
코딩테스트(2108)
코드 수정
등급관리 로직
현재
fetchMyGardenStats- 사용자의 글 개수와 잔디밭(히트맵) 데이터를 구하기 위해 while 문을 돌며
- 모든 페이지의 게시글을 프론트엔드로 전부 가져오고(N+1 문제 발생)있음
- 이는 글이 100개, 1000개로 늘어나면 브라우저가 느려지고 서버 트래픽이 폭주하는
- 치명적인 성능 저하를 유발
- 사용자의 글 개수와 잔디밭(히트맵) 데이터를 구하기 위해 while 문을 돌며
개선방안
- 백엔드에서 '사용자의 총 글 개수' / '히트맵용 날짜 데이터' / '계산된 등급 정보'를
- 한 번에 던져주는 통계 전용 API를 만들기 필요
- 백엔드에서 '사용자의 총 글 개수' / '히트맵용 날짜 데이터' / '계산된 등급 정보'를
service
from apps.post.models import Post
# 등급 설정(GRADE_SETTINGS)
GRADE_SETTINGS = [
...
]
def get_user_garden_stats(user):
"""
특정 유저의 정원(잔디밭 및 등급) 통계 데이터를 계산하여 반환하는 서비스 함수
"""
# 1. DB 조회: 해당 유저의 정상 발행된 글을 가져오고 총 개수를 구함
user_posts = Post.objects.filter(author=user, is_temp=False)
total_count = user_posts.count()
# 2. 날짜 추출: 히트맵을 위해 날짜(created_at)만 뽑아내어 리스트로 만듬 (본문 데이터 배제)
post_dates = list(user_posts.values_list('created_at__date', flat=True))
# 3. 날짜 포맷팅: 프론트엔드에서 사용하기 쉽게 'YYYY-M-D' 문자열로 변환
formatted_dates = [
date.strftime('%Y-%-m-%-d') if hasattr(date, 'strftime') else str(date)
for date in post_dates
]
# 4. 현재 등급 계산: 내 글 개수를 만족하는 가장 높은 등급을 찾기
current_grade = next(
(g for g in GRADE_SETTINGS if total_count >= g["min"]),
GRADE_SETTINGS[-1]
)
# 5. 다음 등급 계산: GRADE_SETTINGS를 역순으로 순회하여 남은 목표 등급 찾기
reversed_settings = list(reversed(GRADE_SETTINGS))
next_grade = next(
(g for g in reversed_settings if g["min"] > total_count),
None
)
# 6. 진행률 계산 초기화: 기본값은 만렙(100%)과 남은 글 수 0으로 설정
progress_percent = 100
remain_posts = 0
# 7. 진행률 수학적 계산: 만렙이 아닐 경우 퍼센티지와 남은 개수를 계산
if next_grade:
remain_posts = next_grade["min"] - total_count
required_for_next = next_grade["min"] - current_grade["min"]
earned_in_current = total_count - current_grade["min"]
# ZeroDivisionError를 방지 및 정확한 퍼센트를 산출
if required_for_next > 0:
progress_percent = (earned_in_current / required_for_next) * 100
# 8. 계산된 모든 데이터를 딕셔너리 형태로 반환 (JSON 직렬화 가능 형태)
return {
"total_count": total_count,
"current_grade": current_grade,
"next_grade": next_grade,
"progress_percent": progress_percent,
"remain_posts": remain_posts,
"heatmap_dates": formatted_dates
}View
from rest_framework.views import APIView
from rest_framework.response import Response
from rest_framework.permissions import IsAuthenticated
from apps.user.services.users_stat_service import get_user_garden_stats
class UserGardenStatsAPIView(APIView):
permission_classes = [IsAuthenticated]
def get(self, request):
# 1. 서비스 레이어 호출(통계데이터 받아오기)
stats_data = get_user_garden_stats(request.user)
# 2. 받아온 딕셔너리 데이터를 JSON 형태로 클라이언트에 응답
return Response(stats_data)수정에 따른 장점
성능 향상과 트래픽 절약 (Performance)
수정 전 (프론트엔드 로직)
- 내 등급을 계산하기 위해 프론트엔드에서 while 문을 돌며
- 내가 쓴 모든 게시글 데이터를 끝까지 다 불러와야 했음
- 만약 글이 1,000개라면 1,000개의 제목, 내용, 썸네일 데이터가 모두
- 네트워크를 타고 브라우저로 전송 (데이터 요금 폭탄, 로딩 지연 발생)
- 내 등급을 계산하기 위해 프론트엔드에서 while 문을 돌며
수정 후 (백엔드 로직)
- 백엔드에서 데이터베이스(DB)에게 "이 유저 글이 총 몇 개야?"라고 물어보면
- DB 내부에서 최적화된 연산(COUNT())으로 단 0.001초 만에 숫자만 반환
- 브라우저로는 무거운 게시글 데이터 대신 "글 100개, 레벨 5, 80% 진행됨"이라는
- 아주 가벼운 텍스트(JSON)만 전송되므로 속도가 수십 배 이상 빨라짐
- 백엔드에서 데이터베이스(DB)에게 "이 유저 글이 총 몇 개야?"라고 물어보면
강력한 보안과 데이터 무결성 (Security)
수정 전
- 프론트엔드(브라우저)에 작성된 자바스크립트 코드는 누구나 F12(개발자 도구)를 눌러서
- 볼 수 있고 조작할 수도 있음
- 악의적인 사용자가 자신의 브라우저에서
total_count = 9999로 변조하여- 최고 레벨 아이콘을 띄우는 등 비즈니스 로직을 속일 수 있었음
- 프론트엔드(브라우저)에 작성된 자바스크립트 코드는 누구나 F12(개발자 도구)를 눌러서
수정 후
- 등급의 기준(GRADE_SETTINGS)과 계산 로직이 백엔드 서버 깊숙한 곳에 숨겨짐
- 프론트엔드는 서버가 주는 결과를 그저 화면에 보여주기만 하므로
- 사용자가 임의로 자신의 등급이나 데이터를 조작하는 것이 원천적으로 불가능해짐
단일 진실 공급원과 유지보수성 (Single Source of Truth)
수정 전
- 만약 나중에 "레벨 2 승급 기준을 글 5개에서 10개로 올리자!"라고 기획이 변경되면
- 프론트엔드 코드를 수정해야 함
- 나중에 모바일 앱(iOS, Android)을 출시하게 되면
- 각각의 앱 코드도 다 수정해야 하는 대참사 발생
- 만약 나중에 "레벨 2 승급 기준을 글 5개에서 10개로 올리자!"라고 기획이 변경되면
수정 후
- 백엔드가 '단일 진실 공급원(하나의 기준점)'이 됨
- 등급 기준이 바뀌거나 이미지가 변경되더라도
- 백엔드의
services.py코드 한 줄만 수정하면 웹사이트 - 모바일 앱 등 모든 프론트엔드 화면에 일제히 새로운 기준이 적용됨
- 유지보수가 압도적으로 편해짐
- 백엔드의
완벽한 역할 분리 (Separation of Concerns)
프론트엔드
- 오직 "사용자에게 어떻게 예쁘게 보여줄 것인가(UI/UX)"에만 집중
- 프로그레스 바 애니메이션 채우기, 잔디밭 색칠하기 등
백엔드
- 오직 "어떻게 정확하고 빠르게 데이터를 계산할 것인가(비즈니스 로직)"에만 집중 가능
오류

500오류
- 이런 어의없는 오류일때마다 화가나는군요
user_posts = Post.objects.filter(author=user, is_temp=False)
total_count = user_posts.count()
——————————————————————————————————————[비교]—————————————————————————————————————————
user_posts = Post.objects.filter(user=user, is_temp=False)
total_count = user_posts.count()- Post테이블의 user컬럼명으로 존재하기때문에 author로 하면 안됨
# models/post.py
class Post(TimeStampedModel):
...
user = models.ForeignKey(
settings.AUTH_USER_MODEL, on_delete=models.CASCADE, related_name="posts"
)
...최적화
날짜 데이터 중복 제거 (QuerySet 최적화)
- 현재 로직은 하루에 글을 10개 쓰면 post_dates 배열에 같은 날짜가 10번 중복해서 들어감
- 프론트엔드에서는 잔디밭에 '글을 쓴 날(존재 여부)'만 확인하면 되므로
- 데이터베이스 단계에서 중복을 제거하고 가져오는 것이 훨씬 효율적
# 모든 글의 날짜를 다 가져옴 (중복 발생)
post_dates = list(user_posts.values_list("created_at__date", flat=True))
——————————————————————————————————————[비교]—————————————————————————————————————————
# 🚀 distinct()를 붙여서 중복된 날짜는 하나로 합쳐서 가져옴 (트래픽 획기적 감소)
post_dates = list(user_posts.values_list("created_at__date", flat=True).distinct())진행률(%) 소수점 처리
- 나누기 연산을 하면 33.3333333333% 처럼 소수점이 길게 나올 수 있음
- JSON 응답 데이터를 깔끔하게 만들고 프론트엔드 렌더링을 돕기 위해
- 정수나 소수점 첫째 자리까지만 반올림하기
progress_percent = (earned_in_current / required_for_next) * 100
——————————————————————————————————————[비교]—————————————————————————————————————————
# 🚀 소수점 버리고 깔끔하게 정수로 표현
progress_percent = int((earned_in_current / required_for_next) * 100)기능구현
마이페이지
- 프로필 이미지 / 작성 글 목록 / 등급 / 작성 글 개수 를 한번에 내려주는 api를 작성하면
- 작성 글 목록은 페이지네이션이 필수인데 유저 프로필 정보(이미지, 등급 등)와 글 목록이
- 하나의 API로 묶여있으면 페이지를 넘길때마다 유저정보까지 중복으로 같이 불러와야함
- 작성 글 목록은 페이지네이션이 필수인데 유저 프로필 정보(이미지, 등급 등)와 글 목록이
필요 API
내 프로필/통계 정보 API
- 역할
- 프로필 이미지, 닉네임, 한 줄 소개(bio), 등급(현재 등급, 다음 등급 등)
- 총 작성 글 개수를 반환
- 역할
내 작성 글 목록 API (기존 API 재사용)
- 역할: 내가 쓴 글을 페이지네이션하여 반환
시리얼라이저
from rest_framework import serializers
# 1. 유저 기본 정보를 담을 중첩 시리얼라이저
class UserInfoSerializer(serializers.Serializer):
email = serializers.EmailField(help_text="유저 이메일")
nickname = serializers.CharField(help_text="유저 닉네임")
profile_img = serializers.CharField(allow_null=True, required=False, help_text="프로필 이미지 URL")
bio = serializers.CharField(allow_null=True, required=False, help_text="자기소개")
# 2. 유저 통계 정보를 담을 중첩 시리얼라이저
class UserStatsSerializer(serializers.Serializer):
total_post_count = serializers.IntegerField(help_text="총 작성 글 개수")
current_grade = serializers.DictField(help_text="현재 등급 정보")
next_grade = serializers.DictField(allow_null=True, help_text="다음 등급 정보 (최고 레벨이면 null)")
progress_percent = serializers.IntegerField(help_text="다음 등급까지의 진행률(%)")
# 3. 최종적으로 마이페이지에 응답할 최상단 시리얼라이저
class UserProfileResponseSerializer(serializers.Serializer):
user_info = UserInfoSerializer(help_text="유저 기본 정보")
stats = UserStatsSerializer(help_text="유저 활동 통계")view
class UserProfileAPIView(APIView):
"""마이페이지 상단에 표시될 유저 프로필 및 활동 통계 정보를 제공합니다."""
permission_classes = [IsAuthenticated]
@extend_schema(
tags=["회원관리"],
summary="마이페이지 프로필 조회",
responses={200: UserProfileResponseSerializer}
)
def get(self, request):
# 1. User 타입 지정
user = cast(User, request.user)
# 2. 서비스 레이어를 호출
stats_data = get_user_garden_stats(user)
# 3. 시리얼라이저에 넣을 원본 데이터를 딕셔너리 형태로 조립
raw_data = {
"user_info": {
"email": user.email,
"nickname": user.nickname,
"profile_img": user.profile_img,
"bio": user.bio,
},
"stats": {
"total_post_count": stats_data["total_count"],
"current_grade": stats_data["current_grade"],
"next_grade": stats_data["next_grade"],
"progress_percent": stats_data["progress_percent"],
}
}
# 4. 조립된 데이터를 시리얼라이저에 넣어 검증 및 직렬화(JSON 변환 준비)를 수행
serializer = UserProfileResponseSerializer(instance=raw_data)
# 5. 시리얼라이징된 안전한 데이터를 클라이언트(프론트엔드)에 반환
return Response(serializer.data)프로필이미지 업로드
고민
현재
- S3 저장 경로가
post/thumbnails/{today}/{unique_filename}으로 하드코딩- 이 API를 그대로 프로필 이미지에 사용하면
- 프로필 사진이 '게시글 썸네일' 폴더에 섞여서 저장됨
- 나중에 S3 용량을 관리하거나 이미지를 정리할 때 귀찮아질 것 같음
- 이 API를 그대로 프로필 이미지에 사용하면
- S3 저장 경로가
해결 방안
- 기존
PresignedUrlAPIView가 업로드 목적(게시글용인지, 프로필용인지)을- 쿼리 파라미터로 받도록 개선
- S3에 업로드한 후, 프론트엔드가 발급받은 이미지 URL을 DB에 저장할 수 있도록
UserProfileAPIView에 PATCH (수정) 메서드를 추가
- 기존
domain 파라미터 추가
# 2. 파일 이름 충돌(덮어쓰기)을 막기 위해 고유한 파일명을 생성합니다.
ext = filename.split(".")[-1]
# 확장자(ext)를 분리한 뒤, 임의의 고유 문자열(uuid)을 붙여줍니다.
unique_filename = f"{uuid.uuid4().hex}.{ext}"
# 3. S3 버킷 내에 저장될 최종 경로를 생성합니다. (예: post/thumbnails/2026/03/08/고유문자열.png)
today = datetime.now().strftime("%Y/%m/%d")
object_name = f"post/thumbnails/{today}/{unique_filename}"
——————————————————————————————————————[비교]—————————————————————————————————————————
# 2. 프론트엔드에서 보낸 도메인 값을 추출 (기본값은 'post_thumbnail'로 설정하여 하위 호환성 유지)
domain = request.query_params.get("domain", "post_thumbnail")
# 3. 파일 이름에서 마지막 '.'을 기준으로 확장자만 분리
ext = filename.split(".")[-1]
# 고유한 파일명을 생성하기 위해 uuid4를 사용하고 확장자를 다시 붙임
unique_filename = f"{uuid.uuid4().hex}.{ext}"
# 오늘 날짜를 YYYY/MM/DD 형식의 문자열로 만듬
today = datetime.now().strftime("%Y/%m/%d")
# 4. 도메인에 따라 S3에 저장될 최종 경로(폴더)를 다르게 설정
if domain == "profile":
# 프로필 이미지일 경우 user/profiles 폴더에 저장
object_name = f"user/profiles/{today}/{unique_filename}"
else:
# 기본 게시글 썸네일일 경우 기존 경로를 유지
object_name = f"post/thumbnails/{today}/{unique_filename}"프로필 수정용 시리얼라이저 추가
- 사용자가 프로필 이미지뿐만 아니라 닉네임, 한 줄 소개를 수정할 수도 있으므로
- 정보 수정을 위한 요청(Request)용 시리얼라이저를 추가
class UserProfileUpdateSerializer(serializers.ModelSerializer):
class Meta:
model = User
# 클라이언트가 수정할 수 있도록 허용할 필드들만 리스트로 명시
fields = ["nickname", "profile_img", "bio"]
# 모든 필드를 필수가 아니게(partial update) 만들어 일부만 수정할 수 있게 함
extra_kwargs = {
"nickname": {"required": False}, # 닉네임 생략 가능
"profile_img": {"required": False}, # 프로필 이미지 생략 가능
"bio": {"required": False}, # 자기소개 생략 가능
}마이페이지 정보 수정(PATCH) 추가
- PATCH 메서드를 추가하여 전달받은 S3 URL을 실제 유저 DB에 덮어씌움
def patch(self, request):
# 1. User 타입 지정
user = cast(User, request.user)
# 2. 시리얼라이저 호출
serializer = UserProfileUpdateSerializer(user, data=request.data, partial=True)
serializer.is_valid(raise_exception=True)
# 3. DB 업데이트
serializer.save()
# 4. 프로필 업데이트가 완료되었으니, 수정된 최신 상태의 프로필을 다시 응답해 주기 위해 GET 로직과 동일하게 통계를 조회
stats_data = get_user_garden_stats(user)
# 5. 응답할 데이터를 조립
raw_data = {
"user_info": {
"email": user.email,
"nickname": user.nickname,
"profile_img": user.profile_img, # 방금 업데이트된 S3 프로필 이미지 주소가 들어감
"bio": user.bio,
},
"stats": {
"total_post_count": stats_data["total_count"],
"current_grade": stats_data["current_grade"],
"next_grade": stats_data["next_grade"],
"progress_percent": stats_data["progress_percent"],
}
}
# 6. 응답용 시리얼라이저에 조립한 데이터를 넣어 검증
response_serializer = UserProfileResponseSerializer(instance=raw_data)
return Response(response_serializer.data)문제

- 401 (Unauthorized) 및 "불러오지 못했습니다" 에러
- 의미: 백엔드(서버)가 "누구인지 알 수 없어 접근 권한이 없다"고 요청을 거절한 상태
- 원인: 프론트엔드 코드 간의 저장소 키(Key) 이름 불일치 때문
- login.html 파일에서는 로그인이 성공했을 때 토큰을 access_token이라는
- 이름으로 로컬 스토리지에 저장중임
- 그런데
mypage.html파일에서는 이 토큰을 꺼내올 때 access라는 이름으로 찾고 있음 - 이름이 다르니 당연히 토큰을 찾지 못해 null 값을 서버로 보내게 되고
- 서버는 인증되지 않은 사용자로 판단하여 401 에러를 발생시킨 것
- 이로 인해 프로필 정보와 게시글을 가져오는 로직이 실패
- login.html 파일에서는 로그인이 성공했을 때 토큰을 access_token이라는
- 404 (Not Found) 에러
- 의미: 요청한 리소스(주소나 파일)를 서버에서 찾을 수 없다는 뜻
- 원인: 데이터 통신 에러와는 별개로
mypage.html에 명시된 기본 프로필 이미지 파일(/static/img/default_profile.png)이- 실제 서버 경로에 존재하지 않아서 발생했을 가능성이 매우 높음
해결
mypage.html에서 토큰을 가져오는 함수의 키 이름을 login.html과 일치
// 로컬 스토리지에서 JWT Access Token을 가져오는 헬퍼 함수
function getAccessToken() {
return localStorage.getItem('access'); // 로그인 시 저장한 키 이름에 맞게 수정하세요.
}
——————————————————————————————————————[비교]—————————————————————————————————————————
// 로컬 스토리지에서 JWT Access Token을 가져오는 헬퍼 함수
function getAccessToken() {
return localStorage.getItem('access_token'); // 로그인 시 저장한 키 이름에 맞게 수정하세요.
}-
(프로젝트 폴더)/static/img/default_profile.png 경로에 이미지 추가

-
결과

문제2

첫 번째 에러
- Cannot set properties of null (setting 'innerText')
- 원인
- 자바스크립트의 fetchUserProfile 함수가
- 통계 정보(총 게시글 수, 등급, 프로그레스 바 등)를 업데이트하려고
- totalPostCount, gradeName 등의 ID를 가진 HTML 태그를 찾았으나
- 현재 mypage.html 파일에는 해당 ID를 가진 태그들이 존재하지 않기 때문
- 태그가 없으니 null을 반환하고, null에 innerText를 넣으려다 에러가 발생한 것
- 통계 정보(총 게시글 수, 등급, 프로그레스 바 등)를 업데이트하려고
- 자바스크립트의 fetchUserProfile 함수가
- 최선의 해결책
- HTML 요소를 업데이트하기 전에, 해당 요소가 화면(DOM)에
- 실제로 존재하는지 먼저 확인하는 방어적(Defensive) 코드를 작성하는 것이 최선
- 향후 HTML 구조가 변경되더라도 자바스크립트 에러로 인해 전체 페이지가 멈추는 것을 방지
- HTML 요소를 업데이트하기 전에, 해당 요소가 화면(DOM)에
두 번째 에러
- data.forEach is not a function
- 원인
- forEach는 데이터가 배열(Array,
[ ])일 때만 사용할 수 있는 반복문 함수 - 백엔드에서 게시글 목록을 불러왔을 때
- 순수한 배열이 아니라 페이지네이션(Pagination) 정보가 포함된
- 객체(Object,
{ }) 형태로 데이터를 보내주었기 때문에 발생한 에러 - (예:
{"count": 10, "next": null, "results": [...]})
- forEach는 데이터가 배열(Array,
- 최선의 해결책
- 백엔드 응답이 순수 배열인지, 아니면 results나 data라는 키(Key) 안에
- 배열이 숨어있는 객체인지 동적으로 파악하여 어떤 상황에서든 유연하게 배열을
- 추출해 내는 로직을 추가하는 것이 가장 견고한(Robust) 최선의 방식
- 백엔드 응답이 순수 배열인지, 아니면 results나 data라는 키(Key) 안에
프로필페이지
- 기존의 로직을 이용하기에는 현재 UserProfileAPIView 여기서는 유저식별자를 받지 않기 때문에
- 다른 사용자의 닉네임을 눌렀을때 그 사용자의 정보를 가져올 방법이 없음
- 따라서 파라미터로 다른 이용자의 정보를 받아오는 로직을 받으려 하는데
고민
- 원래 닉네임을 받아서 검색을 진행하려 했지만 현재 세팅 자체가 닉네임이 unique가 아니기 때문에
- 닉네임으로 진행하기 애매하고 그렇다고 중복금지 처리를 해도
- 지금 깃허브와 디스코드 소셜로그인을 진행하면 각각 기존의 디스코드 / 깃허브의 닉네임을 가지기 떼문에
- 소셜로그인의 닉네임 중복검사를 진행할 방법이 없다
- 원래 닉네임을 받아서 검색을 진행하려 했지만 현재 세팅 자체가 닉네임이 unique가 아니기 때문에
닉네임 중복 처리
닉네임 중복 방지 헬퍼 함수
import uuid
def generate_unique_nickname(base_nickname: str) -> str:
"""
소셜 로그인 시 중복되지 않는 닉네임을 생성하는 함수입니다.
"""
# 1. 소셜 플랫폼에서 받아온 원본 닉네임을 초기값으로 설정
nickname = base_nickname
# 2. DB에 해당 닉네임이 이미 존재하는지 검사 (존재한다면 while 문 실행)
while User.objects.filter(nickname=nickname).exists():
# 3. 중복된다면, uuid를 이용해 랜덤한 4자리 영숫자를 생성
random_str = uuid.uuid4().hex[:4]
# 4. 원본 닉네임 뒤에 랜덤 문자열을 붙여 새로운 닉네임을 만듬 (예: myname_f1a2)
nickname = f"{base_nickname}_{random_str}"
# 5. 중복 검사를 통과한 고유한 닉네임을 반환
return nicknameGithubLoginService
# 10. 깃허브의 유저 고유 ID와 아이디(login)를 가져옵니다.
github_id = str(user_json.get("id"))
nickname = user_json.get("login")
...
# 12. DB 작업 중 오류 발생 시 롤백하기 위해 트랜잭션 블록을 엽니다.
with transaction.atomic():
...
if not user:
user = User.objects.create_user(
email=email,
nickname=nickname,
password=None, # 소셜 로그인이므로 비밀번호는 사용 불가 처리됩니다.
)
...
——————————————————————————————————————[비교]—————————————————————————————————————————
# 10. 깃허브의 유저 고유 ID와 아이디(login)를 가져옵니다.
github_id = str(user_json.get("id"))
nickname = user_json.get("login")
...
# 12. DB 작업 중 오류 발생 시 롤백하기 위해 트랜잭션 블록을 엽니다.
with transaction.atomic():
...
if not user:
# 고유한 닉네임 생성
unique_nickname = generate_unique_nickname(base_nickname)
user = User.objects.create_user(
email=email,
nickname=unique_nickname,
password=None, # 소셜 로그인이므로 비밀번호는 사용 불가 처리됩니다.
)
...DiscordLoginService
# 6. 유저 정보 추출 (디스코드는 id와 username, email을 반환합니다)
discord_id = str(user_json.get("id"))
nickname = user_json.get("username")
email = user_json.get("email")
...
with transaction.atomic():
social_account = SocialAccount.objects.filter(
provider="discord", social_id=discord_id
).first()
if social_account:
user = social_account.user
else:
user = User.objects.filter(email=email).first() # type: ignore
if not user:
user = User.objects.create_user(
email=email,
nickname=nickname,
password=None,
)
SocialAccount.objects.create(
user=user, provider="discord", social_id=discord_id
)
——————————————————————————————————————[비교]—————————————————————————————————————————
# 6. 유저 정보 추출 (디스코드는 id와 username, email을 반환합니다)
discord_id = str(user_json.get("id"))
base_nickname = user_json.get("username")
email = user_json.get("email")
...
with transaction.atomic():
...
if not user:
unique_nickname = generate_unique_nickname(base_nickname)
user = User.objects.create_user(
email=email,
nickname=unique_nickname,
password=None,
)
...수정에 의한 장점
- 사용자 경험 향상
- 가입 시 에러가 나거나 추가로 닉네임을 입력하는 창으로 넘기지 않고 "일단 가입을 완료"시켜줌
- 가입이 끝난 후, 원한다면 유저가 나중에 마이페이지에서 본인이 원하는 닉네임으로
- 자유롭게 바꿀 수 있도록 유도하는 것이 최신 트렌드
- 무한 루프 방지
uuid.uuid4()는 사실상 겹칠 확률이 0에 가까운 고유 값을 만들어주기 때문에- 코드가 무한 루프에 빠질 위험이 없음
- 재사용성 향상
generate_unique_nickname함수를 분리해 두었으므로- 향후 구글, 카카오, 네이버 등 다른 소셜 로그인을 추가할 때도 똑같이 함수 한 줄만 호출하면
- 중복 처리가 끝
- 사용자 경험 향상
model 수정
class User(AbstractBaseUser, PermissionsMixin, TimeStampedModel):
...
nickname = models.CharField(
max_length=50,
...
)
——————————————————————————————————————[비교]—————————————————————————————————————————
class User(AbstractBaseUser, PermissionsMixin, TimeStampedModel):
...
nickname = models.CharField(
max_length=50,
unique=True,
...
)serializer
- 타인의 프로필을 보여줄 때는 이메일을 제외한 공개용 시리얼라이저가 필요
# 5. 타인에게 보여질 공개용 기본 정보 시리얼라이저 (이메일 제외)
class PublicUserInfoSerializer(serializers.Serializer):
nickname = serializers.CharField(help_text="유저 닉네임")
# 프로필 이미지는 없을 수도 있으므로 allow_null 처리
profile_img = serializers.CharField(
allow_null=True, required=False, help_text="프로필 이미지 URL"
)
# 자기소개 역시 없을 수 있으므로 allow_null 처리
bio = serializers.CharField(allow_null=True, required=False, help_text="자기소개")
# 6. 공개용 프로필 최종 응답 시리얼라이저
class PublicUserProfileResponseSerializer(serializers.Serializer):
user_info = PublicUserInfoSerializer(help_text="유저 공개 정보")
stats = UserStatsSerializer(help_text="유저 활동 통계")service
def get_public_profile(nickname: str) -> dict:
"""
닉네임을 기반으로 유저를 찾아 공개용 프로필 데이터를 조립해 반환하는 서비스 함수입니다.
"""
# 1. DB 조회 시도
try:
# 전달받은 닉네임과 정확히 일치하는 단일 유저 객체를 가져옴
target_user = User.objects.get(nickname=nickname)
except User.DoesNotExist:
raise BaseCustomException(ErrorMessage.USER_NOT_FOUND)
# 2. 찾은 유저 객체를 기존 통계 서비스 함수에 넘겨 활동 통계 데이터(게시글 수, 등급 등)를 가져옴
stats_data = get_user_garden_stats(target_user)
# 3. View와 Serializer로 전달할 최종 데이터를 딕셔너리 형태로 조립해 반환
return {
"user_info": {
"nickname": target_user.nickname, # 유저의 닉네임
"profile_img": target_user.profile_img, # 유저의 프로필 이미지 URL
"bio": target_user.bio, # 유저의 한줄 자기소개
},
"stats": {
"total_post_count": stats_data["total_count"], # 총 작성 게시물 수
"current_grade": stats_data["current_grade"], # 현재 등급
"next_grade": stats_data["next_grade"], # 다음 등급
"progress_percent": stats_data["progress_percent"], # 다음 등급까지의 퍼센트
},
}view
class PublicUserProfileAPIView(APIView):
"""특정 닉네임을 가진 사용자의 공개 프로필 및 활동 통계 정보를 제공합니다."""
permission_classes = [AllowAny]
@extend_schema(
tags=["회원관리"],
summary="타인 공개 프로필 조회 (닉네임 기반)",
responses={200: PublicUserProfileResponseSerializer},
)
def get(self, request, nickname):
# 1. 서비스레이어 호출
raw_data = get_public_profile(nickname)
# 2. 서비스 레이어에서 가져온 딕셔너리 데이터를 시리얼라이저에 넣어 JSON 형태로 직렬화 준비
serializer = PublicUserProfileResponseSerializer(instance=raw_data)
return Response(serializer.data)결과
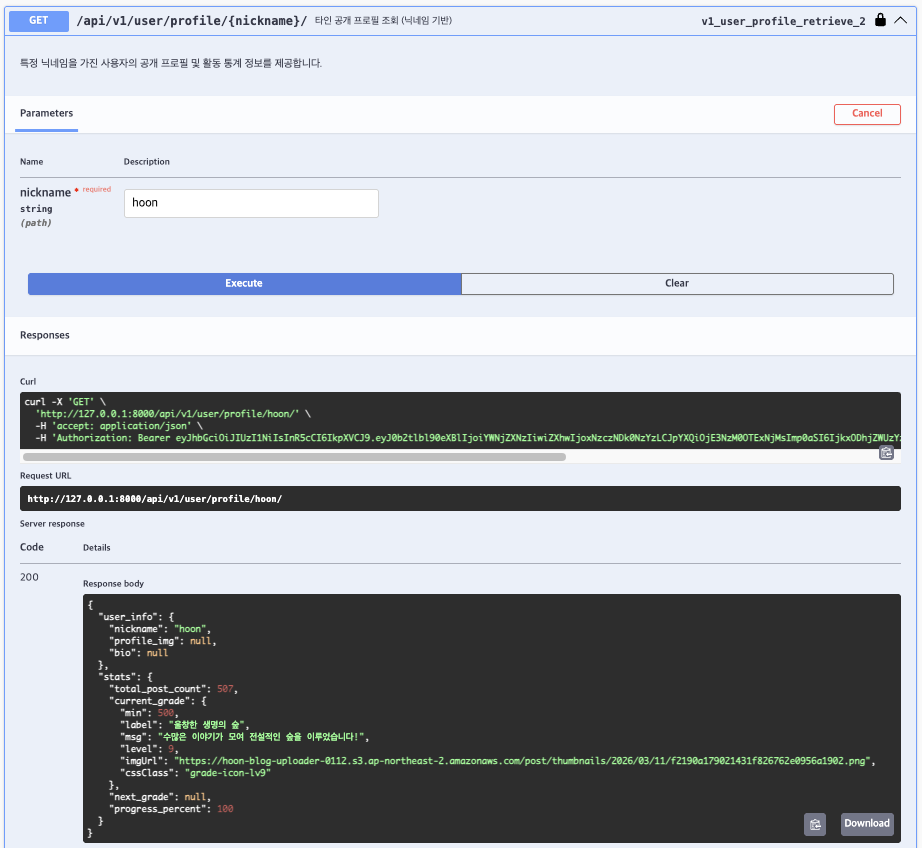
닉네임 클릭
- 아 잘못짤라서 이미지 변경은 안보이네
- 변경 잘됨 gif잘못 잘라서 안보이는 것
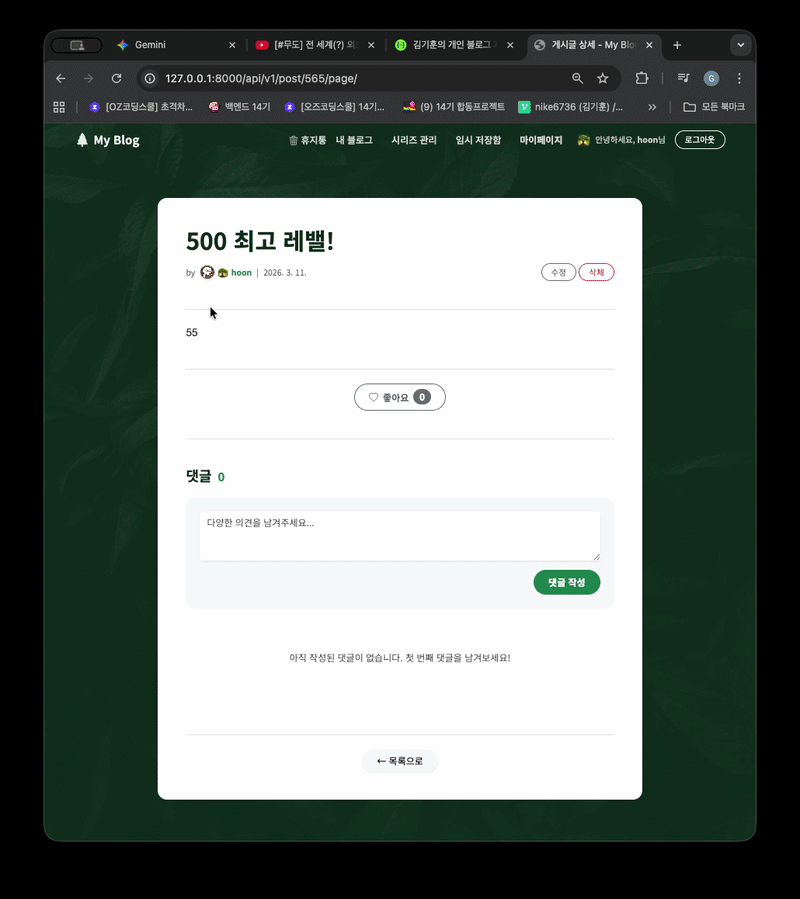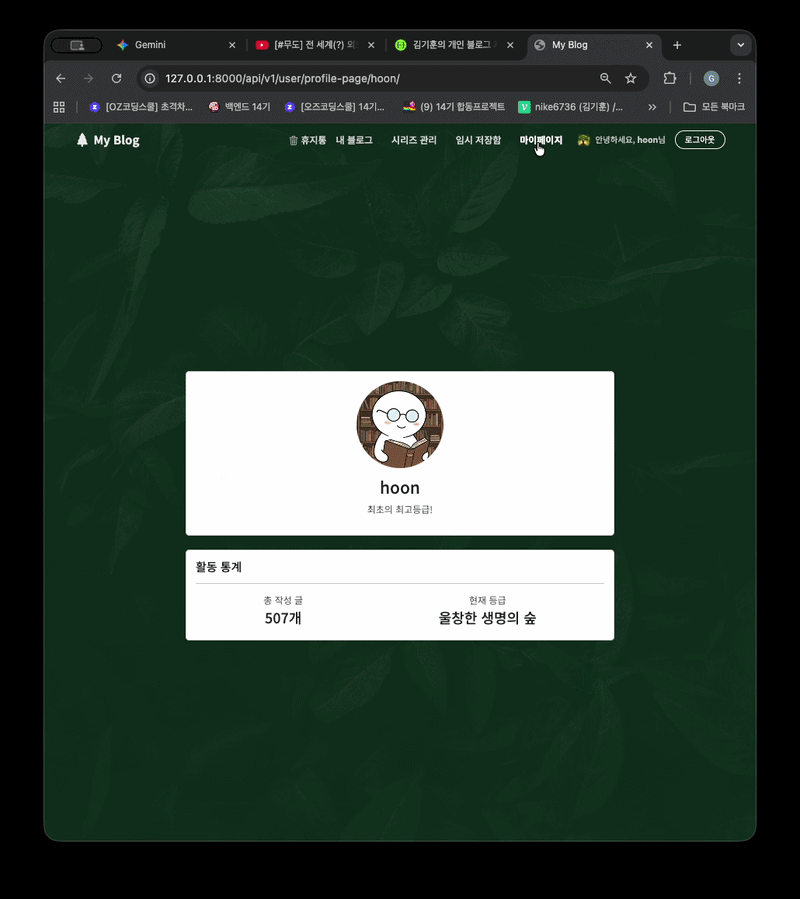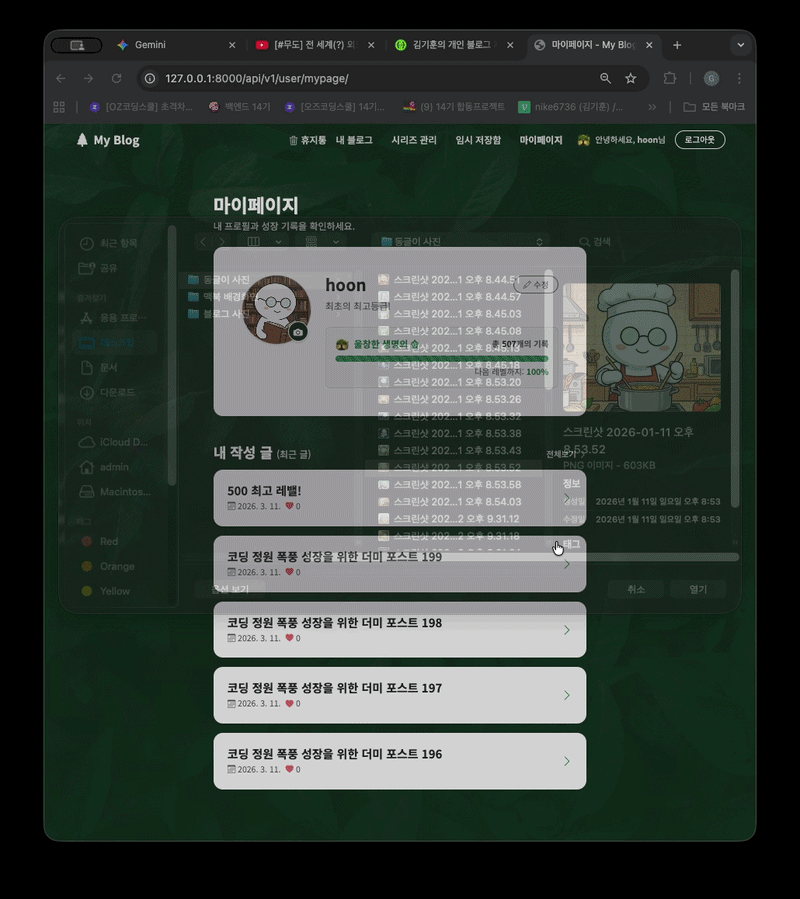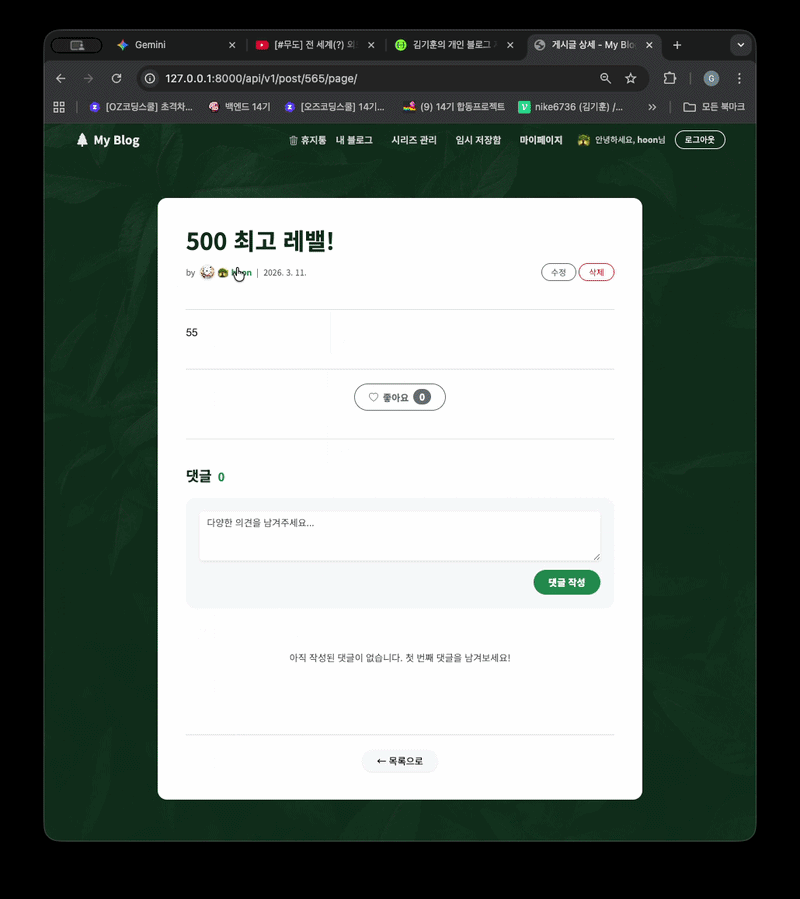
- 변경 잘됨 gif잘못 잘라서 안보이는 것
확인요망

- 아마 라이브러리 바꾸라는 듯

안녕하세요.