데이터 베이스 생성
# mydatabase라는 이름의 데이터베이스 생성
CREATE DATABASE mydatabase;
# 모든 데이터베이스 목록 조회
SHOW DATABASES;
# mydatabase 데이터베이스 사용
USE mydatabase;
# mydatabase 데이터베이스 삭제 (만약 존재하면)
DROP DATABASE IF EXISTS mydatabase;SELECT or 여러가지
기본적인 조회 - SELECT
- 모든 컬럼 조회 :
SELECT * FROM users; - 특정 컬럼만 조회 :
SELECT user_id, username, email FROM users;
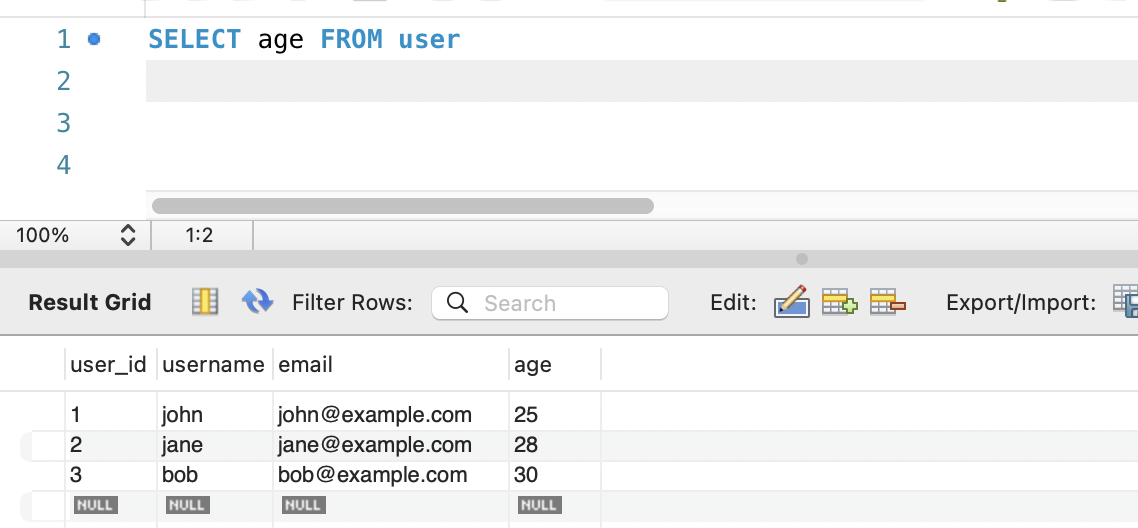
중복 데이터 삭제 - DISTINCT
SELECT DISTINCT age FROM users;: age칸에 중복되는 데이터를 한개남기고 제거
일시적으로 추가 컬럼 만들기 - AS
- 일시적인 컬럼명으로 나이 * 100 을 출력
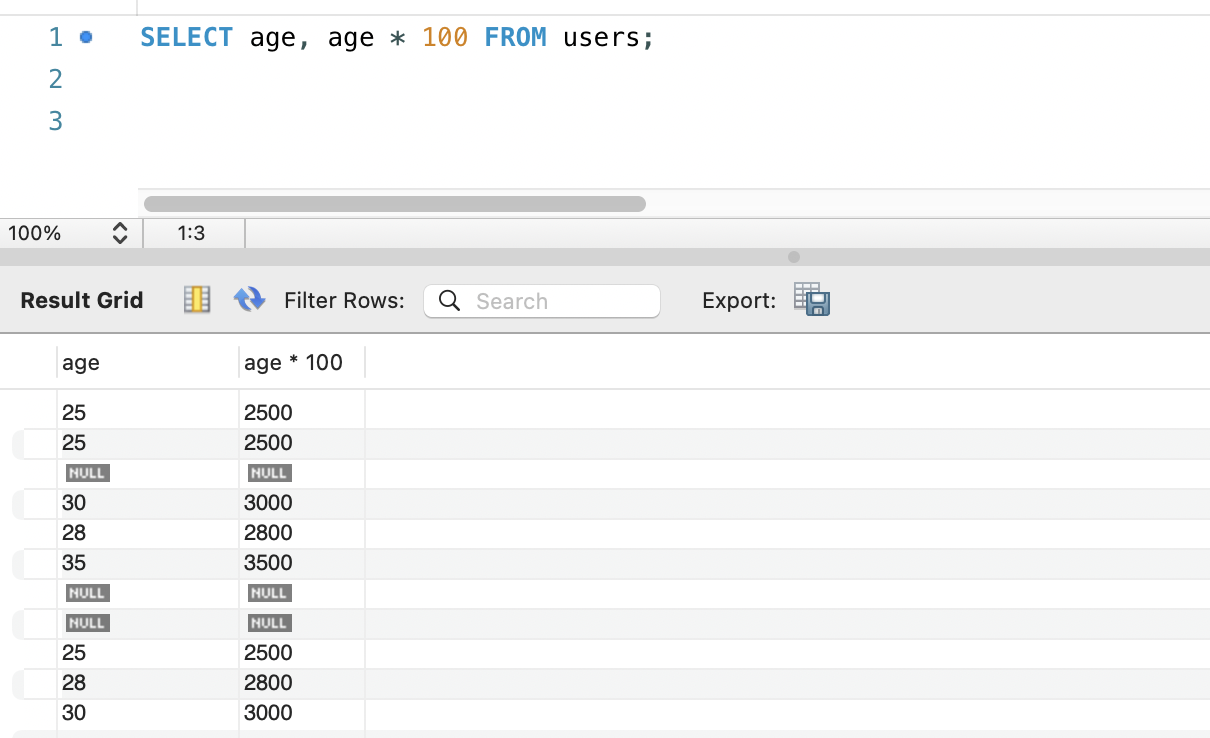
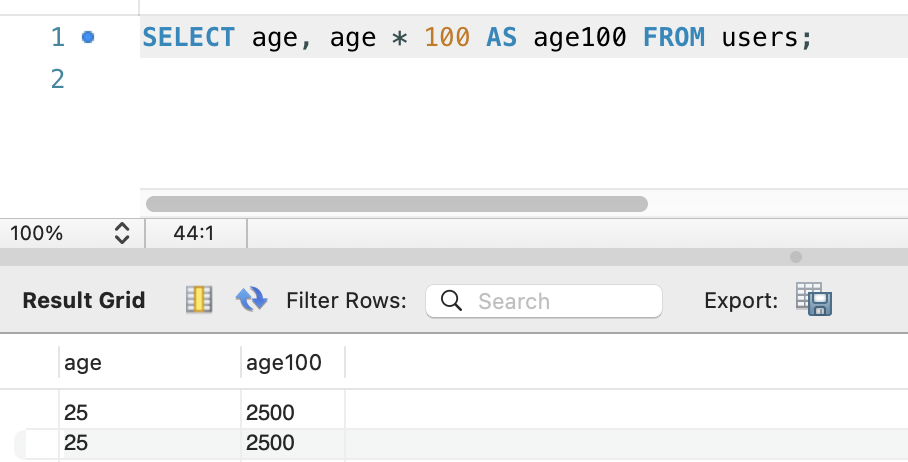
데이터 정렬하기 - ORDER BY
-
나이순으로 오름차순 정렬 =
SELECT * FROM users ORDER BY age; -
나이순으로 내림차순 정렬 =
SELECT * FROM users ORDER BY age DESC; -
여러 기준으로 정렬 (
ASC: 오름차순,DESC: 내림차순)SELECT * FROM users ORDER BY age ASC, created DESC;
조건문 - WHERE
-
특정 조건에 맞는 데이터 조회 =
SELECT * FROM users WHERE age = 30; -
특정 조건 이상 데이터 조회 =
SELECT * FROM users WHERE age >= 30; -
AND, OR를 사용한 복합 조건
SELECT * FROM users WHERE age = 33 AND name = 'Leo';SELECT * FROM users WHERE age = 33 OR name = 'Leo';
-
NOT을 사용한 부정 조건
SELECT * FROM users WHERE NOT age = 33;
-
BETWEEN을 사용한 범위 지정
SELECT * FROM users WHERE age BETWEEN 20 AND 25;
특정 개수 제한 - LIMIT
- 상위 5개의 데이터 조회 :
SELECT * FROM users LIMIT 5; - 10번째부터 5개의 데이터 조회 (페이징) :
SELECT * FROM users LIMIT 10, 5;
UPDATE users
SET username = 'top5_young_people'
WHERE age = 30
LIMIT 5;
# 어린 5명만결과 그룹핑 - GROUP BY
- 데이터를 묶어서 집계(합계, 평균, 개수 등)를 낼 때 쓰는 구문
CREATE TABLE orders (
order_id INT,
customer VARCHAR(50),
menu VARCHAR(50),
price INT
);
INSERT INTO orders VALUES
(1, '철수', '불고기버거', 5000),
(2, '영희', '치즈버거', 5500),
(3, '철수', '치즈버거', 5500),
(4, '민수', '불고기버거', 5000),
(5, '영희', '콜라', 2000);
# 결과
order_id | customer | menu | price
---------+----------+------------+------
1 | 철수 | 불고기버거 | 5000
2 | 영희 | 치즈버거 | 5500
3 | 철수 | 치즈버거 | 5500
4 | 민수 | 불고기버거 | 5000
5 | 영희 | 콜라 | 2000
SELECT menu, COUNT(*) AS order_count
FROM orders
GROUP BY menu;
# 결과
menu | order_count
-----------+------------
불고기버거 | 2
치즈버거 | 2
콜라 | 1
- 메뉴별 판매 개수
- menu 기준으로 묶어서 몇 번 주문됐는지 센 것.
여러 테이블 조인 - JOIN
- "여러 테이블을 합쳐서 하나처럼 보는 것"
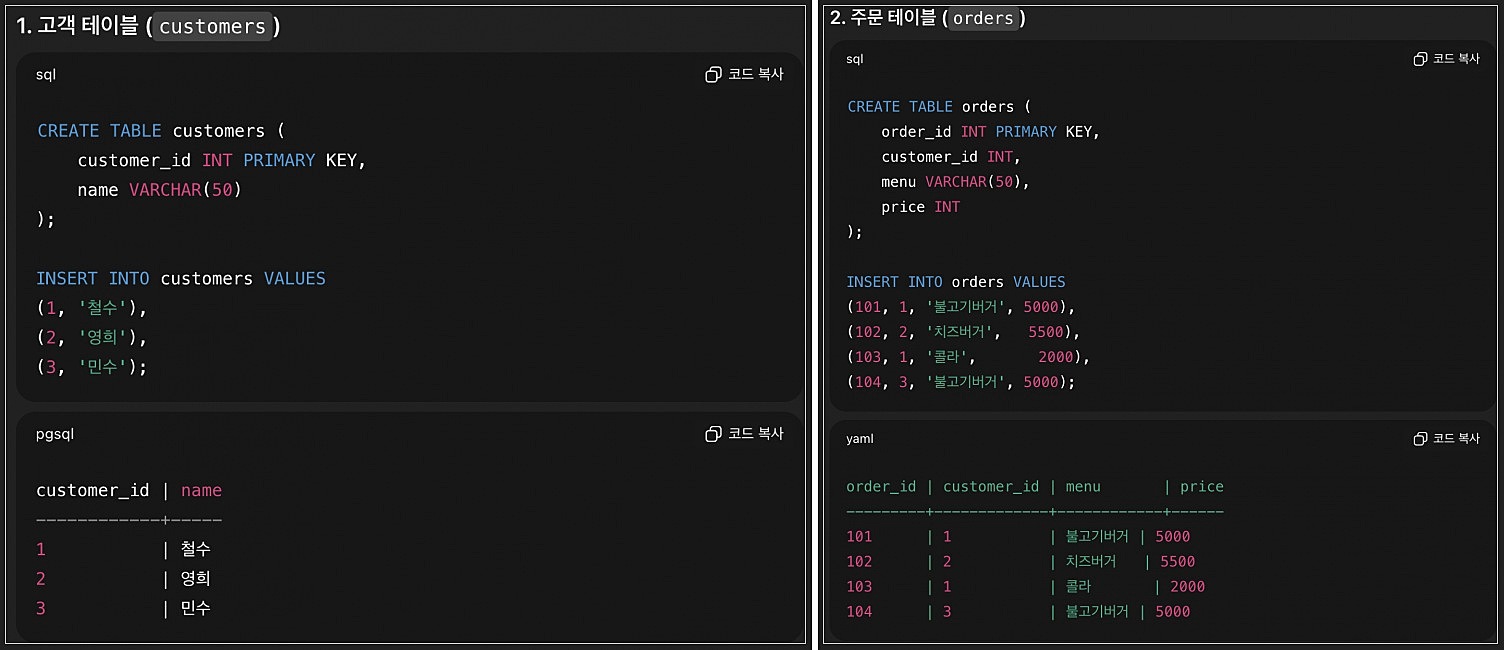
1. INNER JOIN (교집합)
SELECT c.name, o.menu, o.price
FROM customers c
INNER JOIN orders o
ON c.customer_id = o.customer_id;
# 결과
name | menu | price
-----+------------+------
철수 | 불고기버거 | 5000
영희 | 치즈버거 | 5500
철수 | 콜라 | 2000
민수 | 불고기버거 | 5000
LEFT JOIN (왼쪽은 무조건 다, 오른쪽은 매칭되면)
SELECT c.name, o.menu, o.price
FROM customers c
LEFT JOIN orders o
ON c.customer_id = o.customer_id;
# 결과
name | menu | price
-----+------------+------
철수 | 불고기버거 | 5000
철수 | 콜라 | 2000
영희 | 치즈버거 | 5500
민수 | 불고기버거 | 5000
(만약 주문 없는 고객 있었다면 → menu, price = NULL)
- 고객 목록은 전부 나오고, 주문이 없으면 NULL
3. RIGHT JOIN (오른쪽은 무조건 다, 왼쪽은 매칭되면)
SELECT c.name, o.menu, o.price
FROM customers c
LEFT JOIN orders o
ON c.customer_id = o.customer_id;- 주문이 기준 → 주문은 다 나오고, 고객 없으면 NULL
INSERT
모든 컬럼에 값을 지정하는 경우 / 모든 컬럼에 값을 지정하지 않는 경우
- 일부 컬럼에만 값을 지정하고 나머지는 기본값 또는 NULL 값을 가지도록 할 수 있습니다.
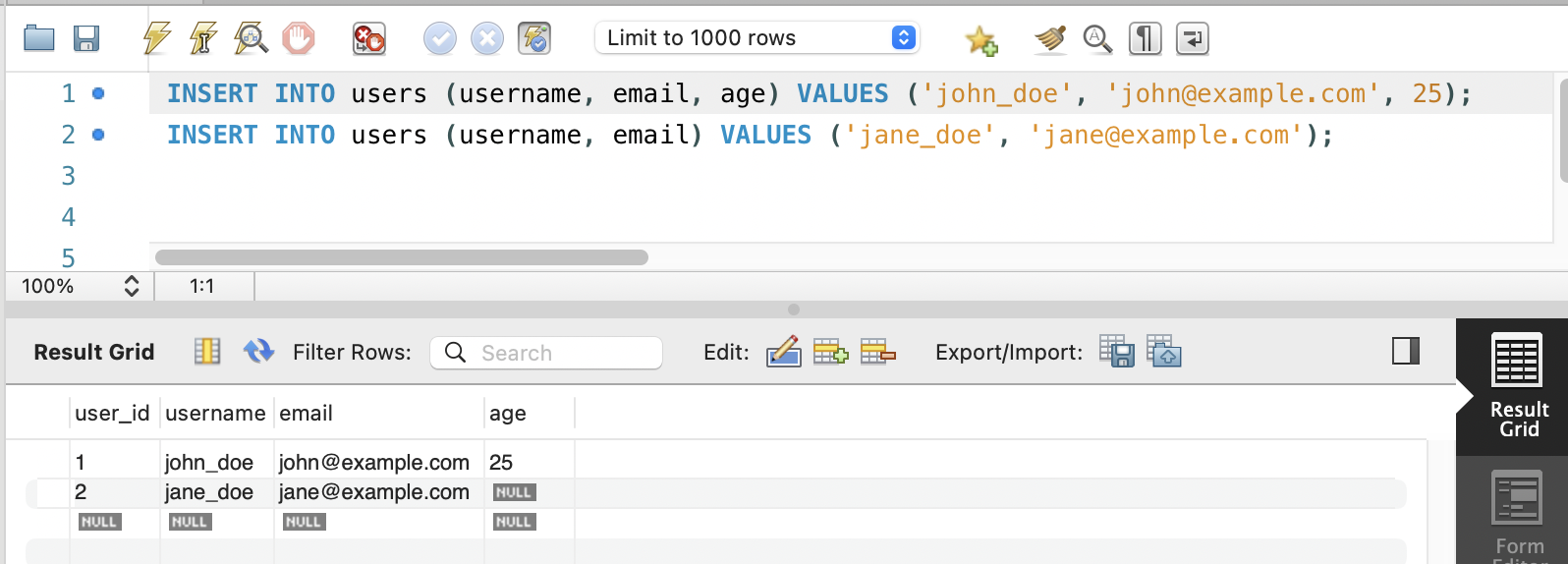
다수의 레코드 한 번에 추가
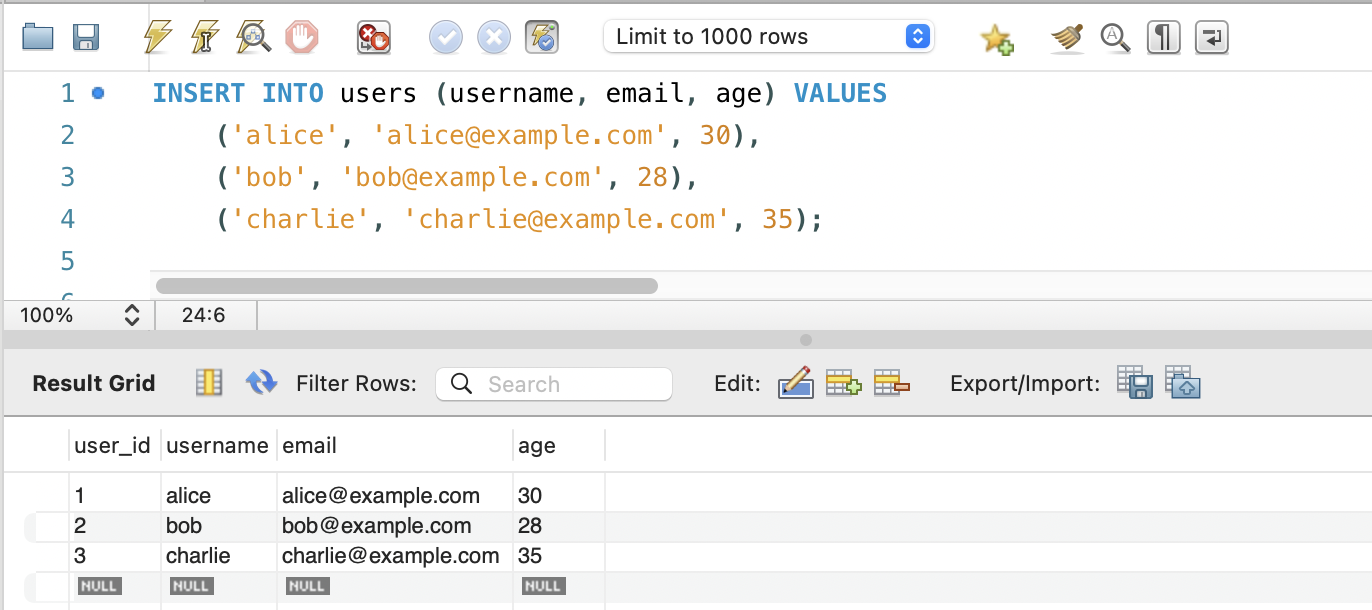
컬럼의 일부만 선택하여 추가
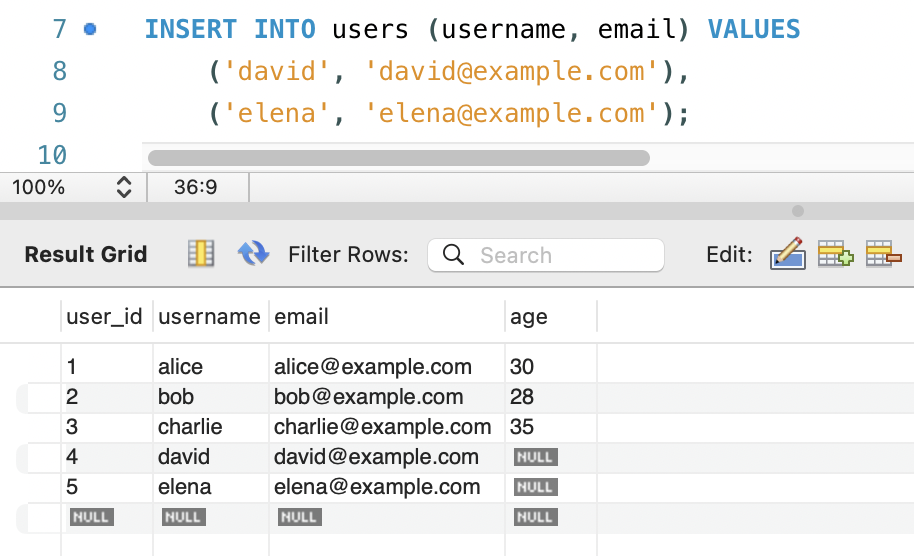
중복된 레코드 피하기(INSERT IGNORE)
- 중복된 값이 있는 경우 레코드를 추가하지 않고 건너 뛰어 에러를 방지합니다.
user_id INT PRIMARY KEY,
-- 첫 삽입
INSERT INTO users (user_id, email, name)
VALUES (1, 'hong@test.com', '홍길동');
-- 같은 user_id 중복 → 원래라면 에러
INSERT IGNORE INTO users (user_id, email, name)
VALUES (1, 'hong@test.com', '홍길순');중복된 레코드 업데이트(ON DUPLICATE KEY UPDATE)
- 중복된 값이 있는 경우 해당 레코드를 업데이트합니다.
user_id INT PRIMARY KEY,
-- user_id = 1 인 데이터 삽입
INSERT INTO users (user_id, name, age)
VALUES (1, '홍길동', 25);
-- user_id = 1 을 다시 삽입하려고 하면 충돌 발생 → 대신 UPDATE 실행
INSERT INTO users (user_id, name, age)
VALUES (1, '홍길동', 30)
ON DUPLICATE KEY UPDATE
age = VALUES(age); - “충돌이 발생하면 age를 새로 넣으려던 값(30) 으로 업데이트하라” 라는 뜻
중복된 기존의 행을 삭제하고 새로운 행을 삽입(REPLACE INTO)
user_id INT PRIMARY KEY,
-- user_id = 1 인 데이터 삽입
INSERT INTO users (user_id, name, age)
VALUES (1, '홍길동', 25);
-- user_id = 1 을 다시 삽입하려고 하면 중복이므로 기존 행 삭제 후 새 행 삽입
REPLACE INTO users (user_id, name, age)
VALUES (1, '홍길자',35);
- 기존의 행은 지워지고 (1, '홍길자',35)이 값이 들어간다.
충돌의 판단 기준
- 충돌을 판단하는 기준은 PRIMARY KEY나 UNIQUE KEY 제약 조건
- SQL에서 "중복"이라는 개념은 그냥 값이 같다고 생기는 게 아니고, 인덱스로 관리되는 키(Primary / Unique)에 위배되는 경우에만 발생
- 따라서 이 키들 기준으로만 "중복 충돌"이 감지
- SQL에서 "중복"이라는 개념은 그냥 값이 같다고 생기는 게 아니고, 인덱스로 관리되는 키(Primary / Unique)에 위배되는 경우에만 발생
네 가지 구문 비교 (AUTO_INCREMENT 상황)
- id 컬럼은 자동으로 1, 2, 3… 이렇게 순차적으로 증가하면서 값이 들어감
- 기존 행을 수정(UPDATE)하는 경우에는 id 값이 그대로 유지
- 행이 삭제되고 새로 삽입되면 → id가 새 번호로 올라감
INSERT / INSERT IGNORE / ON DUPLICATE KEY UPDATE 는 위의 상황과 같지만, REPLACE INTO 만 id값이 1올라간다.
REPLACE INTO users (id, name, age)
VALUES (1, '홍길자', 35);
# 결과
id | name | age
---+--------+----
2 | 홍길자 | 35SET 문을 사용한 수정
UPDATE users
SET username='john', email='john@example.com'
WHERE age=25 ;SET username='john', email='john@example.com': username과 email 컬럼을 새로운 값으로 바꾼다.WHERE age=25;: 나이가 25인 행만 수정한다.
UPDATE
- 기본적인 UPDATE 쿼리
UPDATE 테이블명 : 업데이트 할 테이블의 이름
SET 컬럼1 = 값1, 컬럼2 = 값2, ... : 업데이트할 칼럼과 새로운 값을 지정
WHERE 조건; : 어떤 레코드를 업데이트할지 결정하는 조건 UPDATE users
SET name = 'John'
WHERE id = 1;
# users 테이블에서 id가 1인 레코드의 이름을 'John'으로 수정
-------------------------------------------------
# 여러 레코드 동시에 업데이트
UPDATE users
SET username = 'senior'
WHERE age >= 60;
# age기준에 해당하는 여러개 수정
- SET SQL_SAFE_UPDATES = 0; (세이프 모드 비활성화)
- SELECT ROW_COUNT(); (업데이트된 레코드 수 확인)
CASE
- 조건문을 처리하는 기능 (SELECT, ORDER BY, GROUP BY 같은 구문에서 많이 사용)
- 프로그래밍 언어의 if-else 같은 역할을 해서, 조건에 따라 다른 값을 반환할 수 있다
CASE
WHEN 조건1 THEN 결과1
WHEN 조건2 THEN 결과2
...
ELSE 기본값
END
- WHEN : 조건을 적는 부분
- THEN : 조건이 참일 때 반환할 값
- ELSE : 어느 조건도 해당하지 않을 때 반환할 값(생략가능)
- END : CASE 문을 닫는 키워드
SELECT
name,
score,
CASE
WHEN score >= 90 THEN 'A'
WHEN score >= 80 THEN 'B'
WHEN score >= 70 THEN 'C'
ELSE 'F'
END AS grade
FROM students;
- ORDER BY에서 활용
SELECT name, role
FROM employees
ORDER BY
CASE
WHEN role = 'Manager' THEN 1
WHEN role = 'Staff' THEN 2
ELSE 3
END;
SUBQUERY
UPDATE products
SET price = price * 1.1
WHERE category_id IN (SELECT id FROM categories WHERE name ='Electronics');
# 다른 서브쿼리 결과에 따라 업데이트REGEXP
UPDATE users
SET email = CONCAT(email, '_new')
WHERE email REGEXP '@example\.com$';
# 정규 표현식을 활용하여 업데이트데이터 제거
- 특정 테이블에서 모든 행 삭제 : DELETE FROM users;
- 특정 조건을 만족하는 행 삭제 : DELETE FROM users WHERE age < 18;
LIMIT을 사용한 삭제
- 특정 개수 이상의 행을 삭제하지 않도록 제한
- DELETE FROM orders WHERE status = 'canceled' LIMIT 100;
JOIN을 사용한 삭제
- 다른 테이블과 조인하여 삭제
DELETE e FROM employees AS e
JOIN departments AS d ON e.department_id = d.id
WHERE d.name = 'Marketing';USING을 사용한 삭제
- 다른 테이블과 조인하여 삭제 (USING 구문 활용)
DELETE FROM employees
USING employees, departments
WHERE employees.department_id = departments.id AND departments.name = 'HR';RETURNING을 사용한 삭제 및 반환
- 삭제한 행 반환 (PostgreSQL에서 사용 가능)
- DELETE FROM users WHERE age > 65 RETURNING *;
외래키 (FOREIGN KEY ~ REFERENCES)
CREATE TABLE users (
user_id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(50)
);
CREATE TABLE orders (
order_id INT AUTO_INCREMENT PRIMARY KEY,
user_id INT NOT NULL,
product VARCHAR(100),
price DECIMAL(10,2),
CONSTRAINT fk_orders_users
FOREIGN KEY (user_id) REFERENCES users(user_id)
ON DELETE RESTRICT
ON UPDATE CASCADE
);
- 자식 테이블(orders)의 특정 컬럼이 부모 테이블(users)의 기본키(PK)나 고유키(UNIQUE) 를 반드시 참조해야 함을 의미
- 즉, 존재하지 않는 부모 데이터는 참조할 수 없다는 규칙을 강제하는 장치
- orders.user_id에 값을 넣으려면 반드시 users.user_id에 그 값이 있어야 한다.
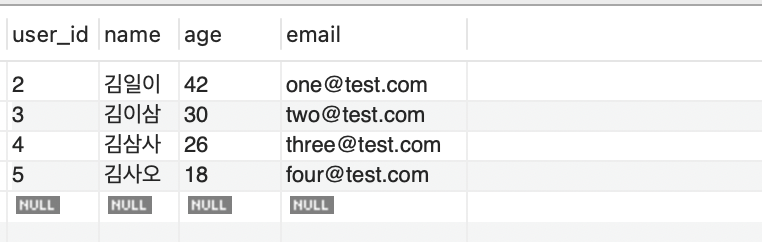
-
users 테이블에 이렇게 값이 들어가 있다면 orders 테이블의 user_id의 값에는 1이 들어갈 수 없다.
-
이름 붙이기: CONSTRAINT fk_orders_users
- fk_orders_users → 외래키 제약조건의 이름 = 수정하거나 삭제할때 편리
- 설정하지 않으면 삭제할 때 자동 생성된 이름을 찾아야 하는데 찾기 힘듬
ALTER TABLE orders DROP FOREIGN KEY fk_orders_users;
옵션
- ON DELETE RESTRICT: 부모가 삭제되면 자식이 있으면 막음
- ON DELETE CASCADE: 부모 삭제 시 자식도 자동 삭제
- ON UPDATE CASCADE: 부모 PK 값이 바뀌면 자식도 자동 수정
외래키를 삭제하고 다시 추가
# 삭제
ALTER TABLE orders DROP FOREIGN KEY fk_orders_users;
# 다시 추가
ALTER TABLE orders
ADD CONSTRAINT fk_orders_users
FOREIGN KEY (user_id) REFERENCES users(user_id);
ALTER TABLE
- 이미 만들어 둔 테이블에 나중에 외래키를 추가하기
ALTER TABLE orders # 자식테이블
ADD CONSTRAINT fk_orders_users # 제약조건이름
FOREIGN KEY (user_id) # 자식 컬럼 REFERENCES users(user_id) # 부모테이블(부모컬럼)
ON DELETE RESTRICT
ON UPDATE CASCADE;

안녕하세요.