MongoDB 특징
- 문서 지향 데이터베이스 (Document-Oriented)
- 테이블-행(Row) 구조 대신 컬렉션(Collection)-문서(Document) 구조 사용
- 문서는 JSON과 비슷한 BSON(Binary JSON) 형태로 저장
- 스키마가 자유로워 유연한 설계 가능
- 스키마리스 (Schema-less)
- 같은 컬렉션 안에서도 문서마다 컬럼(필드)이 달라도 저장 가능
- 데이터 구조가 자주 바뀌는 서비스에 적합 (스타트업, 로그 데이터 등)
- 수평 확장(Sharding) 지원
- 데이터를 여러 서버에 나누어 저장 → 대용량 데이터 처리에 강함
- 수직 확장(서버 업그레이드)뿐 아니라 수평 확장(Scale-out)이 자연스럽게 됨
- 고성능 (빠른 읽기/쓰기)
- 다양한 인덱스(Index) 지원
- 대규모 로그, IoT, 게임 데이터 등에서 많이 활용
- 풍부한 기능
- ReplicaSet: 데이터 복제 및 장애 복구(Failover) 지원
- Aggregation Framework: SQL의
GROUP BY와 유사한 집계 기능 - Geospatial Query: 위치 기반 검색 지원
- Flexible Indexing: 복합 인덱스, 텍스트 검색 등 제공
MongoDB의 구조: - Database - Collection - Document
- Database (데이터베이스)
- MongoDB는 여러 개의 데이터베이스를 가질 수 있습니다. 각 데이터베이스는 독립적으로 관리되고 여러 컬렉션을 포함할 수 있습니다.
- 데이터베이스는 일반적으로 관련된 데이터를 그룹화하는 데 사용됩니다.
- Collection (컬렉션)
- 컬렉션은 문서(Document)의 그룹입니다. 테이블과 유사하게 데이터를 저장하며 스키마가 없어 유연한 구조를 가지고 있습니다.
- 서로 다른 Document들이 하나의 컬렉션에 저장될 수 있습니다.
- Document (문서):
- 문서는 MongoDB에서의 기본 데이터 단위로, JSON 형태의 키-값 쌍을 갖습니다.
- 각 문서는 서로 다른 구조를 가질 수 있으며, 필요에 따라 필드를 동적으로 추가할 수 있습니다.
- Document는 Collection 내에 저장되며, 각 Document는 고유한 ObjectId를 가집니다.
SQL과 MongoDB의 작동 비교
CREATE TABLE customer (
id INT PRIMARY KEY,
name VARCHAR(50) NOT NULL,
age INT
);
- age 컬럼이 INT인데 문자열 "스물다섯"을 넣으려 하면 에러 발생.
- 장점: 정합성, 데이터 품질 보장.
- 단점: 초기 설계/변경 부담 있음 (컬럼 추가하려면 ALTER 필요).
// 컬렉션 이름: users
db.users.insertMany([
// 첫 번째 문서
{
"_id": 1,
"name": "홍길동",
"age": 25
}
// 두 번째 문서 (age 대신 email, extra 필드 추가)
{
"_id": 2,
"name": "김기훈",
"email": "test@example.com",
"hobby": ["game", "music"]
}
])- 스키마 없음 (Schema-less) :
- 하나의 컬렉션(collection) 안에 있는 문서(document)들이 서로 다른 필드를 가질 수 있음.
- 타입도 다를 수 있음.
- 장점:
- 빠른 프로토타이핑 → 설계 바꾸지 않고 새로운 필드를 추가 가능.
- 비정형 데이터 저장 유연 (JSON 기반).
- 단점:
- 데이터 일관성 관리는 애플리케이션이 책임져야 함.
- 같은 “customer”인데 어떤 문서엔 age가 있고, 어떤 문서엔 없고, 타입도 다르면 나중에 통계/쿼리 힘들어질 수 있음.
- 실제 운영에서는 스키마 검증(Validation) 기능을 제공하여 SQL처럼 컬럼 제약을 강제할 수도 있다.
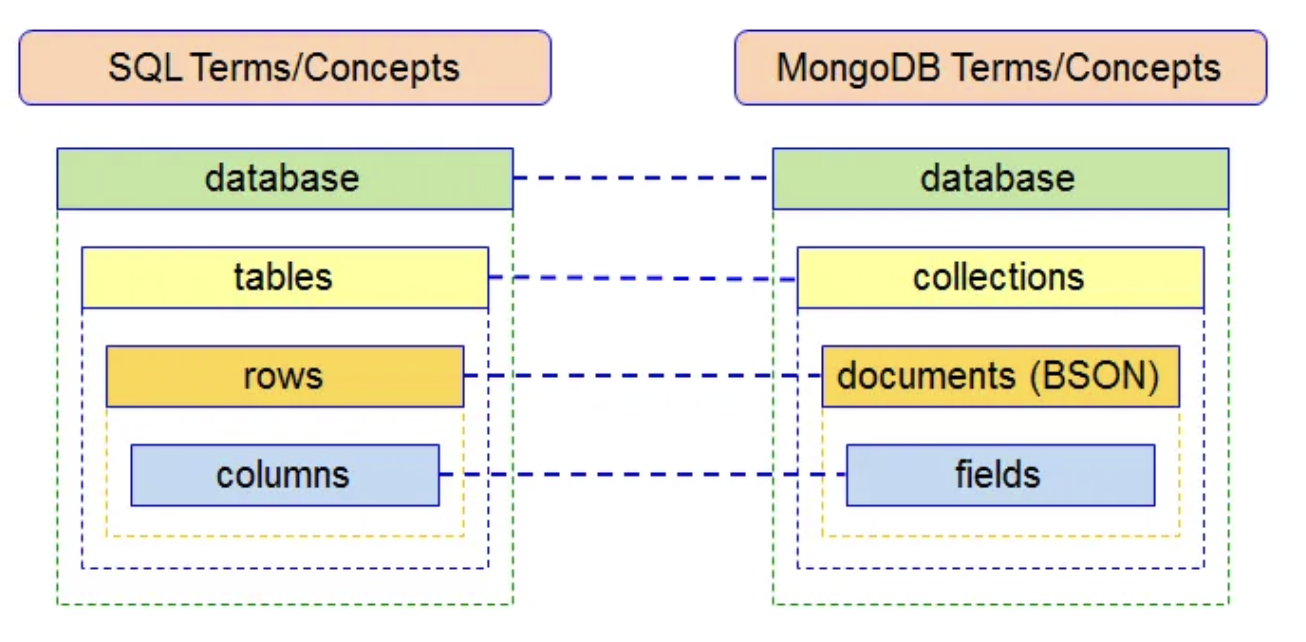
MongoDB 구조 (SQL이랑 비교)
- 유연성과 동적 스키마:
- MongoDB는 동적 스키마를 허용하여 데이터의 유연한 구조를 제공합니다.
- RDBMS는 정적인 스키마를 가지고 있어 데이터 모델을 변경하려면 일정한 절차가 필요합니다.
- 수평적 확장:
- MongoDB는 수평적 확장이 가능하며, 여러 서버에 데이터를 분산하여 대용량 데이터를 처리할 수 있습니다.
- RDBMS는 주로 수직적 확장이 일반적이며, 서버의 성능을 업그레이드하는 방식으로 확장됩니다.
- Database (DB) → SQL의 Database와 비슷
- Collection → SQL의 Table과 비슷
- Document → SQL의 Row(행)와 비슷
- Field → SQL의 Column(열)과 비슷
- Document → SQL의 Row(행)와 비슷
- Collection → SQL의 Table과 비슷
// users 컬렉션에 도큐먼트 하나 추가
db.users.insertOne({
"_id": 1,
"name": "홍길동",
"age": 25
});
db.users.insertOne({- users 컬렉션이 이미 있으면 → 그 컬렉션에 문서(document)들이 삽입
- users 컬렉션이 없으면 → MongoDB가 자동으로 컬렉션을 생성한 뒤, 문서를 넣음
- 즉, MongoDB는 컬렉션을 미리 CREATE하지 않아도,
insertOne이나insertMany를 실행하면 자동 생성
- 주의 사항
- 원하지 않는 컬렉션이 잘못된 이름으로 생성될 수도 있음 → "user" vs "users"
- 명시적으로 생성하고 싶을때
db.createCollection("users")
기본 명령어 (데이터베이스, 컬렉션 관련)
1. 데이터베이스 생성 또는 전환 : use [데이터베이스 이름]
- 지정된 데이터베이스로 전환하거나 없으면 새로 생성합니다.
2. 현재 데이터베이스 확인 : db
- 현재 사용 중인 데이터베이스를 표시합니다.
3. 데이터베이스 목록 조회 : show dbs
- 서버에 존재하는 모든 데이터베이스 목록을 보여줍니다.
4. 데이터베이스 삭제 : db.dropDatabase()
- 현재 선택된 데이터베이스를 삭제합니다.
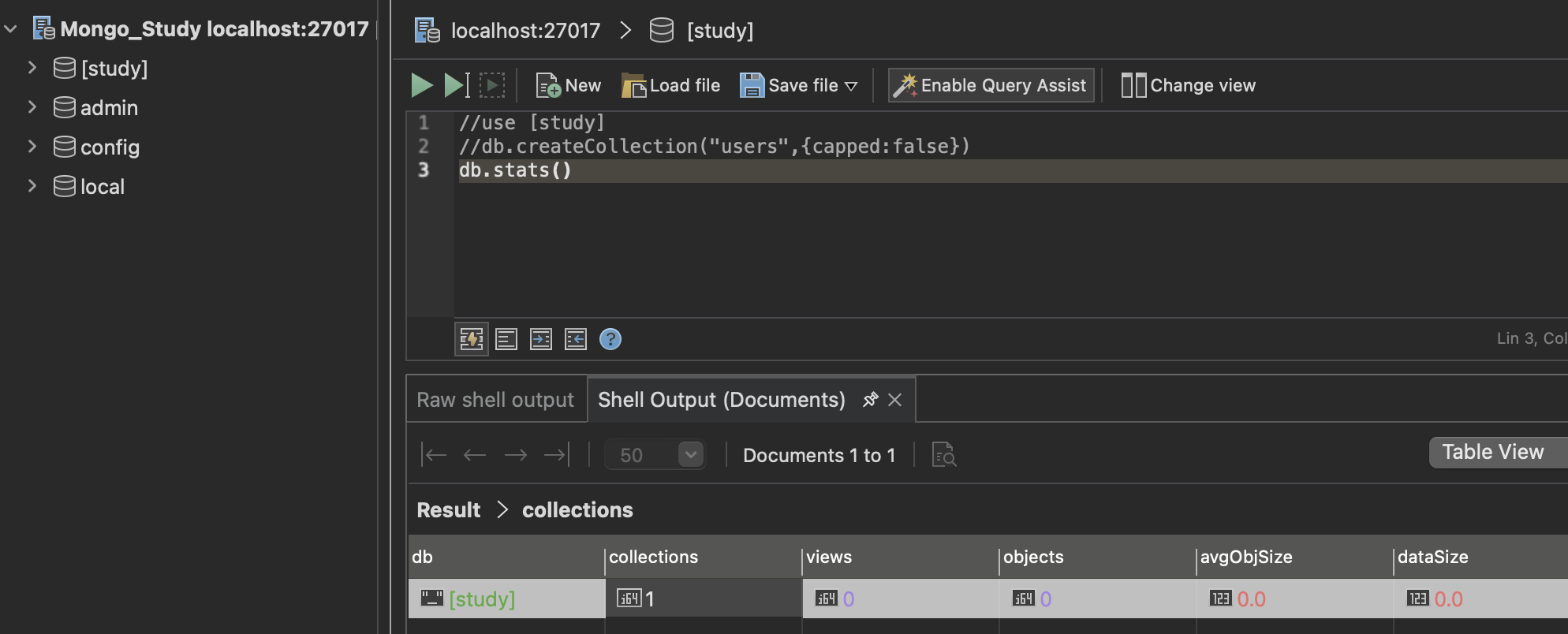
5. 데이터베이스 상태 확인 : db.stats()
- 현재 데이터베이스의 통계 정보를 제공합니다.
컬렉션 관련 명령어
1. 컬렉션 생성
db.createCollection("users", { capped: false })users라는 이름의 새로운 컬렉션을 생성- capped 옵션은 해당 컬렉션이 용량 제한이 있는지 여부를 결정
db.createCollection("log", { capped: true, size: 100000 })log라는 이름의 컬렉션을 생성하고, 이를capped컬렉션으로 지정size는 컬렉션의 최대 크기를 바이트 단위로 설정- 컬렉션의 크기가 100,000바이트를 초과하면, 가장 오래된 문서부터 새 문서로 대체
2. 컬렉션 목록 조회 : show collections
- 현재 데이터베이스에 있는 모든 컬렉션의 목록을 표시합니다.
3. 컬렉션 이름 변경 : db.users.renameCollection("customers")
users컬렉션의 이름을customers로 변경합니다.
4. 컬렉션 삭제 : db.customers.drop()
customers라는 이름의 컬렉션을 삭제합니다.
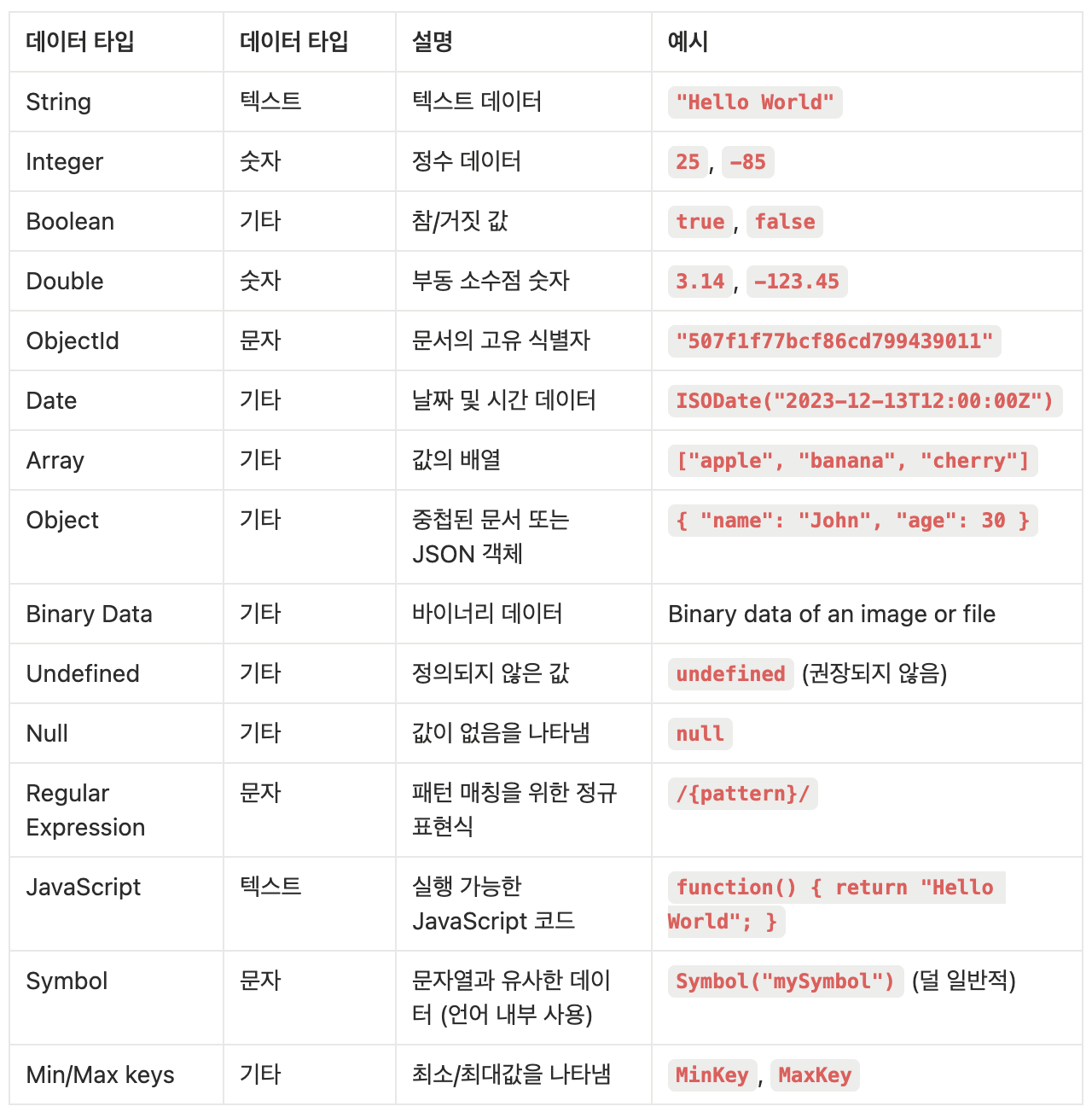
MongoDB의 데이터 타입
MongoDB 쿼리 기초
db.createCollection("users", { capped: false })생성 (Create)
// 단일 문서 삽입
db.users.insertOne({ name: "Alice", age: 30, address: "123 Maple St" })
// 여러 문서 삽입
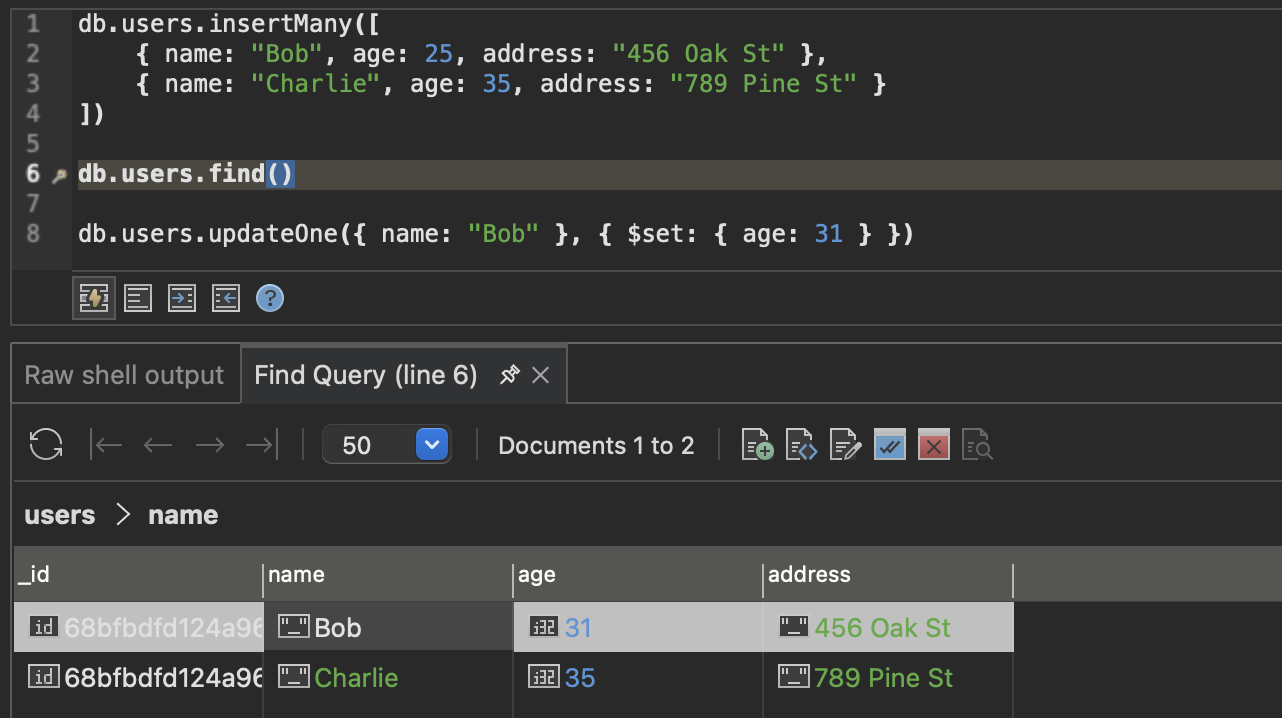
db.users.insertMany([
{ name: "Bob", age: 25, address: "456 Oak St" },
{ name: "Charlie", age: 35, address: "789 Pine St" }
])insertOne: name,age,address 가 한개의documentkey:values값으로 넣는다.- MySQL에서 사용하는 법
- INSERT INTO users (name, age, address) VALUES ('Alice', 30, '123 Maple St');
읽기 (Read) (=MySQL 비교)
// 모든 문서 조회
db.users.find() = SELECT * FROM users;
// 특정 필드 조회
db.users.find({}, { name: 1, address: 1 }) = SELECT name, address FROM users;
// 조건에 맞는 문서 조회
db.users.find({ address: "서울" }) = SELECT * FROM users WHERE address = '서울';
- db.users.find({}, { name: 1, address: 1 })
- 첫 번째 인자 = query (검색 조건) : 어떤 도큐먼트를 가져올지 필터링하는 조건
- {} → 조건이 없음 → 컬렉션의 모든 도큐먼트를 대상으로.
- 두 번째 인자 = projection (출력 필드) : 가져온 도큐먼트에서 어떤 필드를 보여줄지 선택.
- { name: 1, address: 1 } → name, address만 보여주고 나머지는 생략.
- 첫 번째 인자 = query (검색 조건) : 어떤 도큐먼트를 가져올지 필터링하는 조건
갱신 (Update)
// 특정 문서 업데이트
db.users.updateOne({ name: "Alice" }, { $set: { age: 31 } })
// 여러 문서 업데이트
db.users.updateMany({ address: "서울" }, { $set: { address: "부산" } })삭제 (Delete)
// 특정 문서 삭제
db.users.deleteOne({ name: "Alice" })
// 조건에 맞는 여러 문서 삭제
db.users.deleteMany({ address: "부산" })MongoDB 비교문법 & 논리연산
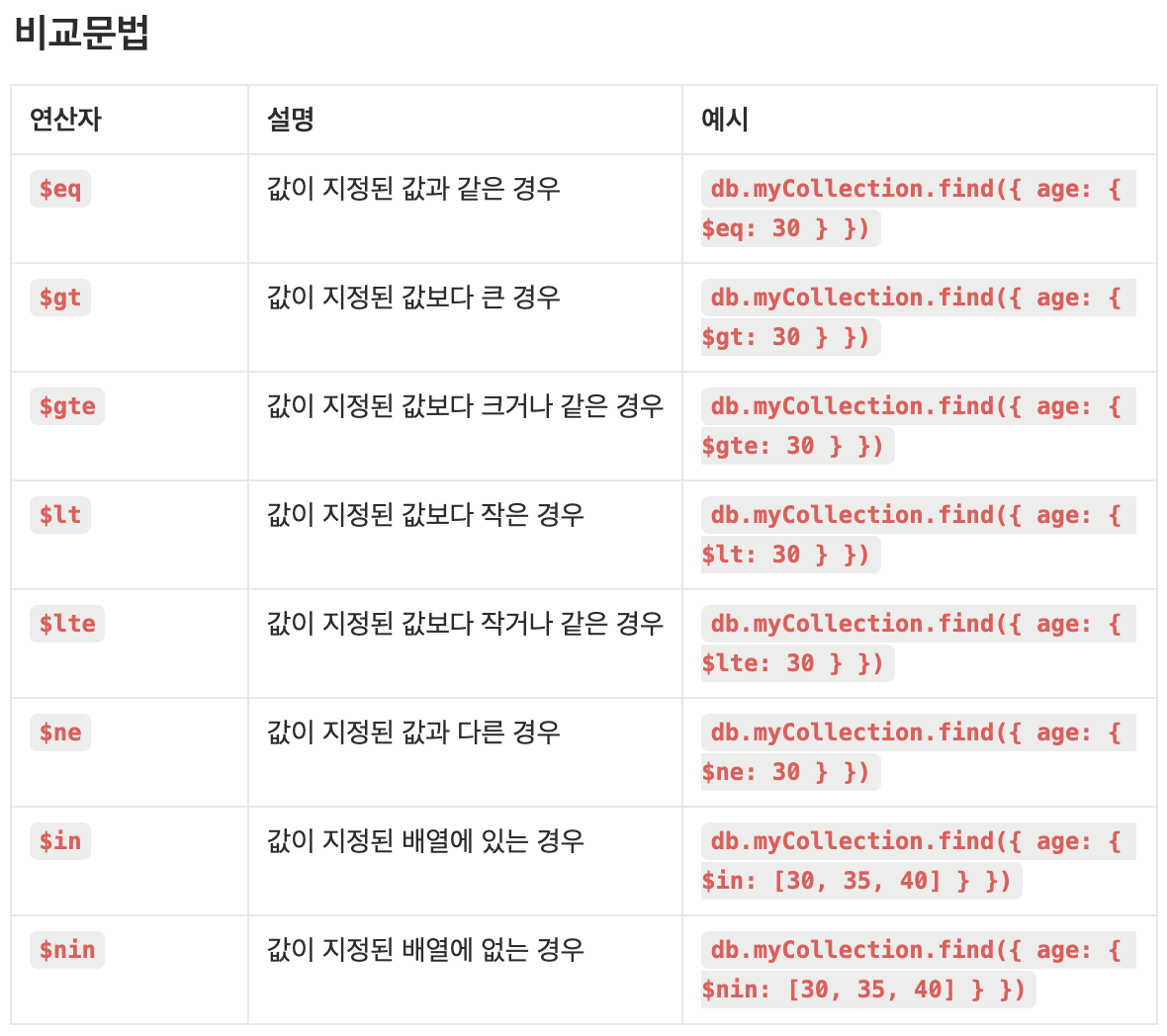
db.myCollection.find({ age: { $in: [30, 35, 40] } })
- 의미: age 필드 값이 30, 35, 40 중 하나인 도큐먼트만 가져와라
SELECT * FROM myCollection WHERE age IN (30, 35, 40);과 동일
db.myCollection.find({ age: { $nin: [30, 35, 40] } })
- 의미: age 필드 값이 30, 35, 40 중 아무것도 아닌 도큐먼트를 가져와라

db.myCollection.find({ $and: [{ age: { $gt: 20 } }, { age: { $lt: 30 } }] })
- 나이가 20보다 크고 30보다 작은 값을 찾아라
db.myCollection.find({ $nor: [{ age: 20 }, { name: "Alice" }] })
- 나이가 20이 아니고 이름이 Alice가 아닌 값들을 모두 찾아라
MongoDB Aggregation 문법
- Aggregation(집계) = 데이터를 모아서(Group) 계산하고, 변환해서 원하는 형태로 만드는 과정
- SQL로 치면 GROUP BY, COUNT(), SUM(), AVG(), JOIN, HAVING 같은 걸 합쳐놓은 느낌
기본구조
- Aggregation은 파이프라인(pipeline) 방식으로 동작 즉, 데이터를 여러 단계로 흘려보내면서 처리
db.collection.aggregate([
{ 단계1 },
{ 단계2 },
{ 단계3 },
...
])- 각 단계는 stage(스테이지)라고 부르고
- stage들은 match, $group, $sort 등)로 정의
자주 사용하는 stage
- $match → SQL의 WHERE
{ $match: { age: { $gte: 20 } } }
age ≥ 20인 도큐먼트만 필터링- $group → SQL의 GROUP BY
{
$group: {
_id: "$city", // 그룹 기준
count: { $sum: 1 }, // 개수 세기
avgAge: { $avg: "$age" } // 평균
}
}
해석 : city별로 그룹을 묶고, count와 평균 나이 계산- $sort → SQL의 ORDER BY
{ $sort: { avgAge: -1 } }
해석 : 평균 나이를 기준으로 내림차순 정렬- $project → SQL의 SELECT (필드 가공)
{ $project: { name: 1, age: 1, _id: 0 } }
해석 : name과 age만 출력, _id는 제외- $limit, $skip → SQL의 LIMIT, OFFSET
{ $limit: 5 }
{ $skip: 10 }
해석1 : 결과 도큐먼트를 앞에서 5개까지만 보여줍니다.
해석2 : 결과 도큐먼트를 앞에서 10개 건너뛰고 그다음부터 보여줍니다.- $lookup → SQL의 JOIN
{
$lookup: {
from: "orders", // 다른 컬렉션
localField: "customer_id",
foreignField: "customer_id",
as: "orders"
}
}
해석 : users와 orders 조인하기Aggregation 해보기
# 데이터
db.users.insertMany([
{ name: "홍길동", age: 25, city: "Seoul" },
{ name: "김철수", age: 30, city: "Busan" },
{ name: "이영희", age: 22, city: "Seoul" },
{ name: "박민수", age: 35, city: "Busan" },
{ name: "최지현", age: 28, city: "Seoul" }
])
# Aggregation 쿼리
db.users.aggregate([
{ $match: { age: { $gte: 25 } } }, // 25세 이상만
{ $group: { _id: "$city", avgAge: { $avg: "$age" }, total: { $sum: 1 } } },
{ $sort: { avgAge: -1 } } // 평균 나이 내림차순
])
# 결과
[
{ _id: "Busan", avgAge: 32.5, total: 2 },
{ _id: "Seoul", avgAge: 26.5, total: 2 }
]
실습
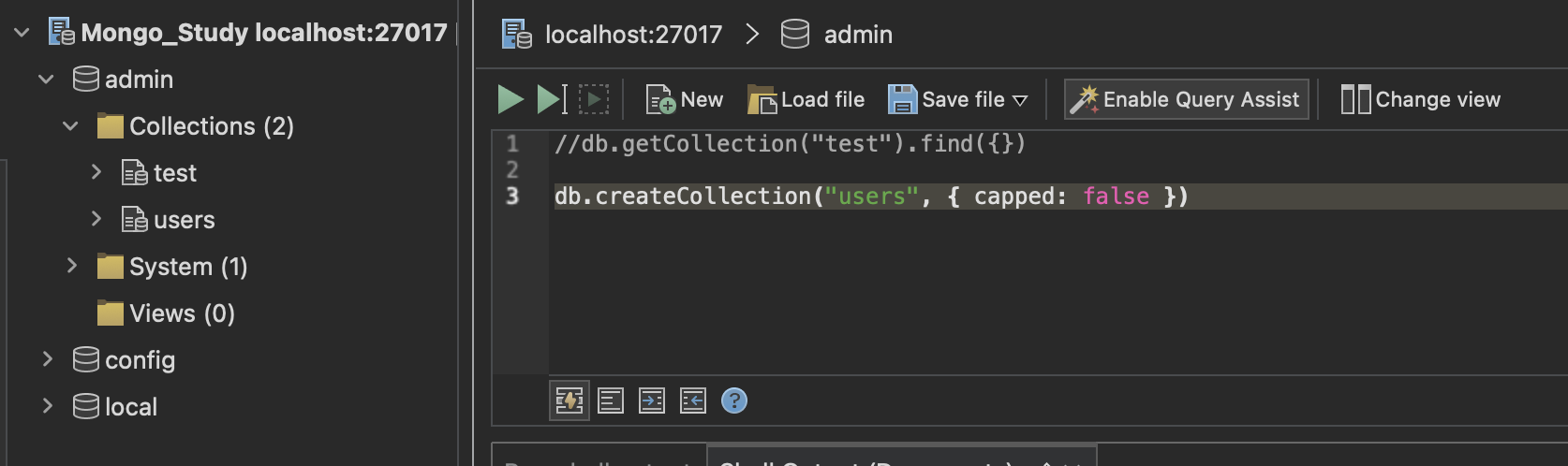
- Mongo_Study localhost:27017 → 이건 “연결(Connection)” 이름
- admin, config, local → 이게 실제 데이터베이스(Database)

안녕하세요.