Hash, Set, Heap 📌
시간 초과를 막아주는 무기
Hash (해시)
이름표가 붙은 마법의 사물함- 해시(Hash)는 데이터를 빠르게 저장하고 찾기 위해 사용하는 자료구조
- 파이썬에서는 딕셔너리(dict)라는 이름으로 이미 완벽하게 구현되어 있음
원리
Key(열쇠)를Hash Function(마법의 함수)에 넣으면 데이터를 저장할Index(사물함 번호)가 튀어나옴- 우리는 그 번호의 사물함에
Value(값)를 넣거나 빼면 됨
비유
- 학교 도서관에서 책을 찾을 때, 책 전체를 뒤지는 대신
- 컴퓨터(해시 함수)에 책 이름(Key)을 검색해서 바로 꽂혀있는 위치(Index)를 알아내는 것과 같음
시간 복잡도
- 데이터를 찾거나, 넣거나, 지우는 데 걸리는 시간이 평균적으로
- 데이터가 10만 개든 1,000만 개든 거의 1초도 안 걸려서 바로 찾아냄
언제 사용?
- "A와 짝지어진 B가 무엇인가?"처럼 쌍(Key-Value)으로 된 데이터를 다룰 때
- 리스트(List)에서
if x in list:를 사용하면 의 시간이 걸려 시간 초과가 날 때, 이를 로 줄이기 위해
Set (집합)
중복을 허락하지 않는 출입 명부- Set(집합)은 수학 시간의 집합과 같음
- 내부적으로는 Hash와 똑같은 원리로 돌아가지만, 'Value'는 없고 'Key'만 저장한다는 특징이 있음
원리
- 파이썬의
set()을 사용 - 데이터를 넣을 때 이미 존재하는 데이터인지 해시를 통해 만에 확인하고, 이미 있다면 무시
- 파이썬의
비유
- 클럽 입구에서 작성하는 출입 명부와 같음
- 철수가 10번 들락날락해도 명부에는 '철수'라는 이름이 한 번만 적힘
- 또, 명부를 훑어보지 않아도 철수가 안에 있는지 없는지 바로 알 수 있음
시간 복잡도
- 탐색, 삽입, 삭제 모두 평균
언제 사용?
- 데이터 중에서 중복을 제거해야 할 때
- "이 데이터가 존재하는가?"(Membership test)를 엄청나게 빠르게 확인해야 할 때
교집합(&),합집합(|),차집합(-)등을 구할 때
Heap (힙)
가장 센 놈만 항상 옥상에 있는 피라미드Heap(힙)은 최댓값이나 최솟값을 엄청나게 빠르게 찾아내기 위해- 고안된 완전 이진 트리(Complete Binary Tree) 구조, 파이썬에서는 heapq 모듈을 사용
원리
- 부모 노드는 항상 자식 노드보다 작다(최소 힙) 또는 크다(최대 힙)는 규칙을 유지
- 주의할 점은
전체가 완벽하게 정렬된 것은 아니다라는 것 - 오직
루트(꼭대기)에는 항상 최솟값(또는 최댓값)이 있다는 것만 보장
- 주의할 점은
- 부모 노드는 항상 자식 노드보다 작다(최소 힙) 또는 크다(최대 힙)는 규칙을 유지
비유
- 전교생 토너먼트 대회와 비슷
- 누가 2등이고 3등인지는 경기 대진표(트리)의 복잡한 구조를 다 뜯어봐야 알지만
- 전교 1등(최댓값)은 항상 맨 위 우승자 자리에 앉아있기 때문에 0.1초 만에 누군지 알 수 있음
시간 복잡도
- 최소/최대 확인:
- 데이터 삽입/삭제:
- 리스트를 매번
sort()하면 이 걸리는데, 힙은 이보다 훨씬 빠름
- 리스트를 매번
언제 사용?
- 주어진 데이터들을 다 정렬할 필요는 없고 지속적으로 가장 작은 값이나 가장 큰 값만 쏙쏙 뽑아내야 할 때
- 다익스트라(
Dijkstra) 같은 최단 경로 알고리즘을 구현할 때(우선순위 큐 역할)
그래프 탐색
그래프의 표현
- 그래프 탐색을 하려면 먼저
- 노드(정점, Vertex)와 간선(Edge)들의 연결 상태를 컴퓨터가 이해할 수 있는 데이터 구조로 저장해야 함
- 대표적으로 두 가지 방법이 존재
인접 행렬 (Adjacency Matrix)\
- 2차원 배열을 사용하여 정점 간의 연결을 0과 1로 표현(정점의 개수가 일 때, 크기의 배열이 필요)
인접 리스트 (Adjacency List)
- 각 정점마다 연결된 다른 정점들의 목록(리스트)을 저장
DFS
깊이 우선 탐색 (Depth-First Search)개념
- 시작 정점에서 출발해 한 방향으로 갈 수 있는 데까지 깊게 탐색하다가
- 더 이상 갈 곳이 없으면 가장 최근의 갈림길로 돌아와서 다른 방향을 탐색하는 방법
- 미로 찾기를 할 때 한쪽 벽만 짚고 가는 방식과 유사
자료구조
- 스택(Stack) 또는 함수의 재귀 호출(Recursion)을 사용
BFS
너비 우선 탐색 (Breadth-First Search)개념
- 시작 정점에서 가까운 정점(동일한 깊이)부터 먼저 모두 탐색한 후 그 다음으로 가까운 정점들을 탐색하는 방법
- 호수에 돌을 던졌을 때 물결이 퍼져나가는 모습을 상상하면 좋음
자료구조
- 큐(Queue)를 사용
- 파이썬에서는 성능을 위해
collections모듈의deque를 사용해야 함
라이브러리
heapq
heapq.heappush(heap, item)- 기능
- 힙(리스트)에 새로운 원소 item을 추가
- 추가한 후에도 최소 힙의 구조(가장 작은 값이 인덱스 0에 위치)를 유지
- 시간 복잡도
- 예시
- 기능
import heapq
hq = []
heapq.heappush(hq, 4)
heapq.heappush(hq, 1)
heapq.heappush(hq, 7)
print(hq) # 출력: [1, 4, 7] (1이 가장 먼저 나옴)heapq.heappop(heap)- 기능
- 힙에서 가장 작은 원소를 빼내어(pop) 반환
- 원소가 빠져나간 후에도 남은 원소들이 다시 최소 힙 구조를 유지하도록 재정렬됨
- 만약 힙이 비어있을 때 호출하면 IndexError가 발생
- 시간 복잡도
- 예시
- 기능
# 위 hq 상태: [1, 4, 7]
min_val = heapq.heappop(hq)
print(min_val) # 출력: 1
print(hq) # 출력: [4, 7]heapq.heapify(x)- 기능
- 이미 데이터가 들어있는 일반 리스트 x를 즉각적으로 최소 힙 구조로 변환
- (새로운 리스트를 반환하는 게 아니라, 기존 리스트 원본을 섞어버립니다.)
- 시간 복잡도
- 주의
- 빈 힙에 heappush를 번 반복하면 이 걸리지만
- 처음부터 리스트에 다 담아두고 heapify를 한 번 호출하면 으로 훨씬 빠름
- 예시
- 기능
arr = [5, 3, 8, 1, 2]
heapq.heapify(arr)
print(arr) # 출력: [1, 2, 8, 5, 3] (완벽한 오름차순 정렬은 아니지만, arr[0]은 무조건 1입니다)-
heapq.heappushpop(heap, item)- 가끔 연산 횟수를 조금이라도 더 줄여 최적화하고 싶을 때 사용
- 기능
- item을 먼저 힙에 넣은 다음, 가장 작은 값을 뺍니다.
- (넣으려는 값이 기존 힙의 최솟값보다 작으면, 넣자마자 그 값이 바로 튀어나옵니다.)
- 시간 복잡도
-
heapq.heapreplace(heap, item)- 기능
- 힙에서 가장 작은 값을 먼저 뺀 다음, item을 넣습니다. (힙 크기가 변하지 않을 때 유용합니다.)
- 시간 복잡도
- 기능
-
🔥
[실전 꿀팁]다중 조건으로 정렬하기 (튜플 활용)- 사용처
- Class 3 후반부에 '다익스트라(최단 경로)' 알고리즘을 풀 때 반드시 써야 하는 테크닉
- heapq는 리스트 안에 튜플(Tuple)이나 리스트를 넣으면, 첫 번째 요소를 기준으로 최소 힙을 구성함
- 이 원리를 이용하면 나중에 간선의 가중치(비용)를 기준으로 가장 가까운 노드를 뽑아내는 로직을
- 아주 쉽게 짤 수 있음
- 예시
- 사용처
import heapq
hq = []
# (우선순위, 실제 데이터) 형태로 넣습니다.
heapq.heappush(hq, (3, "사과"))
heapq.heappush(hq, (1, "바나나"))
heapq.heappush(hq, (2, "포도"))
print(heapq.heappop(hq)) # 출력: (1, '바나나') -> 우선순위(1)가 가장 작으므로 먼저 나옴!deque(데크)
"Double-Ended Queue"
- 양쪽 끝에서 데이터를 넣거나 뺄 수 있는 아주 유연하고 강력한 자료구조
- 파이썬의 collections라는 기본 모듈에 포함되어 있어 별도의 설치 없이 바로 사용가능
리스트(list) 대신 deque
- 파이썬의 일반 리스트도
append()와pop()을 지원 - 앞쪽(0번 인덱스)에서 데이터를 조작할 때 치명적인 단점 존재
- 파이썬의 일반 리스트도
리스트 (list)
- 첫 번째 요소를 삭제(
pop(0))하면, - 뒤에 남은 모든 요소들을 한 칸씩 앞으로 당겨야 함
- 데이터가 개라면 의 시간이 걸림
- 첫 번째 요소를 삭제(
데크 (deque)
- 내부적으로 '양방향 연결 리스트(Doubly Linked List)' 구조로 되어 있어,
- 앞이나 뒤 어디서든 데이터를 넣고 빼는 작업이 (거의 즉시)만에 끝남
주요 명령어
- 큐(Queue) 문제를 풀 때는 보통
append()로 넣고popleft()로 빼는 조합을 가장 많이 사용
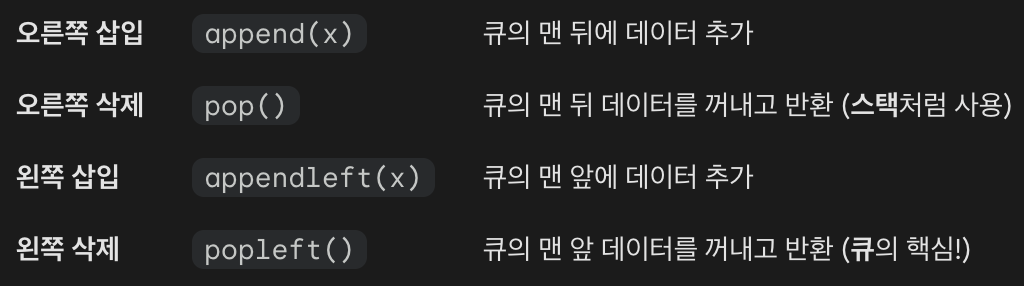
- 큐(Queue) 문제를 풀 때는 보통
사용 예시
from collections import deque
# 1. 생성
dq = deque([1, 2, 3])
# 2. 오른쪽에 추가/삭제
dq.append(4) # [1, 2, 3, 4]
dq.pop() # 4 반환, 현재 [1, 2, 3]
# 3. 왼쪽에 추가/삭제 (deque의 진가)
dq.appendleft(0) # [0, 1, 2, 3]
dq.popleft() # 0 반환, 현재 [1, 2, 3]
# 4. 기타 유용한 기능
dq.rotate(1) # 시계 방향 회전: [3, 1, 2]
dq.reverse() # 순서 뒤집기: [2, 1, 3]일반적인 파이썬 리스트(list)에서 pop(0)을 수행하면 첫 번째 요소를 삭제한 뒤 나머지 모든 요소를 한 칸씩 앞으로 당겨야 하므로 의 시간이 걸립니다. 하지만 collections.deque는 양방향 연결 리스트 형태라 양 끝의 삽입/삭제가 로 매우 빠릅니다.
rotate
- rotate()의 기본값은 오른쪽으로 회전
[1, 2, 3]에서 rotate()를 하면[3, 1, 2]
- 왼쪽으로 회전
que.rotate(-1)
- rotate()의 기본값은 오른쪽으로 회전

안녕하세요.