map
A,B = map(int,input().split())- "정수"형태의 입력값 A,B를 한번에 받는다.
numbers = list(map(int,input().split()))- 위의 변수명 A,B처럼 여러개의 변수명을 선언할 필요 없이 한번에 입력받기가 가능
index
a = list.index(b)- 리스트안에서의 b의 위치를 인덱스값으로 반환
- 인덱스값은 0부터 시작하기 때문에 1부터 시작하고 싶다면 출력할때 a+1로 하면됨
set
list(set(list))- 순서를 신경 쓸 필요 없을경우 유용
- 리스트 내부의 중복되는 값을 제거함
sys.stdin.readline()
- "입력 속도를 비약적으로 높여주는 도구"
- 보통 input() 대신 sys.stdin.readline()을 사용함
사용 이유
- input()
- 사용 편의성을 위해 여러 가지 내부 처리를 거침
- 입력받은 값의 끝에 있는 줄바꿈 문자(\n)를 자동으로 제거
- input("입력하세요: ")처럼 안내 문구를 출력할 수 있는 기능이 있어 추가적인 부하가 발생
- 사용 편의성을 위해 여러 가지 내부 처리를 거침
- sys.stdin.readline()
- 데이터를 한 번에 뭉텅이(버퍼)로 읽어오는 방식(대량의 데이터를 읽을 때 훨씬 빠름)
비교
- 입력데이터가 10만개 100만개 등등 비약적으로 많아질 경우
- input()을 쓰면 '시간 초과(Time Limit Exceeded)'가 날 확률이 매우 높음
- sys.stdin.readline()을 쓰면 가볍게 통과하는 경우가 많음
- 입력데이터가 10만개 100만개 등등 비약적으로 많아질 경우
사용 시기
- 입력 개수가 10,000개 이상인 문제
- 반복문 안에서 input()을 호출해야 할 때
- 일반적인 문제
- 습관적으로 써두면 시간 초과 걱정을 덜 수 있어 좋음
주의
- sys.stdin.readline()은 문장의 끝에 있는 줄바꿈 문자(\n)까지 통째로 읽어옴
- 예를 들어 hello라고 치면 "hello\n"이 저장됨
- 문자열을 다룰 때는 반드시
.rstrip()을 붙여서 공백을 제거해주는 것이 좋음
- sys.stdin.readline()은 문장의 끝에 있는 줄바꿈 문자(\n)까지 통째로 읽어옴
- input()
사용법
import sys
# 1. 문자열 한 줄 읽기
data = sys.stdin.readline()
# 2. 정수 하나 읽기
n = int(sys.stdin.readline())
# 3. 여러 개의 정수를 한 줄에서 읽기 (가장 많이 사용!)
a, b, c = map(int, sys.stdin.readline().split())팁
- sys.stdin.readline()을 길게 치는 건 번거로움
import sys
input = sys.stdin.readline # 이제 input()을 호출하면 자동으로 readline이 작동합니다.
# 평소처럼 사용하면 됨 (속도는 훨씬 빠름!)
n = int(input())정렬
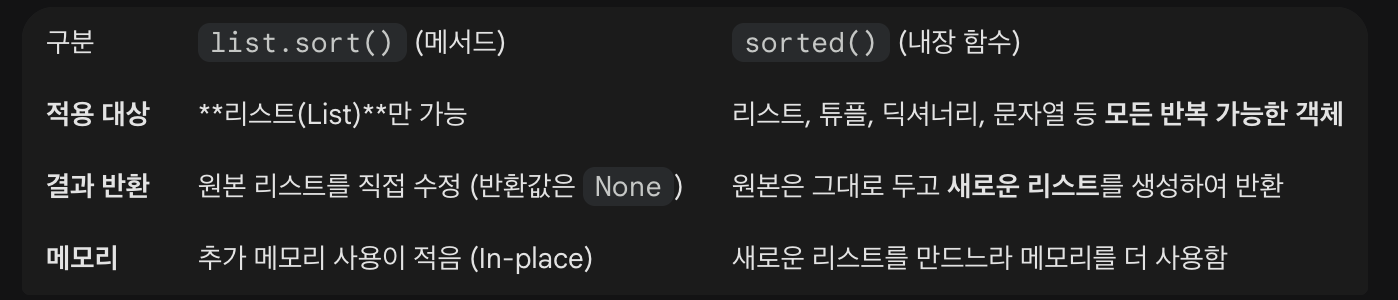
sort() 메소드 (제자리 정렬)
- 리스트 자체를 직접 수정하여 정렬합니다.
- 원본 리스트를 유지할 필요가 없을 때 사용하며, 메모리를 아낄 수 있습니다.
nums = [5, 2, 9, 1, 5]
nums.sort() # 원본인 nums 리스트가 [1, 2, 5, 5, 9]로 변함
print(nums)
words = ["banana", "apple", "cherry", "Apple"]
words.sort()
print(words) # 결과: ['Apple', 'apple', 'banana', 'cherry']sorted() 함수 (새로운 리스트 반환)
- 원본 리스트는 그대로 두고, 정렬된 새로운 리스트를 만들어 반환합니다.
- 원본 데이터가 나중에 필요할 때 유용합니다
nums = [5, 2, 9, 1, 5]
new_nums = sorted(nums) # nums는 그대로, new_nums만 정렬됨
print(new_nums) # [1, 2, 5, 5, 9]
print(nums) # [5, 2, 9, 1, 5]사용자 정의 정렬(key 활용)
- key 파라미터에 함수를 전달하면, 그 함수의 결과값을 기준으로 정렬을 수행
단일 기준 정렬 (예: 문자열 길이순)
words = ["apple", "it", "banana", "kiwi"]
# len(문자열의 길이)을 기준으로 정렬
words.sort(key=len)
print(words) # 결과: ['it', 'kiwi', 'apple', 'banana']다중 기준 정렬 (lambda 활용)
- "먼저 길이순으로 정렬하고,
- 길이가 같다면 알파벳 순으로 정렬해줘"와 같은 복합 조건이 필요할 때 lambda를 사용
# (나이, 이름) 형태의 리스트
members = [(25, "John"), (20, "Alice"), (25, "Bob"), (20, "David")]
# 1순위: 나이(x[0]) 오름차순
# 2순위: 이름(x[1]) 알파벳순
members.sort(key=lambda x: (x[0], x[1]))
print(members)
# 결과: [(20, 'Alice'), (20, 'David'), (25, 'Bob'), (25, 'John')]
- # "길이순" 정렬 후 "알파벳순" 정렬
words = ["apple", "bat", "banana", "art", "kiwi", "ace"]
# 1순위: 길이(len(x)) 오름차순
# 2순위: 알파벳(x) 사전순
words.sort(key=lambda x: (len(x), x))
print(words)
# 결과: ['ace', 'art', 'bat', 'kiwi', 'apple', 'banana']
# 설명: 'ace', 'art', 'bat'은 모두 길이가 3으로 같지만, 2순위인 사전순으로 정렬되었습니다.
- # "길이순(오름차순)" + "사전순(내림차순)"
words = ["apple", "bat", "banana", "art", "kiwi", "ace"]
# 1순위: 길이(len(x)) 내림차순 (큰 것부터)
# 2순위: 사전순(x) 오름차순
# 숫자인 길이에 -를 붙여서 큰 값이 가장 작게 인식되게 만듭니다.
words.sort(key=lambda x: (-len(x), x))
print(words)
# 결과: ['banana', 'apple', 'kiwi', 'ace', 'art', 'bat']sorted
기본
numbers = [10, 1, 5, 8, 2]
# 오름차순 정렬
print(sorted(numbers)) # [1, 2, 5, 8, 10]
# 내림차순 정렬 (큰 숫자부터)
print(sorted(numbers, reverse=True)) # [10, 8, 5, 2, 1]딕셔너리 정렬
data = {'apple': 3, 'banana': 1, 'cherry': 2}
# 키 기준 정렬
print(sorted(data))
# 결과: ['apple', 'banana', 'cherry']
# 값(Value) 기준으로 정렬하고 싶을 때 (람다 활용)
print(sorted(data.items(), key=lambda x: x[1]))
# 결과: [('banana', 1), ('cherry', 2), ('apple', 3)]문자열 정렬
text = "python"
print(sorted(text))
# 결과: ['h', 'n', 'o', 'p', 't', 'y']숫자 하나 의 자릴수 정렬
n = 5291
# 1. 문자열 변환 -> 2. sorted로 정렬(리스트 반환) -> 3. 다시 합치기 -> 4. 정수 변환
sorted_n = int("".join(sorted(str(n))))
print(sorted_n) # 1259유용한 정렬 옵션
- reverse=True: 내림차순 정렬이 필요할 때 사용합니다.
- key 파라미터: 정렬 기준을 직접 정할 때 사용합니다.
words = ['banana', 'pie', 'apple', 'kiwi']
# 길이를 기준으로 정렬
short_words = sorted(words, key=len)
print(short_words)
# 결과: ['pie', 'kiwi', 'apple', 'banana']N = int(input())
S = int("".join(sorted(str(N),reverse=True)))
print(S)set
# 'a', 'b' 등을 문자열로 감싸주어야 합니다.
A = ['a', 'a', 'b', 'b', 'c', 'c', 'c', 'd']
B = list(set(A))
# set은 순서를 보장하지 않으므로 결과 순서는 바뀔 수 있습니다.
print(B)
# 결과 예시: ['c', 'd', 'b', 'a'] 또는 ['a', 'b', 'c', 'd']ceil
- 올림
리스트 안의 내용물만 공백으로 구분해서 출력
join 메서드 사용
- 리스트의 요소가 문자열(str)일 때 사용할 수 있는 가장 세련된 방법
- 리스트 안에 숫자(int)가 들어있다면, 먼저 문자열로 변환하는 과정이 필요
# 리스트 요소가 문자열인 경우
arr = ['1', '2', '3', '4']
print(" ".join(arr))
# 리스트 요소가 숫자인 경우 (map 사용)
nums = [1, 2, 3, 4]
print(" ".join(map(str, nums)))Unpacking 연산자 (*) 사용
- print 함수에 리스트를 넘길 때 앞에
*를 붙이면, 리스트의 요소를 하나씩 낱개로 풀어서 전달 - 별도의 변환(map) 과정 없이 숫자 리스트도 바로 출력 가능
- print 함수에 리스트를 넘길 때 앞에
nums = [1, 2, 3, 4]
print(*nums)반복문과 end 파라미터 사용
- 복잡한 조건이 필요하거나 알고리즘의 흐름을 직접 제어하고 싶을 때 사용
- print 함수는 출력 후 기본적으로 줄바꿈을 하지만, end 옵션을 주면 줄바꿈 대신 다른 문자를 넣을 수 있음
- 단점: 마지막 숫자 뒤에도 공백이 하나 더 붙게됨
nums = [1, 2, 3, 4]
for x in nums:
print(x, end=" ")Counter
collections.Counter는 파이썬에서 "항목의 개수를 세는 기계"- 리스트나 문자열 같은 반복 가능한(iterable) 객체를 넣으면,
- 각 요소가 몇 번 등장했는지 세어서 딕셔너리 형태로 반환해 줌
Counter의 기본 작동 원리
from collections import Counter
# 리스트 안의 요소 개수 세기
my_list = ['apple', 'blue', 'apple', 'red', 'red', 'apple']
count_result = Counter(my_list)
print(count_result)
# 출력: Counter({'apple': 3, 'red': 2, 'blue': 1})
# 특정 요소의 개수 확인
print(count_result['apple']) # 3
print(count_result['grape']) # 0 (없는 키를 넣어도 에러 대신 0을 반환!)성능
- list.count()와 Counter를 비교
- list.count(x)
- 리스트를 처음부터 끝까지 다 훑으면서 x가 몇 개인지 찾습니다.
- 리스트 길이를 N, 찾는 횟수를 M이라 하면 전체 시간 복잡도는
O(N X M)
- Counter(list)
- 리스트를 단 한 번만 훑으면서
(O(N))모든 요소의 개수를 세어 딕셔너리에 저장합니다. - 그 후 개수를 찾는 건 딕셔너리 조회
(O(1))이므로, 전체 시간 복잡도는O(N + M)
- 리스트를 단 한 번만 훑으면서
- list.count(x)
유용한 기능
- most_common(n)
- 가장 많이 등장한 상위 n개의 요소를 리스트 안의 튜플 형태로 반환합니다.
c = Counter('abracadabra')
print(c.most_common(2))
# 출력: [('a', 5), ('b', 2)] (가장 많이 나온 순서대로 2개)- Counter끼리는 더하기, 빼기, 교집합, 합집합 연산이 가능
c1 = Counter(a=3, b=1)
c2 = Counter(a=1, b=2)
print(c1 + c2) # Counter({'a': 4, 'b': 3})
print(c1 - c2) # Counter({'a': 2}) (결과가 0 이하면 출력에서 제외됨)sys.stdin.read
- input()이나 sys.stdin.readline()은 한 줄씩 읽어오지만
- sys.stdin.read()는 입력값 전체를 하나의 거대한 문자열로 통째로 읽어옴
사용 예시
# 입력 데이터
3 4
ohhenrie
charlie
baesangwook
obama
baesangwook
ohhenrie
clinton
- sys.stdin.read() 실행 직후
- "3 4\nohhenrie\ncharlie\nbaesangwook\nobama\nbaesangwook\nohhenrie\nclinton"
- 이라는 하나의 거대한 문자열이 생성
- .split() 실행 직후
- 공백이나 줄바꿈을 기준으로 문자열을 쪼개서 하나의 리스트로 만듬
['3', '4', 'ohhenrie', 'charlie', 'baesangwook', 'obama', 'baesangwook', 'ohhenrie', 'clinton']
- "3 4\nohhenrie\ncharlie\nbaesangwook\nobama\nbaesangwook\nohhenrie\nclinton"
.split()
- .split() 함수는 인자(괄호 안)를 비워두면
- 스페이스(공백), 탭(\t), 엔터(줄바꿈, \n)를 모두 똑같은 '나누는 기준'으로 봄
- .split() 함수는 인자(괄호 안)를 비워두면
# 1번 입력 방법
3 4 ohhenrie charlie baesangwook ...
# 2번 입력 방법
3 4
ohhenrie
charlie
baesangwook
...
# 결과 (data 리스트) (동일)
['3', '4', 'ohhenrie', 'charlie', 'baesangwook', ...] 종료
- input()은 엔터를 치면 즉시 다음 코드로 넘어가지만
- sys.stdin.read()는 "이제 입력이 진짜 끝났다(EOF)"라는 신호를 줄 때까지 계속 기다림
- 입력을 다 치고 Ctrl + D
집합(set) 연산자
& (교집합 연산)
- set(집합) 자료구조에 사용하는 & 연산자는 수학의 '교집합'과 똑같은 역할
- 즉, "두 곳에 모두 포함된 데이터만 골라내기"를 수행
# 집합 정의
A = {"철수", "영희", "길동"}
B = {"영희", "길동", "민수"}
# 교집합 연산 (&)
result = A & B
print(result)
# 결과: {'영희', '길동'} | (합집합 연산)
- 두 집합의 모든 원소를 합칩니다. (중복된 값은 알아서 하나만 남깁니다.)
A = {"철수", "영희", "길동"}
B = {"길동", "민수", "희수"}
result = A | B
# 결과: {'철수', '영희', '길동', '민수', '희수'}- (차집합)
- 앞의 집합에서 뒤의 집합과 겹치는 원소를 빼버립니다.
A = {"철수", "영희", "길동"}
B = {"길동", "민수", "희수"}
result = A - B
# 결과: {'철수', '영희'} (A에서 길동이가 빠짐)^ (대칭 차집합)
- 둘 중 한 곳에만 속한 원소들을 합칩니다. (즉, 공통된 부분만 쏙 뺍니다.)
A = {"철수", "영희", "길동"}
B = {"길동", "민수", "희수"}
result = A ^ B
# 결과: {'철수', '영희', '민수', '희수'} (공통인 길동이만 빠짐)출력 최적화
- 출력해야 할 명단이 수십만 개라면
- for문 안에서 print()를 반복하는 것보다 문자열을 하나로 합쳐서 한 번에 출력하는 것이 더 빠를 수 있음
'\n'.join(result)- 리스트의 모든 요소를 줄바꿈 문자(\n)로 연결해 하나의 거대한 문자열로 만든 뒤 한 번에 출력하는 기법
# 지금 방식
for name in result:
print(name)
# 추천 방식 (Join 활용)
print('\n'.join(result))이항계수
이론
- 주어진 집합에서 순서에 상관없이 원소를 선택하는 방법의 가짓수를 의미

공식
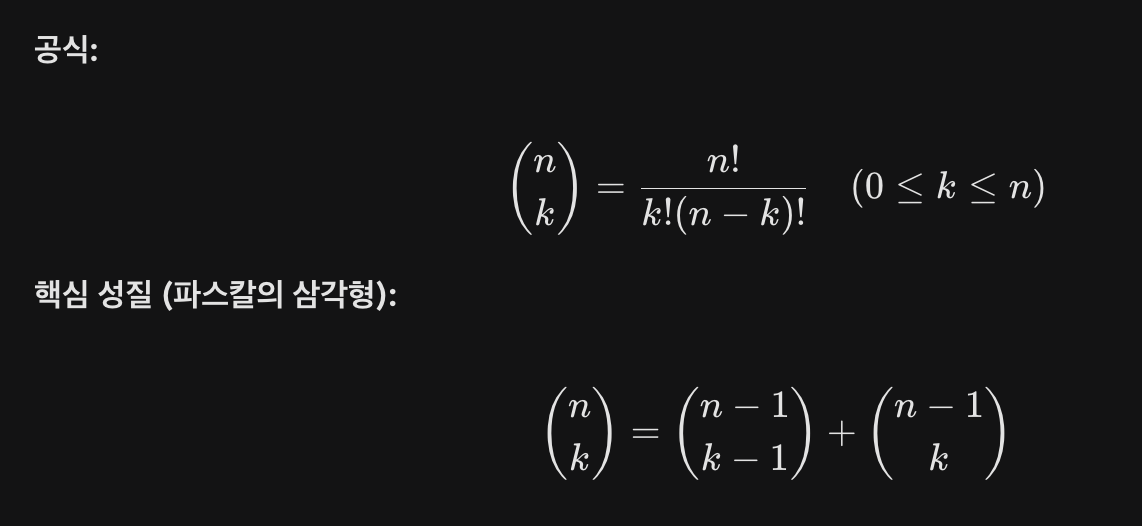
문제 분석 및 접근 방식
n과 k가 작은 경우 (n <= 30)
- 단순 팩토리얼 계산이나 재귀로 해결 가능
n이 적당히 큰 경우 (n <= 1000)
- O(n^2)의 시간 복잡도를 가지는 동적 계획법을 사용
n이 매우 크고 소수 M으로 나눈 나머지를 구할 때
- 페르마의 소정리를 이용한 O(n) 풀이가 필요
if __name__ == '__main__':
- 이 문장은 파이썬 파일이 직접 실행되었을 때만 특정 코드를 동작시키게 만드는 '안전장치'
def solve_dp():
...
if __name__ == '__main__':
solve_dp()직접 실행할 때 (주인공)
- 우리가 파이썬 파일을 직접 실행하면 파이썬은 이 파일의 이름을
__main__이라고 인식 - 그래서 조건문이 참(True)이 되어 solve_apart()가 실행
- 우리가 파이썬 파일을 직접 실행하면 파이썬은 이 파일의 이름을
다른 파일에서 불러올 때 (조연)
- 만약 다른 파일에서
import my_code처럼 이 파일을 부품으로 가져다 쓴다면,- 이름이
__main__이 아니라 파일명으로 인식됨
- 이름이
- 이때는 조건문이 거짓(False)이 되어 내부 코드가 멋대로 실행되지 않음
- 만약 다른 파일에서

안녕하세요.