SQL vs ORM
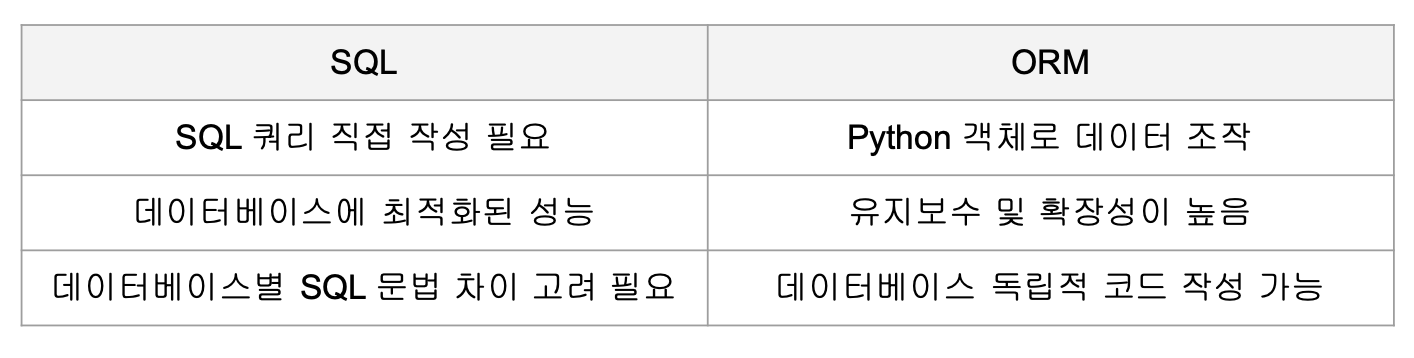
SQL(Structured Query Language)
- 관계형 데이터베이스와 상호작용하기 위한 언어
- 데이터를 삽입(INSERT), 조회(SELECT), 수정(UPDATE), 삭제(DELETE)하는 명령 제공
- 장점
- 데이터베이스 제어가 명확하고 강력
- 복잡한 데이터 조작 및 분석을 직접 수행 가능
- 단점
- 애플리케이션 코드와 분리된 언어로 작성 필요
- 데이터베이스별 SQL 문법에 약간의 차이 존재
- SQL 코드가 많아질수록 유지보수 어려움
ORM(Object-Relational Mapping)
- 객체와 관계형 데이터베이스 간의 매핑을 의미
- 객체: 객체, 클래스, 속성의 구조 / 관계형 데이터베이스: 테이블, 로우, 컬럼과 같은 구조 (RBDMS)
- 데이터베이스의 테이블을 객체로 매핑하고, 객체 간의 관계를 데이터베이스의 외래 키 등으로 매핑하는 방식
- DB에 있는 데이터들을 객체처럼 사용할 수 있도록 도와준다. SQL 쿼리문 없이 데이터 CRUD가 가능.
- 장점
- 개발자 친화적
- SQL 대신 Python 코드로 데이터 처리 가능
- 테이블 변경 시 코드를 수정하면 쿼리와 매핑이 자동으로 처리
- 데이터베이스 독립성: 코드 수정 없이 SQL 전환 가능 (ex. MySQL -> PostgreSQL)
- 안정성: SQL Injection 같은 보안 취약점을 자동으로 방지
- 결과 오류를 줄일 수 있음 (쿼리 결과에 대한 증명이 가능)
- 개발자 친화적
- 단점
- 복잡한 쿼리는 직접 SQL 작성 필요
- ORM 레이어로 인해 성능이 약간 저하될 수 있음
SQLAlchemy ORM
- 관계형 데이터베이스와 상호작용하기 위한 강력하고 유연한 도구 제공
- 단순 데이터베이스 연동, 복잡한 쿼리 작성 등 다양한 요구를 충족할 수 있도록 설계됨
SQLAlchemy 특징
- 유연성과 강력함
- 단순한 데이터 조작부터 복잡한 쿼리 작성까지 다양한 기능 제공
- 관계형 데이터베이스의 강점을 최대한 활용 가능
- 데이터베이스 독립성
- SQLite, PostgreSQL, MySQL, Oracle 등 대부분의 데이터베이스를 지원
- 데이터베이스를 변경해도 코드 수정이 최소화됨
- 고성능과 확장성
- SQLAlchemy Core를 사용하면 SQL 쿼리를 직접 작성 가능
- 대규모 프로젝트에서도 안정적으로 동작
- 사용자 친화적: Pythonic한 문법으로 직관적이고 간결한 코드 작성 가능
SQLAlchemy의 구성 요소
-
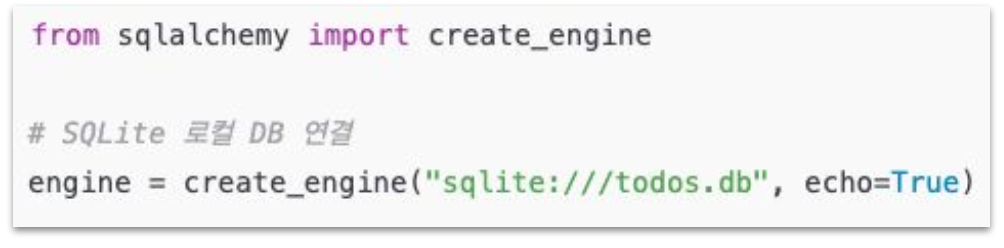
Engine: DB 연결 객체
- 데이터베이스와의 연결을 관리하는 핵심 요소
- 데이터베이스 URL을 통해 연결 설정
-
Session: DB 작업을 실행하는 통로
- DB 연결을 통해 실제 CRUD 실행

- DB 연결을 통해 실제 CRUD 실행
-
Base
- 테이블 정의를 위한 클래스 기반
- 모든 테이블 클래스는 Base를 상속받아 정의

-
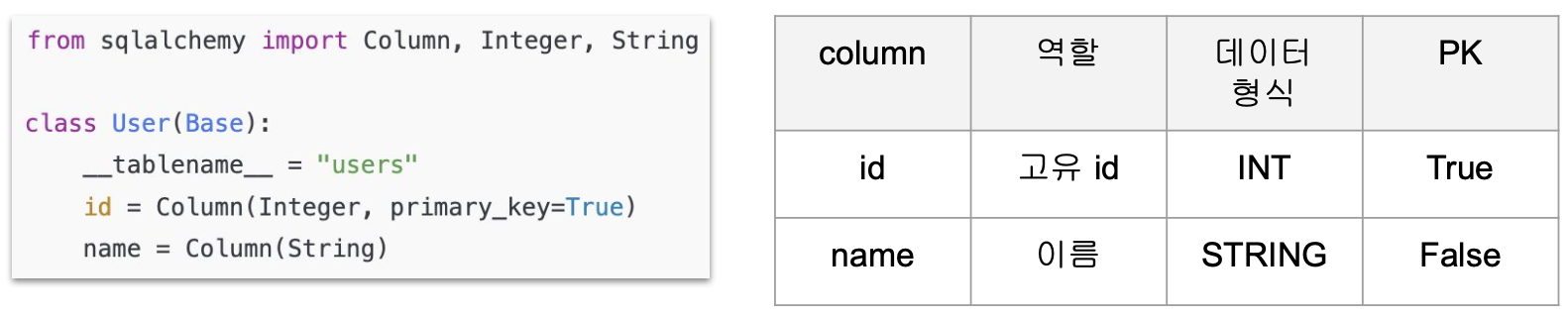
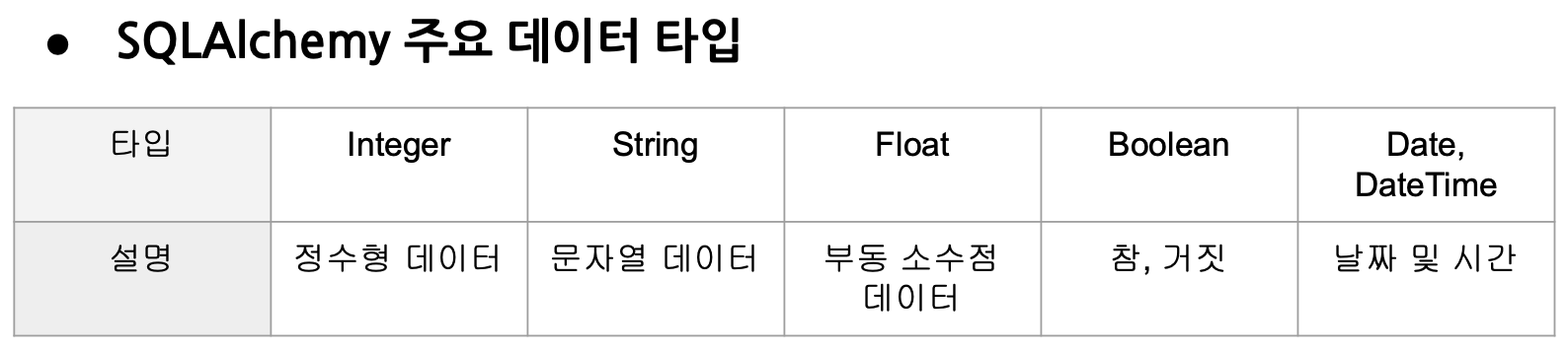
Model
- Python 클래스 형태로 테이블 구조를 정의
- 테이블 컬럼은 클래스의 속성으로 매핑
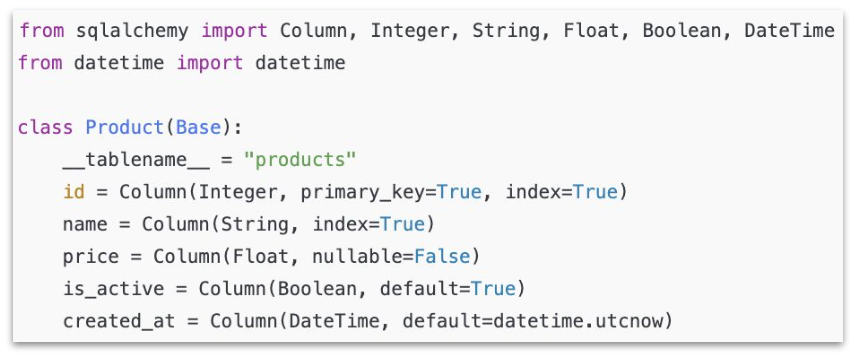
SQLAlchemy 기본 문법
-
데이터베이스 생성
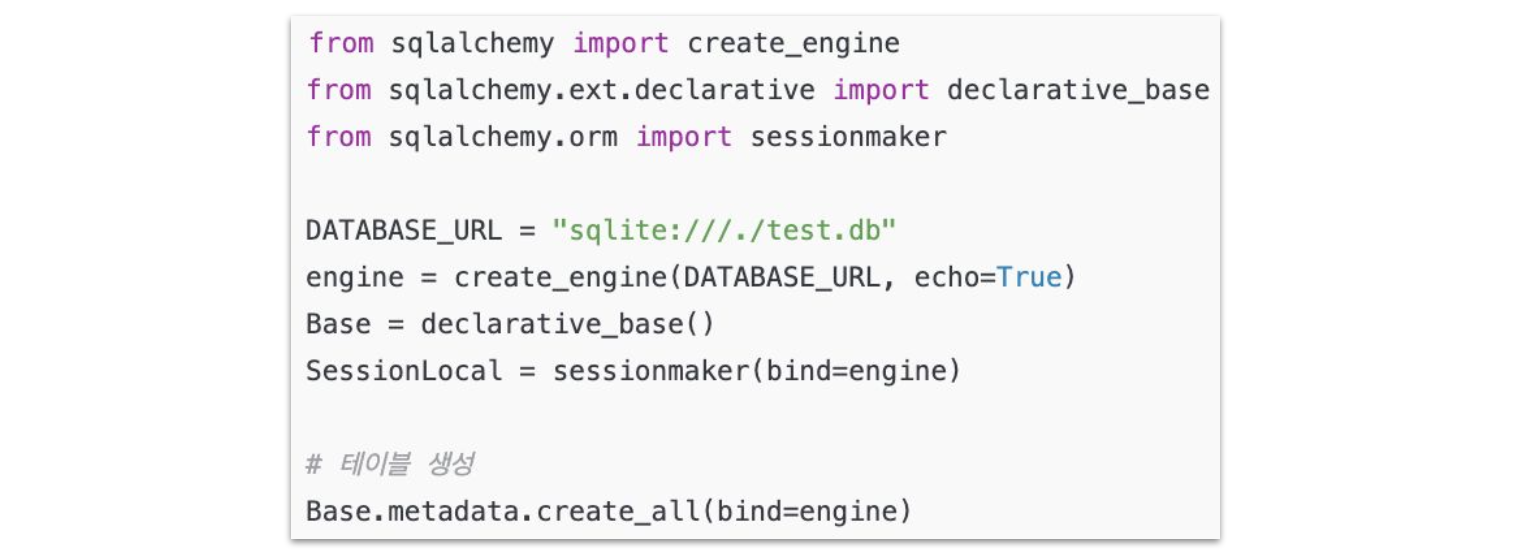
-
테이블 생성
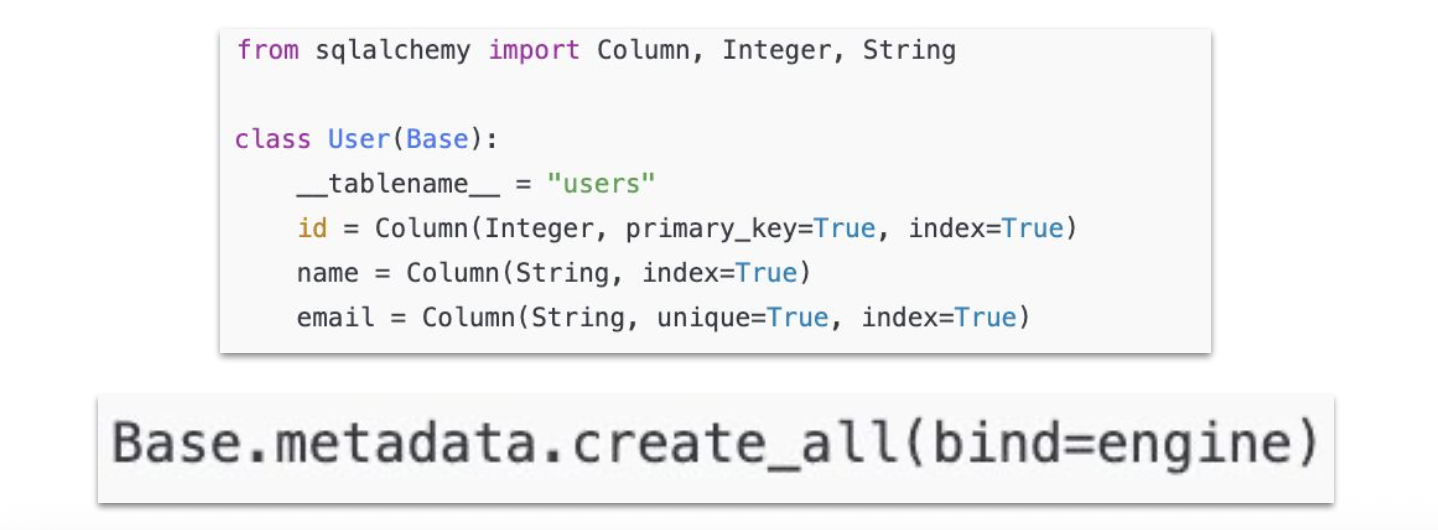
-
데이터 삽입
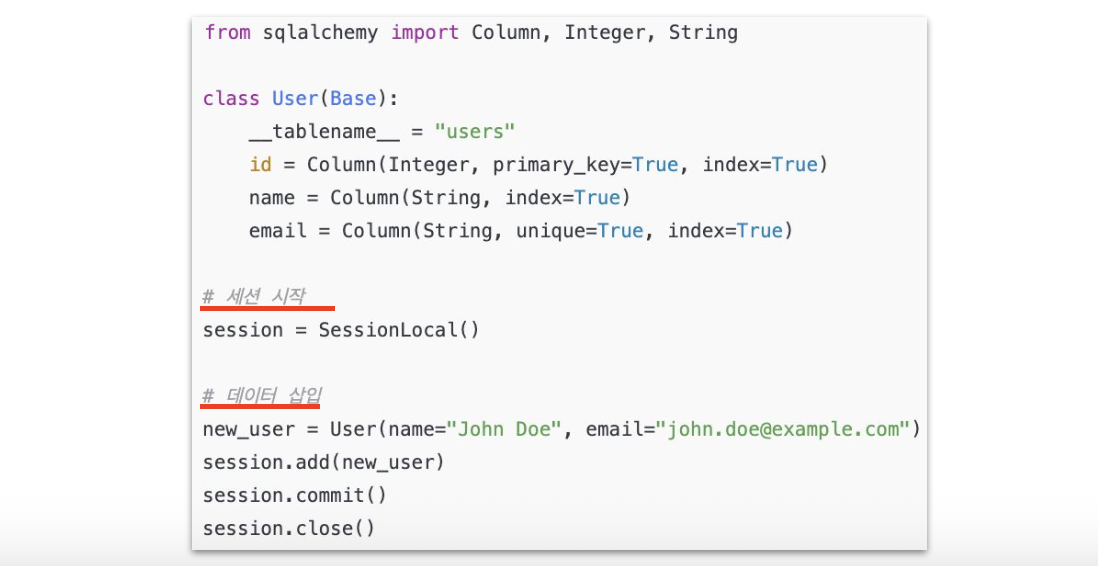
-
데이터베이스 조회
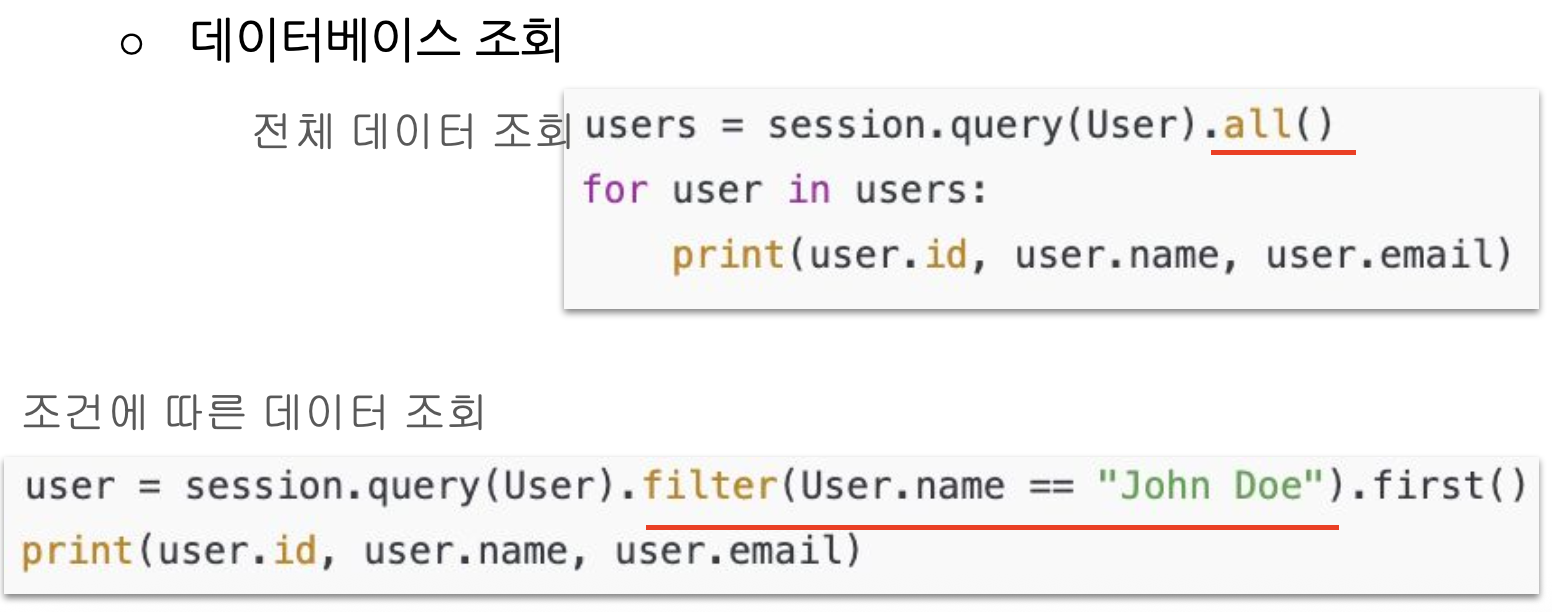
-
데이터베이스 수정
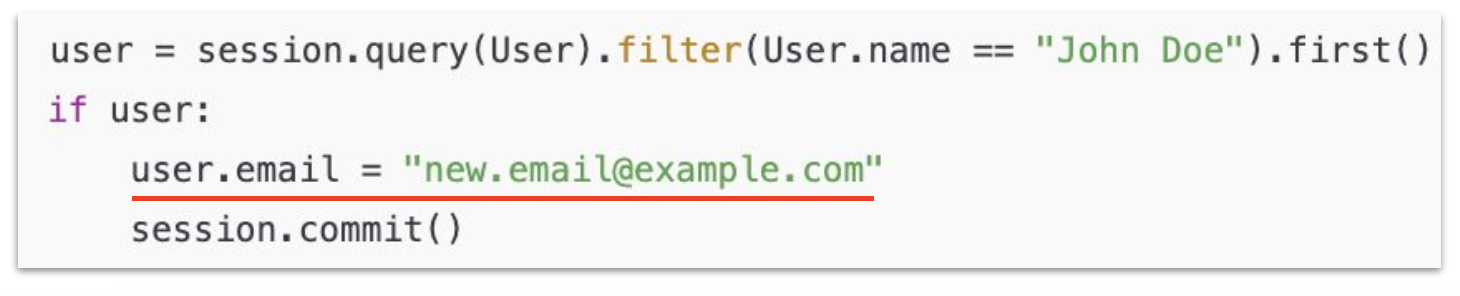
-
데이터베이스 삭제

꾸미기
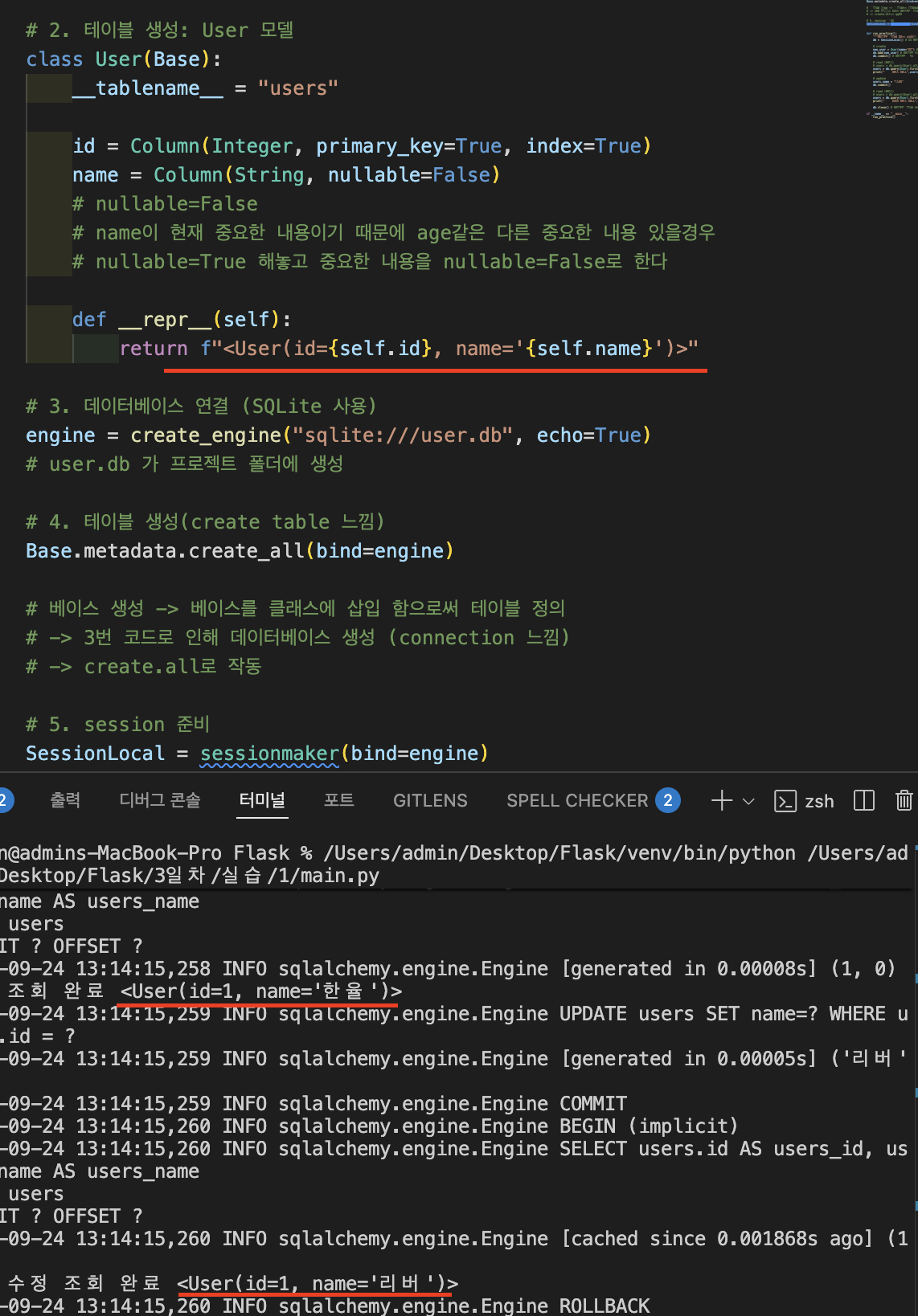
원하는거 실행
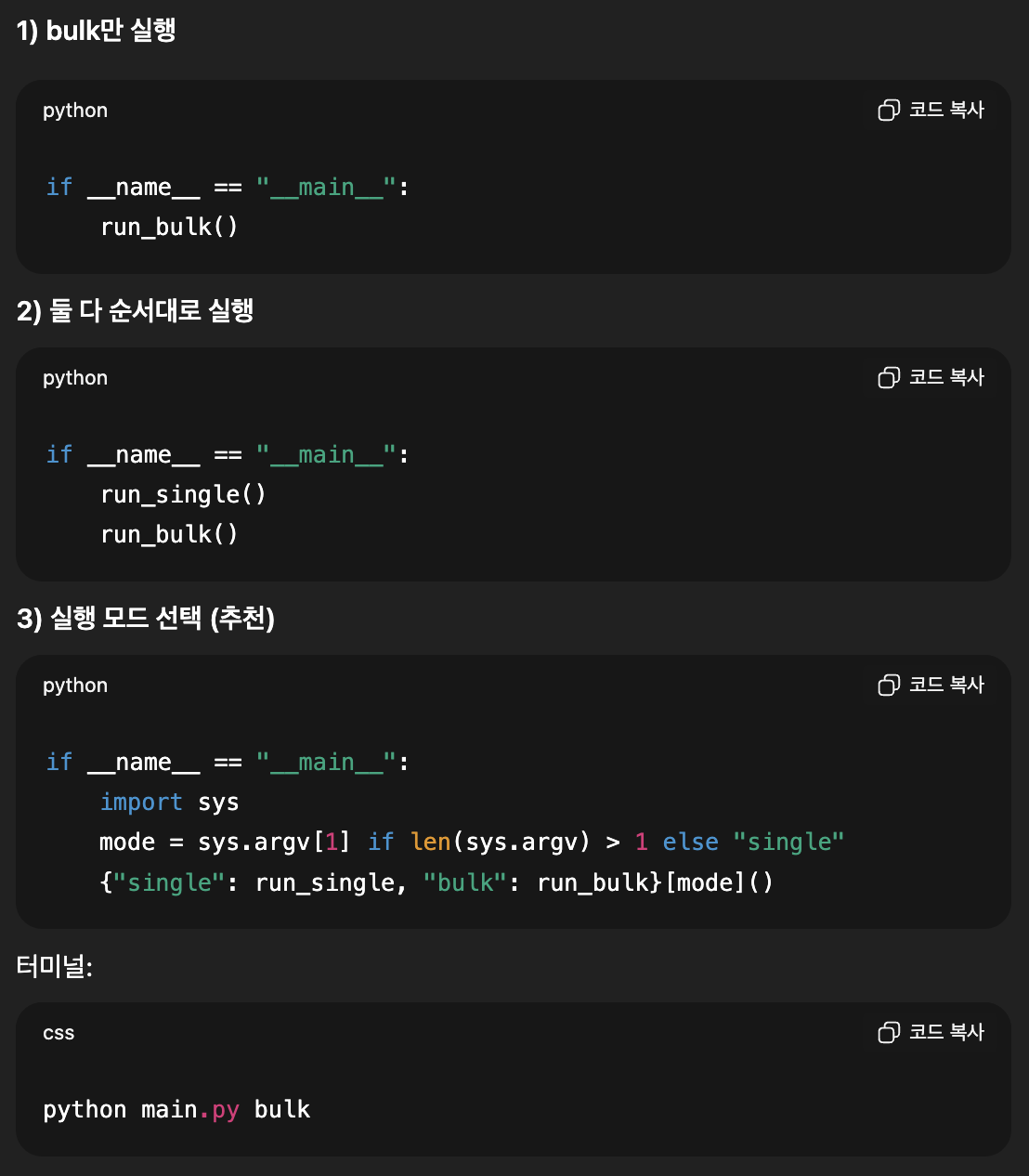
블루프린트
미사용 vs 사용 차이 비교
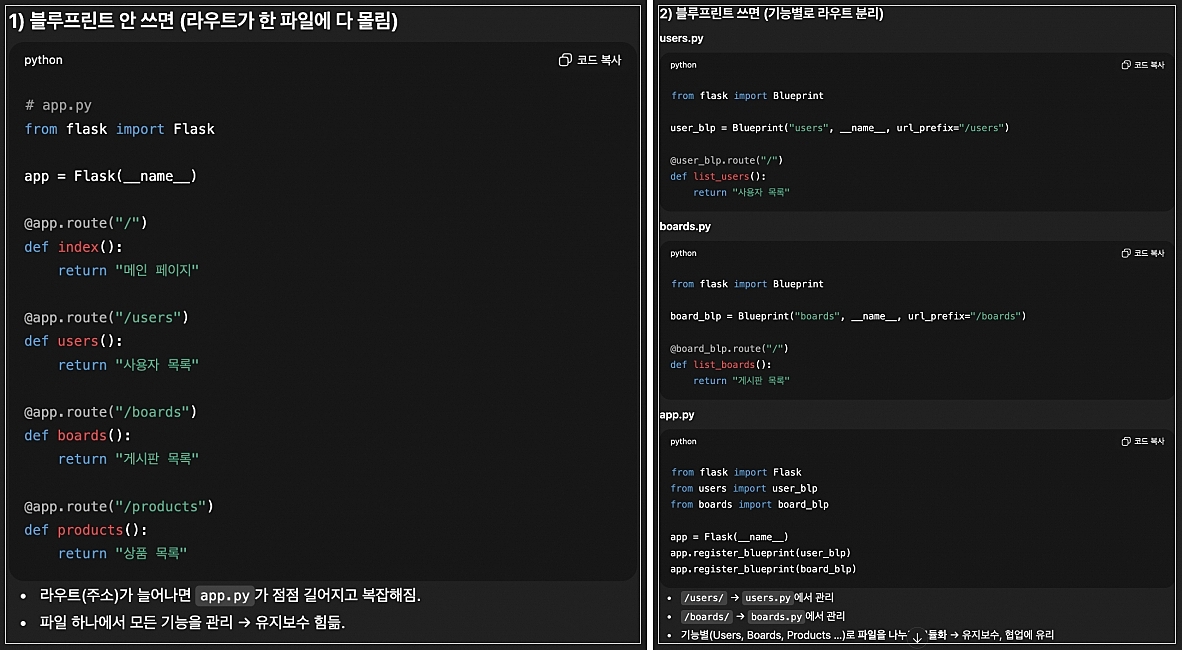
-
라우트 모음집 : 기능별로 주소와 핸들러를 분리하는 방법
- 파일이 커지는걸 막고 모듈별로 깔끔하게 관리하기 위해 필요
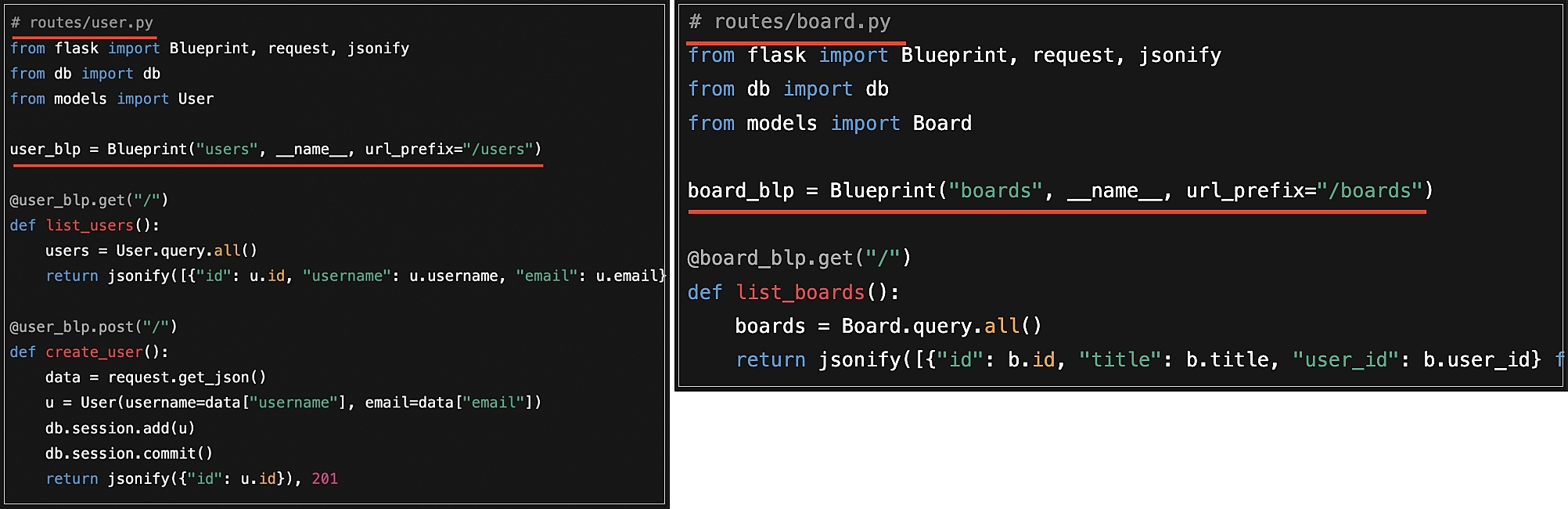
- 파일이 커지는걸 막고 모듈별로 깔끔하게 관리하기 위해 필요
-
user_blp = Blueprint("users", name, url_prefix="/users")
- "users" : 이 이름으로 Flask 내부에 등록되고, Swagger 같은 문서에도 반영
- name : 현재 파이썬 모듈 이름을 전달. Flask가 경로/리소스를 추적하는 데 사용 (관례적)
-
url_prefix="/users"
- 이 블루프린트에 등록된 모든 라우트 앞에 /users가 자동으로 붙음.
- @user_blp.route("/") : 실제 경로는 /users/ 로 노출됨.
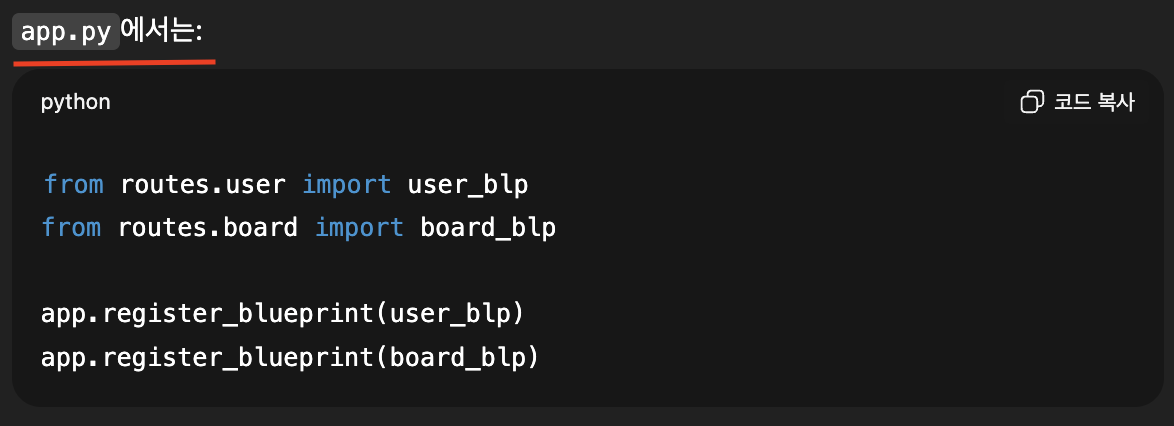
- user_blp = Blueprint(...) → “빈 라우트 묶음 상자” 생성
- @user_blp.route(...) → 상자 안에 라우트들 등록
- api.register_blueprint(user_blp) → Flask 앱에 상자를 장착 (이제 진짜 경로가 살아남)
Flask-Smorest 블루프린트 (Swagger 문서 자동화)
- Flask에서 Blueprint는 원래 있던 개념, Flask-Smorest의 Blueprint는 그걸 확장해서 “API 전용 기능(OpenAPI/Swagger, 검증 등)”을 더한 버전
- 자동 Swagger(OpenAPI) 문서화
- 요청 데이터 검증
- 응답 데이터 검증/직렬화
- RESTful 클래스 기반 뷰(MethodView)와 자연스러운 연계를 지원

VOD
Flask-SQLAlchemy
- Flask에서 SQLAlchemy(ORM)를 쉽게 사용할 수 있도록 도와주는 라이브러리
model
- 데이터베이스 테이블의 구조를 정의
- SQLAlchemy와 같은 ORM을 사용하여 데이터베이스에 질의(Query), 삽입(Insert), 업데이트(Update), 삭제(Delete) 등의 작업을 수행
- 역할 : 데이터베이스와의 상호작용에 초점을 맞춤
- 목적 : 데이터의 저장과 조회를 위한 구조를 제공
- SQLAlchemy와 같은 ORM을 사용하여 데이터베이스에 질의(Query), 삽입(Insert), 업데이트(Update), 삭제(Delete) 등의 작업을 수행
Schema
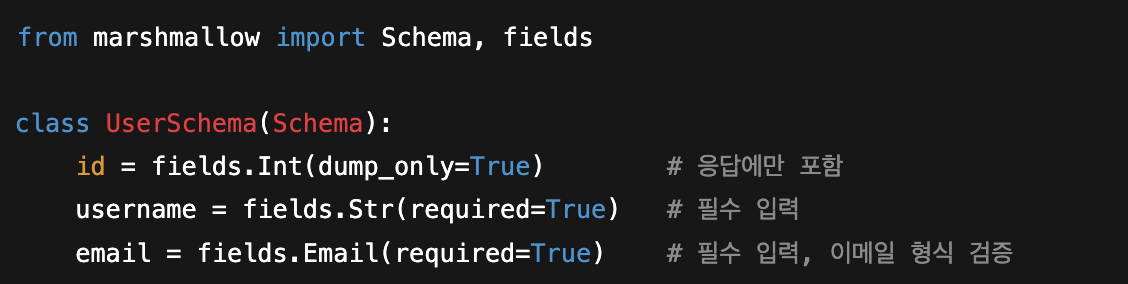
- Marshmallow와 같은 라이브러리를 사용하여 데이터의 직렬화 및 역직렬화를 처리
- API 요청에서 받은 데이터의 유효성을 검증하고, 응답 데이터를 적절한 포맷으로 변환
- 클라이언트가 JSON 형식으로 데이터를 보낼 때, 이 데이터를 검증하고 파이썬 객체로 변환
- 서버가 클라이언트에 데이터를 응답할 때, 파이썬 객체를 JSON 형식으로 변환
- 역할 : 데이터의 직렬화 및 역직렬화에 중점을 둠
- 목적 : 데이터의 형식 및 유효성 검사를 위한 구조를 제공
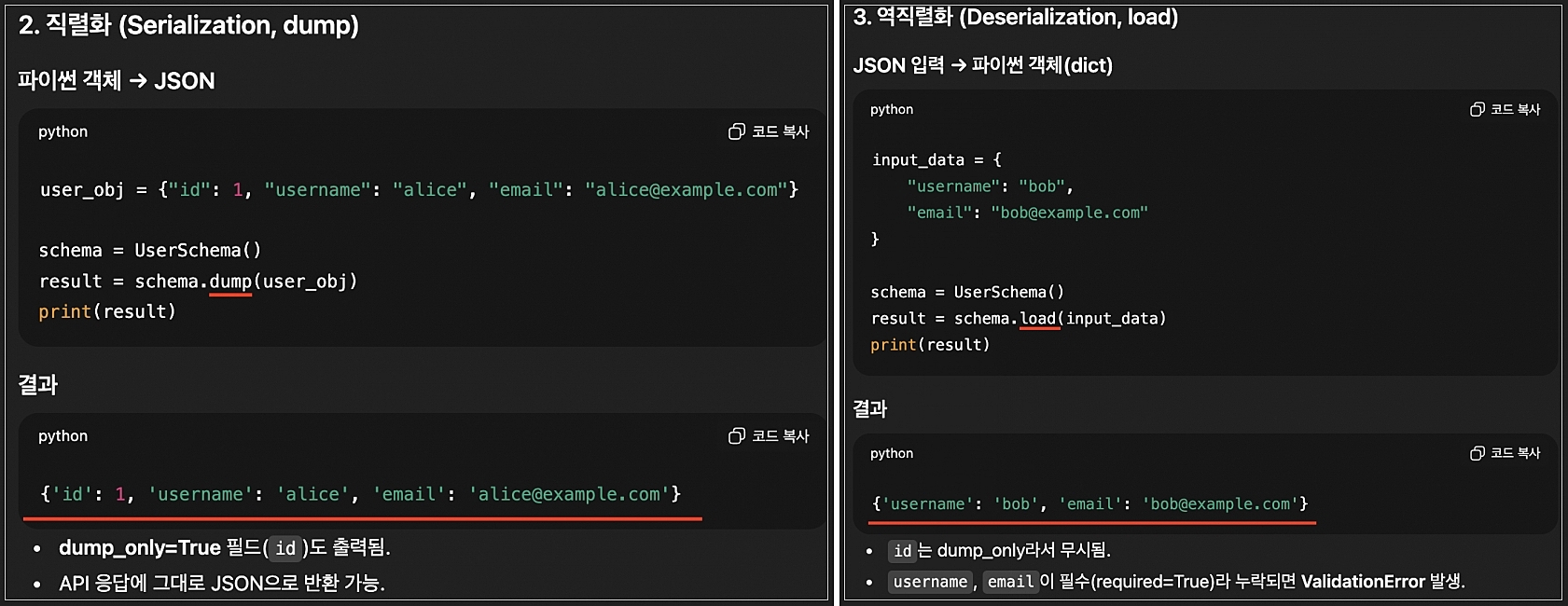
직렬화(dump) or 역직렬화(load)
- 직렬화 : 복잡한 데이터 구조(예: Python 객체)를 JSON과 같은 포맷으로 변환하는 과정
- 역직렬화 : JSON 같은 입력 데이터를 파이썬 객체(dict)로 변환하는 과정
CRUD 테스팅
준비
- terminal 에 python , python3 을 입력하여 파이썬 쉘 접속
- 웹 서버를 켜지 않고, 파이썬 쉘/스크립트에서 DB 작업을 할 때
- with app.app_context(): 필요
> python # 파이썬 쉘로 접속
from db import db
from app import app
from models import User
with app.app_context():
# 코드 작성Create
# 앱 컨텍스트 열기
>>> with app.app_context():
... new_user = User(name='newuser', email='newuser@example.com') # 인스턴스 생성
... db.session.add(new_user) # DB에 추가
... db.session.commit() # 실제 저장
... user = User.query.filter_by(name='newuser').first() # 조회
... print(user)
user.name # newuser
user.email # newuser@example.comRead
# 모든 레코드 조회하기
with app.app_context():
users = User.query.all() # 전체 데이터를 리스트 형태로 반환
for user in users: # for문을 돌면서 각 사용자 객체의 id, name, email을 출력
print(user.id, user.name, user.email)
# 특정 조건을 만족하는 User 조회
with app.app_context():
users = User.query.filter_by(name='coding').all()
# name='coding' 조건을 만족하는 모든 레코드를 가져옴
print(users)
with app.app_context():
user = User.query.filter_by(name='newuser').first()
# 조건(name='newuser')을 만족하는 첫 번째 레코드를 가져옴
# .first()는 딱 한 건만 반환 (없으면 None).
if user: # if문을 통해 존재 여부를 체크한 뒤 정보 출력.
print(f'Name: {user.name}, Email: {user.email}')
else:
print('User not found')Update
# 레코드 수정
with app.app_context():
user = User.query.filter_by(name='newuser').first()
# name='newuser'를 가진 사용자를 찾아서 email을 변경.
if user:
user.email = 'updated@example.com' # 객체 속성 변경
db.session.commit() # 실제 DB에 저장
print('User updated')
else:
print('User not found')Delete
with app.app_context():
user = User.query.filter_by(name='newuser').first()
# name='newuser'를 가진 사용자를 찾아서 삭제.
if user:
db.session.delete(user) # db.session.delete(user) → 세션에서 삭제 예약
db.session.commit() # 실제 DB에서 반영
print('User deleted')
else:
print('User not found')
안녕하세요.