
코딩테스트(1929)
기능구현
검색기능
Django ORM의 Q 객체를 활용한 icontains 검색
- 장점
- 추가적인 설치나 외부 의존성 없이 기존 코드에 즉시 적용 가능
- 단점
- DB의 크기가 매우 커질경우, icontains는 인덱스를 타지 않아 Full Table Scan이 발생하여 느려질 수 있음
- 장점
PostgreSQL Full-Text Search
- PostgreSQL을 사용하고 있기 때문에
- Django에서 지원하는 SearchVector, SearchQuery, SearchRank를 사용 가능
- 장점
- 형태소 분석 가능 / 빠름
- 단점
- SQLite나 MySQL에서는 동작 안 함
- PostgreSQL에 종속적인 코드가 됨
- 장점
Elasticsearch / OpenSearch 도입
- 장점
- 검색성능 최고 / 형태소 분석 가능 / 오타 교정
- 단점
- 별도의 검색 엔진 서버를 띄워야 하기 때문에 너무 오버스펙임
- 장점
Q객체 방식 채택
전체 글 조회
service
def get_global_posts(
series_id: int | None = None, tag_name: str | None = None
) -> QuerySet[Post]:
"""
전체 피드 및 시리즈 목차, 태그 필터링용 포스트 목록을 가져옵니다.
"""
# 1. 기본 필터링 조건 (임시글 제외, 공개글, 삭제되지 않은 글) 적용
qs = Post.objects.filter(
is_temp=False,
visibility=Post.Visibility.PUBLIC,
deleted_at__isnull=True,
)
# 2. 시리즈 ID가 전달되었다면 해당 시리즈의 글만 필터링
if series_id:
qs = qs.filter(series_id=series_id)
# 3. 태그 이름이 전달되었다면, 연결된 태그의 이름이 일치하는 글만 필터링
if tag_name:
qs = qs.filter(tags__name=tag_name)
# 4. N+1 문제 해결 및 좋아요 수 계산 후 생성일 기준 내림차순 정렬 반환
return (
qs.select_related("user")
.prefetch_related("tags")
.annotate(likes_count=Count("likes", distinct=True))
.order_by("-created_at")
)
——————————————————————————————————————[비교]—————————————————————————————————————————
def get_global_posts(
series_id: int | None = None,
tag_name: str | None = None,
search_keyword: str | None = None # 검색 키워드 파라미터 추가
) -> QuerySet[Post]:
"""
전체 피드 및 시리즈 목차, 태그 필터링, 검색용 포스트 목록을 가져옵니다.
"""
qs = Post.objects.filter(
is_temp=False,
visibility=Post.Visibility.PUBLIC,
deleted_at__isnull=True,
)
if series_id:
qs = qs.filter(series_id=series_id)
if tag_name:
qs = qs.filter(tags__name=tag_name)
# 검색 기능 로직 추가
if search_keyword:
qs = qs.filter(
Q(title__icontains=search_keyword) |
Q(content__icontains=search_keyword) |
Q(tags__name__icontains=search_keyword)
).distinct() # 태그 M:N JOIN으로 인한 중복 결과 제거를 위해 필수
return (
qs.select_related("user")
.prefetch_related("tags")
.annotate(likes_count=Count("likes", distinct=True))
.order_by("-created_at")
)view
def get(self, request: Request):
# 1. URL에서 '?series=숫자' 값을 꺼내옵니다.
series_id_str = request.query_params.get("series")
series_id = (
int(series_id_str) if series_id_str and series_id_str.isdigit() else None
)
# 2. URL에서 '?tag=문자열' 값을 꺼내옵니다.
tag_name = request.query_params.get("tag")
# 3. 서비스 레이어 호출 시 series_id와 tag_name을 함께 전달합니다.
posts = get_global_posts(series_id=series_id, tag_name=tag_name)
# 4. 페이지네이션 적용 후 반환
paginator = self.pagination_class()
page = paginator.paginate_queryset(posts, request, view=self)
if page is not None:
serializer = PostListSerializer(page, many=True)
return paginator.get_paginated_response(serializer.data)
return Response(PostListSerializer(posts, many=True).data)
——————————————————————————————————————[비교]—————————————————————————————————————————
def get(self, request: Request):
# 1. URL에서 '?series=숫자' 값을 꺼내옵니다.
series_id_str = request.query_params.get("series")
series_id = (
int(series_id_str) if series_id_str and series_id_str.isdigit() else None
)
# 2. URL에서 '?tag=문자열' 값을 꺼내옵니다.
tag_name = request.query_params.get("tag")
# 3. URL에서 '?search=검색어' 값을 꺼내옵니다.
search_keyword = request.query_params.get("search")
# 4. 서비스 레이어 호출 시 series_id와 tag_name을 함께 전달합니다.
posts = get_global_posts(series_id=series_id, tag_name=tag_name, search_keyword=search_keyword)
# 5. 페이지네이션 적용 후 반환
paginator = self.pagination_class()
page = paginator.paginate_queryset(posts, request, view=self)
if page is not None:
serializer = PostListSerializer(page, many=True)
return paginator.get_paginated_response(serializer.data)
return Response(PostListSerializer(posts, many=True).data)개인 작성 글 검색
service
def get_my_published_posts(
*, user: User, series_id: int | None = None, tag_name: str | None = None
) -> QuerySet[Post]:
"""
내가 작성한 발행 글 중 조건에 맞는 글만 가져옵니다.
"""
# 1. 내 글 중 임시저장 및 삭제되지 않은 글 필터링
qs = Post.objects.filter(
user=user,
is_temp=False,
deleted_at__isnull=True,
)
# 2. 시리즈 ID 필터링
if series_id:
qs = qs.filter(series_id=series_id)
# 3. 태그 이름 필터링 추가
if tag_name:
qs = qs.filter(tags__name=tag_name)
# 4. N+1 문제 해결 및 좋아요 수 계산 후 반환
return (
qs.select_related("user")
.prefetch_related("tags")
.annotate(likes_count=Count("likes", distinct=True))
.order_by("-created_at")
)
——————————————————————————————————————[비교]—————————————————————————————————————————
def get_my_published_posts(
*, user: User, series_id: int | None = None, tag_name: str | None = None, search_keyword: str | None = None
) -> QuerySet[Post]:
"""
내가 작성한 발행 글 중 조건에 맞는 글만 가져옵니다.
"""
# 1. 내 글 중 임시저장 및 삭제되지 않은 글 필터링
qs = Post.objects.filter(
user=user,
is_temp=False,
deleted_at__isnull=True,
)
# 2. 시리즈 ID 필터링
if series_id:
qs = qs.filter(series_id=series_id)
# 3. 태그 이름 필터링 추가
if tag_name:
qs = qs.filter(tags__name=tag_name)
# 4. 검색 기능 로직 추가
if search_keyword:
qs = qs.filter(
Q(title__icontains=search_keyword) |
Q(content__icontains=search_keyword) |
Q(tags__name__icontains=search_keyword)
).distinct()
# 5. N+1 문제 해결 및 좋아요 수 계산 후 반환
return (
qs.select_related("user")
.prefetch_related("tags")
.annotate(likes_count=Count("likes", distinct=True))
.order_by("-created_at")
)view
def get(self, request: Request):
# 1. User 타입 지정
user = cast(User, request.user)
# 2. URL 파라미터에서 series 값을 꺼내옵니다.
series_id_str = request.query_params.get("series")
series_id = (
int(series_id_str) if series_id_str and series_id_str.isdigit() else None
)
# 3. URL 파라미터에서 tag 값을 꺼내옵니다.
tag_name = request.query_params.get("tag")
# 4. 서비스 레이어 호출 시 시리즈와 태그 조건 전달
posts = get_my_published_posts(
user=user, series_id=series_id, tag_name=tag_name
)
# 5. 페이지 네이션 적용 및 응답
paginator = self.pagination_class()
page = paginator.paginate_queryset(posts, request, view=self)
if page is not None:
return paginator.get_paginated_response(
PostListSerializer(page, many=True).data
)
return Response(PostListSerializer(posts, many=True).data)
——————————————————————————————————————[비교]—————————————————————————————————————————
def get(self, request: Request):
# 1. User 타입 지정
user = cast(User, request.user)
# 2. URL 파라미터에서 series 값을 꺼내옵니다.
series_id_str = request.query_params.get("series")
series_id = (
int(series_id_str) if series_id_str and series_id_str.isdigit() else None
)
# 3. URL 파라미터에서 tag 값을 꺼내옵니다.
tag_name = request.query_params.get("tag")
# 4. URL에서 '?search=검색어' 값을 꺼내옵니다.
search_keyword = request.query_params.get("search")
# 4. 서비스 레이어 호출 시 시리즈와 태그 조건 전달
posts = get_my_published_posts(
user=user, series_id=series_id, tag_name=tag_name, search_keyword=search_keyword
)
# 5. 페이지 네이션 적용 및 응답
paginator = self.pagination_class()
page = paginator.paginate_queryset(posts, request, view=self)
if page is not None:
return paginator.get_paginated_response(
PostListSerializer(page, many=True).data
)
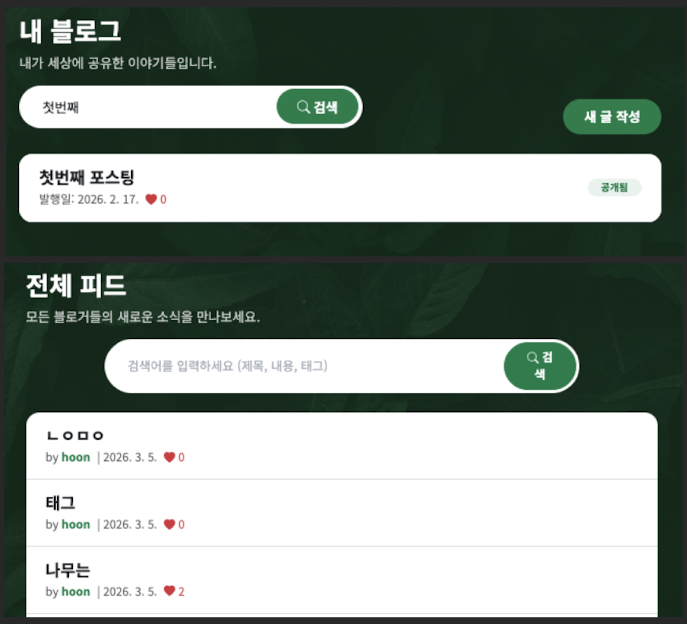
return Response(PostListSerializer(posts, many=True).data)검색 결과 사진
스웨거
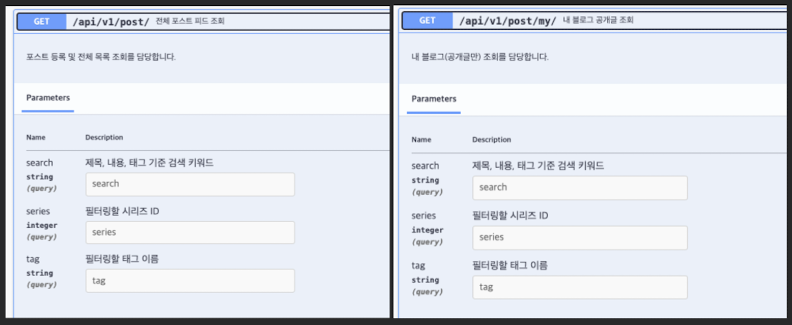
탬플릿
작성 디자인 수정
- 썸네일(대표 이미지) 업로드 영역
- 에디터 상단에 넓게 배치하면 블로그 포스팅의 완성도를 높이고 밋밋함도 잡을 수 있습니다.
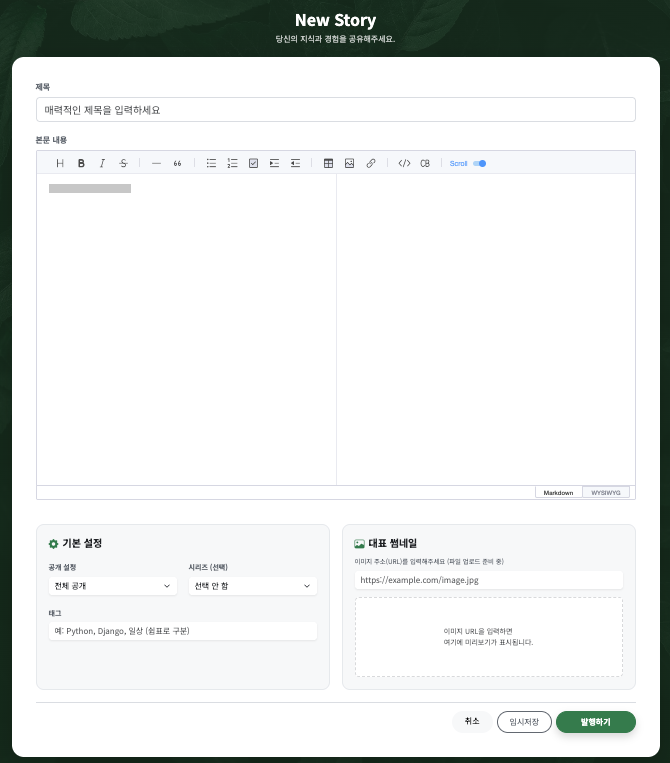
- 에디터 상단에 넓게 배치하면 블로그 포스팅의 완성도를 높이고 밋밋함도 잡을 수 있습니다.
- 우측 사이드바 (작성 가이드)
- 카드 우측에 작은 패널을 두어 '마크다운 자주 쓰는 문법' 등을 띄워두면 공간도 채우고 유용성도 올라갑니다.
내일 구현 예정
- 이미지 처리방식(S3)
- 소셜 로그인(github / discord)
- ai 요약기능 (버튼을 누르면 진행되도록)
- 연타는 막을것
- 자동 임시 저장 (Auto-save) & 글자 수 세기

안녕하세요.