
강의 주소(유튜브 아답터)
2026/02/12
1강
자료구조를 공부해야 하는 이유
- 데이터를 체계적으로 저장하고 효율적으로 활용하기 위해
- 특정한 상황에서의 문제를 해결할 때, 상황에 적합한 자료구조를 활용
- 자료구조의 개념은 시간이 지나도 변하지 않음
- 프로그램의 실행 시간과 메모리 관리를 위해서 필요
자료구조
- 컴퓨터에서 처리할 데이터를 효율적으로 관리하고 구조화시키기 위한 방법
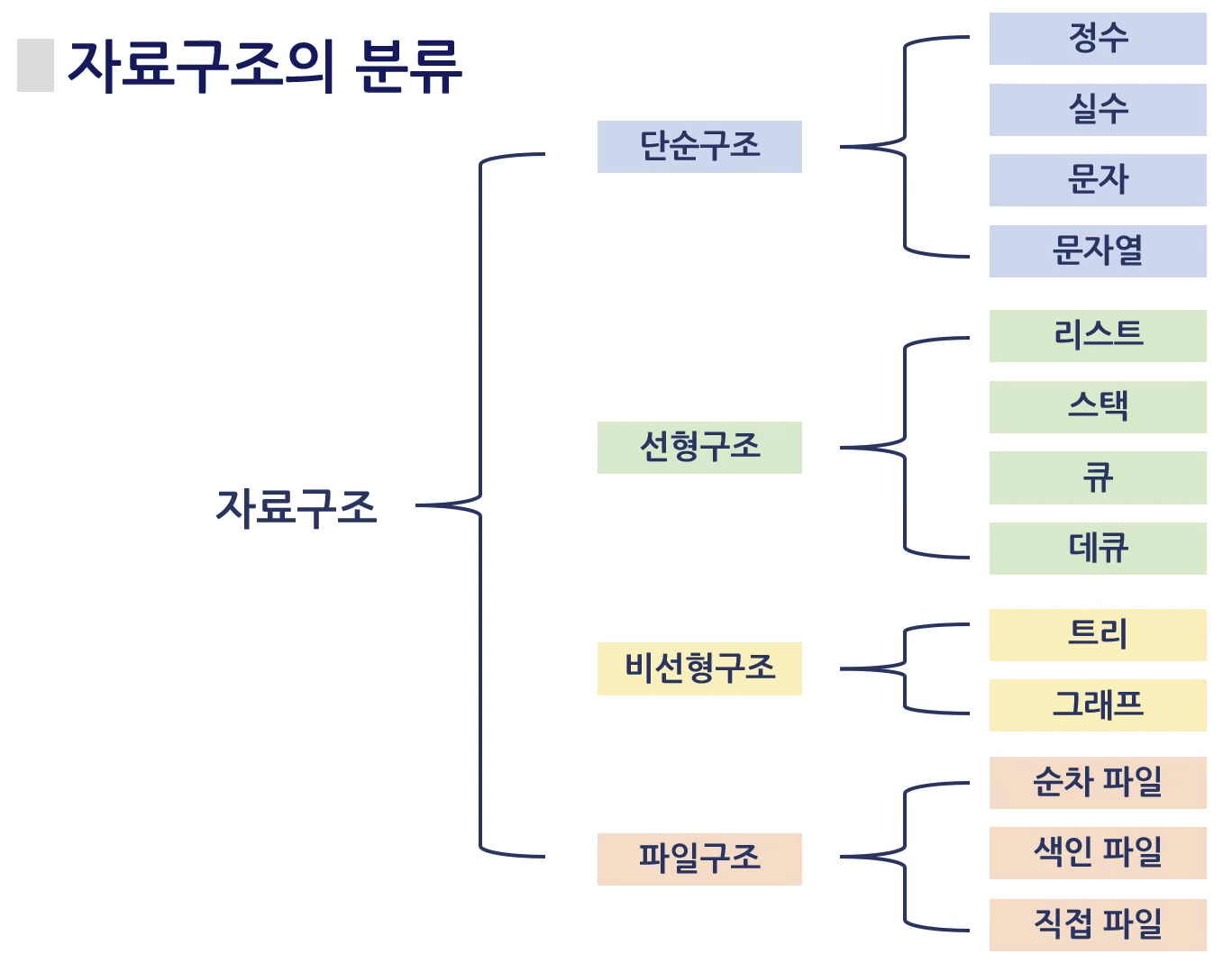
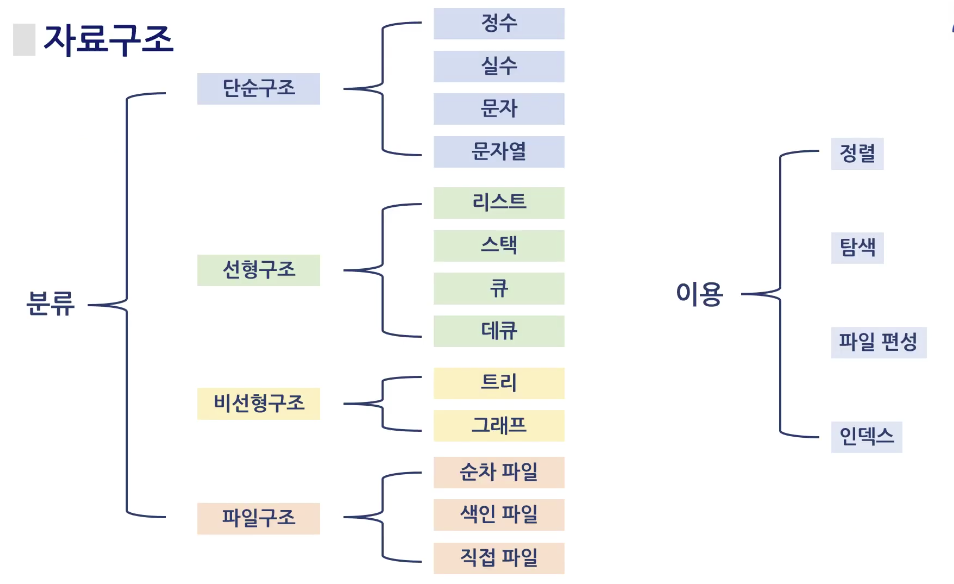
자료구조의 분류
4가지
- 단순 구조
- 정수 (ex. -2,-1,0,1,2)
- 실수 (ex. 1.173)
- 문자 (ex. A, B, C)
- 문자열 (ex. "abc")
- 선형 구조
- 리스트
- 스택
- 큐
- 데큐
- 비선형 구조
- 트리
- 그래프
- 파일구조
- 순차 파일
- 색인 파일
- 직접 파일
- 단순 구조
자료구조의 이용
- 정렬
- 기억장치에 저장된 데이터를 일정한 순서로 나열하는 것
- 탐색
- 기억장치에서 데이터를 찾는 것
- 파일 편셩
- 데이터를 기억 장치에 저장할 때의 파일 구조
- 인덱스
- 특정 데이터를 빠르게 찾기 위한 것
2강. 알고리즘 성능분석
자료구조와 알고리즘의 관계
- 자료구조에 따라 알고리즘이 달라지며
- 자료구조와 알고리즘은 서로 의존적인 관계
시간복잡도와 공간복잡도
좋은 알고리즘을 평가하는 요소
- 속도
- 시간복잡도
- 메모리 사용량
- 공간복잡도
- 일반적으로 메모리 사용량 보다 실행속도에 관심
- 일반적으로 데이터 수 n에 대하여 덧셈, 뺄셈, 곱셈 등의 획수를 시간복잡도로 표현
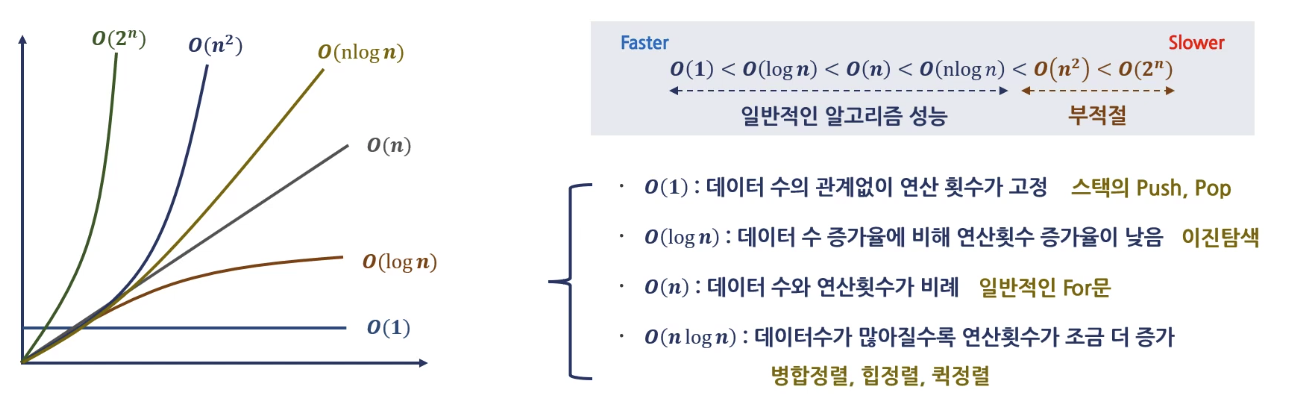
빅오(Big-O)
- 최악의 경우에 대한 성능을 판단
빅오메가(Big-Ω)
- 최선의 경우에 대한 성능을 판단
빅세타(Big-0)
- 평균의 경우에 대한 성능을 판단
- 속도
빅오(Big-O) 표기법
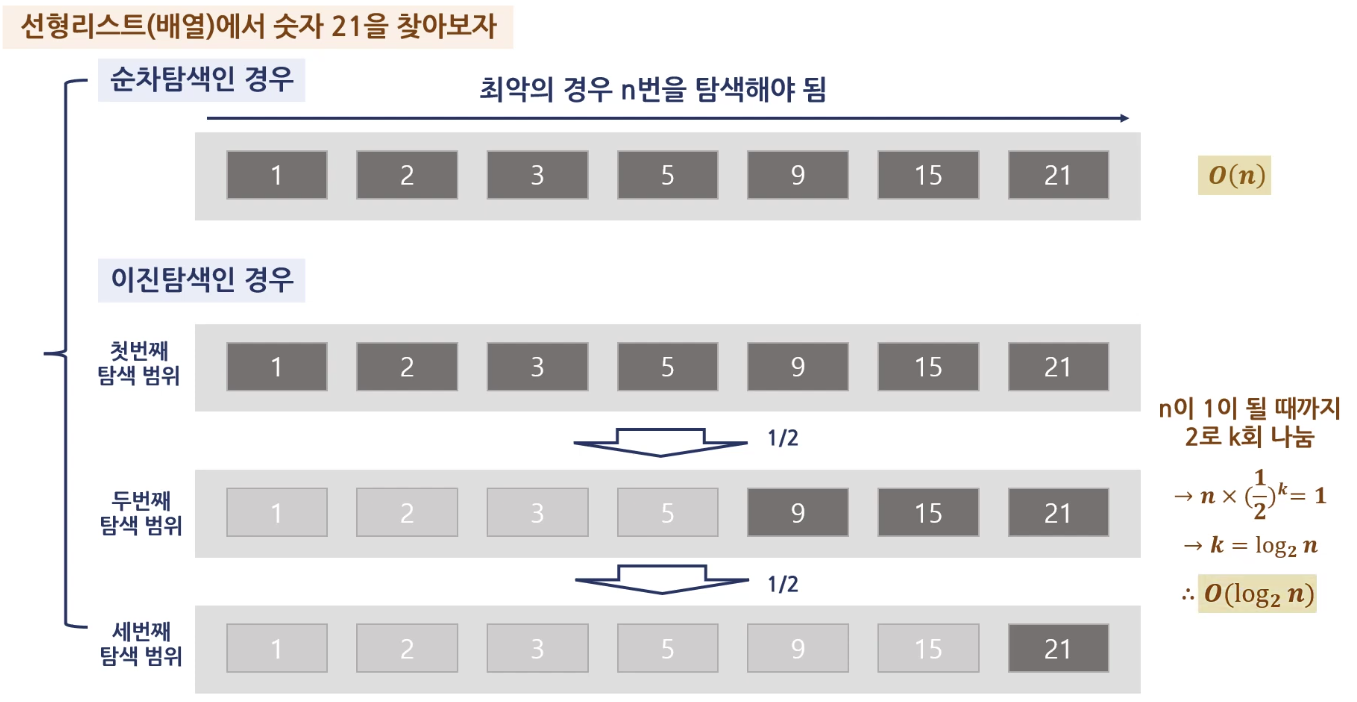


2026/02/15
3강. 선형 자료구조
리스트 / 스택 / 큐 / 데큐
리스트
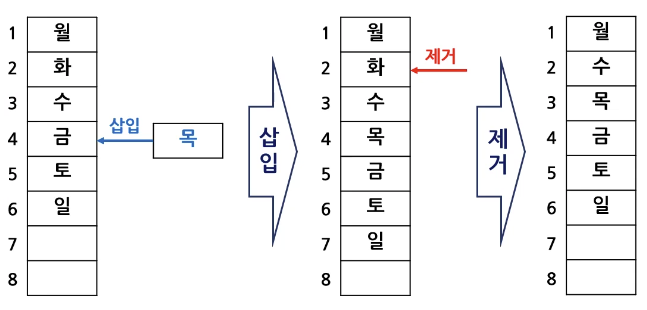
선형리스트
- 연속되는 기억장치에 저장되는 자료구조
특징
- 가장 간단한 자료구조
- 빠른 접근속도
- 효율적인 메모리 공간
단점⚠️
- 삽입/삭제 시 데이터 이동으로 인한 번거로운 작업 필요
- 연속되는 기억장치에 저장되는 자료구조
연결 리스트
- 자료를 임의의 공간에 기억시키고, 순서에 따라 포인터로 연결시킨 자료구조
- 포인터: 기억장치의 주소를 가리크는 변수
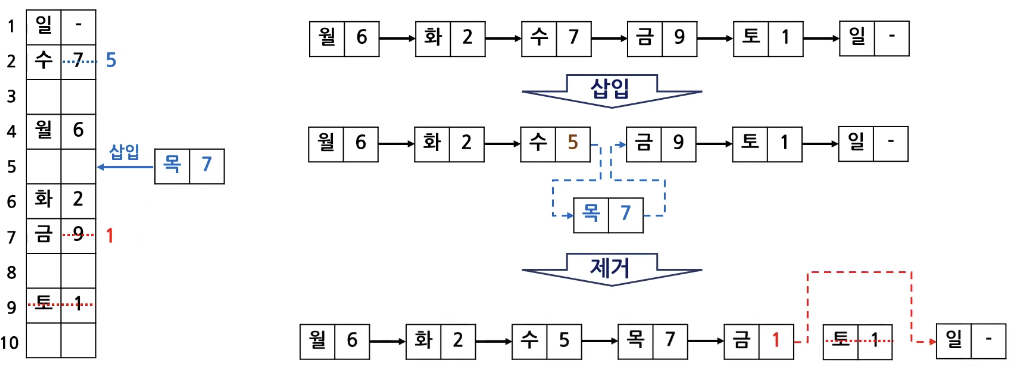
- 포인터: 기억장치의 주소를 가리크는 변수
특징
- 노드의 삽입, 제거가 용이
- 기억공간이 연속적일 필요없음
단점
- 포인터 부분이 필요하여 선형리스트 대비 낮은 메모리 이용 효율
- 연결을 통해 순차적으로 접근해야 하므로 느린 접근 속도
종류
- 단순 연결 리스트

- 단순 원형 연결 리스트

- 이중 연결 리스트

- 이중 원형 연결 리스트
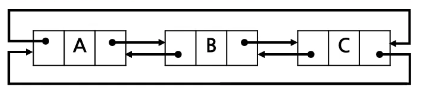
- 단순 연결 리스트
- 자료를 임의의 공간에 기억시키고, 순서에 따라 포인터로 연결시킨 자료구조
스택(Stack)
-
리스트의 한쪽 끝으로만 자료의 삽입, 삭제가 이루어지는 자료구조
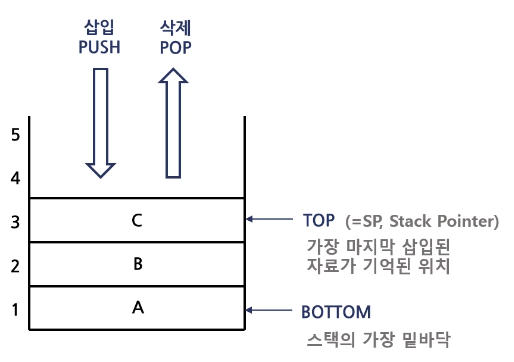
-
특징
- 가장 나중에 입력된 데이터가 먼저 삭제되는 후입선출(LIFO:Last In First Out) 구조
- 스택에 모든 메모리가 채워져 있는 상태에서 자료를 삽입하려고 하면 Overflow가 발생
- 스택에 모든 메모리가 비워져 있는 상태에서 자료를 제거하려고 하면 Underflow가 발생
-
활용 사례
- 웹 브라우저 방문기록 뒤로가기
- 프로그램의 실행 취소 (Undo)
- 인터럽트가 발생하여 복귀주소 저장 시
- 후위 표기법으로 수식을 표현
- 함수 호출 순서 제어
- 깊이 우선 탐색(DFS) 구현
큐(Queue)
-
한쪽에서 데이터의 삽입이 이루어지고 다른 한쪽에서 데이터의 삭제가 이루어지는 자료구조
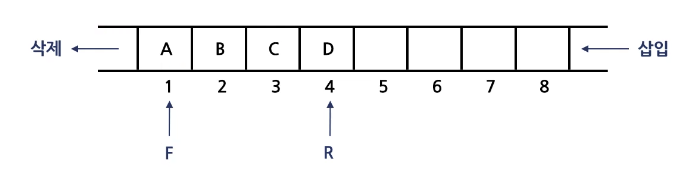
-
특징
- 가장 먼저 입력된 데이터가 먼저 삭제되는 선입선출(FIFO:First In First Out) 구조
- 프런트(F, Front) 포인터
- 가장 먼저 입력된 데이터의 기억공간을 가리키며, 삭제 작업을 할 때 사용
- 리어(R, Rear) 포인터
- 가장 마지막에 입력된 데이터의 기억공간을 가리키며, 삽입 작업을 할 때 사용
-
활용 사례
- 우선순위가 같은 작업 예약(프린터 인쇄)
- 은행 창구 업무의 서비스 순서 대기 처리 콜센터 고객 대기시간
- 운영 체제의 작업 스케줄링
- 너비 우선 탐색(BFS) 구현
데큐(DeQue)
-
삽입과 삭제가 양쪽 끝에서 모두 발생할 수 있는 자료구조

-
특징
- Double Ended Queue의 약자
- Stack과 Queue의 장점만을 활용하여 구성
-
활용 사례
- 우선순위를 조절하는 스케줄링
- 문서 편집의 Undo/Redo
-
종류
- 입력제한데큐(Scroll)
- 한쪽에서의 입력을 제한함 (따라서 한쪽에서는 삭제만 발생)

- 한쪽에서의 입력을 제한함 (따라서 한쪽에서는 삭제만 발생)
- 출력제한데큐(Shelf)
- 한쪽에서는 출력을 제한함 (따라서 한쪽에서는 삽입만 발생)

- 한쪽에서는 출력을 제한함 (따라서 한쪽에서는 삽입만 발생)
- 입력제한데큐(Scroll)
2026/02/16
4강. 비선형 자료구조 - 트리
트리 / 그래프
트리
- 노드들아 나무 가지처럼 연결된 계층적 자료구조
- ex. 가족 계보, 연산 수식, 회사 조직 구조도, Heep 표한하기 적합(heep: 메모리를 표현하는 방법)

노드(Node)
- 데이터를 저장하고 있는 가장 기본적인 구성요소
- 자료 항목을 가지는 트리를 구성하는 기본요소
- ex.
A, B, C, D, E, F, G, H, I,J, K, L, M
근 노드(Root Node)
- 트리의 가장 맨 상단에 있는 노드
- ex.
A
차수(Degree)
- 각 노드에서 뻗어나온 가지 수
- ex.
A=3, B=2, C=1, D=3
잎사귀 노드(Leaf Node)
- 자식이 하나도 없는 노드 (차수가 0인 노드)
- ex.
K. L, F, G, M, L, J
트리의 깊이(Depth)
- 트리에서의 최대 깊이
- ex.
Depth : 4
트리의 차수(Degree)
- 노드들의 차수 중 최대 차수
- ex.
Degree: 3
이진 트리(Binary Tree)
자식이 둘 이하(차수가 2 이하)인 노드로만 구성된 트리
전 이진 트리(Full binary Tree)
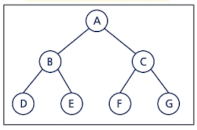
- 모든 노드가 0개 또는 2개의 자식노드를 갖는 트리
완전 이진 트리(Complete binary Tree)
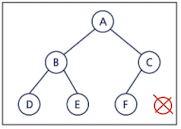
- 마지막 깊이를 제외한 모든 깊이의 노드가 완전히 채워져 있는 트리 (모든 노드는 왼쪽부터 채워짐)
이진 트리의 공식

이진 트리의 순회
-
트리를 구성하는 노드들을 모두 방문하는 방법
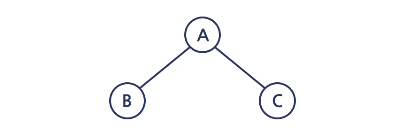
전위 순회(Pre-order)
Root → Left → Right(A → B→ C)
중위 순회(In-order)
Left → Root → Right(B → A→ C)
후위 순회(Post-order)
Left → Right → Root(B → C→ A)
풀이
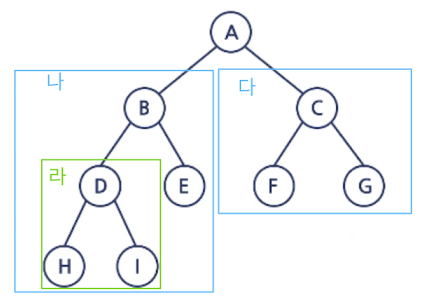
전위 순회
A → 나 → 다(나: B → 라 → E / 다: C → F → G)A → B → 라 → E → C → F → G(라: D → H → I)결과: A → B → D → H → I → E → C → F → G
중위 순회
나 → A → 다(나: 라 → B → E / 다: F → C → G)라 → B → E → A → F → C → G(라: H → D → I)결과 :
H → D → I → B → E → A → F → C → G
후위 순회
나 → 다 → A (나: 라 → E → B / 다: F → G → C)
라 → E → B → F → G → C → A(라: H → I → D)결과:
H → I → D → E → B → F → G → C → A
이진 수식 트리
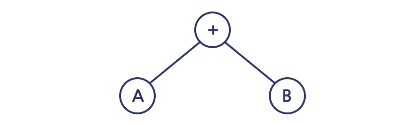
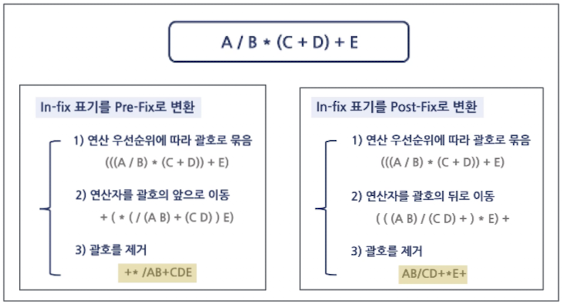
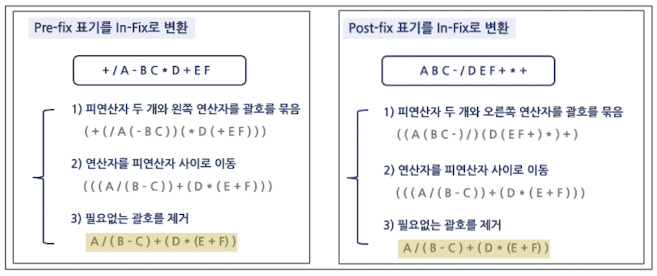
전위 표기법 (Pre-Fix)
Root → Left → Right (
+AB)
중위 표기법 (In-Fix)
Left → Root → Right (
A+B)
후위 표기법 (Post-Fix)
Left → Right → Root (
AB+)
이진 수식 트리 주의 ⚠️
- 컴퓨터에서는 중위 표기법을 사용 시, 어떤 수식을 먼저 연산해야 할지 확인절차 필요
- 스택으로 연산이 가능한
Post-Fix나Pre-Fix방식을 활용
- 스택으로 연산이 가능한
2026/02/17
5강. 비선형 자료구조 - 그래프
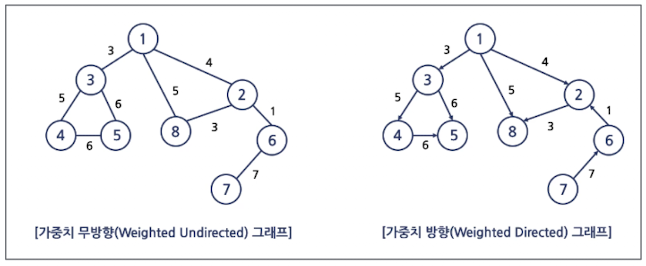
그래프
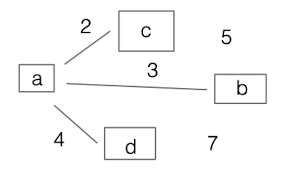
- 정점(Vertex) 혹은 노드(Node)와 이들을 연결하는 간선(Edge)의 집합으로 이루어진 자료구조
- ex. 통신망 / 교통 시스템 / 소셜 네트워크 분석 / 인공지능 및 머신러닝
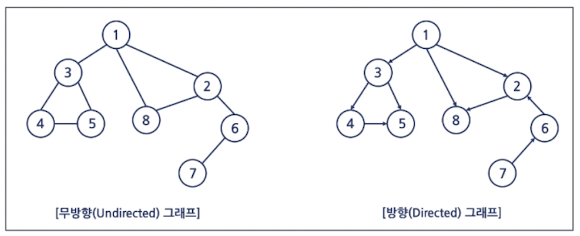
그래프 종류
-
무방향 그래프
- 간선을 통해 양방형 이동 가능
-
방향 그래프
- 일방향으로만 이동 가능
- 일방향으로만 이동 가능
-
가중치 무방향 그래프 / 가중치 방향 그래프
- 간선에 비용이나 가중치가 할당된 그래프
- 도로 건설 비용, 통신망의 사용료 등에서 사용함
그래프의 구현 방법
인접 리스트(Adjacency List)
- 인접한 정점을 인접 리스트에 저장하는 방법
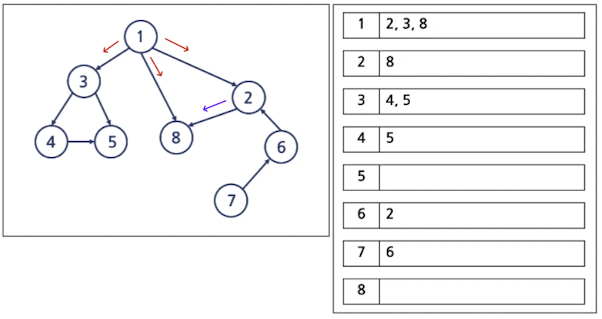
- 인접한 정점을 인접 리스트에 저장하는 방법
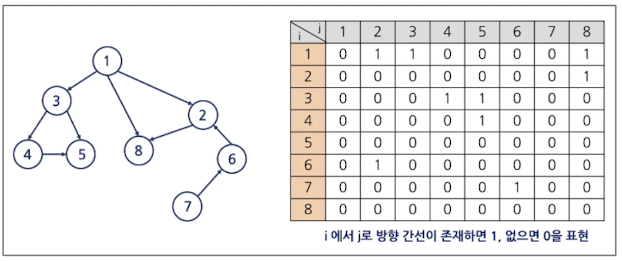
인접 행렬(Adjacency Matrix)
- 2차원 배열을 이용하여 노드 간의 연결 관계를 나타내는 방법
- 갈 수 있으면 1 없으면 0 (구현하기는 쉽지만 메모리를 많이 잡아먹음)
그래프 알고리즘 종류
그래프 탐색 알고리즘
- 특정 정점(노드)를 찾는 알고리즘
너비 우선 탐색(BFS)(Queue) / 깊이 우선 탐색(DFS)(Stack)
최단 경로 알고리즘
- 두 정점 간의 최소 가중치 합을 찾는 알고리즘
다익스트라(Dijkstra) / 벨만-포드(Bellman-Ford)
- 두 정점 간의 최소 가중치 합을 찾는 알고리즘
최소 신장 트리 알고리즘
- MST, Minimum Spanning Tree
- 모든 정점을 최소한의 간선으로 연결하는 그래프를 찾는 알고리즘
크루스칼(Kruskal) / 프림(Prim)
그래프와 트리의 관계
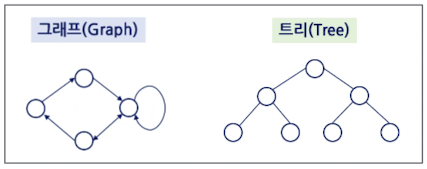
그래프
- 노드와 노드를 연결하는 간선으로 구성
- 사이클 / 자체 순환 가능
- 부모 - 자식 개념이 없음
- 네트워크 모델
- 노드와 노드를 연결하는 간선으로 구성
트리
- 방향성이 있는 비순환 그래프 (트리는 그래프에 속한다.)
- 사이클 / 자체순환 불가능
- 계층 모델
2026/02/18
6강. 정렬
- 각 데이터를 특정 항목으로 오름차순 혹은 내림차순으로 재배열 하는 작업
자료구조의 이용
정렬
- 기억장치에 저장된 데이터를 일정한 순서로 나열하는 것
탐색
- 기억장치에서 데이터를 찾는 것
파일 편성
- 데이터를 기억 장치에 저장할 때의 파일 구조
인덱스
- 특정 데이터를 빠르게 찾기 위한 것
내부정렬
- 데이터량이 적을 때 주기억장치에서 정렬하는 방법(주기억장치: RAM / 속도 ↑)
- (1) 삽입법 : 삽입 정렬, 쉘 정렬
- (2) 교환법 : 버블 정렬, 선택 정렬, 퀵 정렬
- (3) 선택법 : 힙정렬
- (4) 병합법 : 머지정렬(합병정렬)
- (5) 분배법 : 기수정렬
외부정렬
- 대용량의 데이터를 보조기억장치에서 기억시켜서 정렬하는 방법 (보조기억장치: HDD / SSD / 속도 ↓)
- 밸런스 병합 정렬
- 캐스케이드 병합 정렬
- 폴리파즈 병합 정렬
- 오실레이팅 병합 정렬
버블 정렬(Bubble Sort)
- 두 개의 데이터를 비교하여 크기에 따라 위치를 서로 교환하는 정렬 방식
평균과 최악 모두 시간복잡도는 O(𝘯²)
선택 정렬(Selection Sort)
- N개의 데이터 중 최솟값을 찾아 첫 번째 위치에 놓고, 나머지 N-1개로 반복하여 정렬하는 방식
평균과 최악 모두 시간복잡도는 O(𝘯²)
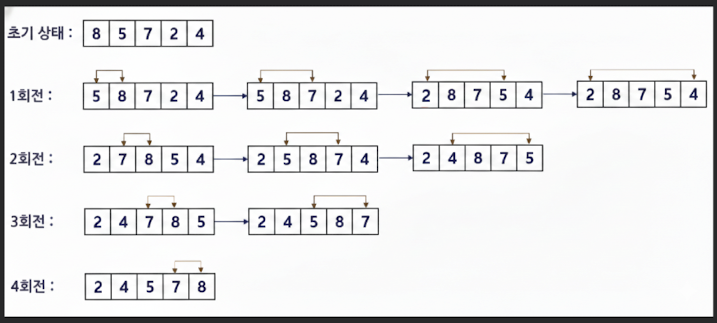
삽입 정렬(Insertion Sort)
- 순서화된 데이터에 새로운 데이터를 순서에 맞게 입하여 정렬하는 방식
평균과 최악 모두 시간복잡도는 O(𝘯²)
쉘정렬(Shell Sort)
- 삽입 정렬이 어느 정도 정렬된 배열에서 빠른 것에 착안한 삽입 정렬의 확장 기법
- 삽입 정렬의 문제점: 삽입해야 할 위치가 상당히 멀다면 많은 이동이 필요
- (1) 여러 개의 부분 리스트를 만들고, 각 부분 리스트를 삽입 정렬을 통하여 정렬
- (2) 모든 부분 리스트의 정렬이 완료되면 더 적은 부분 리스트로 만들어 반복
평균 시간복잡도는 O(𝘯¹﹒⁵), 최악 시간복잡도는 O(𝘯²)
- 삽입 정렬의 문제점: 삽입해야 할 위치가 상당히 멀다면 많은 이동이 필요
2026/02/19
7강.정렬 - 2
퀵 정렬 / 힙 정렬 / 머지정렬 / 기수정렬
- 구현은 까다롭지만 성능이 좋음
퀵 정렬(Quick Sort)
- 데이터들을 피벗(키)을 부분적으로 나누어 가며 정렬하는 방법
평균 시간복잡도는 O(𝘯 ㏒ 𝘯), 최악 시간복잡도는 O(𝘯²)
특징
- 피벗(Pivot)을 기준으로 작은 값은 왼쪽, 큰 값은 오른쪽으로 분할
- 프로그램을 Recall해야 하므로 스택이 필요
- 분할(Divide)과 정복(Conquer)을 활용
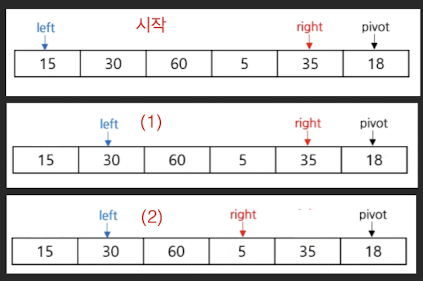
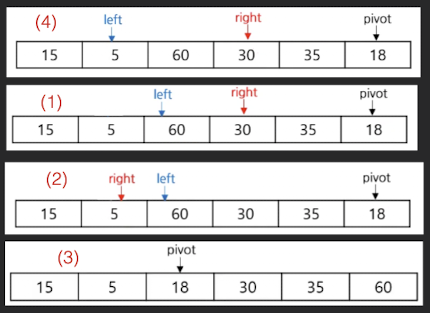
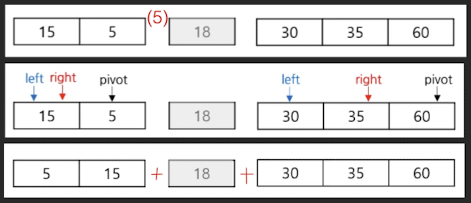
알고리즘
- (1) Left 값> pivot 값 만족 시 까지 Left 증가
- (2) Right 값 < pivot 값 만족 시 까지 Right 감소
- (3) Left >= Right 이면, Left와 Pivot 값 변경
- (4) Left < Right 이면, Left와 Right 값 변경
- (5) Pivot 기준으로 분할 및 반복
실습
힙 정렬(Heap Sort)
- 전이진 트리(Complete Binary Tree)를 이용한 정렬 방식
- 평균과 최악 모두 시간복잡도는 O(𝘯 ㏒ 𝘯)
- 노드의 역순으로 자식 노드와 부모 노드를 비교하여 큰 값을 위로 올림
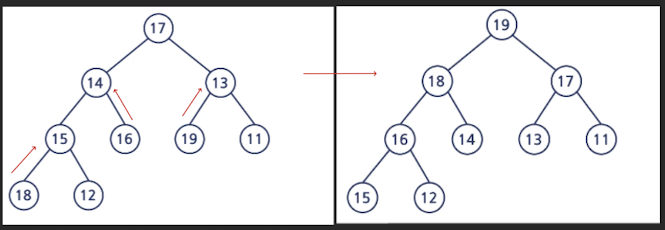
비교
- 리스트 기반 데이터 저장 시 정렬 시간 복잡도 O(𝘯)
- 리스트 기반 데이터 삭제 시 정렬 시간 복잡도 O(1)
- 힙 기반 데이터 저장 시 정렬 시간 복잡도 O(㏒ 𝘯)
- 힙 기반 데이터 삭제 시 정렬 시간 복잡도 O(㏒ 𝘯)
우선순위 큐 (Priority Queue)
- 우선순위를 가진 항목들을 저장하는 큐
스택
- 가장 나중에 들어온 데이터가 먼저 삭제
큐
- 가장 먼저 들어온 데이터가 먼저 삭제
우선순위 큐
- 가장 우선순위가 높은 데이터가 먼저 삭제
사용 예시
- 네트워크 트래픽 제어
- 운영체제의 작업 스케줄링
- 일반적으로 힙 정렬을 이용하여 사용함
병합 정렬(Merge Sort)
- 이미 정렬되어 있는 2개의 리스트를 하나의 리스트로 합병하는 방식
- 평균과 최악 모두 시간복잡도는 O(𝘯 ㏒ 𝘯)

- 평균과 최악 모두 시간복잡도는 O(𝘯 ㏒ 𝘯)
기수 정렬(Radix Sort= Bucket Sort)
- 큐(Queue)를 사용하여 자릿수(Digit)별로 정렬하는 방식
- 평균과 최악 모두 시간복잡도는 O(dn)

- 평균과 최악 모두 시간복잡도는 O(dn)
2026/02/20
8강.탐색
기억공간에 저장된 특정 데이터를 찾아내는 작업
순차 탐색
- 순서화 되어 있지 않은 데이터를 첫 번째 부터 차례대로 탐색하는 방식
제어 탐색
- 반드시 순서화 되어있는 데이터를 탐색하는 방식
- 제어탐색 방식은 아무리 빨라도 시간복잡도가 O(㏒ 𝘯)
- 메모리를 많이 사용하더라도 시간복잡도를 더 줄일 수 있는 방법
해싱(Hashing)
-
(1) 이진 탐색(Binary Search)
- 전체 데이터를 두 개의 서브 데이터 세트로 분리해 가면서 찾고자 하는 데이터를 탐색하는 방식
- 가장 뛰어남
특징
- 비교 횟수를 거듭할수록 검색 대상이 되는 데이터 수가 절반으로 줄어들기에
- 탐색 효율이 가장 좋음

- 탐색 효율이 가장 좋음
- 비교 횟수를 거듭할수록 검색 대상이 되는 데이터 수가 절반으로 줄어들기에
- 전체 데이터를 두 개의 서브 데이터 세트로 분리해 가면서 찾고자 하는 데이터를 탐색하는 방식
-
(2) 피보나치 탐색(Fibonacci Search)
- 피보나치 수열에 따라 다음 비교할 대상을 선정하며, 가감산만을 활용하기에 효율이 우수
-
(3) 보간 탐색(Interpolation Search)
- 찾으려는 데이터가 있을법한 부분의 키를 택하여 탐색하는 방식
- 예측을 해야 하므로 프로그래밍 불가
- 찾으려는 데이터가 있을법한 부분의 키를 택하여 탐색하는 방식
-
(4) 블록 탐색(Block Seach)
- 여러 데이터를 Block 단위로 구성하여 저장해놓고,
- 어느 Block에 있는지 확인하여 탐색
- 여러 데이터를 Block 단위로 구성하여 저장해놓고,
-
(5) 이진 트리 탐색(Binary Tree Search)
- 이진 검색 트리로 구성하여 탐색하는 방식
이진 검색 트리
- 왼쪽 자식 노드의 값은 부모 노드 값보다 작고 오른쪽 자식 노드 값은
- 부모 노드 값보다 큰 값을 갖도록 구성한 트리
- 이진 검색 트리로 구성하여 탐색하는 방식
블록 탐색과 이진 트리 탐색
-
블록 탐색 사용
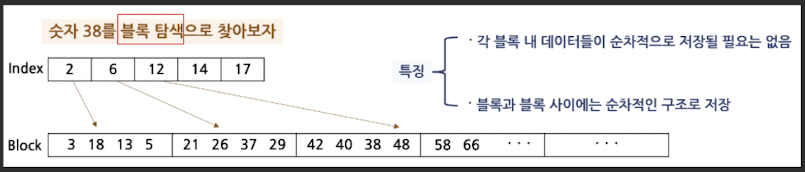
-
이진 트리 탐색
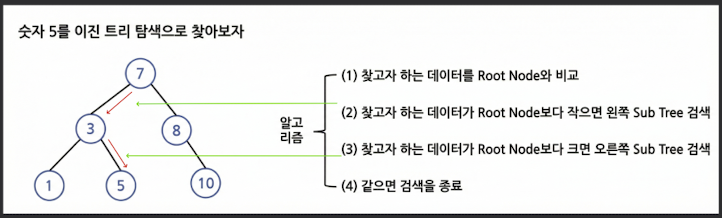
2026/02/21
9강. 탐색-해싱(Hashing)
제어탐색 방식은 아무리 빨라도 시간복잡도가 O(㏒ 𝘯)
- 메모리를 많이 사용하더라도 시간복잡도를 더 줄일 수 있다면?
해싱(Hashing)
- 각각의 데이터를 고유한 숫자 값으로 표현하고
- 이를 통하여 기억장소에 저장하거나 검색 작업을 수행하는 방식
특징
- 해시 함수(Hash Function)을 이용하여, 해시 테이블(Hash Table)에 인덱스를 계산
- 다른 방식에 비해 검색 속도가 가장 빠름(O(1))
- 삽입, 삭제의 빈도가 많을 때 유리한 방식
- Key-Value 변환 방법
- 데이터 검색과 저장 뿐만 아니라 데이터 무결성 검사, 암호화에도 활용
해시 함수(Hash Function)
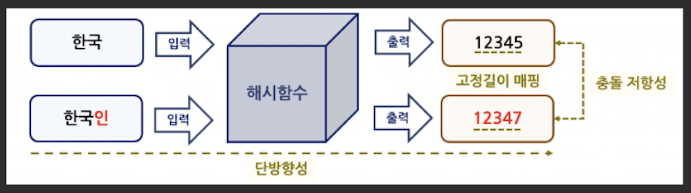
- 임의의 길이를 가진 데이터를 입력 받아 고정된 길이의 값(해시 값)을 출력하는 함수
- 함수: 입력 → 내부로직 → 출력
- 입력되는 값이 1000자 이상일 경우 그걸 해시함수에 넣어서 해시값을 받아놓으면
- 해시값의 변경여부에 따라 입력값의 변경 여부를 알 수 있다.
특징
- 단방향성
- 임이의 데이터를 입력받아서 출력하는 값은 알 수 있다
- 하지만 출력값을 통해 입력값을 알 수는 없다
- 고정길이 매핑
- 데이터의 입력값은 달라도 출력값은 고정된 값으로 받는다
- 충돌 저항성
- 입력되는 값이 서로 다르면 출력되는 값도 서로 다르다
- 단방향성
해시 테이블(Hash Table)
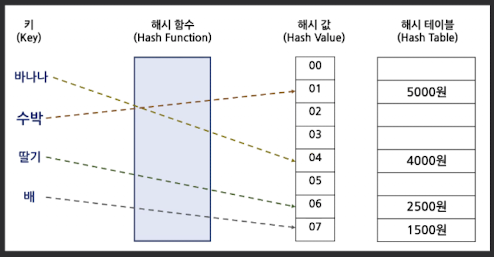
- 데이터가 저장되는 곳으로
- 해시 함수를 통해 산출된 해시 값(Hash Value)을 인덱스로 하여 데이터를 저장
- 공간을 할당하기 때문에 공간의 낭비는 있지만 탐색속도가 상당히 빨라진다.
해시 충돌(Collision)
- 해시 함수가 서로 다른 Key에 대하여 같은 값을 반환하여
- 같은 위치에 두 개 이상 데이터가 저장되는 현상
Open Hasing
- Chaining, 혹은 Close Addressing 기법이라고도 하며
- 해시 테이블, 저장공간 이외 공간 활용
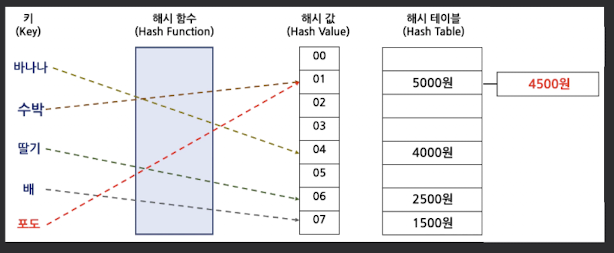
- 해시 테이블, 저장공간 이외 공간 활용
- Chaining, 혹은 Close Addressing 기법이라고도 하며
Close Hashing
- Linear Probing, 혹은 Open Addressing 기법이라고도 하며
- 해시 테이블 공간 안에서 순차적으로 다음 빈 공간에 정장
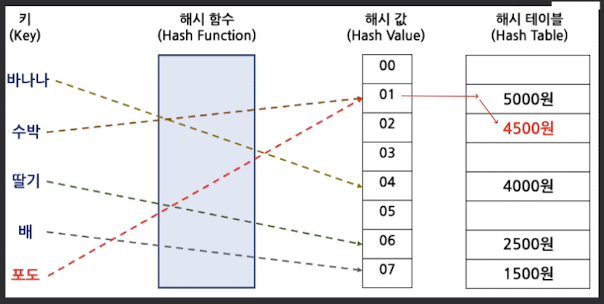
- 해시 테이블 공간 안에서 순차적으로 다음 빈 공간에 정장
- Linear Probing, 혹은 Open Addressing 기법이라고도 하며
2022/02/22
10강. 인덱스와 파일구조
인덱스
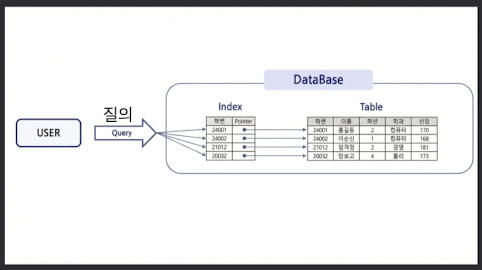
데이터베이스의 테이블에 대한 검색 속도를 향상시켜주는 자료구조
-
특징
- 테이블을 검색하는 속도와 성능이 향상
- 데이터가 저장된 물리적 구조와 밀접한 관계
- 인덱스를 관리하기 위한 추가 작업 및 저장 공간 필요
- 잘못 사용하는 경우 오히려 성능 저하 발생
-
B-Tree
- 탐색 성능을 높이기 위해 균형 있게 높이를 유지하는 검색 트리
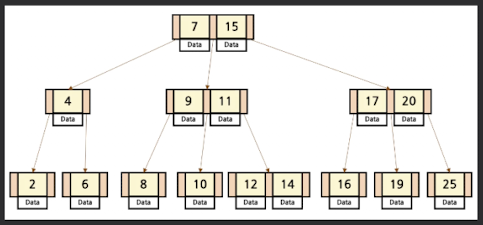
특징
- Node의 Key의 수가 k개라면, 자식 Node의 수는 k+1개
- Node의 key는 오름차순을 유지
- 모든 Leaf는 같은 Level에 존재
- Root Node는 항상 2개 이상의 자식 Node를 가짐
- 탐색 성능을 높이기 위해 균형 있게 높이를 유지하는 검색 트리
-
B+Tree
- B-Tree에서 확장된 트리로서, Leaf 노드를 제외하고는 데이터를 저장하지 않는 트리
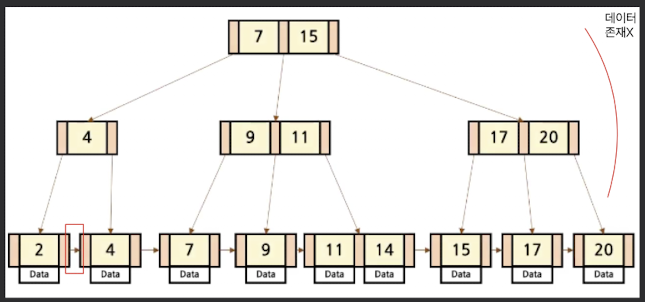
- 특징
- Internal Node는 Key와 Pointer만을 저장하여 메모릿 효율이 좋음
- 탐색 시 Leaf Node간 Linked List로 연결되어 있어 선형 시간이 소요
- B-Tree에서 확장된 트리로서, Leaf 노드를 제외하고는 데이터를 저장하지 않는 트리
-
Hash Table
- key를 찾으면 key에 해당하는 value를 찾을 수 있다.
파일구조
- 보조기억장치에 파일을 구성하는 데이터들을 저장하는 방식
순차 파일(Sequential File)
- 데이터를 물리적으로 연속 공간에 순차적으로 기록하는 방식
- 가장 간단하여 어떤 매체에서도 용이하게 사용
- 연속적인 공간에 저장하므로 메모리 효율이 높음
- 삽입/삭제 시 전체를 복사하므로 시간이 많이 소요
- 순차적으로 검색 하기에 검색 효율 및 응답 시간이 낮음
- 데이터를 물리적으로 연속 공간에 순차적으로 기록하는 방식
직접 파일(Direct File)
- 데이터를 특정 순서 없이 해시함수를 활용하여 물리적 저장공간에 임의로 기록하는 방식
- 접근 시간이 빠르고 삽입, 삭제, 갱신이 용이
- 어떤 데이터라도 평균 접근 시간내 검색이 가능
- 데이터 주소 변환을 위한 메모리 효율 저하
- 기억장치의 물리적 구조를 알아야 하며, 프로그래밍 복잡
- 데이터를 특정 순서 없이 해시함수를 활용하여 물리적 저장공간에 임의로 기록하는 방식
색인 순차 파일(Indexed Sequential File)
- 데이터를 키 값 순으로 정렬(Sort)시켜 기록하고, 색인(Index)을 구성하여 편성하는 방식
구성 요소
기본 구역(Prime Area)
- 실제 데이터가 기록되는 구역
색인 구역(Index Area)
- 기본 구역을 찾아가기 위한 Index로 구성
- (Track Index < Cylinder Index < Master Index)
오버플로 구역(Overflow Area)
- 기본 구역에 빈 공간이 없어 새로운 데이터 삽입이 불가할 때를 대비한 공간
특징
- 순차처리와 랜덤처리가 모두 가능하여, 융통성 있는 활용 가능
- 효율적인 검색, 삽입, 삭제 갱신이 가능
- 색인 구역과 오버플로 구역을 구성하기 위한 추가 기억공간이 필요
- 데이터를 키 값 순으로 정렬(Sort)시켜 기록하고, 색인(Index)을 구성하여 편성하는 방식

안녕하세요.