SQLD 시험 구조
| 구분 | 과목 | 주요 내용 | 문항 수 | 난이도 |
|---|---|---|---|---|
| 1과목 | 데이터 모델링 개념 | 엔터티, 속성, 관계, 식별자, 정규화, 도메인, ERD | 20문항 | 중간 |
| 2과목 | SQL 기본 및 활용 | SELECT, GROUP BY, JOIN, 서브쿼리, DDL/DML/DCL, 인덱스 | 20문항 | 난이도 가장 중요 |
총정리 및 요약 정리
1과목 — 데이터 모델링 필수 핵심
엔터티(ENTITY)
- 정의
- 업무에서 관리해야 하는 정보 집합
- 현실 세계에서 데이터로 관리할 필요가 있는 객체(예: 고객, 주문, 상품 등)
- 특징
- 유일성, 지속성, 업무 프로세스 기반
- 반드시 속성을 가진다
- 두 개 이상의 인스턴스를 가진다
- 업무에서 필요로 하는 정보다
- 종류
- 기본 엔터티 / 중심 엔터티 / 행위 엔터티
- 엔터티 타입 분류 기준
- 발생 시점 / 유무형 개념 / 업무 규칙
엔터티 간 관계에서 “약한 엔터티(Weak Entity)”
- 다른 엔터티의 식별자를 함께 사용해야 구분 가능한 엔터티
- 부모 엔터티의 식별자와 자신의 속성을 결합해 구분된다.(주문-주문상세)
- 강한 엔터티의 식별자 필요
엔터티(Entity)와 인스턴스(Instance) 관계
- 엔터티는 인스턴스의 집합
- 엔터티는 추상적 개념, 인스턴스는 그 실제 데이터를 의미
일반화(Generalization)와 특수화(Specialization)
- 일반화는 하위 엔터티의 공통 속성을 상위 엔터티로 통합하는 것
- 특수화는 반대로 세분화하는 것
속성(Attribute)
- 엔터티가 가지는 구체적 정보
- 특징
- 하나의 엔터티는 여러 속성을 가질 수 있다
- 속성은 반드시 하나의 도메인을 가져야 한다
- 속성은 엔터티의 상태나 성질을 나타낸다
- 속성은 엔터티 내부의 구성 요소이며, 다른 엔터티의 속성을 포함하지 않는다.
- 종류
- 기본속성 / 설계속성 / 파생속성
- “파생 속성(Derived Attribute)”
- 계산된 값이나 다른 속성으로부터 유도되는 속성
- 다른 속성으로부터 계산되는 값(예: 나이 = 오늘날짜 - 생년월일)
- “파생 속성(Derived Attribute)”
- 기본속성 / 설계속성 / 파생속성
- 도메인(Domain)
- 속성이 가질 수 있는 값의 범위
- 속성의 값이 될 수 있는 유효한 범위
- 결정자(Determinant)
- 다른 속성 값을 결정하는 속성
관계(Relationship)
- 정의
- 엔터티 간 연결
- 1:1 / 1:N(가장 중요) / N:M(중간 엔터티 필요)
- “1:1”
- 한 엔터티의 한 인스턴스가 다른 엔터티의 한 인스턴스와 연결된다(사원 - 사원증)
- ‘1:N’
- 하나의 엔터티가 여러 엔터티와 연결(예를 들어 ‘부서 - 사원’)
- “1:N” 관계에서 외래키는 어디에 존재 하는가?
- 자식 엔터티
- “1:N” 관계에서는 ‘N’ 쪽(자식)에 외래키가 존재
- *“다대다(N:M)”**
- 조인 테이블(교차 엔터티)
- 다대다 관계는 중간에 별도의 연결 엔터티(Bridge Table, Mapping Table)를 만들어
- 1:N, N:1로 분리해야 한다.
- “1:1”
- 관계(Relationship)의 참여도(Cardinality)를 의미하는 것
- 1:1, 1:N, M:N 관계
- 카디널리티(Cardinality)
- “참여도 + 관계 차수”
- 참여도와 매칭 정보를 포함한다
- 필수적 관계인지(필수/선택), 몇 개 매칭되는지(1:1, 1:N 등)
- 필수/선택 여부를 포함한다
- “참여도 + 관계 차수”
식별자(Identifier)
- 식별자(Identifier)의 역할
- 식별자는 엔터티의 각 인스턴스를 구분하기 위한 속성 또는 속성들의 조합
- 식별자 관계(Identifying Relationship)의 특징
- 자식 엔터티의 외래키가 기본키 일부가 된다
- 식별자 관계는 부모의 식별자를 자식의 기본키로 포함하는 강한 종속 관계
- 식별자(Identifier) 선정 시 고려할 사항
- 유일성 / 최소성 / 안정성
- 좋은 식별자는 유일하고, 최소 속성을 가지며, 변경 가능성이 낮고 의존적이지 않아야 한다.
- 식별자(Identifier) 선정 기준
- 업무적으로 의미 있는 값이어야 한다
- 식별자는 업무적 의미, 유일성 , 불변성이 중요
- 단순해야 한다
- NULL이 없어야 한다
- 식별자 관계(Identifying)와 비식별자 관계(Non-Identifying) 차이
- 외래키가 기본키에 포함되는지 여부
- 식별자 관계는 부모의 식별자가 자식의 기본키에 포함되고, 비식별자 관계는 포함되지 않는다.
- 자식은 독립적으로 존재할 수 없다
- 식별자 관계는 부모의 키를 자식의 기본키에 포함시킨다
- 주식별자(PK): 반드시 값 존재 + 중복 없음 / 외래키(FK): 참조 무결성 유지
정규형
- 1NF: 원자값
- 모든 속성이 원자값(Atomic Value)을 가진다
- 각 속성이 더 이상 분해되지 않는 원자값이어야 한다.
- 원자값 / 반복 속성 제거 / 다중값 제거
- 2NF: 부분 함수 종속 제거(PK 일부에 종속X)
- 모든 속성이 기본키에 완전 함수 종속되어야 한다
- 2NF는 1NF를 만족하면서 부분 함수 종속이 없는 상태(부분 함수 종속 제거)
- 복합키 중 일부에만 종속된 속성이 있는 경우를 의미한다.
- 3NF: 이행적 종속 제거
- 기본키에 이행적 함수 종속이 존재하지 않는다(이행적 함수 종속을 제거)
- 비주요 속성이 다른 비주요 속성에 종속되지 않아야 한다.
- 모든 결정자가 후보키이다
- BCNF: 결정자 → 후보키만 가능
- 모든 결정자가 후보키여야 해서
정규화 (가장 자주 나옴)
- 정규화의 주요 목적
- 데이터 중복 최소화 및 이상(Anomaly)현상 방지
- 데이터의 일관성을 높이고 이상 현상을 방지하기 위한 설계 기법
- 무결성 향상
- 데이터 구조 안정화
- 정규화는 저장 공간을 감소시키는 방향
- 비정규화(De-normalization)의 주된 목적
- 데이터 접근 성능 향상
- 비정규화는 일부 중복을 허용하여 조회 속도 향상을 목적으로 한다.
- 비정규화(De-normalization)를 고려해야 하는 경우
- 조회 속도를 높여야 할 때
- 비정규화는 데이터 무결성을 일부 희생하고 조회 성능을 높이는 설계 기법
- 지나친 조인 발생
- 정규화가 너무 잘 되어 있어 성능 저하
- 통계 컬럼 추가
- 비정규화(De-normalization) 방법
- 1) 테이블 반정규화
- 두 테이블을 합치거나
- 중간 엔터티(교차 테이블)를 제거하거나
- 테이블을 통합/분할하는 것
- 2) 컬럼(속성) 반정규화
- 중복 속성 추가
- 계산된 값 미리 저장
- 코드 컬럼 통합
- 3) 관계(Join) 반정규화
- 자주 쓰는 데이터를 부모 테이블로 끌어올리는 것 등
- 1) 테이블 반정규화
- 정규화 과정에서 “함수적 종속(Functional Dependency)”
- 한 속성의 값이 다른 속성의 값을 결정하는 관계
- 함수적 종속은 X → Y 형태로 표현되며, X가 Y를 결정짓는 관계를 의미
빈출 문제
- 1:N 관계는 자식 테이블에 PK + FK
- 중복 발생 → 정규화 필요
- 조회 성능 올리기 → 반정규화
중요도 살짝
ERD
- ERD 구성요소
- 엔터티 / 속성 / 관계
- ERD 작성 시 관계의 선택성(Optionality) 표시 방법
- 점선과 실선으로 표시
- 관계선 실선 : 식별 관계
- 선택성은 “점선(선택적)”과 “실선(필수적)”으로 표현하며, 관계 참여 여부를 의미
- 점선과 실선으로 표시
- “이행적 함수 종속(Transitive Dependency)”
- 학번 → 학과코드 → 학과명
- 학번이 학과코드를 결정하고, 학과코드가 학과명을 결정한다면 학번 → 학과명은 이행적 종속
- 비식별 관계 = 점선, PK로 전달되지 않고 FK로만 존재.
모델링
- 개념적 모델링
- ‘업무 중심’으로 데이터를 추상화하는 과정
- 엔터티, 속성, 관계를 도출하고 비즈니스 규칙을 정의
- 데이터 모델링의 3단계
- 개념적 → 논리적 → 물리적 순서
- 데이터 모델링은 추상적 수준부터 구체적 수준으로 내려간다.
- 데이터 모델링의 목적
- 데이터 중복을 줄인다
- 업무 규칙을 데이터 구조로 표현한다
- 데이터 무결성을 향상시킨다
- 성능보다는 정확성과 일관성이 핵심이다. 성능은 물리 설계 단계에서 다룬다.
- “업무규칙(Business Rule)”이 모델링에 미치는 영향
- 관계의 존재 여부나 선택성을 결정한다
- 업무규칙은 엔터티 간의 관계, 필수 여부(옵셔널), 참여 제약 등을 정의하는 핵심 근거가 된다
- 논리 모델링 단계에서 주로 수행하는 작업
- 테이블/컬럼 상세 정의
- 슈퍼타입–서브타입 모델링에서 서브타입 분리 기준
- 공통 속성 / 배타적 속성 / 개별 행위
업무 규칙(Business Rule)
- 업무 제약 조건
- 엔터티 발생 조건
- 값의 허용 범위
기본키
- 기본키의 조건
- 유일성 / 최소성 / 불변성
- 개체 무결성(Entity Integrity)에 대한 설명
- 기본키는 NULL 값을 가질 수 없다
- 개체 무결성은 기본키 = NULL 불가 + 중복 불가.
- 외래키는 NULL 값을 가질 수 있다.(선택적 관계)
관계형 데이터베이스(RDBMS)
- 관계형 데이터베이스(RDBMS)의 특징
- 데이터의 무결성을 보장
- 릴레이션은 행과 열로 구성
- 릴레이션 간 관계는 외래키로 표현
서브타입(Subtype)-슈퍼타입(Supertype) 관계
- 공통 속성을 슈퍼타입에 둔다
- 서브타입은 선택적 존재가 가능하다
- 슈퍼타입은 여러 서브타입을 가질 수 있다
- 서브타입은 상호 배타적이다
- 공통 속성/행위를 묶기 위해 슈퍼타입은 필요하다.
서브쿼리
- 단일행 서브쿼리에 사용 가능한 연산자 : '='
2과목 — 1
# SELECT 기본 구조
SELECT 컬럼
FROM 테이블
WHERE 조건
GROUP BY 그룹기준
HAVING 그룹조건
ORDER BY 정렬;- 논리적 실행 순서
- FROM → WHERE → GROUP BY → HAVING → SELECT → ORDER BY
# 서브쿼리 핵심
SELECT *
FROM emp
WHERE sal > (SELECT AVG(sal) FROM emp);
- 단일 행: =, >, <
- 다중 행: IN, ANY, ALL
COUNT(*)
# GROUP BY + HAVING (최빈출)
SELECT dept, COUNT(*)
FROM emp
GROUP BY dept
HAVING COUNT(*) >= 5;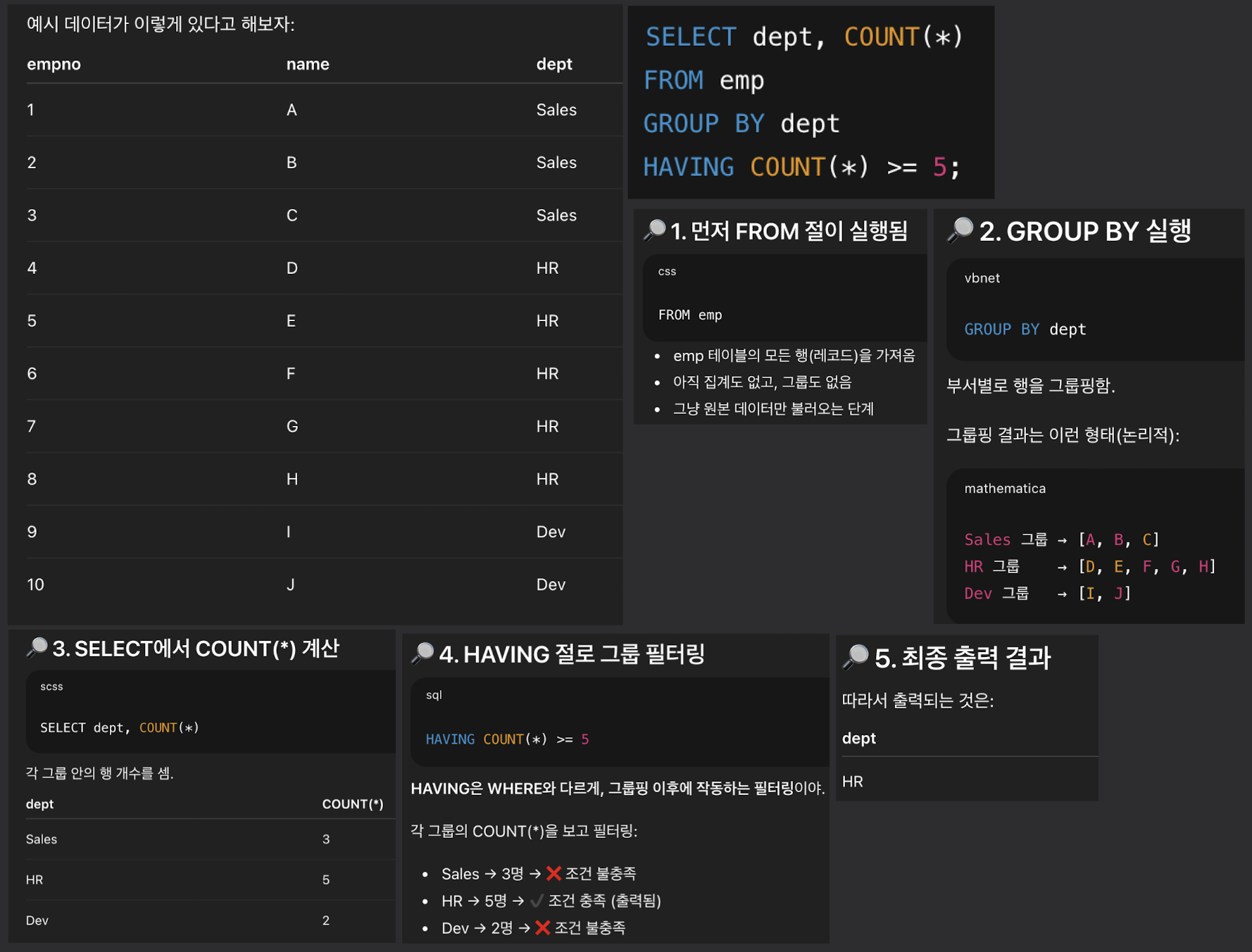
- GROUP 기준은 dept
- dept별로 데이터 묶고, 묶인 결과에 대해 COUNT(*) >= 5 필터링
- SELECT는 그룹 기준 + 집계 함수만 가능
- dept별로 데이터 묶고, 묶인 결과에 대해 COUNT(*) >= 5 필터링
SELECT deptno, COUNT(DISTINCT job)
FROM emp
GROUP BY deptno;- SQL의 결과
- 부서별로 중복되지 않는 직무(job)의 개수를 출력
- DISTINCT는 중복 제거, COUNT는 개수를 센다.
SELECT job, COUNT(*)
FROM emp
GROUP BY job
UNION
SELECT 'TOTAL', COUNT(*)
FROM emp;
- SQL의 결과
- 각 직무별 인원수와 전체 인원수를 함께 출력
- UNION은 두 SELECT 결과를 합쳐 중복을 제거하며, UNION ALL은 중복 포함.
SELECT COUNT(DISTINCT dept) FROM emp;- 부서 종류의 개수를 센다
SELECT COUNT(*)
FROM emp
WHERE deptno = 10;- SQL의 결과
- 부서 10번의 직원 수
서브쿼리
SELECT name, salary
FROM employee
WHERE salary > (SELECT AVG(salary) FROM employee);- 다음 SQL의 결과
- 평균 급여보다 높은 급여를 받는 직원 목록
- 서브쿼리가 먼저 실행되어 평균 급여를 구하고, 그보다 높은 행만 출력
Null
SELECT NVL(comm, 0) FROM emp;
- NULL 처리 관련 올바른 SQL
- NULL 값을 0으로 대체하여 출력
- Oracle의 NVL, MySQL의 IFNULL, SQL 표준의 COALESCE 함수로 NULL을 대체
- NULL은 알 수 없는 값
- 집계 함수에서 제외된다
- NVL/COALESCE로 처리한다
- WHERE에서 IS NULL로 비교한다
GROUP BY
SELECT deptno, SUM(salary)
FROM emp
GROUP BY deptno
ORDER BY SUM(salary) DESC;- 다음 SQL의 실행 결과
- 부서별 급여 합계를 내림차순으로 정렬한 결과
- GROUP BY로 집계 후, ORDER BY로 정렬.
SELECT deptno, AVG(sal)
FROM emp
GROUP BY deptno
ORDER BY 2 DESC;
- SQL 결과
- 부서별 평균 급여를 내림차순 정렬
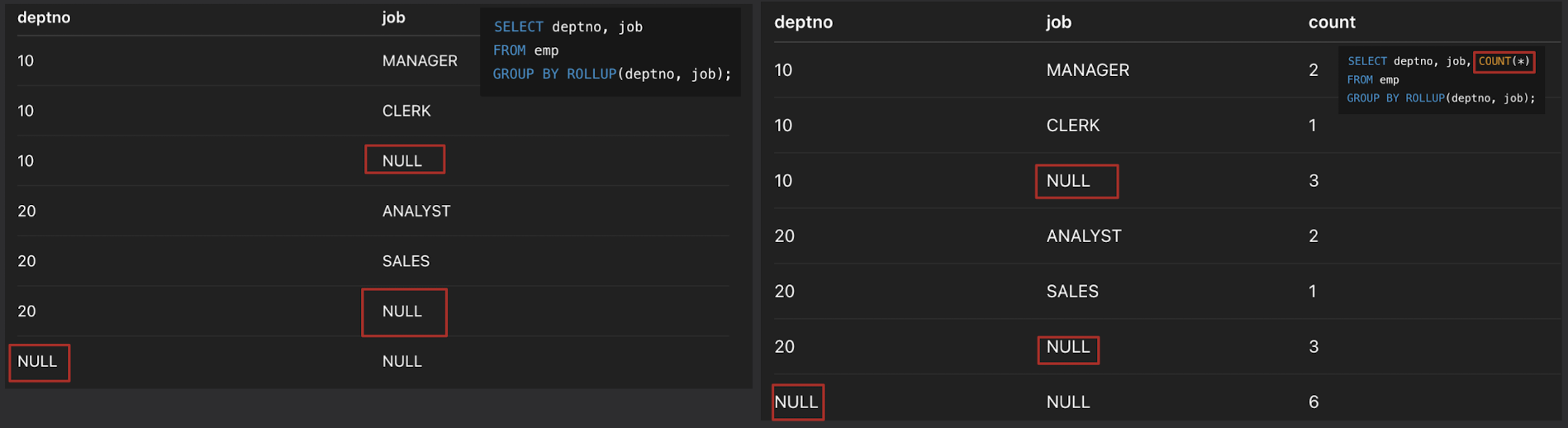
SELECT deptno, job, COUNT(*)
FROM emp
GROUP BY ROLLUP(deptno, job);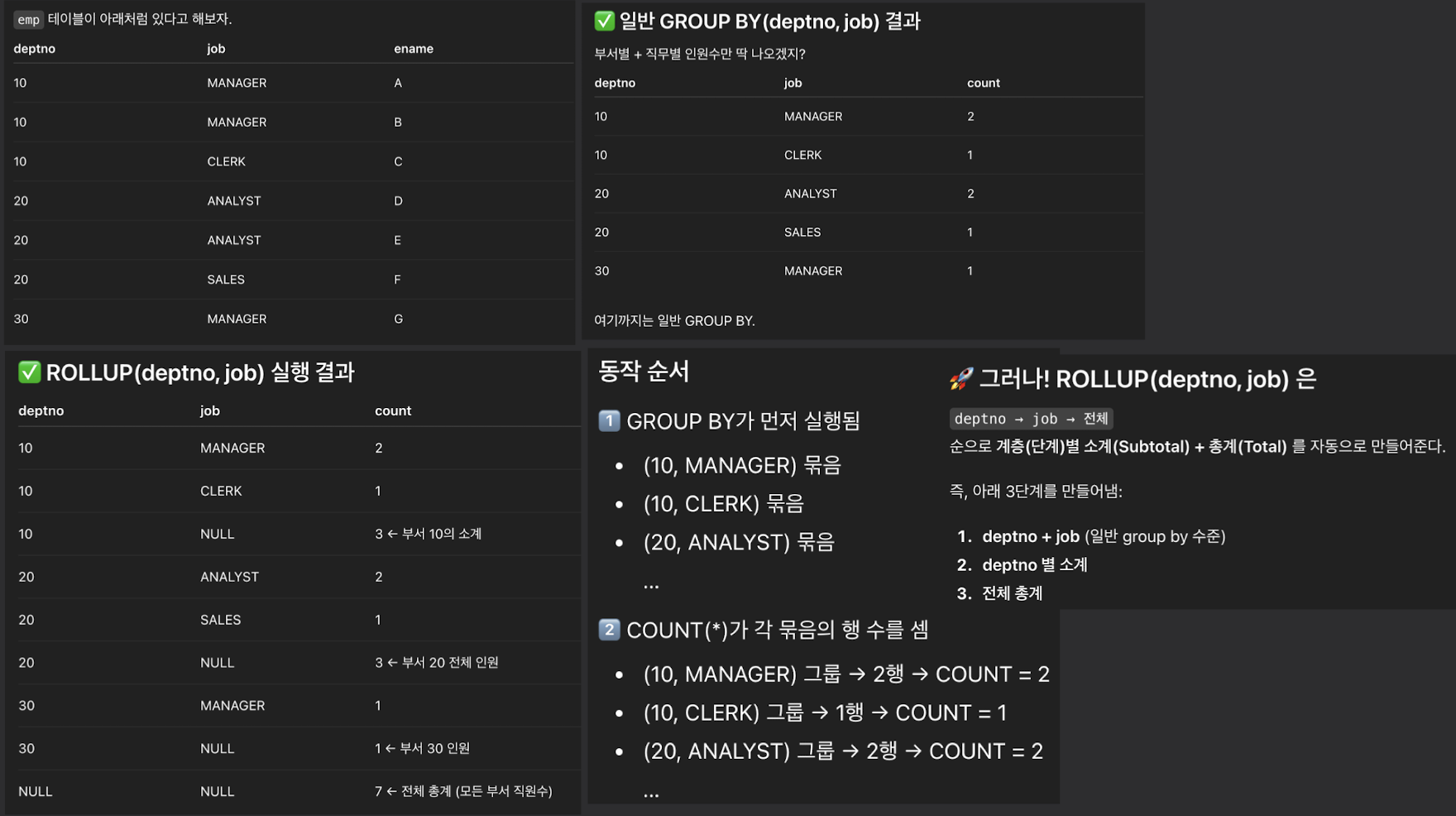
- SQL의 결과
- 부서별·직무별 집계 + 부서별 소계 + 전체 합계까지 출력
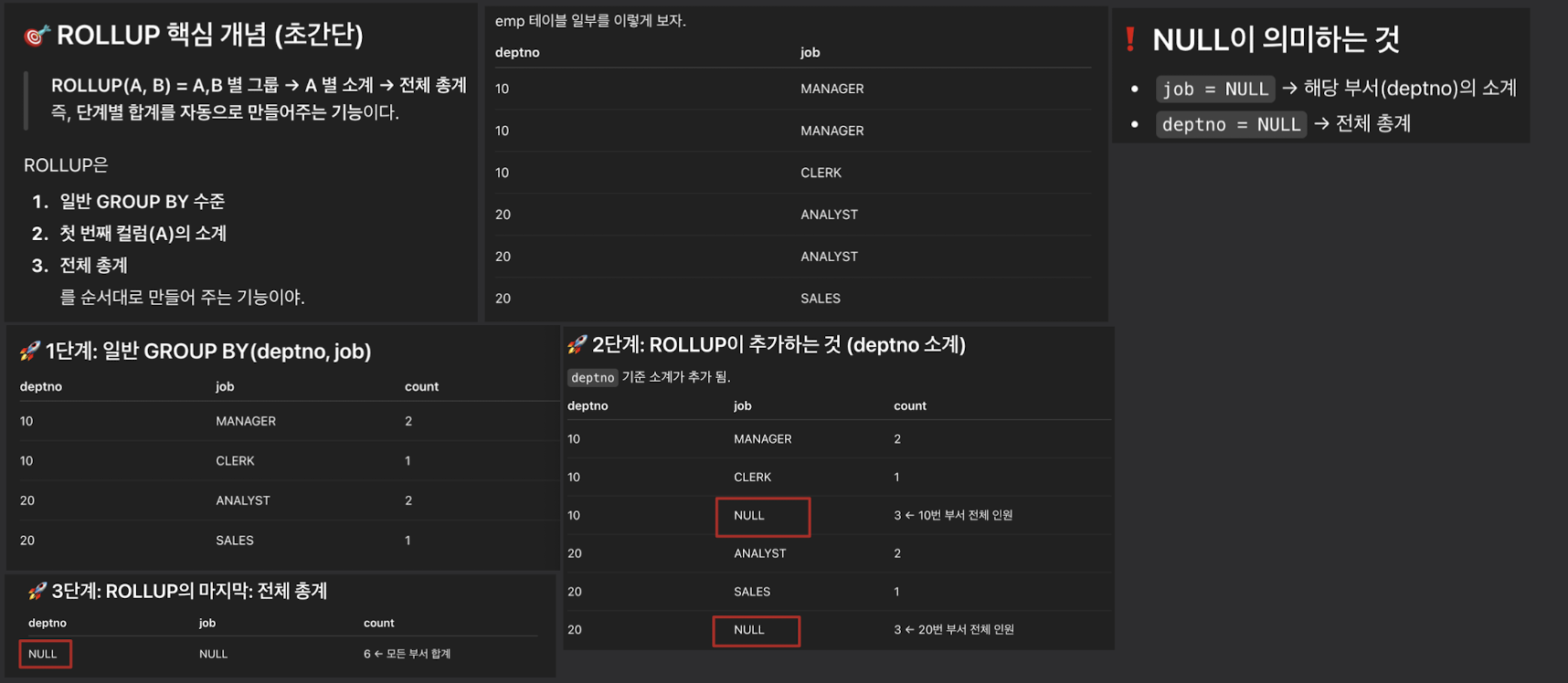
- ROLLUP은 다단계 집계를 수행한다. (GROUPING SETS의 축약형)
- ROLLUP(deptno, job)
- deptno → job → 전체
- 계층(단계)별 소계(Subtotal) + 총계(Total) 를 자동으로 만들어줌
- deptno + job (일반 group by 수준)
- deptno 별 소계
- 전체 총계
- 계층(단계)별 소계(Subtotal) + 총계(Total) 를 자동으로 만들어줌
- deptno → job → 전체
ROLL UP
CASE
SELECT name,
CASE WHEN salary >= 5000 THEN 'HIGH'
WHEN salary >= 3000 THEN 'MID'
ELSE 'LOW' END AS grade
FROM emp;
- CASE문을 활용한 올바른 SQL
- 급여 수준에 따라 등급을 분류한 결과
- CASE는 조건 분기문으로, IF-ELSE와 유사하게 작동한다.
RANK
SELECT deptno, job, RANK() OVER(PARTITION BY deptno ORDER BY salary DESC)
FROM emp;
- SQL의 결과를 설명
- 부서별로 급여 순위를 매긴 결과
- 윈도우 함수 RANK()는 PARTITION BY로 그룹을 나누고, ORDER BY로 순위를 매긴다.
SELECT empno, deptno, RANK() OVER(ORDER BY hiredate) AS hire_rank
FROM emp;
- SQL의 결과
- 입사일이 빠를수록 낮은 순위(1부터)로 부여
- RANK()는 순위를 매기되 동점이 있으면 같은 순위, 이후 순위는 건너뛴다.
ROWNUM
SELECT *
FROM emp
WHERE ROWNUM <= 5;
- ROWNUM을 이용해 상위 5개 데이터를 출력하려면
- ROWNUM은 SELECT 출력 순서 기준으로 붙는다.
- 정렬 후 순번을 매기려면 인라인뷰 안에 ORDER BY를 먼저 넣어야 한다.
CUBE
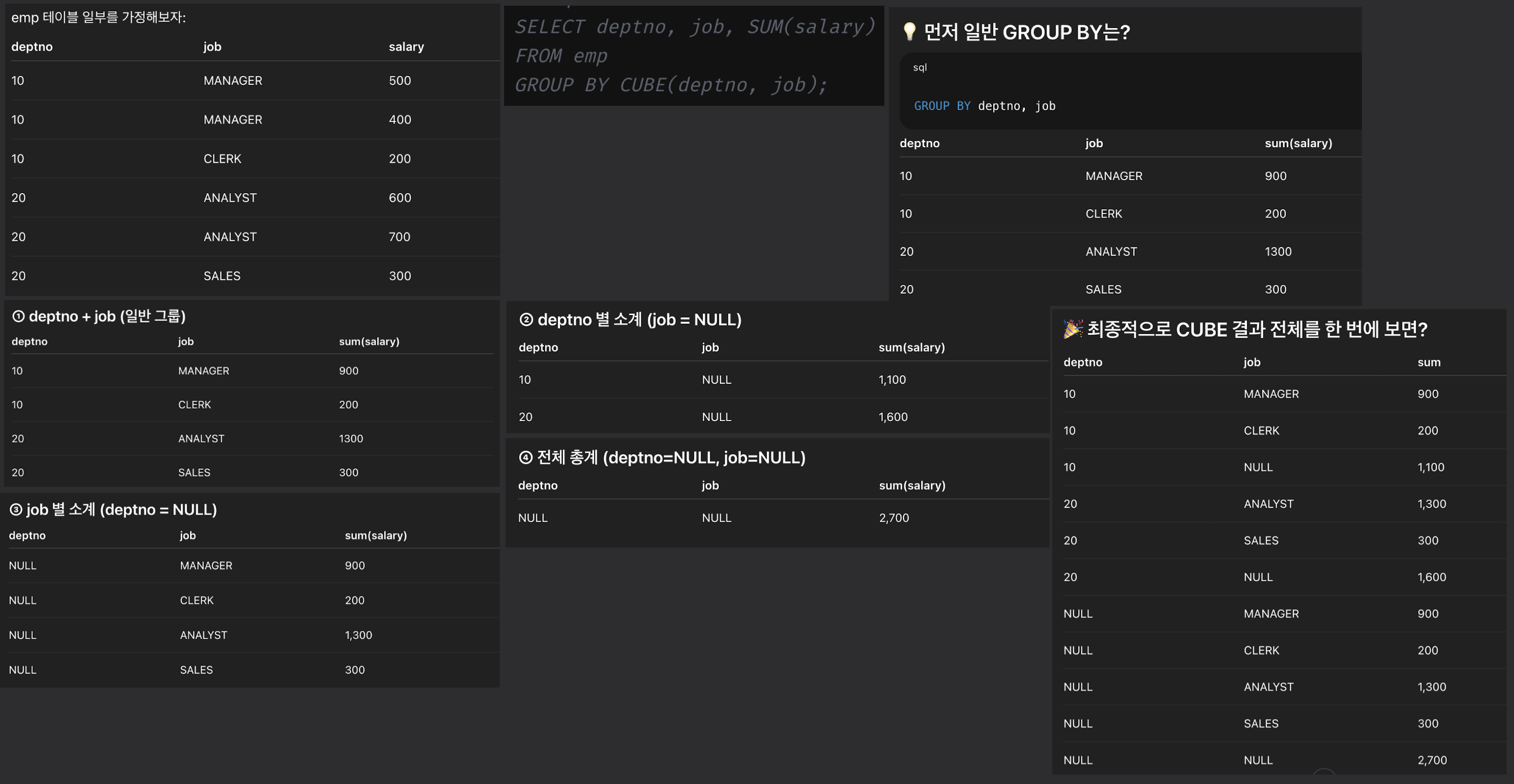
SELECT deptno, job, SUM(salary)
FROM emp
GROUP BY CUBE(deptno, job);
- SQL의 결과
- 부서별, 직무별, 부서+직무별, 전체합계까지 모든 조합의 집계를 수행
- CUBE는 가능한 모든 조합의 그룹핑을 수행하는 다차원 집계 함수
2과목 - 2
인덱스(Index)
- 인덱스(Index)의 효과(인덱스에 대한 설명)
- 검색 속도 향상
- 데이터 변경(INSERT/UPDATE/DELETE)은 느려질 수 있다.
- 카디널리티가 높을수록 효율적이다
- 카디널리티가 높음 = 중복도 높음
- 검색 속도 향상
- 모든 컬럼에 인덱스를 만들면
- 저장 공간 증가 / INSERT 성능 저하 -> 즉, 선택적으로 사용 권장
- 인덱스가 잘 걸리는 컬럼 특징
- 조건절에 자주 등장
- 정렬/조인에 자주 사용
- 고객 ID(고유값)
- 카디널리티(중복도) 높을수록 인덱스 효율 ↑
- 인덱스가 안 걸리는 경우
- %값으로 시작하는 LIKE
- 함수 적용된 컬럼
- 데이터 변화 많으면 오히려 느려짐
- 인덱스가 사용되는 경우
- COL LIKE 'abc%'
- COL BETWEEN 10 AND 20
- COL = 10
- PK 컬럼 검색
DDL / DML / DCL 구분
- DDL: CREATE, ALTER, DROP, TRUNCATE
- DML: INSERT, UPDATE, DELETE
- DCL: GRANT, REVOKE
- TCL: COMMIT, ROLLBACK
제약조건 (Constraints)
- PK
- FK
- UNIQUE
- CHECK
- NOT NULL
- 시험 포인트
- PK = UNIQUE + NOT NULL
- FK는 참조 무결성 체크
- 시험 포인트
2과목 - 3
DISTINCT
- DISTINCT가 적용되는 범위
- 전체 SELECT 리스트
WHERE
- UPDATE 문법에서 WHERE를 생략하면?
- 모든 행 변경
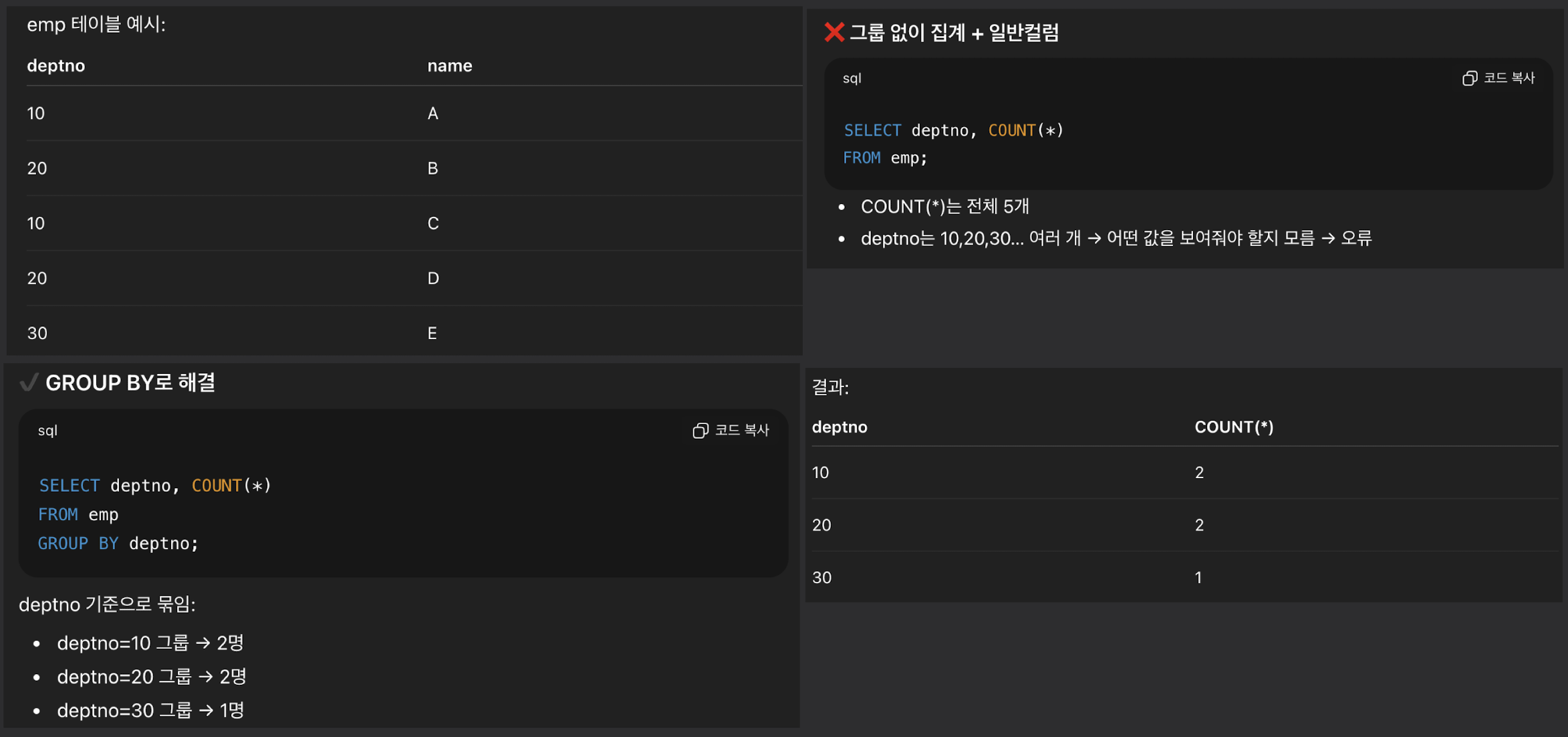
GROUP BY
- GROUP BY 사용 조건
- GROUP BY에 나온 컬럼은 SELECT에도 있어야 한다
SELECT dept, empno, COUNT(*) FROM emp GROUP BY dept;- SELECT에 일반 컬럼(empno)이 있으려면 GROUP BY에 있어야 한다.
HAVING
- WHERE 절과 HAVING 절의 차이점
- WHERE은 그룹 전 필터링, HAVING은 그룹 후 필터링
- WHERE은 행 단위 필터링, HAVING은 GROUP BY 이후 집계 결과 필터링
SELECT deptno FROM emp HAVING COUNT() > 5;틀린 이유- HAVING은 GROUP BY 없이 단독 사용 불가(집계 함수도 없음).
- HAVING 절이 필요한 이유: 집계 후 조건 필터링
- HAVING은 GROUP BY 없이 단독 사용 불가(집계 함수도 없음).
JOIN(=INNER JOIN)
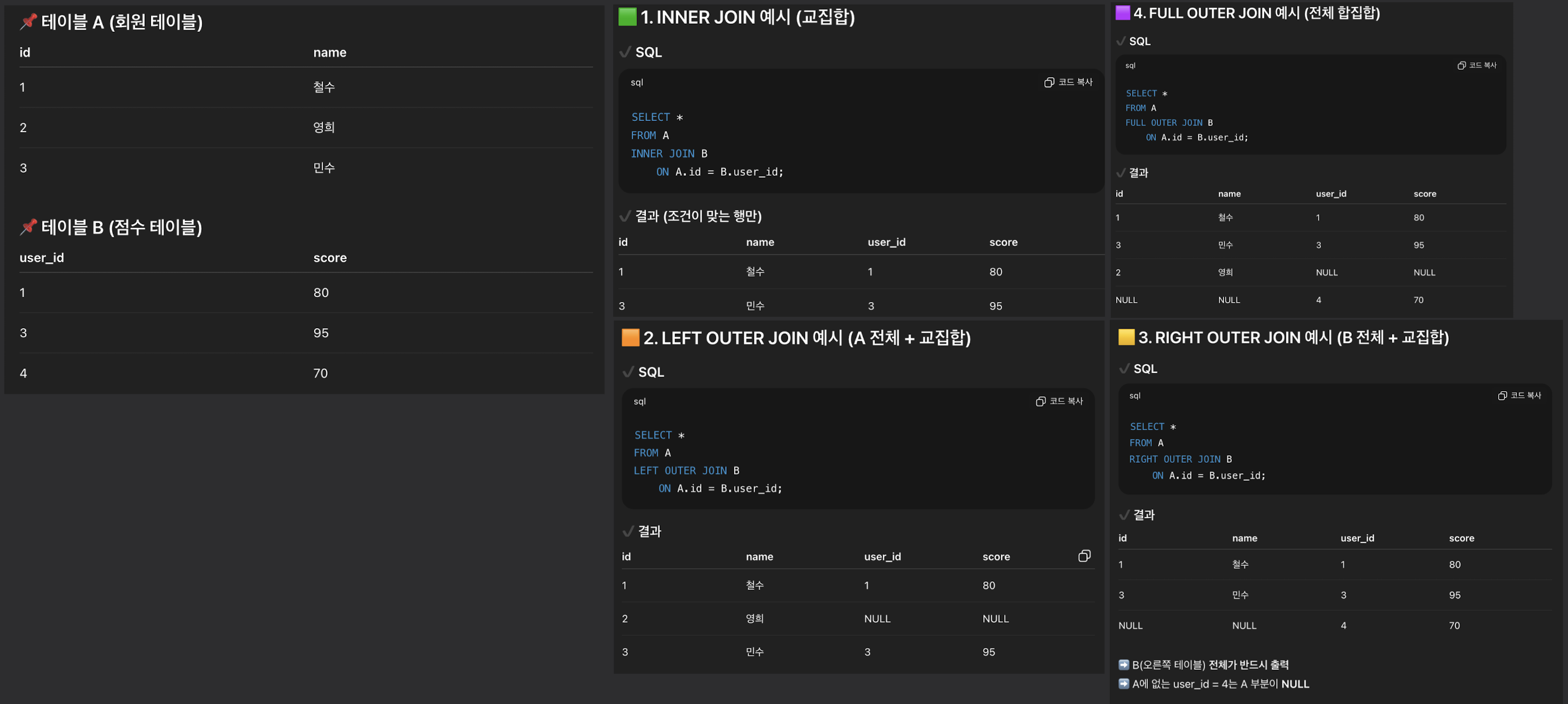
- INNER JOIN(=JOIN)과 OUTER JOIN의 차이
- INNER JOIN은 조건을 만족하는 행만 가져옴 (교집합)
- OUTER JOIN은 한쪽에 없는 값도 포함
- OUTER JOIN에서 NULL 발생하는 곳: 매칭되지 않는 행이 있는 쪽
- OUTER JOIN의 정의
- SQL에서 OUTER 라는 단어는 생략 가능한 옵션
- OUTER JOIN이라고 쓰면 → LEFT / RIGHT / FULL 이 반드시 붙음
- OUTER JOIN 단독으로 사용 X
- LEFT JOIN(LEFT OUTER JOIN): 왼쪽 우선
- 왼쪽 테이블(A) 기준 A의 모든 행을 가져오고 B와 매칭이 안 되면 B 부분이 NULL로 채워짐
- 즉, A 전체 + 교집합
- RIGHT JOIN(RIGHT OUTER JOIN): 오른쪽 우선
- LEFT 반대
- FULL OUTER JOIN (합집합 느낌)
- A 전체 + B 전체, 매칭되면 합쳐서 보여주고, 매칭 안되면 해당 칼럼은 NULL
- SQL에서 OUTER 라는 단어는 생략 가능한 옵션
- CROSS JOIN
- 곱집합(Cartesian Product)
서브쿼리(Subquery)
- 서브쿼리의 특징
- SELECT/WHERE/FROM 절에서 사용 가능
- FROM 절 서브쿼리는 가상 테이블처럼 사용 가능.
- 서브쿼리 결과가 여러 행을 반환할 때 사용해야 하는 연산자
- IN
- 여러 값을 비교할 때 사용하며, = 은 단일 값 비교만 가능
- IN
- 상관 서브쿼리(Correlated Subquery)
- 서브쿼리 중첩이 가장 깊은 형태
- 상관 서브쿼리는 메인쿼리의 각 행마다 반복적으로 실행되므로 가장 깊은 형태로 간주
- 상관 서브쿼리는 메인쿼리 컬럼을 참조하므로, 메인쿼리 행 수에 따라 반복 실행
- 연관 서브쿼리의 특징
- 외부 쿼리의 한 행마다 반복 실행됨(외부 쿼리 행마다 실행되는 반복 구조)
연산자
- 집합연산자(UNION, INTERSECT, MINUS)의 특징
- UNION은 중복 제거
- UNION ALL은 중복 허용
- INTERSECT는 교집합
- MINUS는 오름차순 정렬을 반드시 수행하지 않는다(X) = 수행할수도 있음
- 집합연산자는 결과를 기본적으로 정렬하지만, DBMS에 따라 옵티마이저가 정렬을 생략 가능
- BETWEEN 연산자 사용 예시
salary BETWEEN 5000 AND 10000- BETWEEN은 “A 이상 B 이하” 범위를 의미(작은 값 -> 큰 값)
- BETWEEN 사용 시 포함 범위
- 양쪽 포함
- ANY와 ALL 연산자의 차이
- ANY는 하나라도 맞으면 TRUE, ALL은 모든 값이 맞아야 TRUE
집계함수
- 집계함수 중 NULL 값을 제외하고 평균을 계산하는 함수
- AVG()는 NULL 값을 자동으로 제외하고 평균을 계산
VIEW
- 뷰(View)에 대한 설명
- 뷰는 하나 이상의 테이블을 기반으로 하는 논리적 가상 테이블
- 뷰는 기본 테이블을 기반으로 생성
- 뷰를 이용해 데이터 접근 권한을 제한 가능
- 뷰는 물리 데이터가 아닌 SQL 결과를 논리적으로 보여주는 객체이며, 일부는 수정 가능
- 단일 테이블 기반 단순 뷰는 수정 가능하지만, 조인·집계 포함 뷰는 일반적으로 수정 불가
- 항상 수정 가능 X
- 단일 테이블 기반 단순 뷰는 수정 가능하지만, 조인·집계 포함 뷰는 일반적으로 수정 불가
- 실제 데이터 저장X
- 원본 테이블 변경 시 뷰 결과도 달라짐
- 특정 데이터만 보여주는 용도로 사용
- 보안 강화 가능
- 인라인 뷰(Inline View)의 장점
- SQL 문 안에서만 임시로 뷰처럼 사용 가능하다
- 인라인 뷰는 쿼리 내부에서만 유효한 임시 결과 집합으로, 복잡한 서브쿼리를 단순화하는 데 유용
LIKE
- LIKE 연산자에서 와일드카드
_의 의미- 단일 문자 대체
_는 한 글자,%는 여러 글자를 대체
- LIKE ‘A%’ 의미
- A로 시작하는 값
EXISTS
- EXISTS 연산자의 특징
- 존재 여부만 검사
- EXISTS는 서브쿼리의 결과 존재 여부를 Boolean으로 반환
- 서브쿼리의 결과가 존재하면 TRUE를 반환한다
DELETE / TRUNCATE
- DELETE와 TRUNCATE의 차이점
- DELETE는 로그 기록, TRUNCATE는 최소 로그 기록
- DELETE는 한 행씩 삭제
- TRUNCATE는 DDL로서 전체 삭제 시 빠르지만,
- 로그가 최소만 남고 WHERE 절을 사용할 수 없다.
트랜잭션 (TRANCTION)
- 트랜잭션(Transaction)의 특성
- ACID(Atomicity, Consistency, Isolation, Durability)
Null
- NVL: NULL을 특정 값으로 변환하는 함수.
- Oracle에서 NVL(col, 0)의 역할
- NULL 값을 0으로 치환한다
- Oracle에서 NVL(col, 0)의 역할
ORDER BY
- ORDER BY 실행 순서
- 1 FROM
- 2 WHERE
- 3 GROUP BY
- 4 HAVING
- 5 SELECT
- 6 DISTINCT
- 7 ORDER BY
- 6 DISTINCT
- 5 SELECT
- 4 HAVING
- 3 GROUP BY
- 2 WHERE
- 1 FROM
SELECT dept, COUNT(*) FROM emp WHERE job = 'SALESMAN' GROUP BY dept
HAVING COUNT(*) >= 2 ORDER BY dept;
- 아래 쿼리의 실행 순서
- SQL 논리적 실행 순서는 물리적 순서와 다르며, SELECT는 거의 마지막에 실행
- 1 FROM
- 2 WHERE
- 3 GROUP BY
- 4 HAVING
- 5 SELECT
- 6 ORDER BY
- 5 SELECT
- 4 HAVING
- 3 GROUP BY
- 2 WHERE
SQLD 자주 나오는 유형 정리
- ERD 문제
- 관계 차수, 선택/필수, 식별/비식별
- 정규화
- 이행적, 부분 함수 종속 구분
- JOIN
- INNER/LEFT 차이 이해
- GROUP BY
- SELECT에 집계함수 or 그룹 기준만 가능
- 서브쿼리
- 단일행/다중행 연산자 구분
- 인덱스
- 언제 효과적인지 / 언제 안 걸리는지
- 조인 vs 서브
- 같은 결과라도 구조가 다르면 성능 차이
- NULL 처리
- NVL, COALESCE, IS NULL
마지막 20개 체크리스트 (시험 전 10분)
-
데이터 모델링
-
식별자 / 비식별자 구분 가능
-
1:N 관계 방향 확실히 숙지
-
정규화 원리 암기
-
엔터티 유형 분류 가능
-
도메인 정의 의미 알고 있음SQL
-
SELECT 실행 순서 암기
-
GROUP BY + HAVING 구조 기억
-
JOIN 종류 확실히 구분
-
모든 집계 함수 원리 파악
-
단일행/다중행 서브쿼리 구분
-
인덱스
-
인덱스가 잘 걸리는 컬럼 특징
-
LIKE ‘%값’ 인덱스 안 됨
-
PK/UNIQUE는 자동으로 인덱스 생성
-
성능 & 트랜잭션
COMMIT / ROLLBACK 시점 명확
VIEW는 가상테이블 (데이터 저장X) -
기타
-
NVL / COALESCE 차이 암기
-
RANK vs DENSE_RANK 알고 있음
-
집계함수 + 일반컬럼은 GROUP BY 필요
완전 압축
- 식별자 = 유일 + 최소 + 변동 X
- 1:N 관계에서 FK는 N쪽에 생성
- 정규화: 원자화 → 부분종속 제거 → 이행종속 제거
- 실행 순서: FROM → WHERE → GROUP → HAVING → SELECT → ORDER
- 집계 함수 + 일반 컬럼 = GROUP BY 필요
- LEFT JOIN = 왼쪽 기준 다 보여줌
- 단일행 서브쿼리 = =, >, < / 다중행 = IN, ANY, ALL
- 인덱스는 중복 적고 자주 검색되는 컬럼에
- PK = UNIQUE + NOT NULL
- LIKE ‘값%’ 가능 / ‘%값’ 인덱스 불가
- 부분 함수 종속 제거 = 2NF 핵심.
- 비식별 관계 = 점선, PK로 가지 않고 FK로만 존재.
- N:M은 절대 직접 구현 X → 반드시 중간 테이블.
- 카디널리티(중복 적음)가 높을수록 인덱스 효과 ↑
- %로 시작하는 LIKE는 인덱스 불가.
- 서브쿼리
- 단일행: = > <
- 다중행: IN, ANY, ALL, EXISTS
1시간
1과목 핵심 9개 (10분)
1) 엔터티
- 관리해야 하는 정보 집합
- 속성 + 식별자 포함
- 기본 / 중심 / 행위 엔터티
2) 속성
- 기본 / 설계 / 파생 속성
- 파생: 계산된 값
3) 관계
- 1:1 / 1:N / N:M
- N:M은 중간 엔터티 필요
4) 카디널리티
- 1:1, 1:N, N:M
- 필수/선택 존재
5) 식별자(PK)
- 유일성 + 최소성 + 변동 없음
6) 식별/비식별
- 식별: 실선, PK 상속
- 비식별: 점선, FK만
7) 정규화
- 1NF: 원자값
- 2NF: 부분 함수 종속 제거
- 3NF: 이행 종속 제거
8) 반정규화
- 정규화로 인해 생긴 성능 문제를 해결하기 위해 의도적으로 정규화 원칙을 깨는 것
- 즉, 조인을 줄여서 조회 성능을 높이기 위한 트릭
- 중복/통계 컬럼, 중간 엔터티 제거
9) 도메인
- 속성이 가질 수 있는 값의 범위
SQL 핵심 15개 (20분)
1) SELECT 실행 순서
FROM → WHERE → GROUP BY → HAVING → SELECT → ORDER BY
2) GROUP BY
- SELECT = 그룹 기준 + 집계 함수만 가능
3) HAVING = 그룹 조건
- WHERE = 행 조건
4) JOIN
- INNER = 매칭만
- LEFT = 왼쪽 전체
- RIGHT = 오른쪽 전체
- FULL = 전체
5) 서브쿼리
- 단일행: =, >, <
- 다중행: IN, ANY, ALL
- EXISTS: 존재 여부
6) NULL
- 비교 불가 → IS NULL
- 집계함수 제외
7) NVL / COALESCE
- NVL(값, 대체)
- COALESCE(여러 값 중 첫 NOT NULL)
8) DISTINCT 집계 가능
COUNT(DISTINCT col)
9) LIKE 인덱스
- 'abc%' 가능
- '%abc' 불가
10) BETWEEN 포함
a 이상 b 이하
11) 인덱스 효율
- 중복 적은 컬럼
- PK/UNIQUE 자동 인덱스
12) VIEW
- 가상 테이블
- 데이터 저장 X
13) 4가지 언어 구분
- DDL: CREATE, ALTER, DROP, TRUNCATE
- DML: SELECT, INSERT, UPDATE, DELETE
- DCL: GRANT, REVOKE
- TCL: COMMIT, ROLLBACK
14) JOIN 후 GROUP
- JOIN 결과 → GROUP BY 적용
15) 집계 함수
- COUNT(*) = NULL 포함
- COUNT(col) = NULL 제외
자주 틀리는 함정 12개 (15분)
- 1) SELECT에 일반 컬럼 + 집계 함께 사용 → 일반 컬럼은 GROUP BY 필요
- 2) HAVING을 WHERE처럼 사용 ❌
- HAVING sal > 3000 ❌
- 3) NULL 비교는 IS NULL
- sal = NULL ❌ -> sal IS NULL
- 4) '%abc' 인덱스 안 됨
- 5) COUNT(DISTINCT col) 가능
- SELECT DISTINCT / COUNT(DISTINCT col) 둘다 가능
- 6) LEFT JOIN = 왼쪽 전체
- 7) N:M 직접 구현 불가 → 중간 엔터티 필요
- 8) 2NF = 부분 종속 제거
- 9) 3NF = 이행 종속 제거
- 10) PK = UNIQUE + NOT NULL
- 11) DELETE vs TRUNCATE 차이
- 12) VIEW는 데이터 저장 X
초압축 공식 20줄 (10분 암기)
- 식별자 = 유일 + 최소 + 변동 없음
- 비식별 관계 = 점선
- N:M = 중간 엔터티 필요
- 정규화: 원자 → 부분 → 이행 종속 제거
- SELECT 실행 순서 = FROM WHERE GROUP HAVING SELECT ORDER
- GROUP BY는 집계 + 그룹 기준만 SELECT 가능
- HAVING = 그룹 조건
- LEFT JOIN = 왼쪽 전체
- NULL 비교는 IS NULL
- COUNT(*) = NULL 포함
- DISTINCT + 집계 가능
- LIKE 'abc%' 인덱스 O
- LIKE '%abc' 인덱스 X
- BETWEEN은 a 이상 b 이하
- PK = UNIQUE + NOT NULL
- DDL = CREATE ALT DROP TRUNC
- VIEW 데이터 저장 X
- 단일행 서브쿼리 = = > <
- 다중행 서브쿼리 = IN ANY ALL
- 집계 + 일반컬럼 → 일반컬럼은 GROUP BY 필요
- 집계 : COUNT(), SUM(), AVG(), MAX(), MIN()
SELECT deptno, COUNT(*) FROM emp;= 오류 발생SELECT deptno, COUNT(*) FROM emp GROUP BY deptno;= 성공
시험 직전 셀프 체크 10문제 (5분)
- 1) 2NF는 무엇 제거? → 부분 종속
- 2) 비식별 관계 선? → 점선
- 3) N:M 구현? → 중간 엔터티
- 4) SELECT 순서? → FROM WHERE GROUP HAVING SELECT ORDER
- 5) GROUP BY SELECT 가능? → 그룹 기준 + 집계
- 6) LEFT JOIN 결과? → 왼쪽 전체
- 7) NULL 비교? → IS NULL
- 8) 인덱스 안 되는 LIKE? → %abc
- 9) COUNT(*) vs COUNT(col)? → NULL 포함 여부
- 10) PK는 무엇? → UNIQUE + NOT NULL

안녕하세요.