머신러닝 문제 해결 방법 中 회귀(Regression)
선형 회귀 (Linear Regression)
- 모든 문제들이 선형으로 풀 수 있다고 가정하고 시작해서 선형회귀가 나왔다.
- 머신러닝, 딥러닝의 기본구조는 1차 함수, 선형함수이다.
🔷가설(Hypothesis)
- 문제 해결을 위해서 가설을 세우는데, 선형 회귀에서는 이 가설을 선형함수(수식)으로 세운다.
- 이 가설은 기계가 아닌 사람이 정하고, 정한 가설에 맞게 기계가 문제를 풀도록 한다.
→ 선형 수식을 가설이라고 한다.📝 선형회귀의 전제: 문제 해결에 있어서 가장 효과적인 방법이 선형으로 가설을 만드는 것
🔷 손실함수 Cost/Loss Function
정확한 Y값을 예측하기 위해선 가설로 세운 임의 직선과 점(정답)의 거리를 최대한 가깝게 만들어야 한다. 직선과 점과의 최소 거리를 구하는 function, 평균제곱오차로 cost/loss의 최솟값을 찾는다.
→ 평균 제곱 오차
- minimization: 직선과 점과의 거리의 제곱을 최소화하는 것 = 최적화 문제다.
- 임의로 만든 직선 H(x): 가설(Hypothesis)
- Cost: 손실 함수(Cost or Loss function)
📍 학습이 잘된 모델: 직선 H(x)과 정답 포인트 y의 거리가 최소일 때 = Cost function이 최솟값을 가질 때
- Cost function의 기능
- 예측이 잘되었는지 판단하는 척도
- 학습이 잘되었는지 판단 기준
- 학습을 어느 방향으로 시켜야 하는지 길잡이 역할
- 우리가 이 가설에서 구해야 하는 값: W와 b의 값 = 직선의 기울기와 y절편
- W: Weight (행렬 형태) = x에다 곱한 값
- b: bias (행렬) = Wx에 더한 값
다중 선형 회귀(Multi-variable linear regression)
- 선형 회귀와 똑같지만 입력 변수가 여러 개
- 입력값이 2개 이상이 되는 문제를 선형 회귀로 풀고 싶을 때 다중 선형 회귀를 사용합니다.
가설
손실 함수
📝 정리
선형회귀란? 모든 문제는 선형회귀로 풀 수 있다는 가정한다. 가설을 직선/선형 함수로 표시해서, 이 직선과 정답값의 거리를 좁히는 방법으로 기계한테 학습을 시킨다. 기계는 W, b값을 계속 바꿔 대입하면서 Cost가 minimaize(최소화) 되는 방향으로 학습한다.
Optimizer ⊃ 경사 하강법 (Gradient descent method)
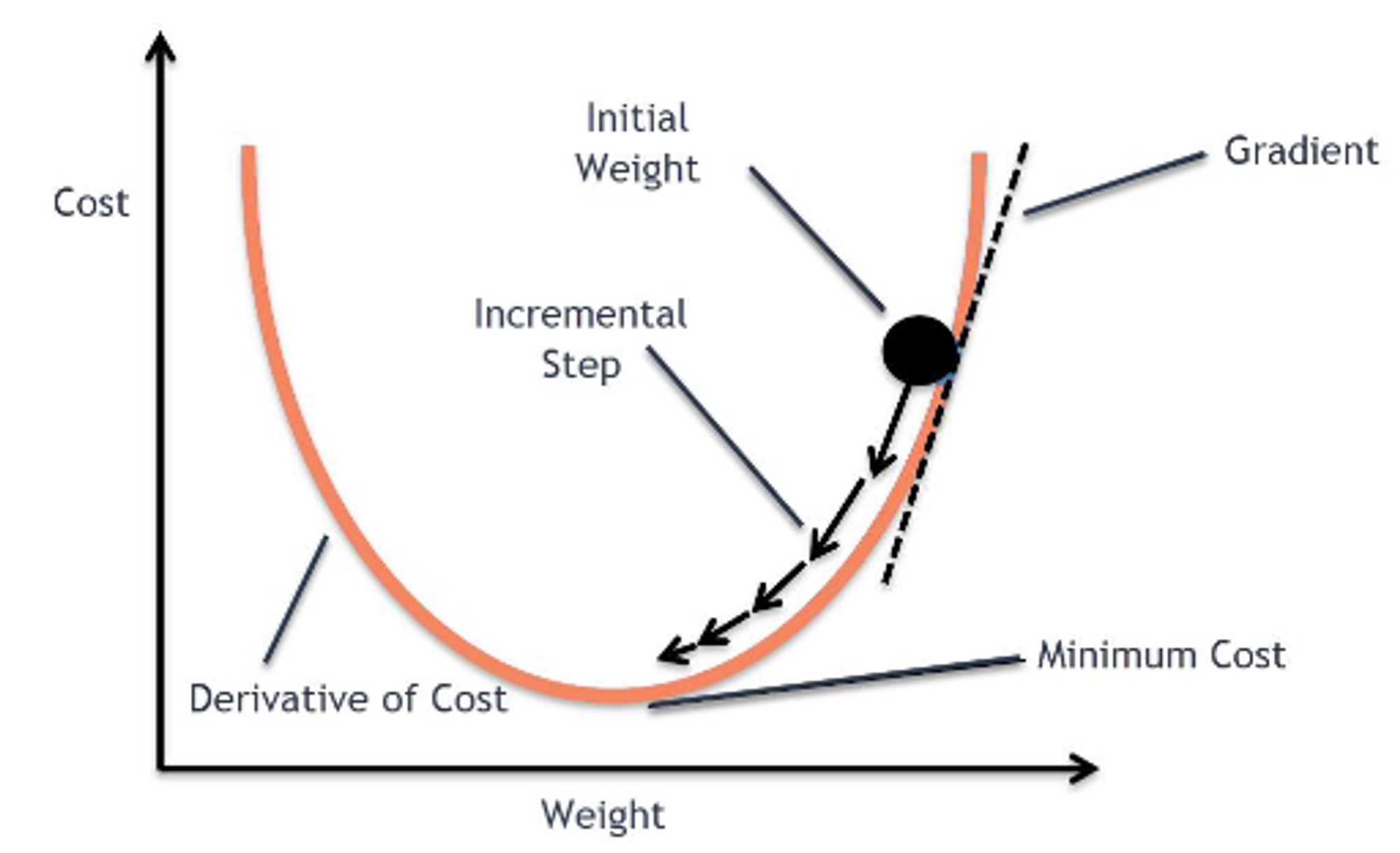
상단의 이미지는 정확도 높은 가설과 결과값을 도출하기 위해서, 손실함수를 최소화(Optimize)해야 한다. 이 손실함수를 최소화하는 방법(Optimizer) 중 경사 하강법을 나타낸다.
상단의 그림의 initial weight에서 W,b값을 바꿔 대입하면서 Cost가 내려가는지 확인하고, 점점 내려가면서 최소점에 도달했을 때 학습을 종료시키는 것.
Cost 가 떨어지면, 내가 올바른 방향으로 학습시키고 있다고 체크할 수 있고, Cost가 올라가면 잘못 학습시키고 있기에 방향을 조정할 수 있다.
설명
컴퓨터는 사람처럼 수식을 풀 수 없기때문에 경사 하강법이라는 방법을 써서 점진적으로 문제를 풀어간다. 처음에 랜덤으로 한 점(initial weight)으로부터 시작한다. 좌우로 조금씩 그리고 한번씩 움직이면서 이전 값보다 작아지는지를 관찰한다. 여기서 조금씩 움직이는, 한 칸씩 전진하는 단위를 Learning rate다. 그리고 그래프의 최소점에 도달하게 되면 학습을 종료된다.
기능
- 그래프에 따라 움직이면서 Cost의 값을 보고, 학습의 방향이 어떤지 확인할 수 있다.
learning rate
- 전진하는 한 칸의 단위(점 사이의 거리)
→ learning rate가 크면 최소점 도달까지 짧게 걸리고, 작으면 최소점 도달까지 오래 걸림- learning rate가 지나치게 클 경우엔 최솟값을 지나치고, 검은 점으로 진동하다가, 최악의 경우엔 발산(무한대로 튕겨 나감)하게 되는 Overshooting이 발생될 수 있다.
- 머신러닝 모델이 학습을 잘하기 위해서는 적당한 Learning rate를 찾는 작업(실험)은 필수적이다.
실제 손실함수
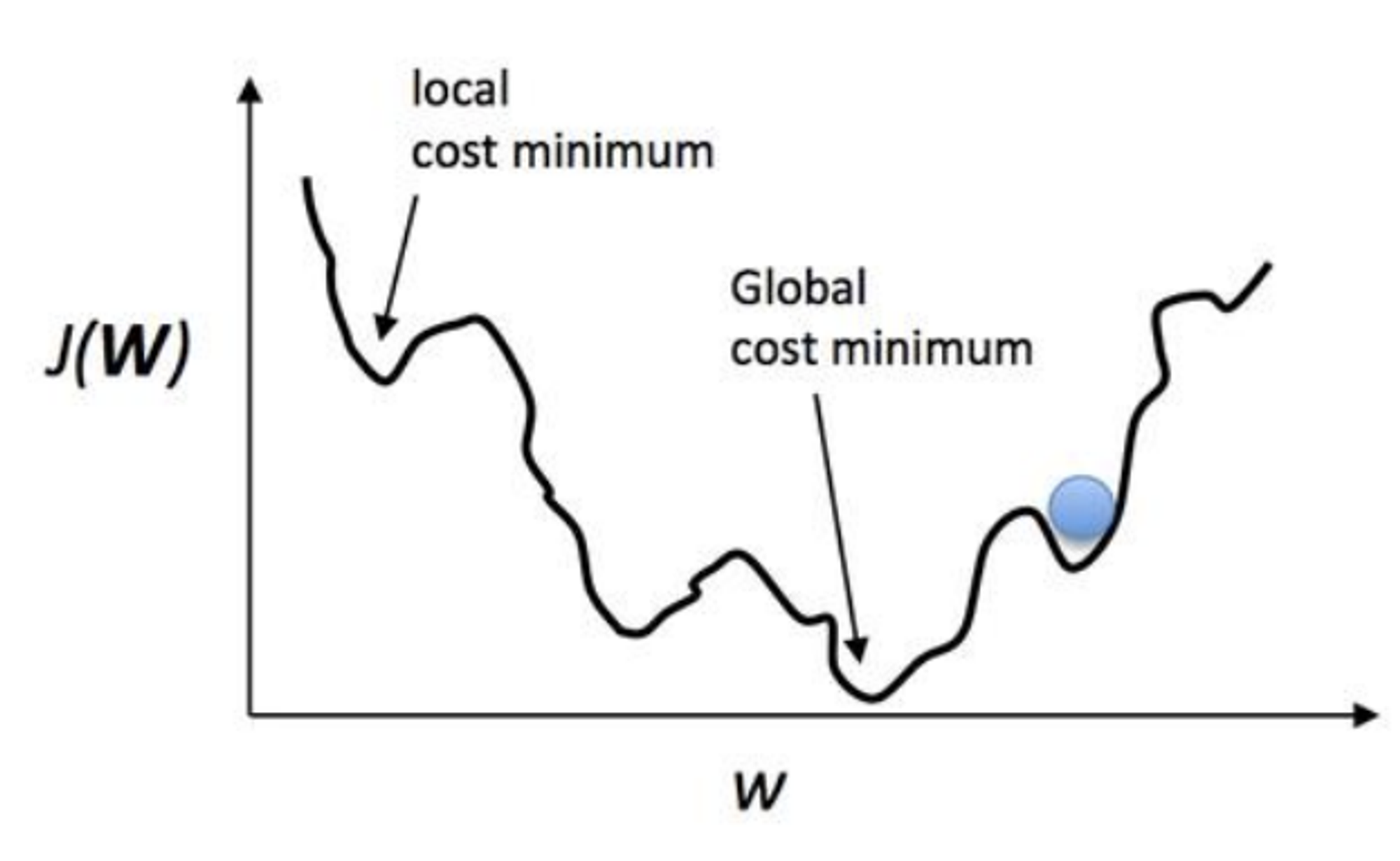
- 손실 함수의 최소점인 Global cost minimum을 찾아야 한다.
- learning rate를 잘못 설정하면 local cost minimum에 빠질 위험도 있다.
- global minimum 을 찾기 위해 좋은 가설과 손실함수를 만들어서 기계가 잘 학습할 수 있도록
데이터셋 분할
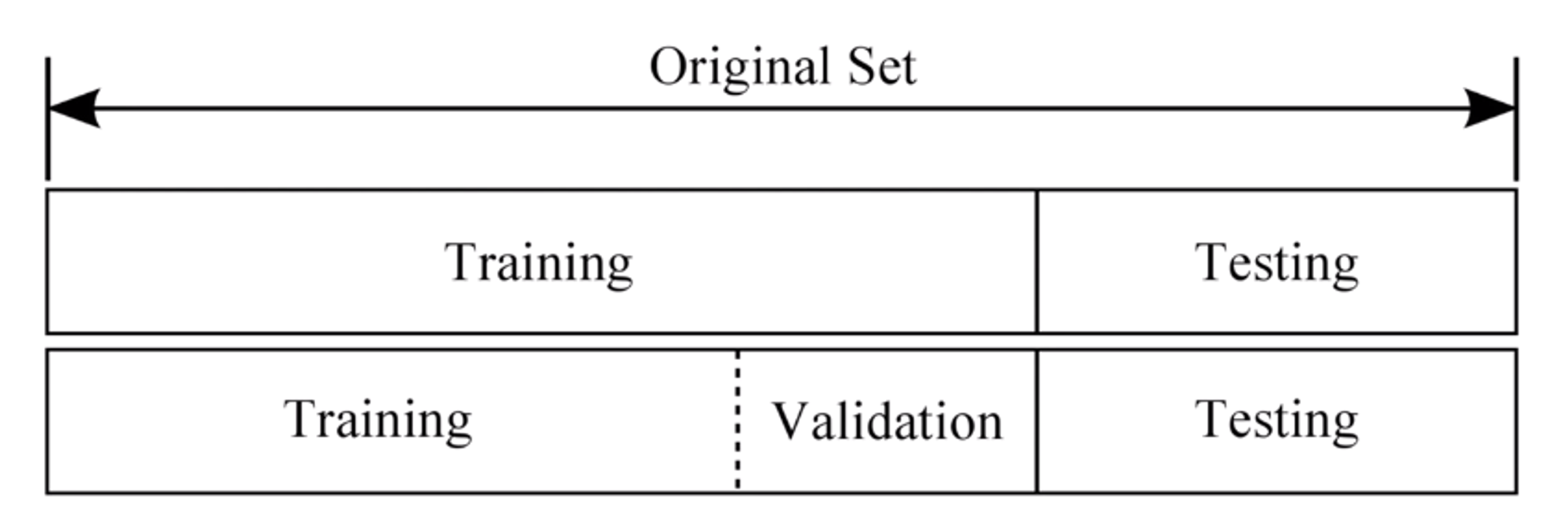
Training set (학습 데이터셋, 트레이닝셋), Validation set (검증 데이터셋, 밸리데이션셋), Test set (평가 데이터셋, 테스트셋)
- traning set 이 전체 데이텟의 80퍼센트 차지
- 다른 데이터셋의 정확도가 높아도, Test set의 정확도가 낮으면 무용지물이다.
Karas를 활용한 선형회귀 실습
ex) 경사하강법으로 loss function의 최솟값 구하기
import numpy as np from tensorflow.keras.models import Sequential # 모델을 정의할 때 쓰임 from tensorflow.keras.layers import Dense # 가설을 구현할 때 쓰임 from tensorflow.keras.optimizers import Adam, SGD x_data = np.array([[1], [2], [3]]) y_data = np.array([[10], [20], [30]]) model = Sequential([ # 모델을 순차적으로 쌓아나갈 수 있는 구조 Dense(1) ]) model.compile(loss='mean_squared_error', optimizer=SGD(lr=0.1)) model.fit(x_data, y_data, epochs=100) # epochs 복수형으로 쓰기!
x_data = np.array([[1], [2], [3]]) y_data = np.array([[10], [20], [30]])- Karas 활용을 위해선 데이터셋을 넘파이로 바꿔줘야 한다.
Dense(1)- 출력값, Y값이 하나다.
model.compile(loss='mean_squared_error', optimizer=SGD(lr=0.1))
-
model.compile= 모델을 구성해준다. -
lossfunction은mean_squared_error(평균제곱오차)를 쓴다. -
Tensorflow에 비해서 수식을 안 써도 되는 장점이 있다.
-
optimizer=SGD- optimizer는 Stochastic Gradient Descent (SGD)를 사용한다.
-
lr=0.1- lr= learning rate
model.fit(x_data, y_data, epochs=100)
model fit- fit(머신러닝에서 많이 사용하는 단어) hypothesis (가설)에 정답값을 맞춘다.
- 'x와 y 데이터를 인자에 넣어서 model에 fitting 과정을 거친다'
- epochs: 반복학습 횟수
y_pred = model.predict([[4]]) print(y_pred)
- predict 메소드 사용해서 예측한다.
- x에 4를 넣었을 때 y의 값을 예측한다.
