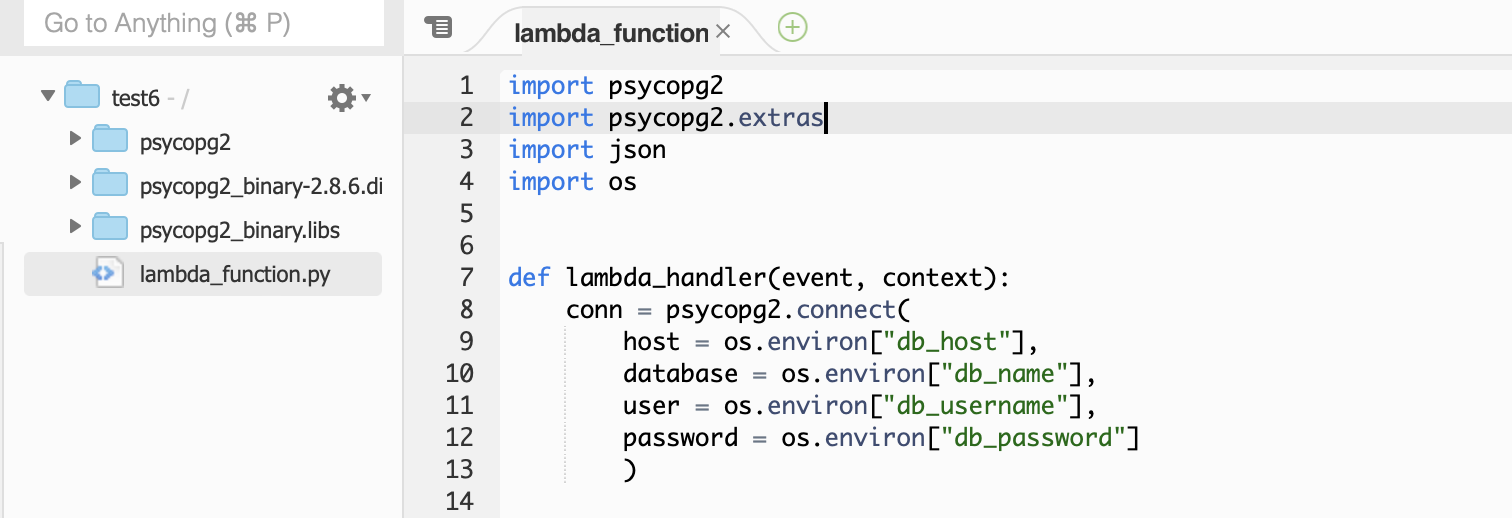
lambda에서 제공하는 환경변수 기능을 사용하여 RDS와 연결하는 코드 작성
conn = psycopg2.connect( host = os.environ["db_host"], database = os.environ["db_name"], user = os.environ["db_username"], password = os.environ["db_password"] )- 환경변수사용방법
- 환경변수는 구성 > 환경변수에 등록할 수 있으며, 암호화되서 보관된다.
- 환경변수는 위의 사진과 같이 os를 import해서 사용하며 ,
os.environ[”환경변수key값”]으로 사용가능 하다.
- 환경변수사용방법
-
cursor메소드 활용하여 psycopg2라이브러리의 execute_batch를 활용하여 한번의 쿼리호출로 여러개의 데이터를 insort하는 방식으로 정의
cur = conn.cursor() query = "INSERT INTO name (name ) VALUES (%s);" vals = [] for i in range(len(event['Records'])): a = json.loads(event['Records'][i]['body']) b = a["name"] c = (b,) vals.append(c) psycopg2.extras.execute_batch(cur,query, vals) conn.commit() cur.close() conn.close()- python의 cursor, execute문은 SQLite로 설명하지만 공식문서에 자세히 설명되어있다.
https://docs.python.org/ko/3/library/sqlite3.html?highlight=cursor#sqlite3.Connection.cursor
- python의 cursor, execute문은 SQLite로 설명하지만 공식문서에 자세히 설명되어있다.
5. 목표3 : AWS_Gateway 설정
- REST API방식으로 생성

- 엔드포인트 리소스 생성 후 post메소드 생성
- 배포하게되면 gateway로 접근가능한 엔드포인트 url 생성
5. 목표4 : Thread 를 활용한 1만개의 request보내기
-
부하테스트 관련 앱 조사
java기반의 jmeter, python기반의 Locust
-
Locust 사용
장점 : 간단하게 pip install로 사용가능
단점 : 1만개를 request하여 그중 몇개가 정상적으로 RDS에 저장되고 저장안되는지 봐야하지만 thread는 정상적으로 생성되지만 request의 제한이 없어 사용 하기 어렵다고 판단
-
python 내장모듈중 ThreadPoolExecutor 모듈을 활용하여 직접 구현
import requests from concurrent.futures import ThreadPoolExecutor import time start = time.time() def post_url(arg): return requests.post(url, json=data, headers=headers) data = { "name" : "name1" } url = "getway endpoint" headers = {'Content-Type': 'application/json'} list_of_urls = [(url, data)]*1000 # 총 데이터의 갯수 설정 with ThreadPoolExecutor(max_workers=1000) as pool: # max_work : 한번에 최대로 만들어지는 쓰레드 갯수 설정 # 데이터 갯수 1000개, 스레드 최대갯수 50개일때, 50개씩 200번 request보낸다는 의미 response_list = list(pool.map(post_url,list_of_urls)) end = time.time() # 여기서부터 는 몇개가 response 200인지 response 500인지 구분하여 갯수 파악하기위한 코드 a = [] b = [] for response in response_list: if response.status_code == 200: a.append(response) else: b.append(response) result = len(a) result1 = len(b) print("성공 :", result, "개", "실패 :", result1, "개") print(f"{end - start:.5f} 초") # request가 보내지는데 걸리는 시간 측정참고 : codethief 블로그
⇒ 결과 : 대략 10~15% 데이터가 DB로 저장되는 것을 확인
2차 과제 완료
- 2차과제는 처음 경험해보는 AWS_lambda와 AWS_Gateway의 개념을 직접 구현하면서 익히는 좋은 과제 였으며, postgresQL이 쉽게 layer에 업로드하는 방식으로 해서 됬다면 격지못할 문제들을 하나씩 가설을 세우고 가설을 하나씩 지워가는 방식으로 접근해서 결국 해결하면서 그냥 쉽게되었다면 몰랐을 부분들을 알게된 좋은 과제였다.
