Outstagram
1.[Outstagram] AOP를 통해 횡단 관심사(cross-cutting concern) 걷어내기
프로젝트 전반에서 현재 로그인된 유저의 정보를 가져오는 일이 많다'나의 게시물', '게시물 작성' 등 많은 로직에서 현재 세션에 있는 유저 정보를 필요로 함필요로 할 때마다 세션에서 유저 정보 가져오는 것은 중복된 코드가 너무 많아짐 -> 한 곳에서 처리하자!!컨트롤러
2.[Outstagram] 이미지 처리 추상화

아직 로컬에서 프로젝트를 진행하고 있기에 이미지 저장도 로컬 디렉토리에 저장하기로 함하지만 이미지 처리는 추후에 로컬이 아닌 S3에 저장되도록 수정할 수 있으므로 이미지 처리를 추상화할 필요가 있다고 느낌그래서 이미지 서비스 계층을 인터페이스화 해서 추후에 AWS S3
3.[Outstagram] DB 쿼리 최적화

'나의 게시물' 조회 기능을 구현할 때, 내가 작성한 게시물과 각 게시물의 대표 이미지 1개씩 내려주도록 개발하고 싶음우선 내가 작성한 모든 게시물을 가져오고각 게시물을 순회하면서 대표 이미지 1개씩 가져옴image게시물 목록 조회 쿼리 1번(게시물 3개), 각 게시물
4.[Outstagram] 좋아요 동시성 문제 해결
동시에 여러 thread들이 좋아요 누르거나, 좋아요 취소했을 때, 해당 게시물의 좋아요 개수가 정확히 수정되는 것이 보장되나??현재는 그냥 @Transactional 애노테이션만 있다 → 이게 동시성 보장을 해주는건 아님현재 상태는 동시에 여러 thread가 좋아요를
5.[Outstagram] 무한 스크롤 구현하려다 Snowflake ID 도입한 이야기
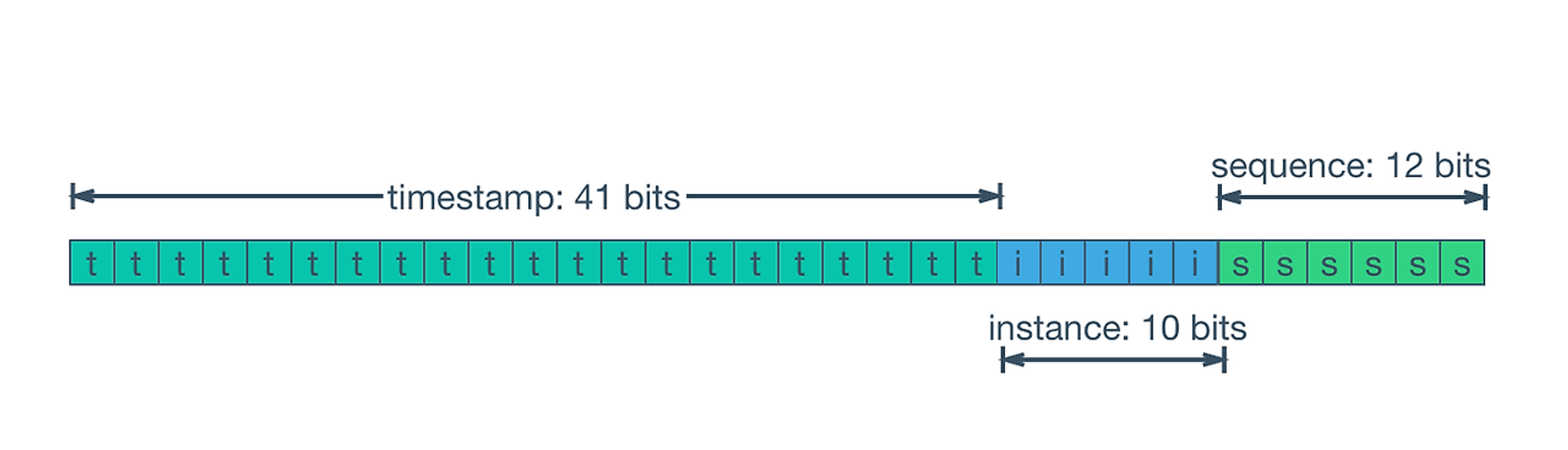
✅ 무한 스크롤 도입 무한 스크롤이란? 아래로 스크롤 하다가 컨텐츠의 마지막 요소를 볼 즈음 다음 컨텐츠가 있으면 불러오는 방식 ❓ 무한 스크롤 방식 도입 이유 페이스북, 인스타 피드 처럼 아래로 계속 스크롤 하면서 보는 기능을 구현하고 싶어서 도입 ✅ 커서 기반
6.[Outstagram] kafka를 활용한 피드 push model 구현 과정

kafka 메시지 큐 도입...
7.[Outstagram] 왜 같은 클래스에서 @Cacheable 달린 메서드 호출하면 씹힐까...
Spring AOP와 프록시 패턴을 이해해보자
8.[Outstagram] 템플릿 메서드 패턴을 실제 프로젝트에 적용해보기
공부한 템플릿 메서드 패턴을 실제 프로젝트에 적용해보자...!!!
9.[Outstagram] Redis에서도 동시성 이슈가 발생한다고...? (lua script 적용기)

lua script를 통해 Redis 동시성 이슈 해결하기
10.[Outstagram] nGrinder를 활용한 부하 테스트 후 성능 튜닝 과정
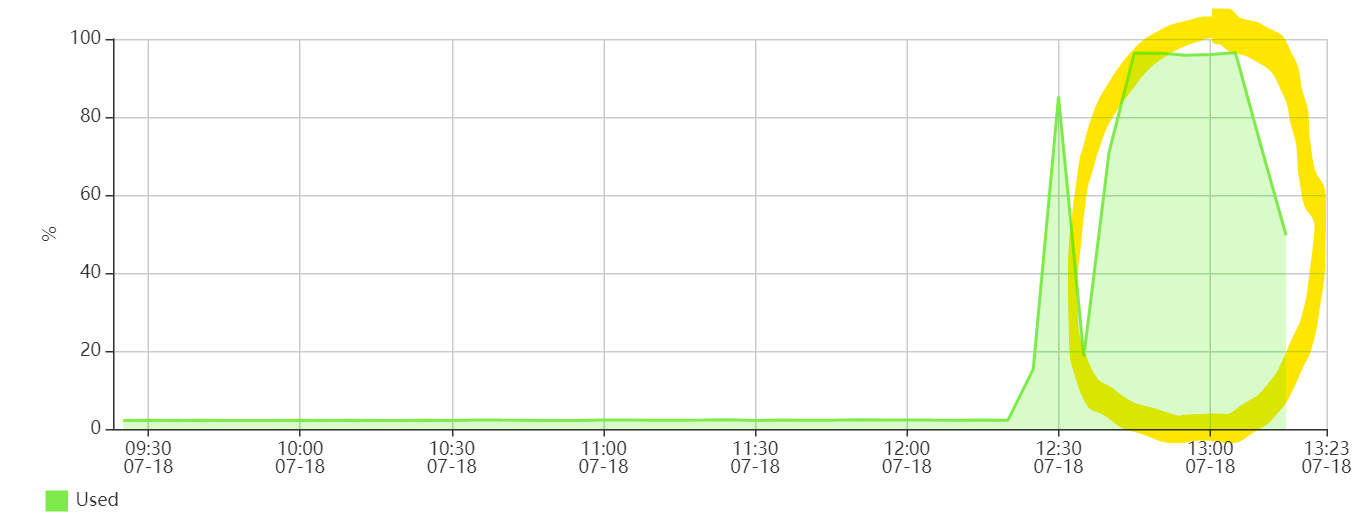
부하 테스트란...? 실제 서비스 시작하기 전에, 현재 구축한 서버에서 어느정도 유저를 커버할 수 있는지, 대략 어느 시점부터 서버에 에러가 발생하기 시작하는지 알기 위해 부하를 부어보는 테스트다. 실제 서비스할 서버 환경과 동일한 환경에서 부하를 늘려가면서 부어본다
11.[Outstagram] Cache 유무에 따른 성능 비교해보기
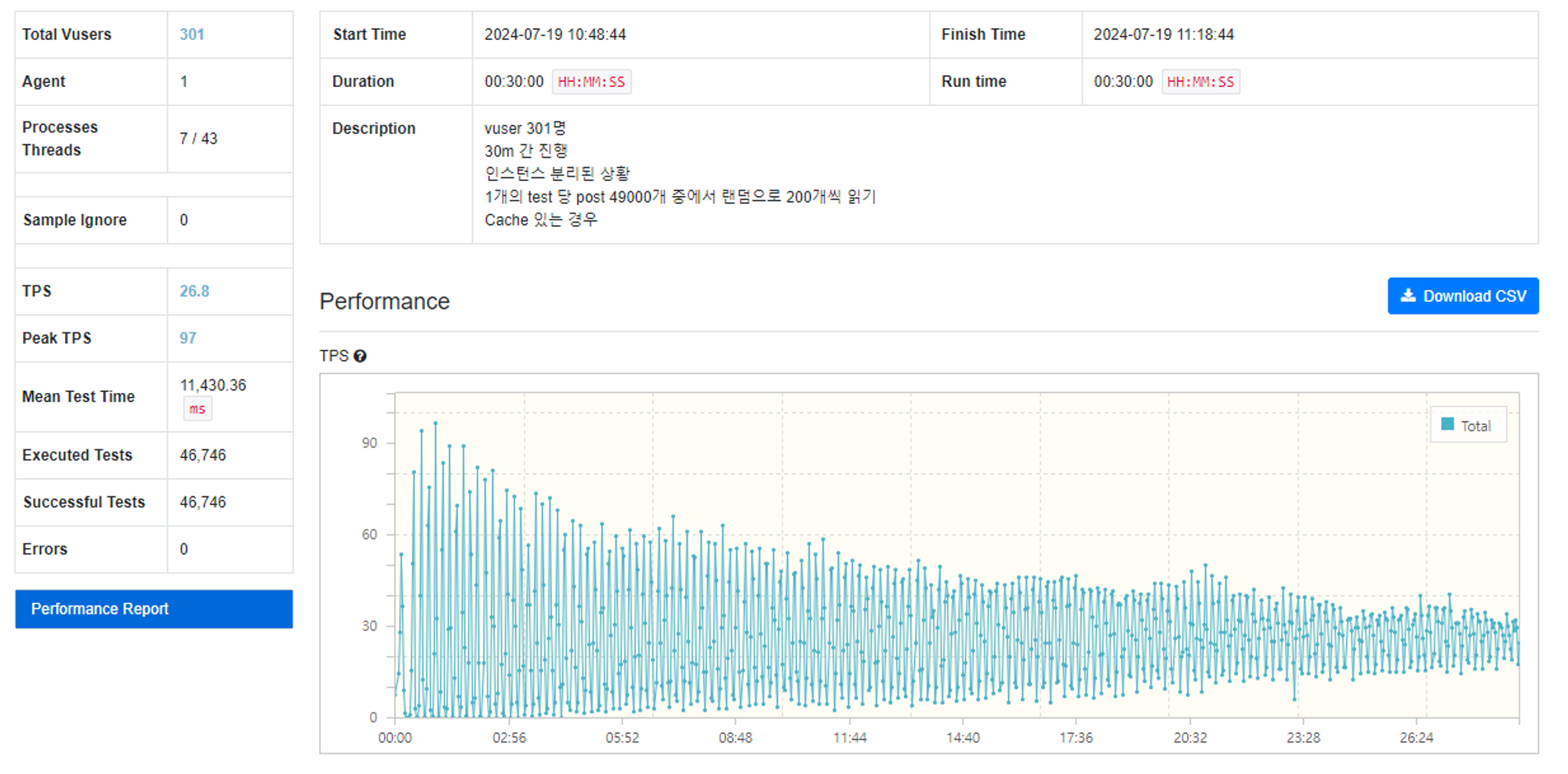
게시물 관련 정보들을 캐시했을 때와 하지 않았을 때의 성능(응답속도)을 비교해보자!!유저가 게시물 단건 조회 시 아래와 같이 많은 정보를 모아서 리턴한다.게시물 정보이미지 정보게시물의 댓글 정보게시물 작성자 유저 정보이 정보들을 모두 DB에 질의해서 모아서 게시물 종합
12.[Outstagram] kafka 메시지 큐를 활용해 비동기 메시지 전송을 도입한 이유
현재 상황 : 게시물 생성 시, feed 목록 구성 및 Elasticsearch DB에도 게시물 저장해야 함성능 저하관심사 분리 실패 ➡ 유지보수 어려움확장성 제한 테스트 어려움유저가 신규 게시물을 생성하면, 신규 게시물을 팔로워들의 feed 목록에 넣어줘야 하고 El
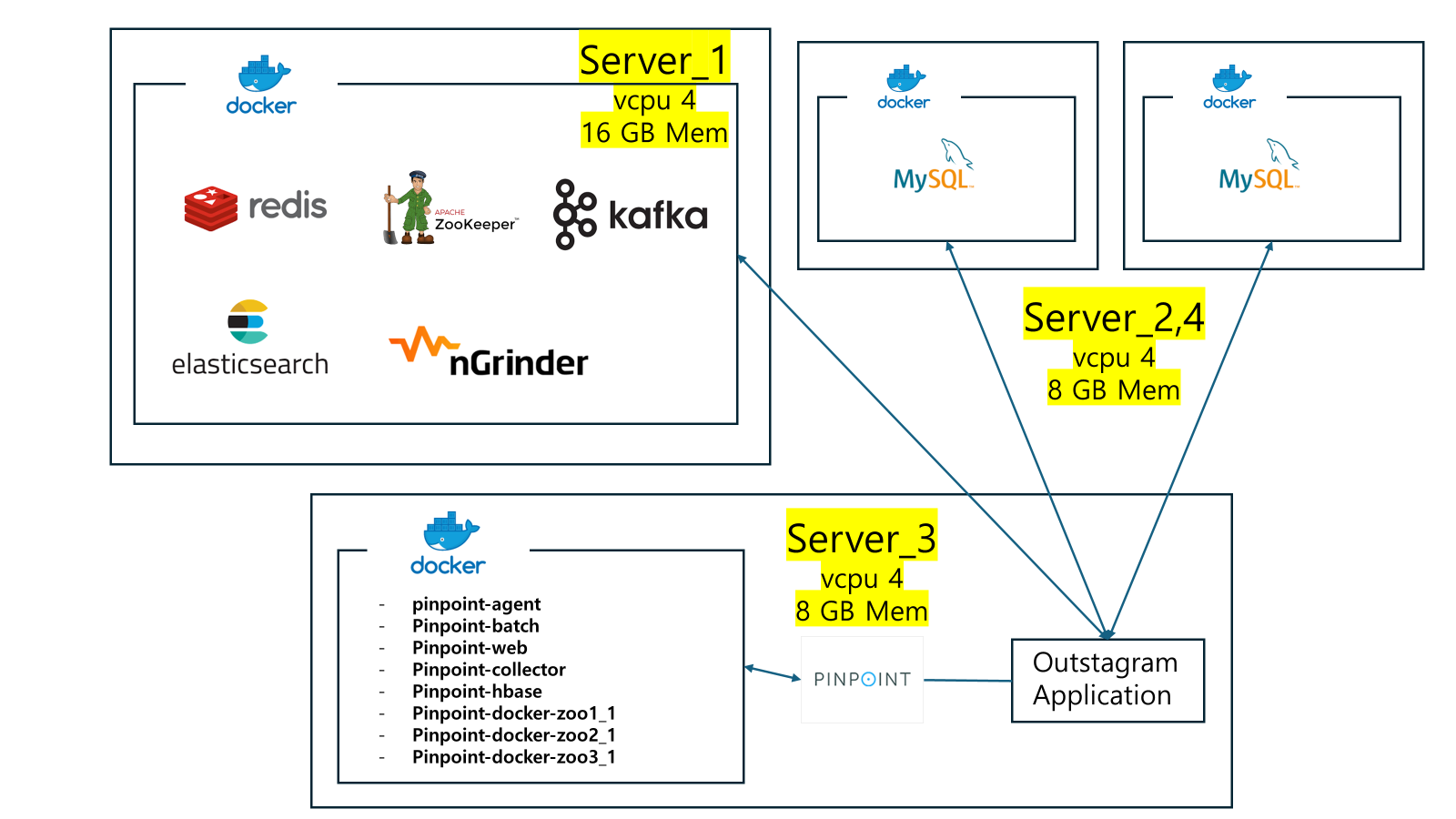
13.[Outsagram] nGrinder & pinpoint로 병목 지점 파악 후, sharding을 통해 성능 개선한 경험

sharding 적용기...
14.[Outstagram] AOP 활용해 동적으로 DB Source 바꾸기
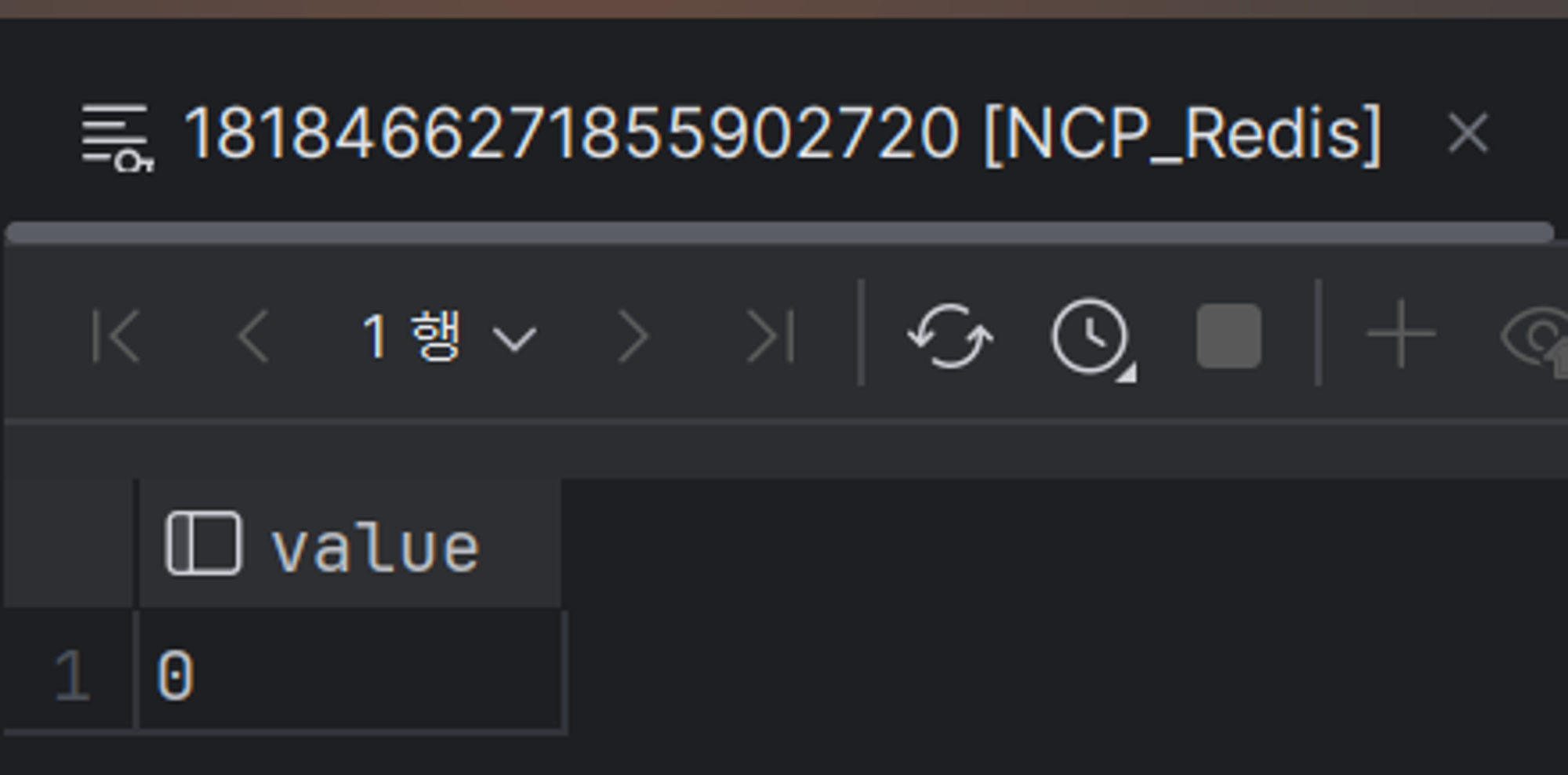
sharding을 애플리케이션 단에서 구현하려면 sharding key를 정하고 해당 key를 바탕으로 런타임 시점에서 DataSource를 정해야 된다.이의 구현 과정을 설명해보려고 한다.DB에 가해지는 부하를 줄이기 위해서 sharding을 해야겠다고 판단했다.No