Redis
데이터베이스, 캐시, 메시지 브로커 및 대기열로 사용하는 빠른 오픈 소스 인 메모리 데이터 스토어
출처 : 우아한테크코스
- 외부 hashMap(key-val) server
- 용량이 많아지면 key값이 너무 많아진다는 문제가 잇다
- database, cache, message broker
- in-memory Data Structure Store
cache
나중의 요청에 대한 결과를 미리 저장했다가 빠르게 사용하는 것
빠르고 비싸고 용량이 적다
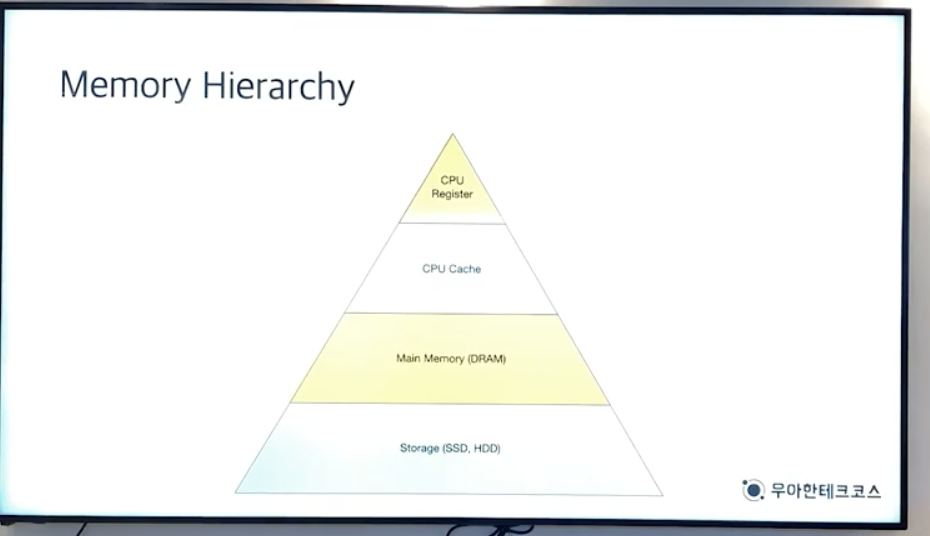
위로 갈수록 비싸고 빠르다
- cache : 빠르고 비싸고 용량이 적다
- Main Memory : 휘발성,컴터 끄면 날아감, 상대적 저렴 - 기술 발달로 원래 storage에서 쓰다가 여기를 사용하기 시작함 ex. In-memory database (cache)
- Storage (SSD, HDD) : 느림 저렴 비휘발성(영구적)
redis
- vs memcached
- 가장 큰 차이점 : 자료구조
- java와 공통점 : string, list, set, sorted set, hash
- java의 한계 (위의 자료구조를 사용해서 저장하지 않고 redis를 쓰는 이유)
- 서버가 여러대인 경우 consistency 문제 발생 가능
- muli-threaded 환경에서 race condition
- redis를 통한 극복
- redis는 기본적으로 single threaded
- redis 자료구조는 atomic critical section에 대한 동기화 제공
cf. critical section : 동시에 여러 thread가 접근해서 안 되는 영역 - 서로 다른 transaction read/write를 동기화
- redis를 쓰는 곳
- 여러 서버에서 같은 데이터 공유할 때
- single server라면? atomic 자료구조 & cache
- redis를 쓸 때 주의해야 할 점
- single thread 서버이므로 시간 복잡도를 고려해야 한다
(하나라도 느리면 지연될 수 있으므로 빨리빨리 처리해야 한다) - in-memory 특성상 메모리 파편화, 가상 메모리 등의 이해가 필요하다
cf. single threaded
- event-driven
- IO-bound process : CPU보다는 메모리 IO 관련 일을 하기 때문에 CPU optimization에 맞지 않다
- context switching의 효율이 적다
cf. Memory 관리
- 메모리 파편화 : 메모리를 할당받고 해제하는 과정에서 빈 공간이 생기는데 할당다가 빈공간이 생겨 필요 이상으로 redis를 쓴다. 그러므로 redis 사용 시 필요한 것보다 더 많이 메모리를 할당해야 한다.
- 가상메모리 SWAP : 프로세스를 메모리에 일부만 올려서 사용하고 잘 안 쓰는 건 backing store(디스크)에 놓고 필요할 때만 불러옴. 불러올 때 latency가 일어나서 single thread의 경우 문제가 생길 수 있다.
- replication - fork : 휘발성을 가지고 있기 때문에 유실 문제를 유념해야. 3ㅔ이터를 복사해서 디스크 등 어디든 전송을 해둬야 한다. 이런 복사와 참조의 과정을 fork라고 하는데 메모리가 가득 차있다면 제대로 복사가 되지 않으니까 주의!
이외
- redis persistent, rdb, aof
- redis cluster
- constant hashing
- data grid
cf. race condition
: 여러 개의 thread가 경합해서 context switching에 따라 원하지 않는 결과 발생

노션 : https://garrulous-gander-3f2.notion.site/c488d337791c4c4cb6d93cb9fcc26f17