console.table(2차원 배열) //표로 나타낸다
목표
- 3 Tier Architecture 를 이해한다.
: server - client - db
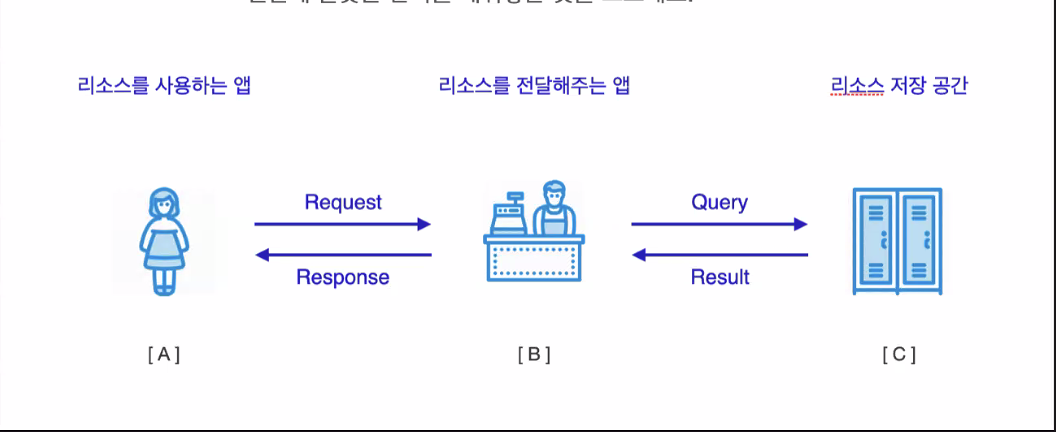
1)클라이언트: 서버에 요청을 보내고 응답을 받는다
presentational layer, UI라고도 한다
2)서버 : 요청을 받고 응답을 보낸다
application tier
3)DB : 2티어에서는 저장소와 전달을 동시에 했다면 데이터가 복잡하고 많아지면서 저장소가 따로 필요해짐
query로 정보를 달라고 하고 result를 받는다
(SSR에서는 db를 server에서, CSR에서는 db를 client에서)
data tier
=> 기능적으로 분리를 하기 때문에
1)에러 핸들링(유지보수)에 용이
2)기능적 분리 : 각각에 집중
-
영속성의 개념을 이해하고, 데이터베이스의 필요성을 인지한다.
: persistency
: db의 필요성(목적) -
데이터베이스 종류를 이해한다.
- 관계형 데이터베이스 vs NoSQL의 차이 이해
SQL 주요 내용
- SQL 주요 문법을 이해할 수 있다.
- 조회(read), 삽입(create), 갱신(update?), 삭제(delete) 구문 : crud
- 조회 시 다양한 조건을 걸어 원하는 정보만 조회 : get요청 할 때 query
- 통계를 위한 쿼리를 만들 수 있다.
- 스키마 디자인을 할 수 있다.
- 앱에 필요한 테이블, 필드, 관계 부여
- 1:N, N:N 관계를 이해하고, 데이터베이스에서 테이블을 조작
- Foreign Key, Primary Key 이해
SQL 소개
데이터베이스의 필요성
데이터 저장하는 방법
1) 파일에 데이터 저장
2) 인메모리 형태로 임시 저장
3) 데이터베이스
4) 이외 : 엑셀 시트, CSV 파일 등
- File I/O
파일을 읽는 방식으로 작동하는 형태
ex. 엑셀 시트, CSV 같은 파일
In-Memory에 비해 데이터를 저장하는 방식으로 적절
한계 :
- 데이터가 필요할 때마다 전체 파일을 매번 읽어야 한다
=> 파일의 크기가 커질수록 비효율적 - 복잡하고 데이터량이 많아질수록 데이터를 불러들이는 작업이 점점 힘들어진다
=> ex. 파일 손상 or 여러 개의 파일들을 동시에 다뤄야 하거나 등
- In-memory
: JS에서 데이터를 다룰 때, 프로그램이 실행될 때에만 존재하는 데이터
ex. 변수를 만들어 저장한 경우
프로그램이 종료될 때 해당 프로그램이 사용하던 데이터도 사라진다
즉 변수 등에 저장한 데이터가 프로그램의 실행에 의존
단점
-예기치 못한 상황으로부터 데이터를 보호할 수 없다
-프로그램이 종료된 상태라면 데이터를 원하는 시간에 받아올 수 없다
-데이터의 수명이 프로그램의 수명에 의존
- 관계형 데이터베이스
하나의 csv 파일이나 엑셀 시트처럼 1)의미에 따라 분류 되어 있고 2)여러 개의 정리된 정보를
=> 한 개의 테이블로 저장 가능
대용량 데이터 외의 다른 목적, 기능들 충족
한 번에 여러 개의 테이블을 가질 수 있기 때문에 SQL을 활용해 데이터 불러오기 수월
SQL 소개
Structured Query Language(SQL)
즉 구조화된 쿼리 언어, 관계형 데이터베이스용 프로그래밍 언어
SQL
: 관계형 데이터베이스(데이터가 구조화된 테이블 사용하는 데이터베이스)에서 사용하는 언어
: 데이터베이스에 쿼리를 보내 원하는 데이터를 가져오거나 삽입할 수 있다
ex. MySQL, Oracle, SQLite, PostgreSQL 등 다양 데이터베이스에서 SQL 구문 사용 가능
NoSQL
: 데이터의 구조가 고정되어 있지 않은 데이터베이스
: 관계형 db와 달리 테이블을 사용하지 않고 다른 형태로 저장
ex. mongoDB와 같은 문서 지향 데이터베이스
=>db 종류를 sql이라는 언어 단위로 분류할 정도로 sql은 중요하다
즉, sql을 사용하기 위해서는 데이터가 구조가 고정되어 있어야 한다
테이블이라는 데이터 구조화의 유무에 따라 sql 사용 가능 유무가 갈리고 이로 인해 sql, nosql이라고 한다
쿼리란?
질의문
-> 저장되어 있는 데이터를 필터하기 위한 질의문
ex. 검색할 때 입력하는 검색어 : 기존에 존재하는 데이터를 검색어로 필터링
데이터베이스 관련 명령어
대문자, 소문자 무관
1. CREATE
1)생성
CREATE DATABASE 데이터베이스_이름;2. USE
1)사용
데이터베이스를 이용해 테이블을 만들거나 수정하거나 삭제하는 등의 작업을 하려면 먼저 사용하겠다는 명령 전달
USE 데이터베이스_이름;show databases
만든 db들을 모두 보여준다
3. CREATE TABLE table이름(column이름 타입 조건)
1)테이블 생성
USE 이용해 데이터베이스를 선택했다면 이제 테이블을 만들 수 있다
user라는 테이블을 만드는 예제
테이블은 필드(표의 열)와 함께 만들어야 한다
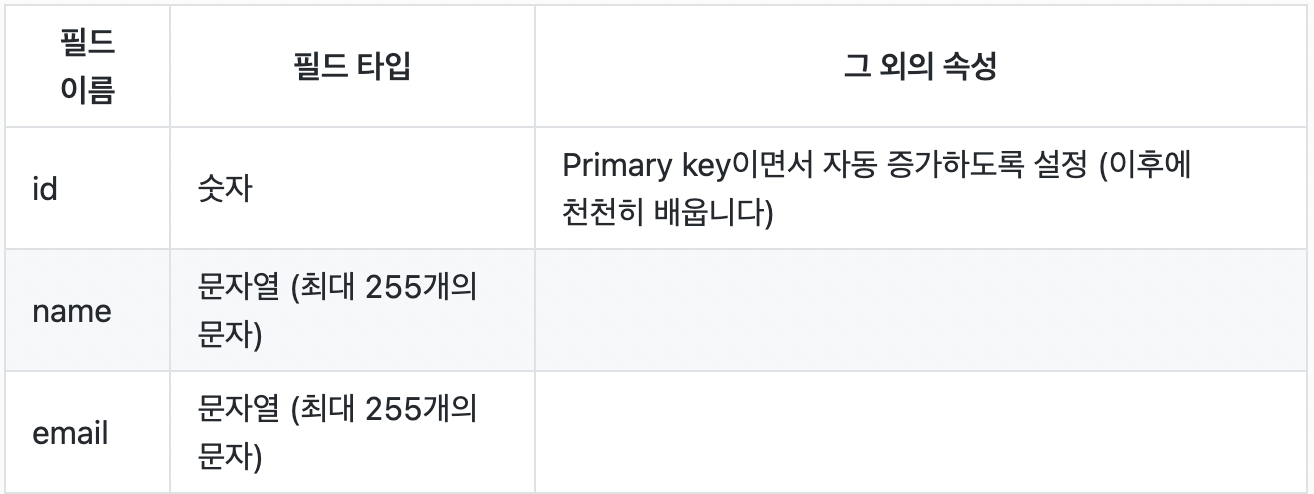
CREATE TABLE user(
id int PRIMARY KEY AUTO_INCREMENT,
name varchar(255)
email varchar(255)
)2)조건들
출처: https://blog.naver.com/pjok1122/221539169731
CREATE TABLE testTable( (1)
id INT(11) NOT NULL AUTO_INCREMENT, (2)
name VARCHAR(20) NOT NULL, (3)
ouccupation VARCHAR(20) NULL, (4)
height SMALLINT, (5)
profile TEXT NULL, (6)
date DATETIME, (7)
CONSTRAINT testTable_PK PRIMARY KEY(id) (8)
);
[출처] [MySQL] 테이블 만들기,수정하기 (Create table, Alter table)|작성자 pjok1122(2)NOT NULL은 값을 비워둘 수 없음을 의미,
AUTO_INCREMENT는 자동으로 값이 1씩 증가하도록 설정하는 옵션
=> auto 칼럼은 하나만 설정할 수 있고 반드시 key여야 한다
(3) name이라는 컬럼을 추가하는데, 가변길이로 20글자까지 허용합니다. (20글자가 넘어가면 20글자에서 자릅니다.)
(4) 위와 동일하지만, 값을 비워두는 것을 허용합니다.
(5) SMALLINT는 INT보다 가질 수 있는 값의 범위가 작습니다. 메모리 측면에서 이득입니다.
(6) TEXT는 아주 긴 문자열을 취급할 때 사용합니다.
(7) DATETIME은 날짜와 시간에 관한 타입입니다.
(8) CONSTRAINT는 제약조건이라는 의미입니다. testTable의 PRIMARY KEY를 id 컬럼으로 지정하겠다는 의미이며, 이 제약조건의 이름을 testTable_PK로 지정한 것입니다
[출처][MySQL] 테이블 만들기,수정하기 (Create table, Alter table)|작성자 pjok1122
auto increment는 pk를 default로 하나하나
ALTER TABLE 변경
테이블의 컬럼 값을 추가하거나 삭제하거나 변경하는 명령을 할 수 있습니다.
(1) ADD
추가된 칼럼은 반드시 마지막에 위치하게 됩니다.
ALTER TABLE 테이블명
ADD 추가할 칼럼명 데이터 유형;(2) DROP COLUMN
ALTER TABLE 테이블명
DROP COLUMN 삭제할 칼럼명;(3) CHANGE
ALTER TABLE 테이블명
CHANGE 컬럼명 컬럼명 새자료형칼럼의 데이터 유형, 디폴트 값, NOT NULL 제약조건에 대한 변경을 포함할 수 있습니다.
타입을 변경할 경우에는 NULL 값이 있는지, 데이터 사이즈가 맞는지 등등을 고려하여 반영해야 합니다.
(4) ADD CONSTRAINT
컬럼에 제약조건을 추가할 수 있습니다
ALTER TABLE 테이블명
ADD CONSTRAINT 제약조건명 제약조건 (칼럼명);
DROP
1)데이터베이스 삭제
DROP DATABASE 데이터베이스_이름;
2)테이블 삭제
DROP TABLE 테이블_이름;3)테이블 안에 있는 데이터 모두 삭제
Use the TRUNCATE statement to delete all data inside a table.
TRUNCATE TABLE Persons;4. DESCRIBE
1)테이블 구조 확인
DESCRIBE user;
5. SELECT[조회]
데이터셋에 포함된 특성 특정
1)테이블의 모든 행 선택
**select** * **from** 테이블_이름2)새로운 행 추가 (열 순서대로 내용ㅇ르 넣는다)
**insert into** kpop_groups **values(**default, "하이키" , 6, 2022**)** //열별 내용을 담는다, default를 쓰면 이전 행의 값+1로 다음 행에 넣는다
id name company_id debut
default "하이키" 6 2022
6.delete[삭제]
1)테이블 전체 삭제
**delete from** kpop_groups2)원하는 조건 만족하는 행만 삭제
**delete from** kpop_groups **where** name='하이키'(필터를 해준다) 7.update set [변경]
3)update set 바꾸고 싶은 내용 where 필터
UPDATE Customers SET City = 'Oslo';
UPDATE Customers SET City = 'Oslo' WHERE Country = 'Norway';
//country가 Norway vlaue를 가진 열만
primary key
db 다이어그램
안에 pk 고유한 값 (primary key)
각각의 레코드를 식별할 수 있게 하는 고유한 id
id int [pk, increment] : 알아서 +1씩 되도록 하는 조건
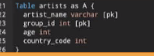
pk가 두개인 이유 : 다중 칼럼을 통해서 할 수 있다
id값을 따로 설정하는 것이 아니라 table에 있는 내용을 기준으로 고유한 값을 설정해준다
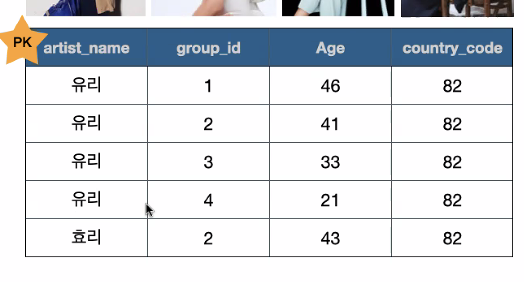
ex. 이름, group_id, age, country_code 모두 고유하지 않다
그러므로 atrist_name과 group_id를 동시에 pk로 설정
=> 같은 그룹 내에 같은 이름이 있는 사람은 없으니까
=> 실무에서는 각각 id를 부여하는 것이 더 좋으
foreign key
Foreign key : reference를 사용해서 외부에 대해 참조
N:N 관계
Question
쇼핑몰 데이터베이스에서 유저, 주문, 상품에 대한 테이블이 각각 있다
users 테이블과 orders 테이블의 관계 (1:N)
, orders 테이블과 items 테이블의 관계를 각각 골라주세요 (N:M)
: 한 유저가 여러개의 주문 생성 가능(1:N) / 하나의 주문은 한명의 유저가 생성할 수 있다 (1:1) => 1:N
하나의 주문에는 여러개의 상품이 담길 수 있다(1:N)/ 하나의 상품은 여러 개의 주문에 묶일 수 있다(1:N) => N:N
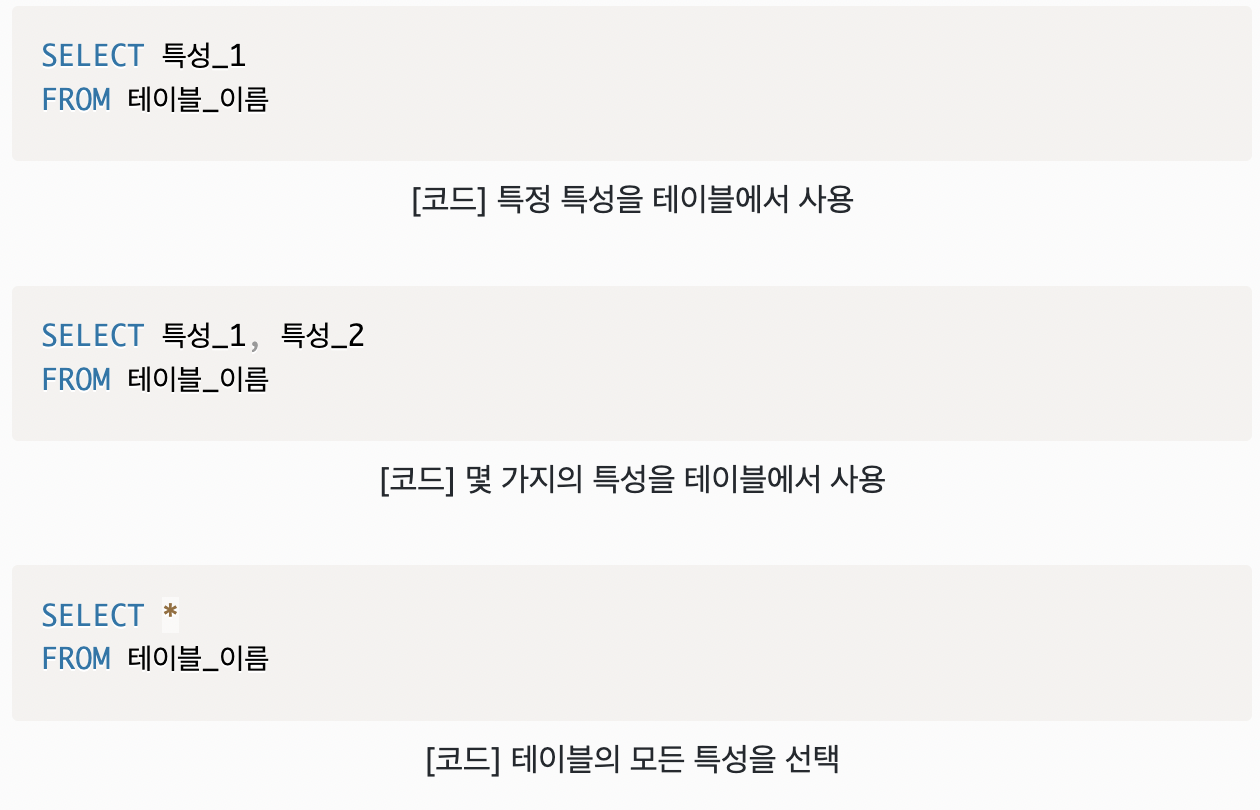
6. FROM
테이블과 관련한 작업을 할 경우 반드시 입력
from 뒤에는 결과를 도출해낼 데이터베이스 테이블 명시
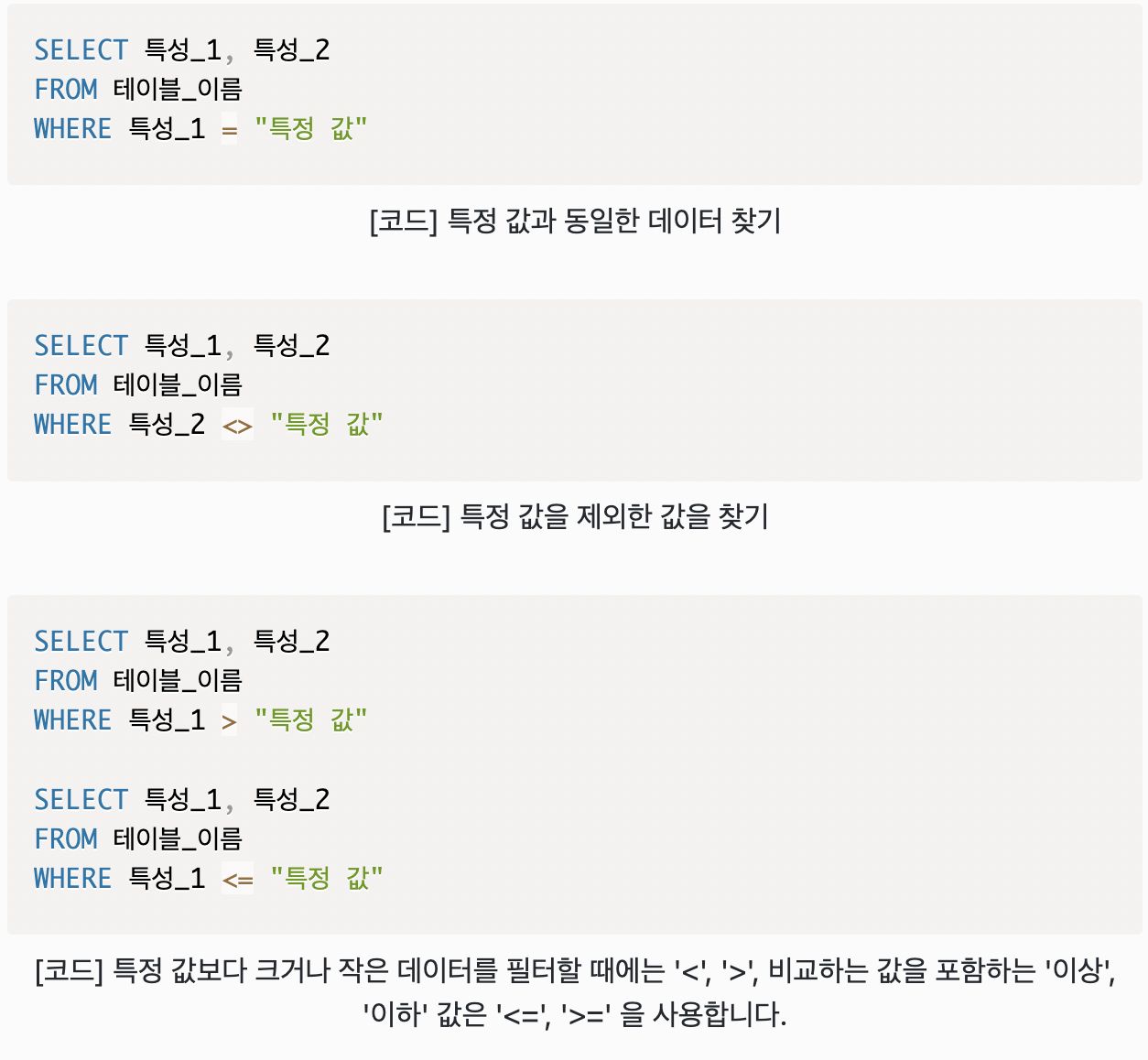
7. WHERE
필터 역할을 하는 쿼리문 (선택)
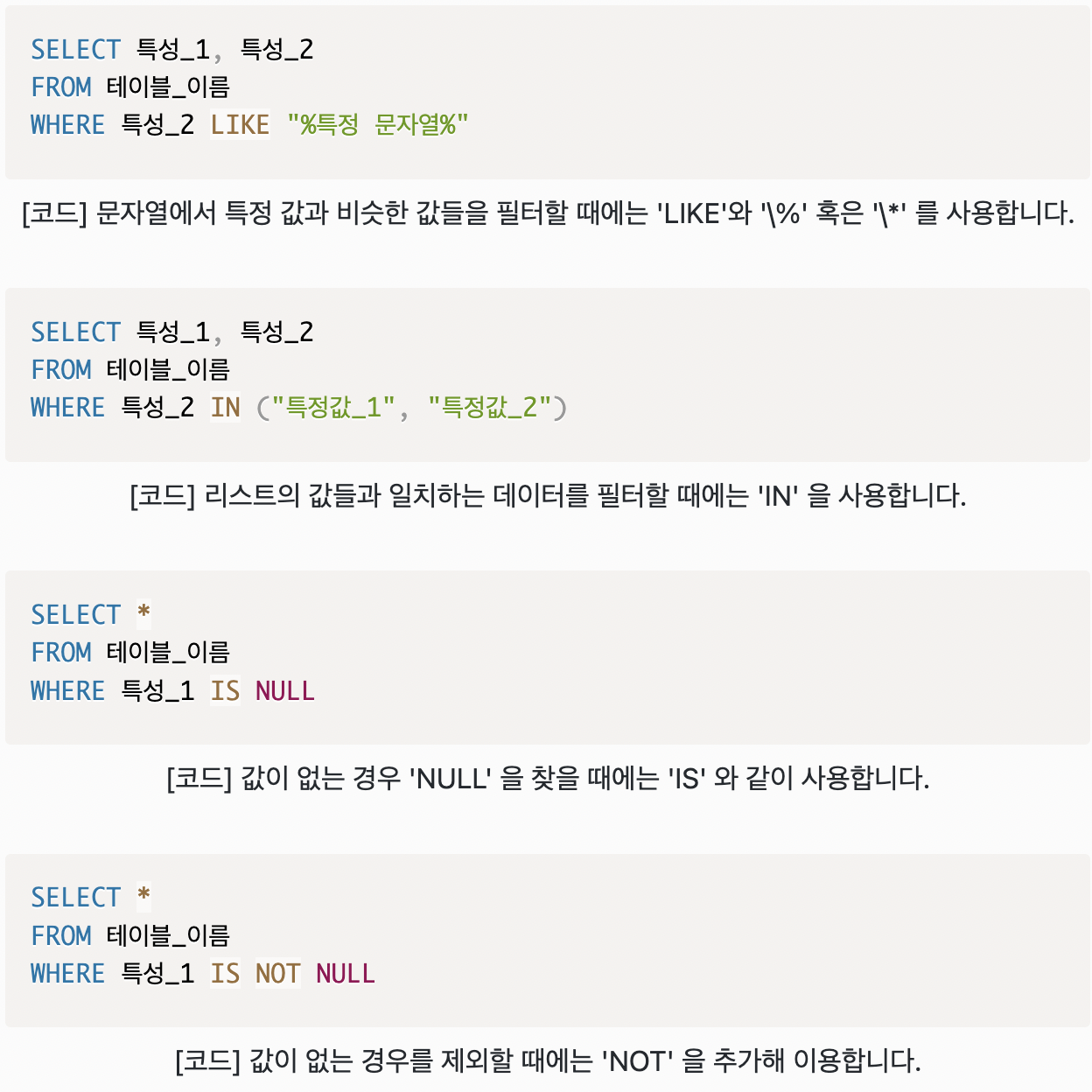

IN
WHERE 절 내에서 특정값 여러개를 선택하는 SQL 연산자
괄호 내의 값 중 일치하는 것이 있으면 TRUE
ex. 레코드 중에서 Country가 Norway가 아니고 France가 아닌 곳 선택
SELECT * FROM Customers
WHERE Country NOT IN('Norway', 'France');BETWEEN
A BETWEEN B AND C
: B와 C의 사이에 있는 A 선택
ex. Price 열의 값이 10-20 사이인 레코드들 모두 선택
SELECT * FROM Products WHERE Price BETWEEN 10 AND 20ex. Price 열의 값이 10-20 사이이지 않은 레코드들 모두 선택
SELECT * FROM Products WHERE Price NOT BETWEEN 10 AND 20ex. ProductName 열의 값이 알파벳상 'Geitost'와 'Pavlova' 사이인 레코드 모두 선택
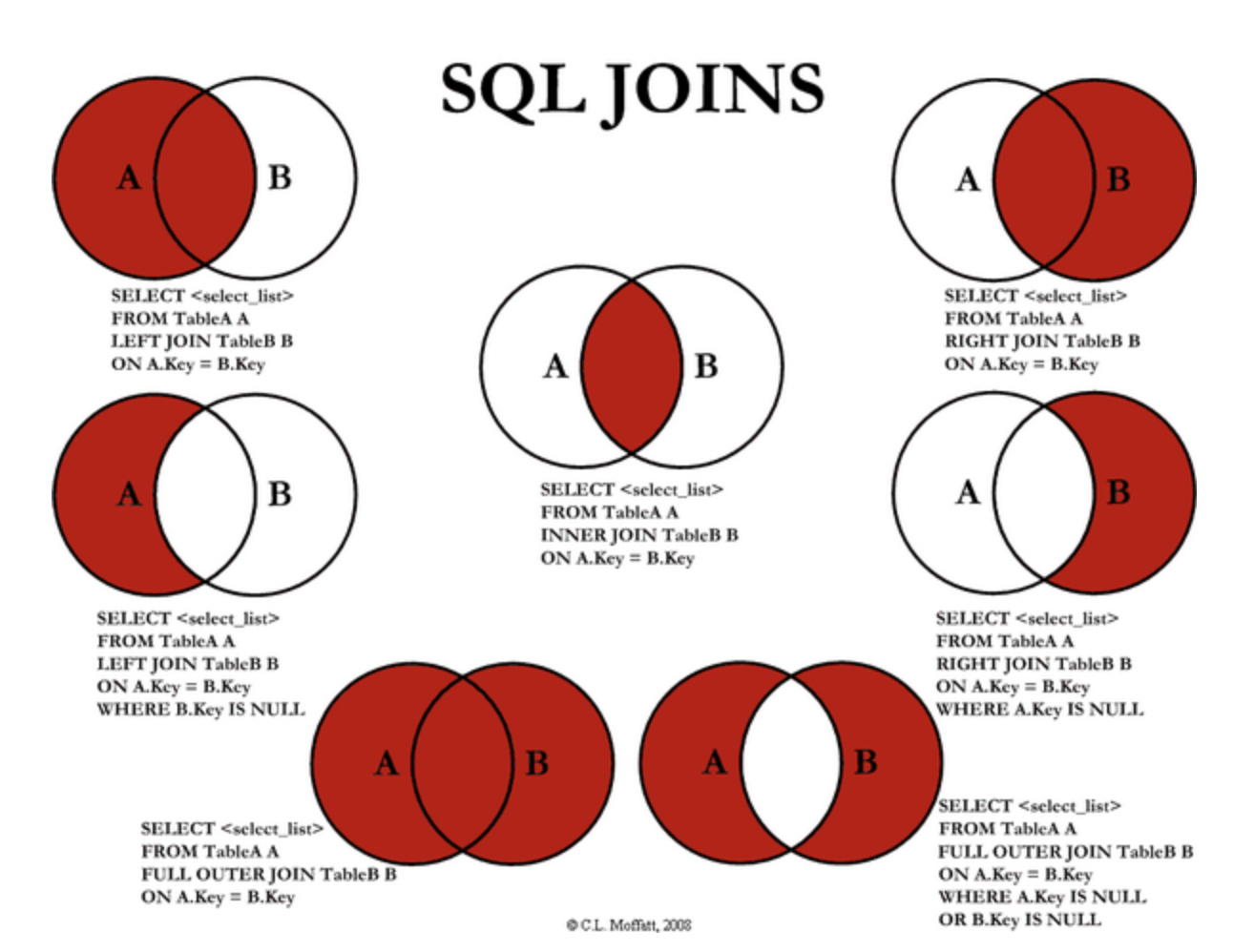
SELECT * FROM Products WHERE ProductName BETWEEN 'Geitost' and 'Pavlova';JOIN
출처:https://pearlluck.tistory.com/46
(INNER) JOIN : 교집합
FULL OUTER JOIN : mysql은 이게 없다
그래서 LEFT JOIN 과 RIGHT JOIN을 이용해 FULL OUTER JOIN을 사용할 수 있다.
LEFT (OUTER) JOIN :왼
RIGHT (OUTER) JOIN :오
LEFT JOIN WHERE A.key IS NULL OR B.key IS NULL
//A 중에서 A.key가 없는 거 빼고, B 중에서 B.key가 없는 거 빼고
=> 칼럼의 키를 기준으로 (내용이 아니라!)
//이때 A만 있거나 B만 있는 경우 다른 테이블의 같은 키에 대한 레코드는 null로 나온다
join(inner join)
교집합
SELECT *
FROM 테이블_1
JOIN 테이블_2
ON 테이블_1.특성_A = 테이블_2.특성_B
//내용이 공통된 부분을 기준으로 연결한다 LEFT (outer) join
왼만
SELECT *
FROM 테이블_1
LEFT OUTER JOIN 테이블_2
ON 테이블_1.특성_A = 테이블_2.특성_B
//왼쪽만출처: https://yoo-hyeok.tistory.com/98
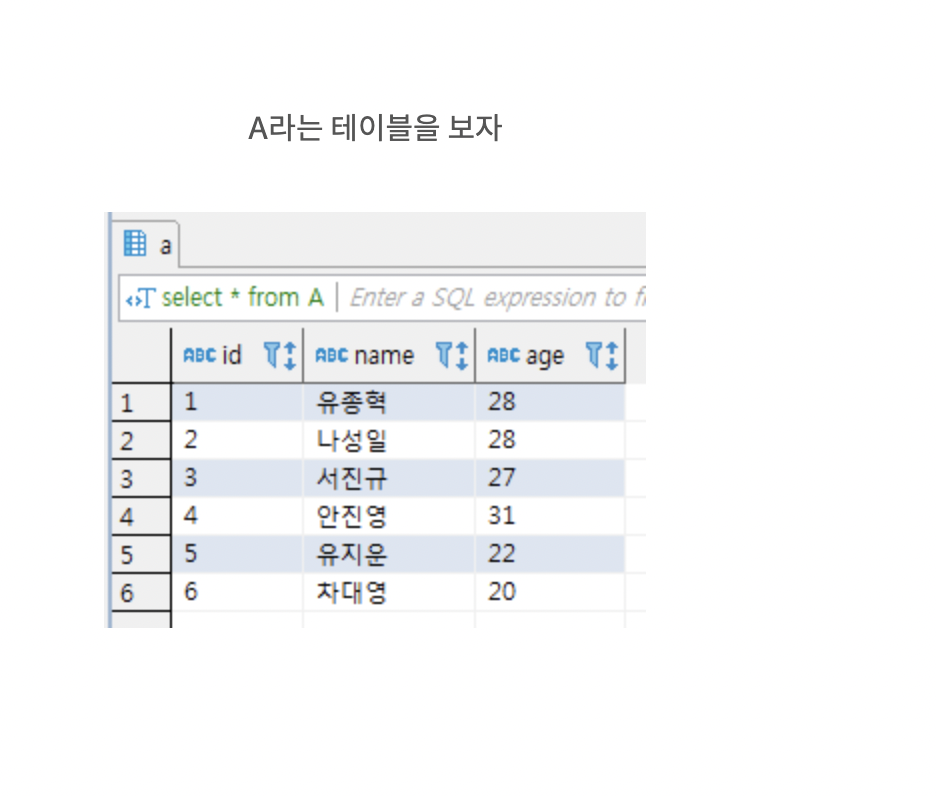
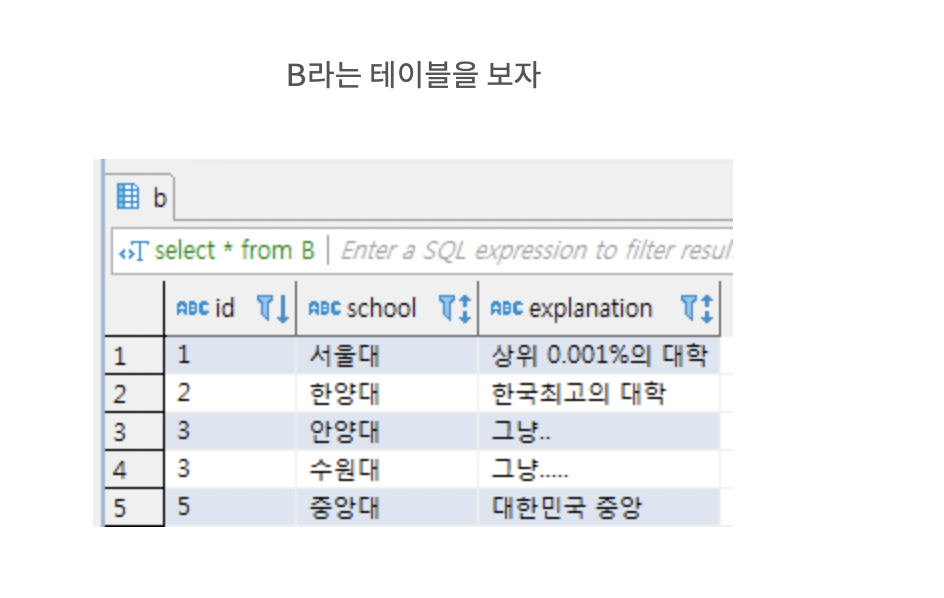
A에 대해 id

a 테이블을 선택하고 b테이블과 id가 같은 애들을 기준으로 join
a : 123456
b : 12335
left join : a를 기준으로 b를 join
1 2 3 3 4 null 5 6 null
//b는 id=4, id=6에 대한 내용이 없으므로 null로 나온다
//id=3인 게 2개여서 a.id=3이 b.id 각각에 맞춰 두번 나온다
=> a의 내용, b의 내용이 모두 들어간다
=> a에 있지만 b에 없는 내용을 null로 표현
right join면
b에 있지만 a에 없는 내용을 null로 표현할 듯
RIGHT (outer) join
오만
SELECT *
FROM 테이블_1
RIGHT OUTER JOIN 테이블_2
ON 테이블_1.특성_A = 테이블_2.특성_Bleft join vs right join
결과가 왼쪽 테이블 전체 데이터 대상이라면 left를 ,오른쪽 테이블의 전체 데이터가 대상이라면 right를 사용합니다.
=> left면 겹치는 대상이 있건없건 left 데이터는 일단 다 나오고 right에서는 겹치는 데이터
right도 마찬가지로 right 데이터는 다 나온다
clause to join the two tables Orders and Customers, using the CustomerID field in both tables as the relationship between the two tables.
=> LEFT JOIN
SELECT *
FROM Orders
**LEFT JOIN** Customers
ON Orders.CustomerID=Customers.CustomerID
//Orders, Customers join하는데 CustomerID 기준으로
//Left니까 Orders에 있지만 Customer에 없으면 null, Orders에 없지만 Customer에 있으면??select all records from the two tables where there is a match in both tables
: the records that match from both tables
=> INNER JOIN
SELECT *
FROM Orders
**INNER JOIN** Customers
ON Orders.CustomerID=Customers.CustomerID;
correct JOIN clause to select all the records from the Customers table plus all the matches in the Orders table. : all the records from both tables
SELECT *
FROM Orders
RIGHT JOIN Customers
ON Orders.CustomerID=Customers.CustomerID;모든 주문 내역 중 주문 아이디와 주문액의 합계를 가져오는 쿼리문
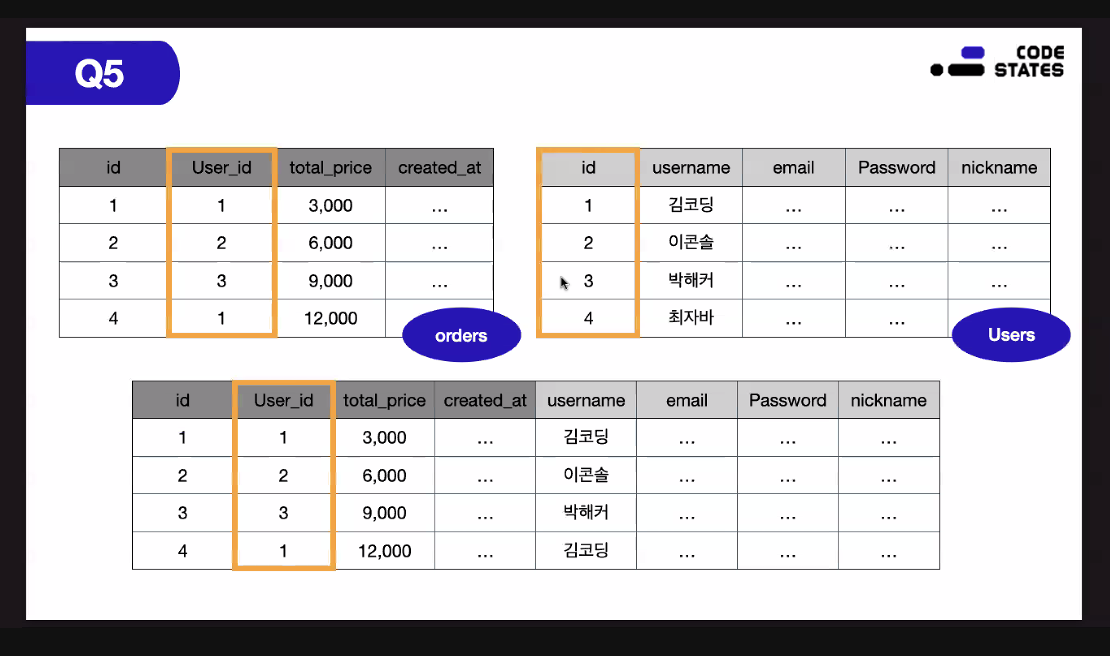
김코딩의 주문 내역을 가져오려면 users의 username에서 가져와야 하므로 다른 테이블과 합쳐서 정보를 추려내야 한다
: JOIN 사용 (사용하고 있는 테이블에 없는 정보를 다른 테이블에서 가져오려면 join을 사용해서 가져온다, user_id를 이용해서
SELECT id, total price
FROM orders
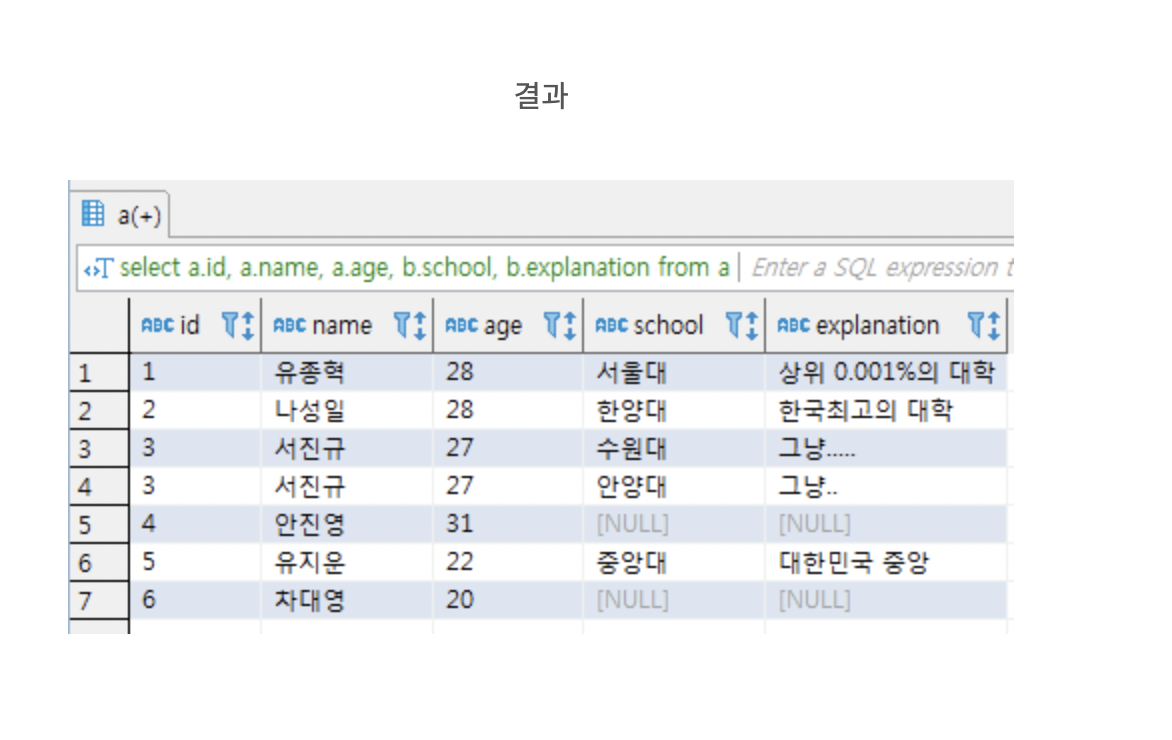
INNER JOIN orders ON users.id = orders.user_id



on : 세로로 합쳐줄 때의 조건
where : 합친 다음에 필터하는 조건 (가로로)
8. LIKE
Which operator is used to search for a specified pattern in a column?
LIKE Correct answer
Select all records where the value of the City column starts with the letter "a".
SELECT * FROM Customers WHERE City LIKE 'a%'
Select all records where the value of the City column end with the letter "a".
SELECT * FROM Customers WHERE City LIKE '%a'
Select all records where the value of the City column contains the letter "a".
SELECT * FROM Customers WHERE City LIKE '%a%'
Select all records where the value of the City column starts with letter "a" and ends with the letter "b".
SELECT * FROM Customers
WHERE City LIKE 'a%b'
;
Select all records where the value of the City column does NOT start with the letter 'a'
SELECT * FROM Customers
WHERE City NOT LIKE 'a%'
SELECT * FROM Customers
WHERE City LIKE '_a%';
Select all records where the first letter of the City is an "a" or a "c" or an "s".
SELECT * FROM Customers
WHERE City LIKE '[acs]%';
Select all records where the first letter of the City starts with anything from an "a" to an "f".
SELECT * FROM Customers
WHERE City LIKE '
[a-f]
%';
Select all records where the first letter of the City is NOT an "a" or a "c" or an "f".
SELECT * FROM Customers
WHERE City LIKE '
[^acf]
%';
9. ALIAS
ALIAS(문법)
ColumnName AS 컬럼명칭 --컬럼에 별칭 부여하기
TableName AS 테이블명칭 --테이블에 별칭 부여하기
ALIAS(예제)
1. 칼럼명에 별칭(AS)짓기
SELECT NO_NUM AS 사원번호,
NO_NAME AS 사원명,
AGE AS 나이 FROM EX_TABLE
SELECT NO_NUM,
NO_NAME AS 사원명
// NO_NAME만 ALIAS 사용
-
테이블 이름 별칭 짓기
When displaying the Customers table, refer to the table as Consumers instead of Customers.
SELECT *
FROM Customers
AS Consumers
; -
칼럼 NUM1+NUM2의 값을 TOTAL이라는 별칭(AS)짓기
SELECT NUM1 + NUM2 AS TOTAL FROM EX_TABLE
3.EX_TABLE이라는 테이블에 A라는 별칭 짓기
SELECT * FROM EX_TABLE AS A
When displaying the Customers table, make an ALIAS of the PostalCode column, the column should be called Pno instead.
SELECT CustomerName,
Address,
PostalCode AS Pno
When displaying the Customers table, refer to the table as Consumers instead of Customers.
SELECT * FROM Customers AS Consumers
10.ALTER
Add a column of type DATE called Birthday.
ALTER TABLE
Persons
ADD Birthday DATE
;
Delete the column Birthday from the Persons table.
ALTER TABLE
Persons
DROP COLUMN
Birthday;
11.GROUP BY
그룹하는 이유
데이터를 왜 그룹화해야 할까요? 다양한 계산을 하기 위해 행을 그룹화합니다.
참고로, GROUP BY 절은 주로 집계 함수와 같이 사용되곤 합니다.
집계 함수는 여러 행의 값을 더하거나, 평균값을 내거나, 개수를 세는 등 여러 개의 데이터에 관한 계산을 합니다.
가장 대표적인 집계 함수에는 하기와 같습니다.
1. COUNT() : 행의 개수를 세어줌
2. AVG() : 행 안에 있는 값의 평균을 내어줌
3. MIN() : 행 안에 있는 값의 최솟값을 반환해줌
4. MAX() : 행 안에 있는 값의 최댓값을 반환해줌
5. SUM() : 행 안에 있는 값의 합을 내어줌
그룹하는 방법
GROUP BY 는 같은 값을 가진 행끼리 하나의 그룹으로 뭉쳐줍니다
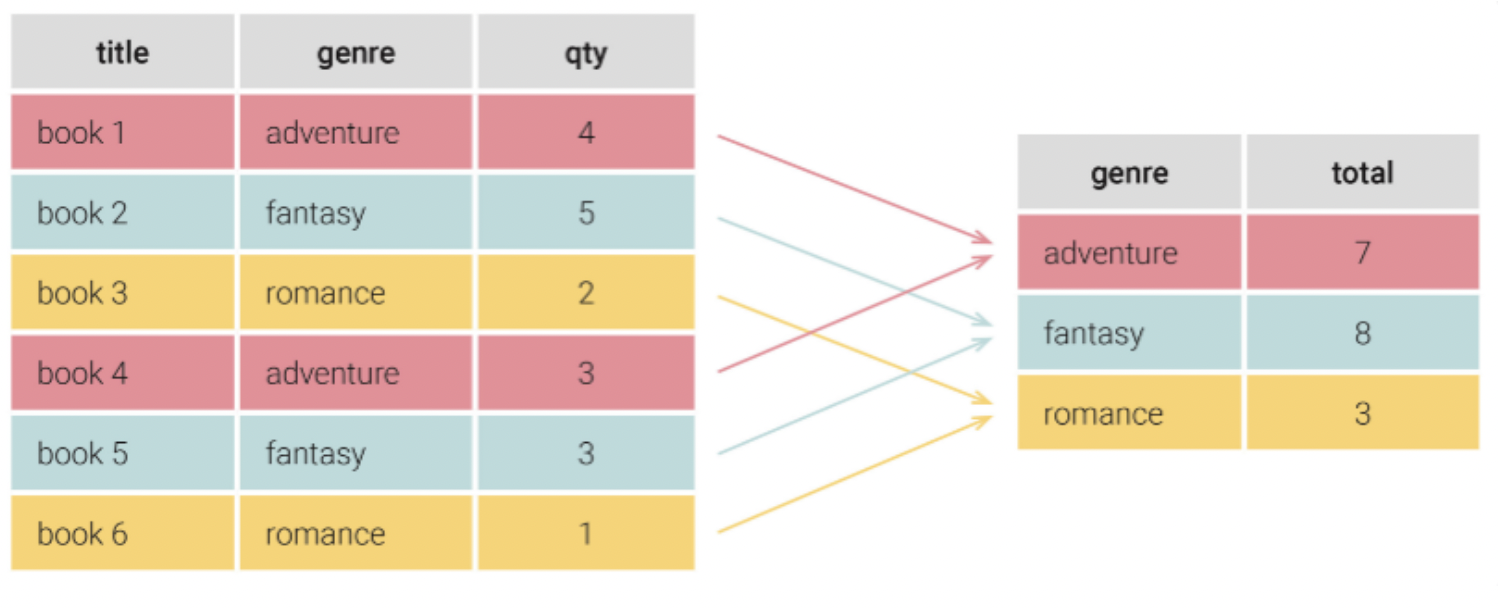
visit 테이블
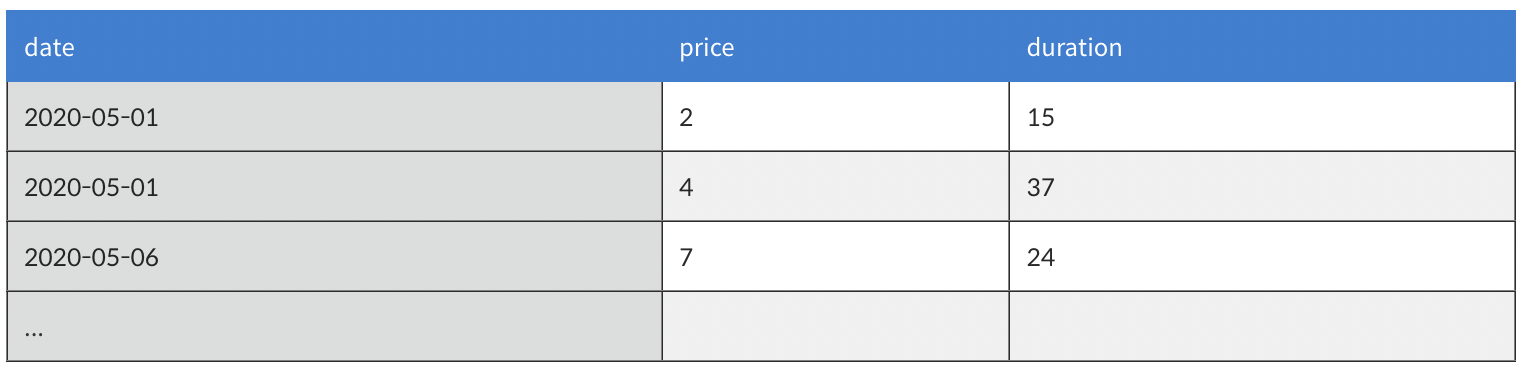
첫 번째 : GROUP BY + 1개의 열
날짜별 방문자 수 구하기
SELECT
date, //칼럼
COUNT(*) AS nums
//테이블의 행의 개수를 센다
//num이라는 칼럼에 담긴다
FROM visit //테이블
GROUP BY date;//같은 날짜 기준으로 하나의 행 //해당 날짜에 방문한 고객의 총 인원수 확인 가능
같은 날짜 기준으로 하나의 행에 들어간다 COUNT가 이해가 안된다
date count
2020-06-29 7
2020-05-23 6
2020-06-23 5
...
=> COUNT 함수의 괄호 안에 모든 행의 개수를 세라는 의미의 * 대신에 열 이름을 넣어도 됩니다.
ex. COUNT(duration) 처럼 말입니다.
=> 와 열 이름을 넣는 것의 차이
: NULL 값이 포함된 행까지 센다
열 이름 : NULL 값을 제외한 행의 개수만을 센다
그러므로 만약 데이터베이스 내에 NULL 값이 존재하지 않는다면, COUNT(*)을 실행하든 COUNT(열 이름)을 실행하든 둘의 결과값은 같다
두 번째 : GROUP BY + 여러 개의 열
월별 티켓의 평균 금액 구하기
SELECT
EXTRACT(year FROM date) AS year,
EXTRACT(month FROM date) AS year,
ROUND(AVG(price), 2) AS avg_price
FROM visit
GROUP BY
EXTRACT(year FROM date),
EXTRACT(month FROM date);
날짜 데이터로부터 연도와 월만 추출하고자 EXTRACT 함수를 사용하였습니다. SELECT 문을 보면 총 3개의 열이 있습니다.
그중 2개는 날짜 데이터를 담고 있는 연, 월 열이고,
마지막 열은 티켓 금액의 평균값을 구하는 함수가 적혀 있습니다.
이 마지막 열은 총 2개의 함수가 섞여 있는데요.
제일 안에 AVG 함수를 통해 티켓의 평균 금액을 구하고, 이를 ROUND 함수를 통해 소수점 둘째 자리까지 반올림해주었습니다.
우리는 각 연도별에 따른 월별 평균 티겟 금액을 보고 싶으므로 총 2개의 열을 기준으로 데이터를 그룹 지어 주었습니다.
첫 번째를 연도로 그룹 했기 때문에 동일한 연도별로 먼저 그룹을 짓고,
그렇게 연도별로 그룹 지어진 데이터를 그다음 기준이 월별로 데이터를 또 한 번 그룹 지어 줍니다.
year month avg_price
2020 5 7.52
2020 6 6.70
참고로, GROUP BY 뒤에 열 이름을 직접 다 적는 대신 쿼리문에서 열의 위치로 대신하여 적을 수 있습니다.
SELECT
EXTRACT(year FROM date) AS year,
EXTRACT(month FROM date) AS month,
ROUND(AVG(price), 2) AS avg_price
FROM visit
GROUP BY 1, 2;
//쿼리문에서 1번째(year), 2번째(month)
GROUP BY 절을 사용할 때
: 1)SELECT 문에 있는 모든 열(year, month)은 집계 함수가 되거나
=>avg 사용
: 2)GROUP BY 절에 나타나야 합니다.
=> group by 1,2
=>GROUP BY 절을 사용하는데 만약 SELECT 문에 집계 함수를 사용하지 않거나 GROUP BY 절에 언급되지 않은 열이 존재한다면 오류가 발생합니다.
세 번째 : GROUP BY 랑 ORDER BY 같이 사용
이번에는 월별 평균 머무른 시간을 알고 싶습니다. 그리고 각 행의 시간 순대로 정렬되었으면 합니다.
SELECT
EXTRACT(year FROM date) AS year,
EXTRACT(month FROM date) AS month,
ROUND(AVG(duration), 2) AS avg_duration
FROM visit
GROUP BY 1, 2
ORDER BY 1, 2;
ORDER BY 절은 우리가 보고 싶은 대로 행의 순서를 정해주는 것입니다.
위 쿼리문을 보면, 첫 번째 열인 연도를 첫 번째 정렬 기준으로 삼았고,
그다음 정렬 기준으로 월로 삼았습니다.
=>ORDER BY 열 이름 뒤에 아무 말도 적지 않으면 오름차순으로,
ORDER BY 열 이름 뒤에 DESC 를 적어주면 내림차순으로 정렬해 줍니다.
이제 위의 쿼리문을 실행해 보도록 하겠습니다.
year month avg_duration
2020 5 47.61
2020 6 51.33
네 번째 : GROUP BY 랑 HAVING 같이 사용
일별 평균 티겟 금액 + 방문 고객 수가 3명보다 적은 날짜 제외
SELECT
date,
ROUND(AVG(price), 2) AS avg_price
FROM visit
GROUP BY date
HAVING COUNG(*) > 3
ORDER BY date;
HAVING 절
: GROUP BY 를 통해 데이터를 그룹핑 한 행에만 사용
날짜별로 그룹 지어진 데이터들의 개수가 3개보다 많아야 우리가 원하는 결과를 얻을 수 있습니다. 만약 그룹 지어진 데이터들이 이 조건을 만족하지 못한다면 결과에는 나타나지 않습니다.
date avg_price
2020-05-01 5.80
2020-05-15 7.00
2020-05-23 6.67
...
다섯 번째 : GROUP BY, HAVING 그리고 WHERE 까지 같이 사용
우리는 일별 평균 머무른 시간 + 일별 방문 고객 수가 3명보다 많아야 + 해당 방문의 머무른 시간이 5분보다 길었으면 합니다.
SELECT
date,
ROUND(AVG(duration), 2) AS avg_duration
FROM visit
WHERE duration > 5
GROUP BY date
HAVING COUNT(*) > 3
ORDER BY date;
새로운 부분은 WHERE 절입니다. WHERE 절을 사용한 이유는 머무른 시간이 5분보다 많은 데이터만 필터링하기 위함이었습니다.
WHERE 절 vs HAVING 절
공통점 : 데이터를 필터링한다는 측면에서 바라보면요.
차이점 :
- WHERE 절 : 행들이 그룹 지어지기 전 단일 행들을 필터링하는 데 사용합니다. 그래서 쿼리문에서도 WHERE 절이GROUP BY 절 전에 적혀 있는 것을 확인할 수 있습니다.
- HAVING 절 : 행들이 그룹 지어진 후의 행들을 필터링하는 데 사용됩니다. 그래서 쿼리문에서도 HAVING 절은 GROUP BY 절 뒤에 적혀 있고요.[Group by + HAVING]
date avg_duration
2020-05-01 29.80
2020-05-15 55.75
2020-05-23 32.17
2020-05-29 69.50
2020-06-02 39.83
2020-06-04 48.67
2020-06-09 48.50
2020-06-23 51.60
2020-06-29 57.86
COUNT
SELECT할 때 사용
COUNT(*)하면 테이블의 전체 행의 개수를 반환
List the number of customers in each country,
ordered by the country with the most customers first.
SELECT
COUNT
(CustomerID),
Country
FROM Customers
GROUP BY Country
ORDER BY
COUNT(CustomerID) DESC
//count한 결과는 AS로 Alias를 쓰지 않았으면 직접 써줘야 한다
//most first : desc
;
INSER INTO
1) INSERT INTO table VALUES(칼럼 순서대로 내용 넣기)
테이블에 레코드 넣는 방법
INSERT INTO Persons VALUES ('Jimmy', 'Jackson') ** Correct answer
//그냥 value 추가 : VALUES()
Insert a new record in the Customers table.
INSERT INTO
Customers //테이블 이름
(CustomerName, //칼럼 순서대로
Address,
City,
PostalCode,
Country)
VALUES(
'Hekkan Burger',
'Gateveien 15',
'Sandnes',
'4306',
'Norway');
Question 17:
With SQL, how can you insert "Olsen" as the "LastName" in the "Persons" table?
INSERT INTO Persons (LastName) VALUES ('Olsen') Correct answer
//values as sth : (sth) values (name)
SELECT FirstName FROM Persons : select a column named "FirstName" from a table named "Persons"?
SELECT * FROM Persons
: select all the columns from a table named "Persons"?
SELECT * FROM Persons WHERE FirstName='Peter'
: all the records from a table named "Persons" where the value of the column "FirstName" is "Peter"?
//extract (records) / table name / condition (column)
SELECT * FROM Customers WHERE NOT City = 'Berlin';
: select all records where City is NOT "Berlin".
(City는 column 이름)
The OR operator displays a record if ANY conditions listed are true. The AND operator displays a record if ALL of the conditions listed are true
SELECT * FROM Customers ORDER BY City
Select all records from the Customers table, sort the result alphabetically by the column City.
SELECT * FROM Customers ORDER BY City DESC
Select all records from the Customers table, sort the result reversed alphabetically by the column City.
SELECT * FROM Customers ORDER BY Country, City;
Select all records from the Customers table, sort the result alphabetically, first by the column Country, then, by the column City.
SELECT * FROM Persons WHERE FirstName='Peter' AND LastName='Jackson'
: select all the records from a table named "Persons" where the "FirstName" is "Peter" and the "LastName" is "Jackson"
//FirstName , LastName가 column의 이름
With SQL, how do you select all the records from a table named "Persons" where the "LastName" is alphabetically between (and including) "Hansen" and "Pettersen"?
SELECT * FROM Persons WHERE LastName BETWEEN 'Hansen' AND 'Pettersen' Your answer
Question 13:
Which SQL statement is used to
SELECT DISTINCT : return only different values
Question 14:
Which SQL keyword is used tosort the result-set?
//result set가 뭐지: (돌려받는 데이터 결과)
//sort : 어떤 기준으로 정렬할지
ORDER BY Correct answer
Question 15:
With SQL, how can you return all the records from a table named "Persons" sorted descending by "FirstName"?
SELECT * FROM Persons ORDER BY FirstName DESC Correct answer
Question 18:
How can you change "Hansen" into "Nilsen" in the "LastName" column in the Persons table?
UPDATEPersons SET LastName='Nilsen'WHERE LastName='Hansen' Correct answer
: where (필터) : LastName='Hansen'인 애를 필터해서 set 뒤 내용으로 update
Question 19:
With SQL, how can youdelete the records where the "FirstName" is "Peter" in the Persons Table?
DELETE FROM PersonsWHERE FirstName = 'Peter' Correct answer
//DELETE
//FROM + 테이블이름
//WHERE: 필터
update table Cutomer but to city=oslo, Country='Norway'(둘다 변경) but only where country is Norway
UPDATE Customer
SET City='Oslo',
Country= 'Norway'
WHERE CustomerID = 32;
delete all the records from the Customers table where the Country value is Norway
Delete From Customers Where Country ='Norway'
delete all the records from the Customers table
DELETE FROM Customers
the MIN function to select the record with the smallest value of the Price column.
SELECT MIN(Price) FROM Products
Use an SQL function to select the record with the highest value of the Price column
SELECT MAX(Price) FROM Products;
Use the correct function to return the number of records that have the Price value set to 18.
SELECT COUNT(*) FROM Products WHERE Price = 18;
Use an SQL function to calculate the average price of all products.
SELECT AVG(PRICE) FROM Products;
Use an SQL function to calculate the sum of all the Price column values in the Products table.
SELECT SUM(Price) From Products;
Question 20:
With SQL, how can you return the number of records in the "Persons" table?
SELECT COUNT(*) FROM Persons Correct answer
//count 함수 인자로 *
Question 21:
What is the most common type of join?
INNER JOIN Correct answer
Question 22:
Which operator is used to select values within a range?
BETWEEN Correct answer
all records from the Customers table where the PostalCode column is empty
SELECT * FROM Customers WHERE PostalCode IS NULL;
Question 23:
The NOT NULL constraint enforces a column to not accept NULL values.
True Correct answer
: 값이 없는 경우를 제외할 때에는 'NOT NULL' 이용
Question 24:
Question 25:
Which SQL statement is used to create a database table called 'Customers'?
CREATE TABLE Customers Correct answer


여러 쿼리문을 한번에 써보기
Brazil에서 온 고객을 도시별로 묶은 뒤 각 도시 수에 따라 내림차순 정렬
CustomerId에 따라 오름차순으로 정렬한 3개의 결과만 요청
테이블을 c로 받고
그중 CustomerId, FirstName, City 의 속성들을 City Count로
join을 e로 SupportRepId, EmployeeId로 합
Country가 브라질인 애들만 필터
3개 이하로
ACID
트랜잭션
여러 개의 작업을 하나로 묶은 실행 유닛
각 트랜잭션은 하나의 특정 작업으로 시작을 해 묶여 있는 모든 작업을 다 완료해야 정상적으로 종료
하나의 트랜잭션에 속해있는 여러 작업 중에서 단 하나의 작업이라도 실패하면 이 트랜잭션에 속한 모든 작업 실패 (&&같은 원리 : 한 작업이라도 falsy하면 false)
트랜잭션 결과 : 성공 or 실패. 즉 미완료된 작업 없이 모든 작업을 성공해야 한다
데이터베이스 트랜잭션은 ACID라는 특성을 가지고 있다
ACID
데이터베이스에서 뭔가 하나를 처리하는데 필요한 트렌젝션을 위해 필요한 성질
주식, 금융 등의 서비스에서 ACID를 의무적으로 지켜서 서비스를 개발하도록 한다
데이터베이스 트랜젝션이 발생할 때 안정성을 보장할 수 있는 성질
Atomicity Consistency Isolation Durability
Atomicity 원자성
하나의 트랜잭션 내에서는 모든 연산이 전부 성공하거나 모두 실패해야 한다
하나의 단위로 묶여 잇는 여러 작업이 부분적으로 실행되면 업데이트가 일어났지만 누가, 언제한지 누락되면서 데이터가 오염될 수 있다
그러므로 모든 작업이 실패하게 만들어 기존 데이터를 보호한다
=> 즉 SQL에서도 특정 쿼리를 실행했는데 부분적으로 실패하는 부분이 있다면 전부 실패하도록 구현
때때로 충돌 요인에 대해 선택지도 제공
ex. 내 계좌에서 출금을 했으면 친구 계좌에서는 입금이 있어야 하는데 한쪽이라도 제대로 되지 않으면 정보 누락 => 그러므로 전체를 취소시킨다 (이런 취소를 롤백이라고 한다)
즉 한 단위의 일에서 하나라도 실패하면 모든 작업이 실패로 돌아가야 한다는 것이 원자성
Consistency 일관성
하나의 트랜젝션가 일어난 이전과 이후에 데이터베이스의 상태가 이전과 같이 유효해야 한다
: 트랜잭션이 일어난 이후의 데이터베이스는 데이터베이스의 제약이나 규칙을 만족해야 한다
Ex. 모든 고객은 반드시 이름이 있어야 한다
- 이름 없는 새로운 고객을 추가하는 쿼리
- 기존 고객의 이름을 삭제하는 쿼리
=> 예시 트랜잭션이 일어난 이후의 데이터베이스는 일관되지 않는 상태를 갖는다
: 데이터베이스의 유효한 상태는 다를 수 있지만, 데이터 상태에 대한 일관성은 변하지 않아야
Isolation 고립성
모든 트랜잭션은 다른 트랜잭션으로부터 독립되어야 한다는 뜻
동시에 여러 트랜잭션들이 수행될 때 각각 고립(격리)되어 있어 연속으로 실행된 것과 동일한 결과를 나타낸다
만약 만원이 있는 계좌에서 B, C에 6000씩 보내면 동시에 보내서 마이너스가 되는 것이 아니라
각각의 송금 작업을 연속으로 실행하는 것과 동일한 결과가 나타난다
격리성을 지키는 각 트랜잭션이 철저히 독립적이기 때문에, 다른 트랜잭션의 작업 내용을 알 수 없다
트랜잭션이 동시에 실행될 때와 연속으로 실행될 때의 db 상태가 동일해야 한다
Durability 내구성, 지속성
하나의 트랜젝션이 성공적으로 수행되었다면, 해당 트랜잭션에 대한 로그가 기록되고 영구적으로 남아야 한다
만약 런타임 오류나 시스템 오류가 발생하더라도 해당 기록은 영구적이어야 한다
은행에서 계좌이체를 성공적으로 실행한 뒤에, 해당 은행 db에 오류가 발생해 종료되더라도 계좌이체 내역은 기록으로 남아야 한다
마찬가지로 계좌이체를 로그로 기록하기 전에 시스템 오류 등에 의해 종료가 된다면 실패로 돌아가고 각 계좌들은 계좌 이체 이전 상태들로 돌아간다

=> C의 경우에는 보낸 사람은 보냈지만 받은 사람은 받지 못해서 원자성 때문에 취소 (롤백)
SQL(구조화 쿼리 언어) vs NoSQL(비구조화 쿼리 언어)
데이터베이스의 종류
분류 방식: 만들어진 방식, 저장하는 정보의 종류, 저장하는 방법
-관계형 데이터베이스 : SQL
-비관계형 데이터베이스: NoSQL
관계형 데이터베이스
- 테이블의 구조와 데이터 타입 등을 사전에 정의
- 테이블에 정의된 내용에 알맞은 형태의 데이터만 삽입 가능
- 행과 열로 구성된 테이블에 데이터 저장
열 : 하나의 속성에 대한 정보 저장
행 : 각 열의 데이터 형식에 맞는 데이터 저장
장점
특정한 형식을 지키므로 (스키마에 맞게 입력해야 하므로)
-> 데이터를 사용할 때에는 매우 수월
-> SQL을 활용해 원하는 정보를 쿼리할 수 있다
=== 관계형 데이터베이스에서는 스키마가 뚜렷하게 보인다
즉 관계형 데이터베이스에서는 테이블 간의 관계를 직관적으로 파악할 수 있다 (스키마??)
ex. MySQL, Oracle, SQLite, PostgresSQL, MariaDB 등
NoSQL
데이터가 고정되어 있지 않은 데이터베이스
SQL과 반대되는 개념 같지만 그렇다고 스키마가 반드시 없는 것은 아니다
관계형 db에서는 데이터를 입력할 때 스키마에 맞게 입력해야 하는 반면,
NoSQL에서는 데이터를 읽어올 때 스키마에 따라 데이터를 읽어온다
-> 'schema on read'
읽어올 때에만 데이터 스키마가 사용된다
데이터를 입력하는 방식에 따라 데이터를 읽어올 때 영향을 미친다
ex. mongoDB, Casandra
NoSQL
비관계형 데이터베이스 구성 형태
- key-value 타입
: 속성을 key(속성)-value(값)의 쌍으로 나타내는 데이터를 배열의 형태로 저장
ex. Redis, Dynamo - 문서형 데이터베이스
: 데이터를 테이블이 아닌 문서처럼 저장하는 데이터베이스
: JSON과 유사한 형식의 데이터를 문서화하여 저장
: 각각의 문서는 하나의 속성에 대한 데이터를 가지고 있고 컬렉션이라는 그룹으로 관리
ex. MongoDB
- wide-column 데이터베이스
: 데이터베이스의 열에 대한 데이터를 집중적으로 관리하는 데이터베이스
각 열에는 key-value형식으로 데이터 저장
컬럼 패밀리라고 하는 열의 집합체 단위로 데이터 처리 가능
하나의 행에 많은 열을 포함할 수 있어 유연성이 높다
데이터 처리에 필요한 열을 유연하게 선택할 수 있다는 점에서 규모가 큰 데이터 분석에 주로 사용되는 데이터베이스 형식
ex. Cassandra, HBase
- 그래프 데이터베이스
: 자료구조의 그래프와 비슷한 형식으로 데이터 간의 관계를 구성하는 데이터베이스
: 노드에 속성별로 데이터를 저장
: 노드 간 관계는 선으로 표현
ex. Neo4J, InfiniteGraph
SQL 기반의 데이터베이스와 NoSQL 데이터베이스의 차이점
데이터 저장
- NoSQL
: 다양 방식
: key-value, document, wide-column, graph 등 - SQL
: SQL + 테이블
: 미리 작성된 스키마를 기반으로 정해진 형식에 맞게 데이터 저장
스키마
- SQL
: 고정된 형식의 스키마 필요
-> 즉 처리하려는 데이터 속성별로 열에 대한 정보를 미리 정해두어야 한다
-> 나중에 변경할 수 있지만 이 경우 DB 전체 수정 or 오프라인으로 전환해야 함 - NoSQL
: 관계형 DB보다 동적으로 스키마 형태 관리 가능
: 행을 추가할 때 즉시 새로운 열 추가 가능
: 개별 속성에 대해 모든 열에 대한 데이터 반드시 입력할 필요 X
쿼리
데이터베이스에 대한 정보를 요청하는 질의문
-
관계형 데이터베이스
: 테이블의 형식과 테이블 간의 관계에 맞춰 데이터 요청 필요
: 그러므로 SQL과 같은 구조화된 쿼리 언어 사요 -
비관계형 데이터베이스
: 데이터 그룹 자체를 조회하는 것에 초점
: 구조화되지 않은 쿼리 언어(UnQL)로도 데이터 요청 가능
확장성
-SQL 기반의 관계형 데이터 베이스
: 수직적으로 확장
: 높은 메모리, CPU를 사용하는 확장
: 데이터베이스가 구축된 하드웨어의 성능 많이 이용
-> 비용이 많이 든다
: 여러 서버에 걸쳐서 DB의 관계를 정의할 수 있지만 매우 복잡, 시간 많이 소모
- NoSQL 기반 데이터 베이스
수평적으로 확장
보다 값싼 서버 증설 또는 클라우드 서비스 이용하는 확장
장점
비관계형 : 확장성, 속도, 용량 면에서 뛰어남
관계형 : 고차원, 구조적
SQL 사용 케이스
: 안정성, 구조, 일관
- 데이터베이스의 ACID 성질 준수 시
트랜잭션에 의한 상태의 변화를 수행하는 과정에서 안전성을 보장하기 위해 필요한 성질
SQL을 사용하면 데이터베이스의 상호작용하는 방식 정확하게 규정 가능
-> 그러므로 예외적인 상황 감소,DB의 무결성 보호 가능
모든 금융 서비스를 위한 SW 개발에서는 반드시 DB의 ACID 성질 준수
그러므로 SQL 사용
- SW에 사용되는 데이터가 구조적이고 일관적인 경우
-> 프로젝트의 규모가 많은 서버를 필요로 하지 않고 일관된 데이터를 사용하는 경우
NoSQL 사용 케이스
비관계형 : 다양한 데이터 유형과 높은 트래픽을 지원
-> 만들 때는 스키마 X, 읽을 때는 스키마 O
- 데이터 구조가 거의 또는 전혀 없는 대용량의 데이터 저장 시 [다양 유형]
: 대부분의 NoSQL은 저장할 수 있는 데이터의 유형에 제한이 없다
-> 필요에 따라 언제든지 데이터의 새 유형 추가 가능
: SW 개발에 정형화되지 않은 많은 양의 데이터 필요 시 NoSQL 적용하는 것이 더 효율적
2.클라우드 컴퓨팅 및 저장 공간 최대한 활용하는 경우 [확장성]
: 클라우드 기반으로 데이터베이스 저장소 구축 시 저렴한 비용의 솔루션 제공받을 수 있다
-> 확장성이 중요하다면 비관계형 사용
- 빠르게 서비스를 구축하는 과정에서 데이터 구조를 자주 업데이트하는 경우 [다양 유형]
: 스키마를 미리 준비할 필요가 없기 때문에 빠르게 개발하는 과정에서 유리
ex. 시장에 빠르게 프로토타입을 출시해야 하는 겨우
ex. sw 버전별로 많은 다운타임(DB 서버를 오프라인으로 전환해 데이터 처리 진행하는 작업 시간) 없이
데이터 구조를 자주 업데이트해야 하는 경우 : 전체적인 수정이 아니라 바로바로 업데이트 해야하니까
정리
NoSQL의 특징
수직적으로 확장되지 않고 수평적으로 확장
확장 : 요구되는 데이터 용량 초과 시 규모를 키우는 거
ACID 철저히 지켜야 하는 경우 부적합
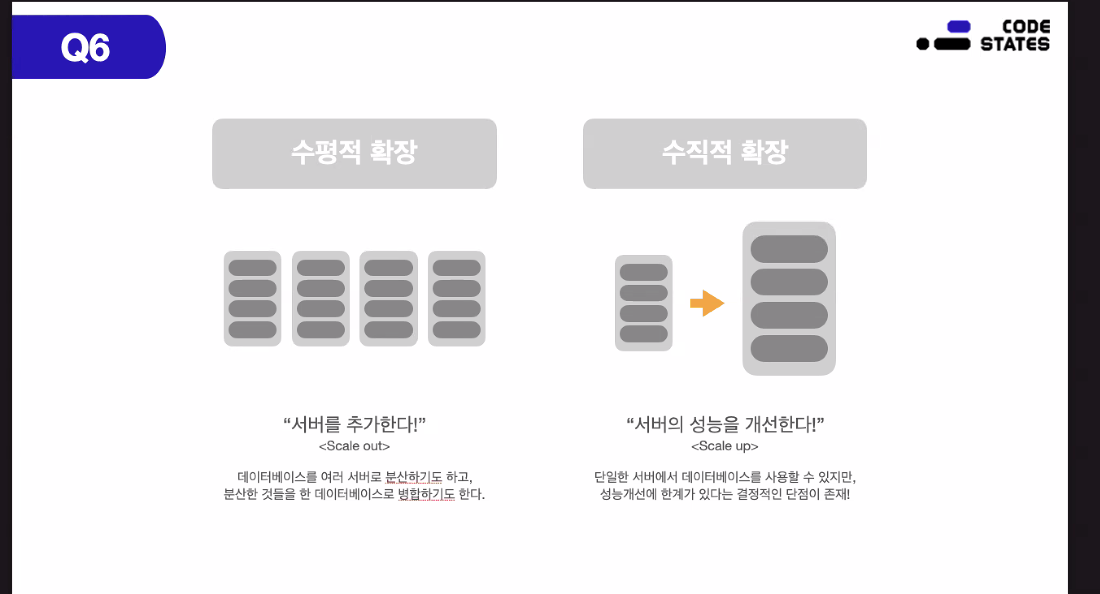
db 서버의 저장 용량이 초과되면 어떤 방식으로 db 서버 확장??
1)수평적 확장 : 장비 추가
-더 많은 서버를 추가한다
-여러 서버로 db를 분산하거나 분산한 것들을 한 db로 병합
but 엄격한 스키마를 사용하고 있는 관계형 db에는 적용하기 어렵다
레코드를 통해서 데이터베이스가 저장되기 때문에
=> NoSQL은 가능 : 구조가 엄격하지 않아서
2)수직적 확장 : 성능 개선
단일한 서버에서 db를 사용할 수 있지만 성능 개선에 한계가 있다
관계형 데이터베이스가 접목되기 좋은 서비스는?
-일관된 데이터가 필요한 앱
-많은 수의 읽기, 쓰기 작업이 동시에 처리되고 시스템의 확장성이 빠른 앱
-기능별로 복잡한 관계가 많이 설정되는 앱
=> 1번
Schema & Query 디자인
- 데이터 간의 다양 관계
- 관계 기술 언어 SQL
- 효율적, 합리적 DB 구성 방법
- DB 관련 정보 찾기 위해 SQL 쿼리 작성
행과 열
행 : 칼럼
열 : 레코드
스키마
db에서 데이터가 구성되는 방식과 서로 다른 엔티티 간의 관계에 대한 설명
엔티티 : 고유한 정보의 단위
즉, db의 청사진
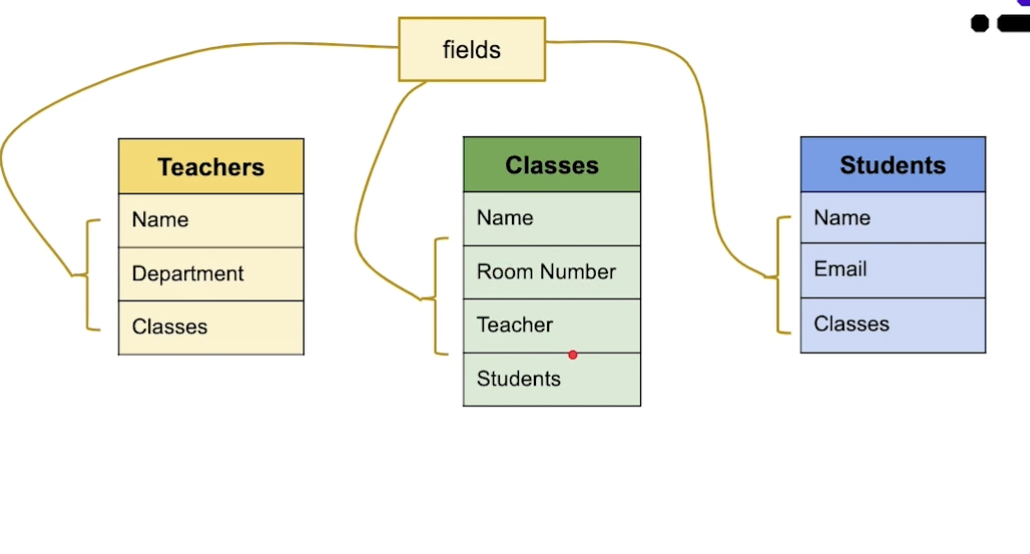
ex. 수강신청
엔티티 : 교수, 수업, 학생
-> db에서 테이블로 표시할 수 있다
-> 각 엔티티에는 해당 엔티티의 특성을 설명하는 필드(열)가 있다
field: 행, 각 엔티티에는 해당 엔티티의 특성을 설명하는 필드가 있다
record : 테이블에 저장된 항목(행)
레코드 3개, 레코드 7개
1:N 관계
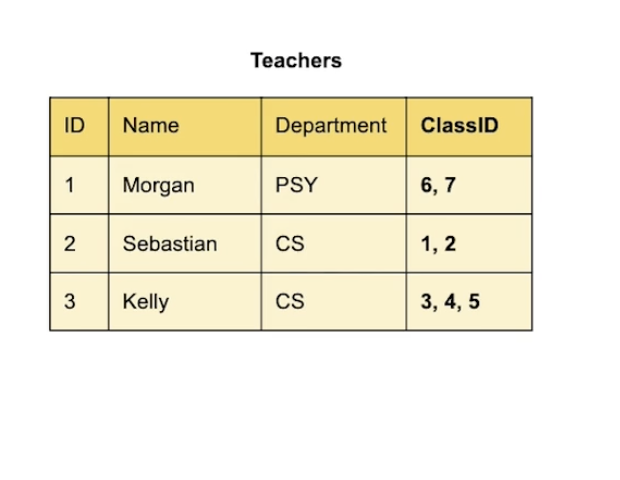
=> (1)교수별 강의수 표현 / (2)강의별 교수 표현 [어떤 게 더 나을까?]
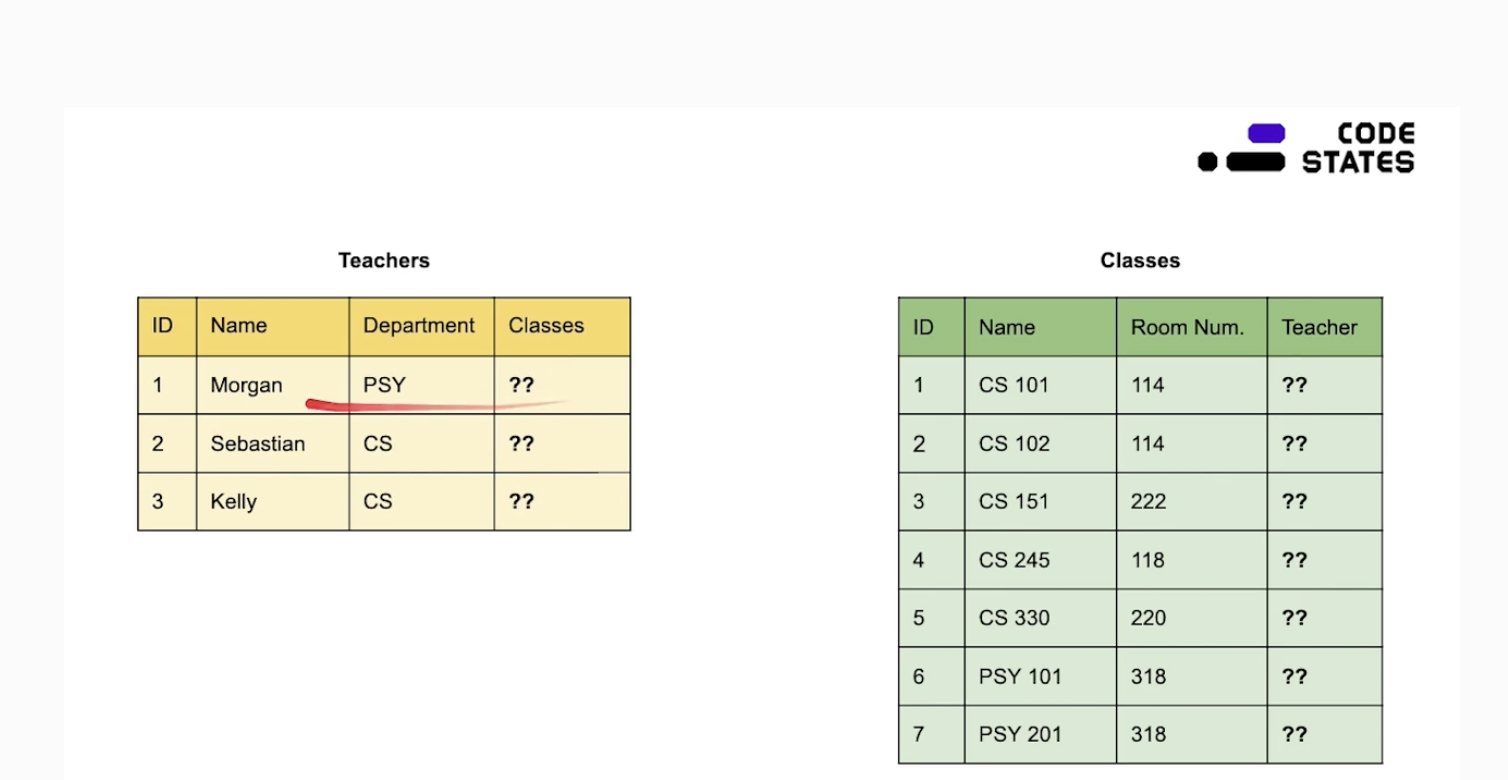
(1)교수별 강의 수 표현
- 만약 수업이 이름이 바뀌면 수정하기 어렵기 때문에 수업의 이름을 적는 게 아니라 primary key라는 id를 넣는다
- Primary key : id 같은 고유한 값
-
Foreign key: id를 이용해 하나하나 참조하는 것
-
교수별 강의를 몇개 할지 모르니까 열의 크기에 비해 수업 ID를 담을 공간이 부족할 수 있다
-
하나를 변경하면 다른 애들도 바뀔지 모른다 (정합성이 떨어진다)
(2)class별 teachers id 표현
teachers 중에서 id를 찾아보면 되니까 더 간단
class별 모두 교수가 한명이니까 이게 더 편하다
N:N
수업과 학생은 다대다 관계
어떻게 표현해야할까?
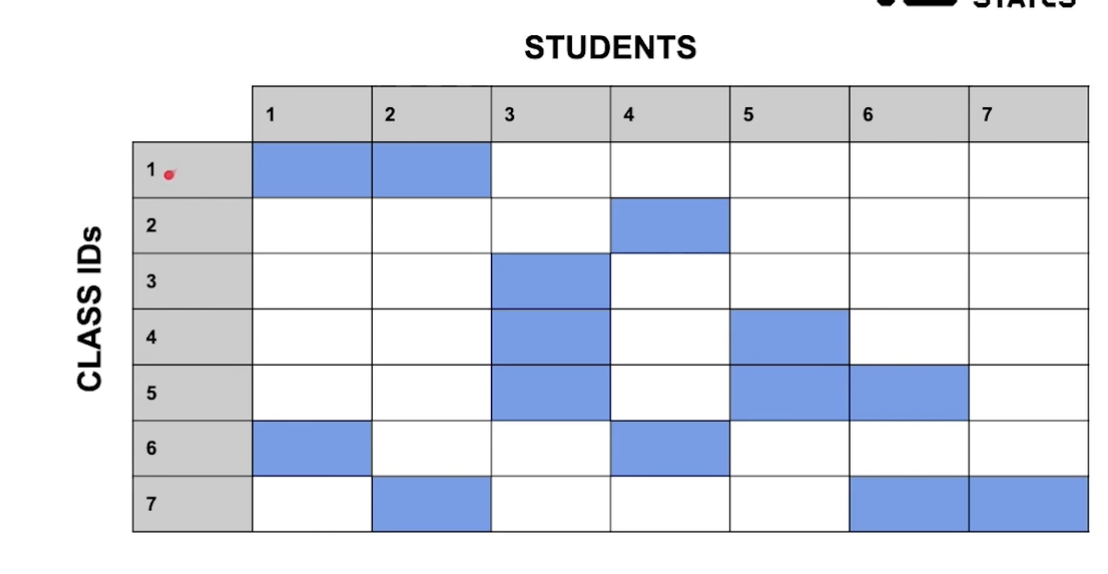
id들이 교차하는 좌표들을 하나의 테이블에 저장할 수 있다
Join table
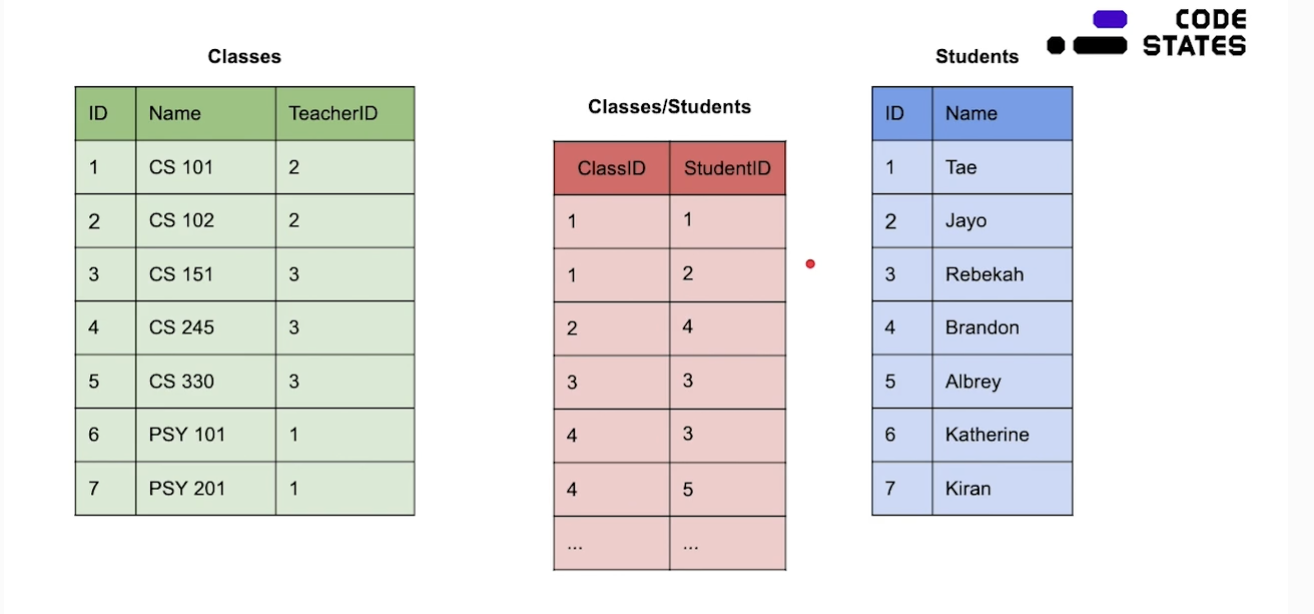
일대다 관계
기존의 다대다 관계를 두 일대다 관계로 나눈 것을 볼 수 있다
이렇게 스키마가 있으니 이제 내용을 채워넣으면 된다
SQL에서는 SQL 쿼리문을 작성해야 채워넣고 찾을 수 있다
엔티티 간의 관계
여러 교수가 한 강의 (X)
한 교수가 여러 강의 (O)
-> 일대다의 관계
데이터베이스 설계
관계형 데이터베이스
구조화된 데이터는 하나의 테이블로 표현
정의된 테이블 : relation이라고도 부른다
그러므로 테이블을 사용하는 데이터베이스를 관계형 데이터베이스라고 한다
키워드
데이터 : 각 항목에 저장되는 값
테이블 : 사전에 정의된 열의 데이터 타입대로 작성된 데이터가 행으로 축적된다
칼럼 : 테이블의 한 열
레코드 : 테이블의 한 행에 저장된 데이터
키 : 테이블의 각 레코드와 구분할 수 있는 값, 각 레코드마다 고유한 값을 가진다
- 기본키(primary key)
- 외래키(foreign key)
관계 종류
테이블과 테이블 사이 관계
- 1:1
- 1:N
- N:N
테이블 스스로 관계
self referencing 관계
1:1관계
하나의 레코드가 다른 테이블의 레코드 한개와 연결된 경우
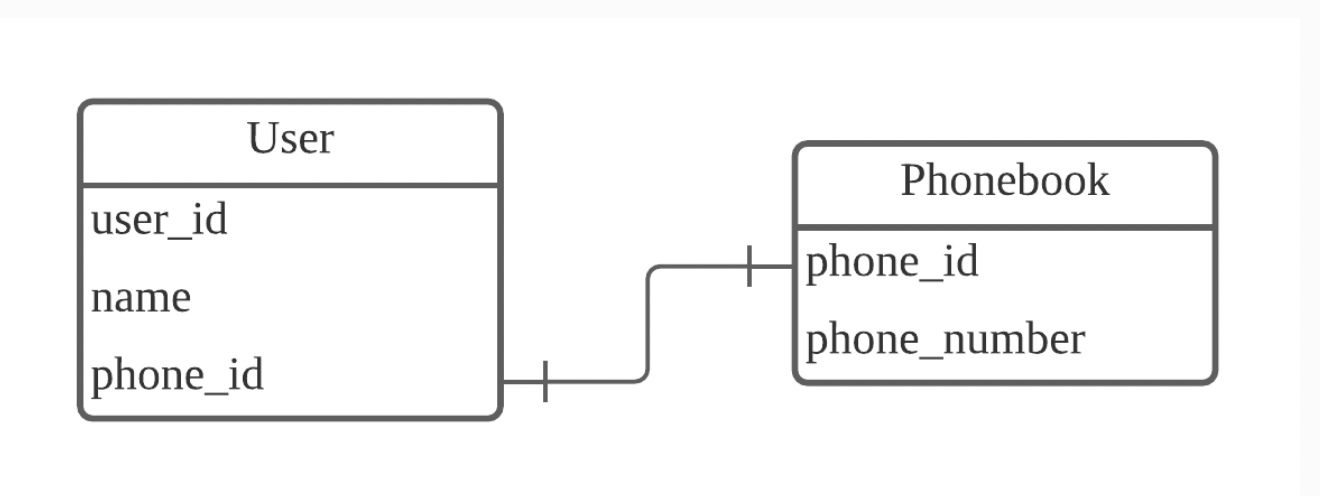
phone_id는 외래키로 phonebook 테이블의 phone_id와 연결
phonebook 테이블은 phone_id, phone_number를 가지고 있다
여기서 각 전화번호가 단 한 명의 유저와 연결되어 있고 그 반대도 동일하다면 user테이블과 phonebook 테이블은 1:1관계
=> 1:1은 자주 사용하지 않는다
=> user테이블에 phone_id를 대신해 phone_number를 직접 저장하는 게 나을 수 있기 때문에
1:N관계
하나의 레코드가 서로 다른 여러 개의 레코드와 연결된 경우
user테이블과 phonebookk 테이블의 관계
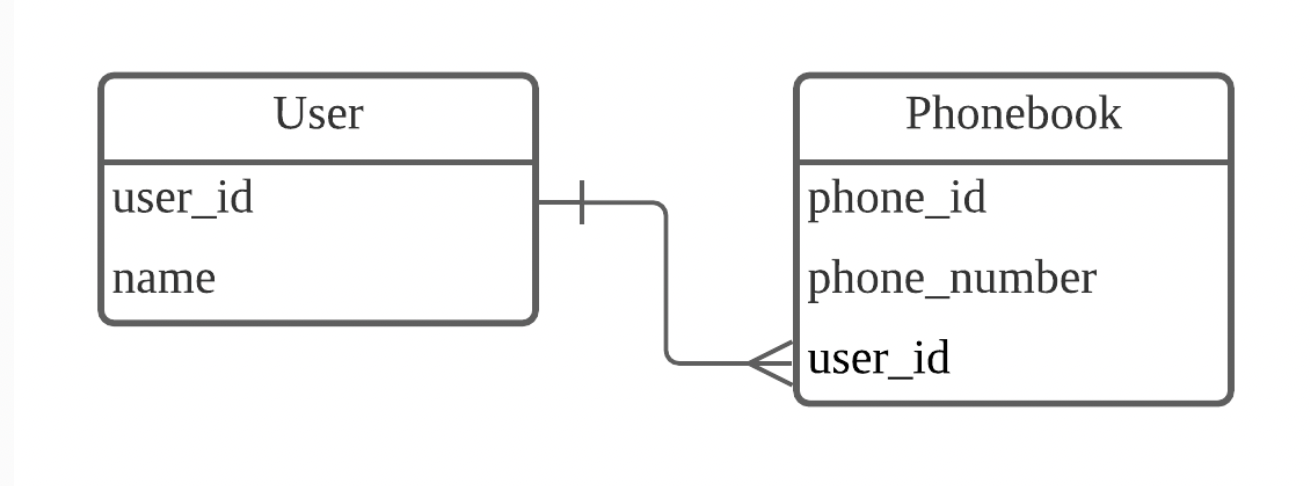
한명의 유저가 여러 전화번호를 가질 수 있다
그러나 여러 명의 유저가 하나의 전화번호를 가질 수는 없다
이런 1:N 관계는 가장 많이 사용
N:N관계
여러 개의 레코드가 다른 테이블의 여러 개의 레코드와 관계가 있는 경우
다대다 관계를 위해 스키마를 디자인할 때에는 Join 테이블을 만들어 관리
1:N 관계와 비슷하지만 양방향에서 다수의 레코드를 가질 수 있다
여행 상품 관리하는 테이블이 있으면 여러 개의 여행 상품이 있고 여러 명의 고객이 있다
고객 한명은 여러 개의 여행 상품을 구매할 수 있고 여행 상품 하나는 여러명의 고객이 구매할 수 있다
N:N 관계는 두개의 일대다 관계와 모양이 같다
두개의 테이블과 1:N 관계를 형성하는 새로운 테이블로 N:N 관계를 나타낼 수 있다
customer_package 테이블에서는 고객 한명이 여러개의 여행 상품을 가질 수 있고
여행 상품 하나를 여러 고객이 가질 수 있다
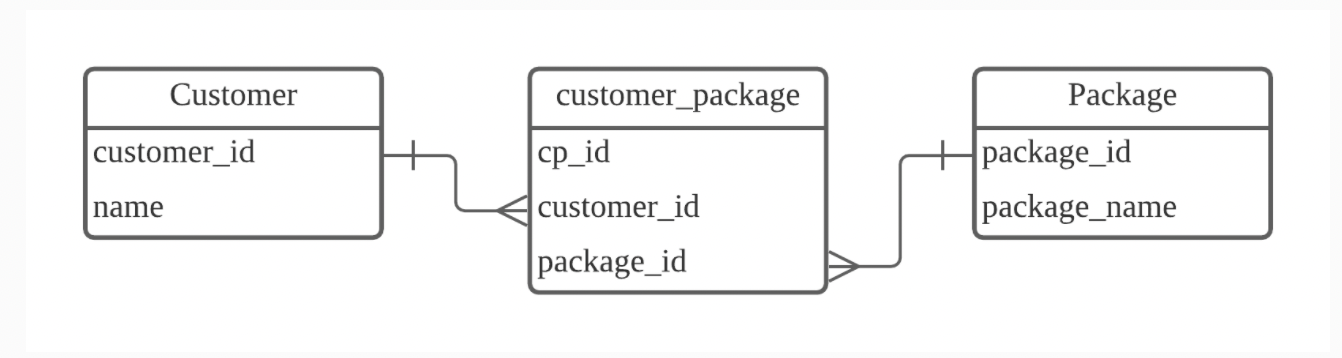
customer_package는 customer_id와 package_id를 묶어주는 역할
어떤 고객이 몇 개의 여행 상품을 구매했는지 또한 어떤 여행 상품이 몇명의 고객을 가지고 있는지 등 확인 가능
이렇게 조인 테이블 생성하더라도 조인 테이블을 위한 기본키(여기서 cp_id) 필수
-> 둘을 연결하기 위한 기본 키
자기 참조 관계
때로 테이블 내에서도 관계가 필요.
예를 들어 추천인이 누구인지 파악하기 위해 사용 가능
user_id는 기본키, name은 사용자의 이름 그리고 recommend_id는 추천인 아이디
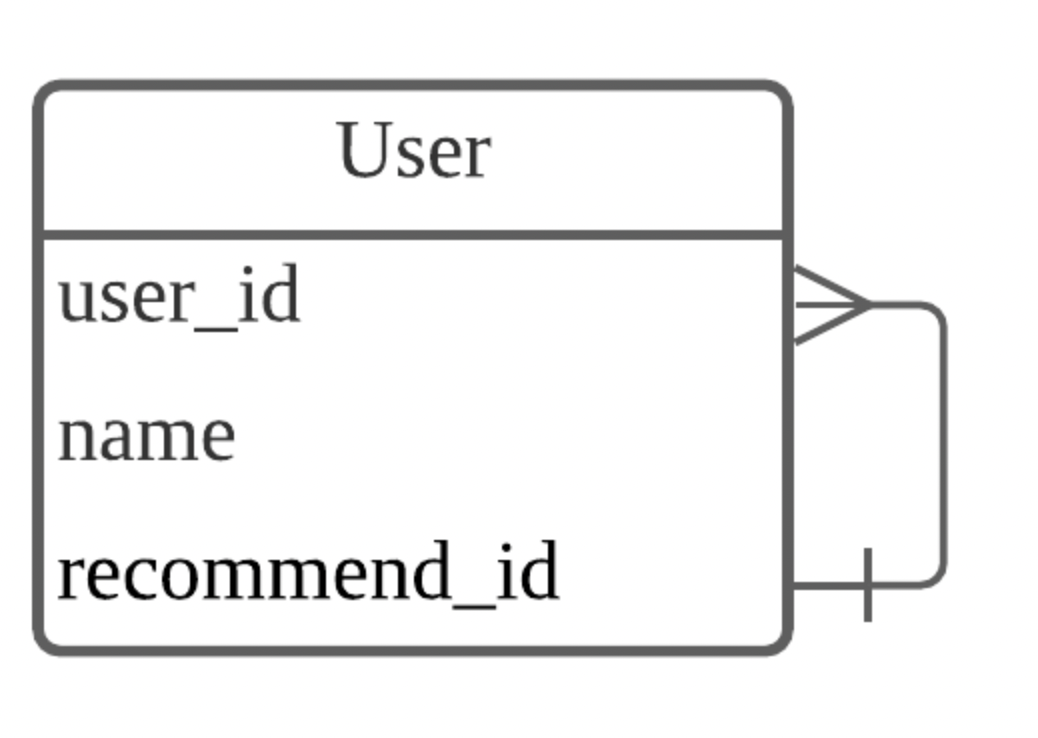
user_id와 recommmend_id는 서로 연결
한명의 유저는 한명의 추천인
그러나 여러명이 한 명의 유저를 추천인으로 등록 가능
이 관계는 1:N(일대다)관계와 유사해보이지만
일반적으로 일대다 관계는 서로 다른 테이블의 관계를 나타낼 때 표현하는 방법
SQL More
SQL에서 사용하는 쿼리에는 유용하게 사용할 수 있는 함수도 많다
SQL에 대해 더 공부한다면 더 많은 쿼리문이 있다
SQL 내장 함수
집합 연산 : 레코드를 조회하고 분류한 뒤, 특정 작업을 하는 연산
Group by : 그룹으로 묶어서 조회

그룹으로 묶어서 조회 : from 뒤에 나오는 테이블의 레코드를 select해서 group으로 묶어 표혀
group by 쿼리로 간단하게 state에 따라 그룹화 가능
쿼리의 결과를 확인하면 데이터가 중간에 비어있는 것을 확인 가능
데이터베이스에서 데이터를 불러오는 과정에서 State에 따라 그룹을 지정했지만 그룹에 대한 작업 없이 조회만 한다
그래서 쿼리의 결과로 나타나는 데이터는 각 그룹의 첫번째 데이터만 표현된다
Having : group by로 조회된 결과 필터링

모든 고객의 주문서에서 가격의 평균을 구한 뒤에, 그 평균이 6.00을 넘는 결과만 조회
Group by로 그룹을 지은 결과에 필터를 적용할 때에는 Having 사용 가능
having vs Where
- having은 그룹화한 결과에 대한 필터
- where는 저장된 레코드를 필터링합니다
=> 실제로 그룹화 전에 데이터를 필터해야 한다면 where 사용
그룹에 대해 할 수 있는 작업
count()
count함수는 레코드의 개수를 헤아릴 때 사용

위 커맨드를 실제로 실행하면 각 그룹의 첫번째 레코드와 각 그룹의 레코드 개수를 집계하여 리턴한다
다음과 같이 변경하면 그룹으로 묶인 결과의 레코드 개수를 확인할 수 있다

SUM()
레코드의 합을 리턴

invoice_items라는 테이블에서 InvoicId 필드를 기준으로 그룹하고 UnitPrice 필드 값의 합을 구한다
위 커맨드는 invoice_items라는 테이블에서 InvocieId 필드를 기준으로 그룹하고 UnitPrice 필드 값의 합을 구한다
AVG()
AVG함수는 레코드의 평균값을 계산하는 함수

MAX(), MIN()
각각 레코드의 최댓값과 최솟값 리턴

위 커맨드에서 MIN을 MAX로 변경하면 각 고객이 지불한 최대 금액 리턴
SELECT 실행 순서
데이터를 조회하는 SELECT 문은 정해진 순서대로 동작
-FROM
-WHERE
-GROUP BY
-HAVING
-SELECT
-ORDER BY

위 쿼리문의 실행 순서는 다음과 같습니다.
1. FROM invoices: invoices 테이블에 접근을 합니다.
2. WHERE CustomerId >= 10: CustomerId 필드가 10 이상인 레코드들을 조회합니다.
3. GROUP BY CustomerId: CustomerId를 기준으로 그룹화합니다.
4. HAVING SUM(Total) >= 30: Total 필드의 총합이 30 이상인 결과들만 필터링합니다.
5. SELECT CustomerId, AVG(Total): 조회된 결과에서 CustomerId 필드와 Total 필드의 평균값을 구합니다.
6. ORDER BY 2: AVG(Total) 필드를 기준으로 오름차순 정렬한 결과를 리턴합니다.
order_items : inner_join
orders와 items의 중간
SPRINT REVIEW
- /.env파일
환경변수 저장하는 용도
dotenv라는 모듈 사용 (npm install 아니면 npm i dotenv)
const dotenv = requrie('dotenv')
dotenv.require();
process.env로 env안에 있는 내용을 객체로 잡을 수 있다
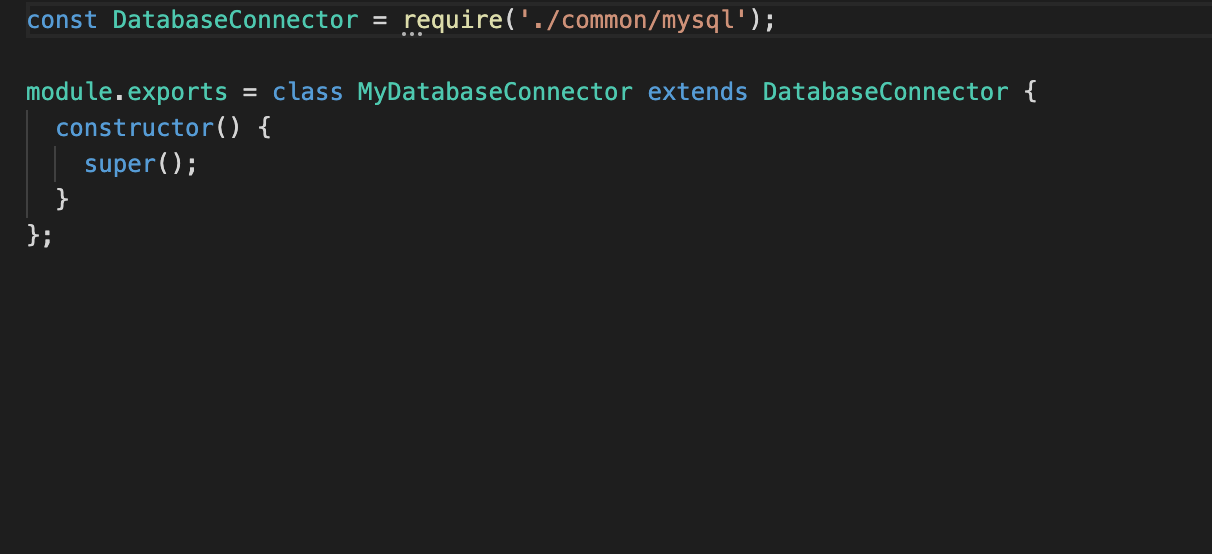
-
/lib/databaseConnector.js
mysql 파일에 있는 클래스 databaseConnector를 상속한 클래스 mydatabaseconnector를 export
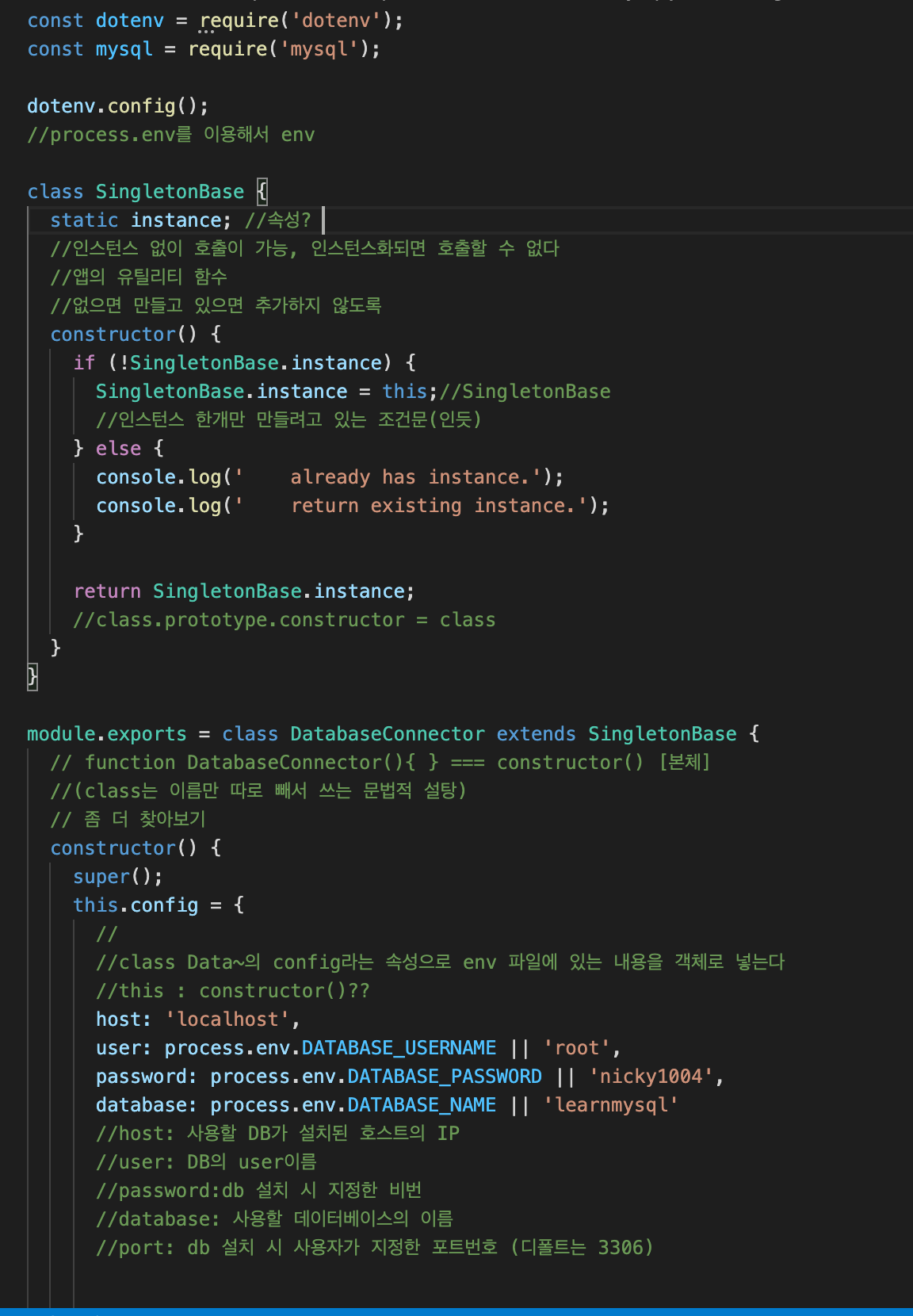
-
/lib/common/mysql.js
1)SingletonBase라는 클래스 생성
정적 변수 instance를 사용해서 이미 instance가 있으면 생성 X, 없으면 생성하도록 한다 (즉 instance는 하나만)
2)SingletonBase를 상속하는 DatabaseConnector를 만든다
(1)config 속성: 환경변수로 만들어놓은 db의 host, pw, db 넣는다
(2)init 메소드 :
- this.connection: mysql.createConnection(config속성에 넣어둔db 관련 정보: host, pw, db)+return promise
//mysql 서버에 해당 내용이 넘어간다
mysql.createConnection() 메서드는 MySQL 서버와 상호 작용하는 데 사용됩니다.
connect() 함수는 서버에 대한 연결을 설정하는 데 사용됩니다.
query() 함수는 MySQL 데이터베이스에 대해 SQL 쿼리를 실행하는 데 사용됩니다.
host, user, password 및 database 매개 변수는 서버 및 데이터베이스를 만들 때 지정한 값으로 바꿉니다.
//promise 사용 이유 : db에서 정보를 다 받은 다음에 다음 행동을 하도록
cf. init(): 초기화하는 함수
(3)terminate 메소드
- this.connection이 없거나 연결이 끊기면 console로 확인
- Promise 리턴 : err가 없으면 delete this.connection하고 resolve로 ok 보낸다
3)query 메소드
: Promise 리턴
: MySQL 데이터베이스에 대해 SQL 쿼리를 실행하는데 사용
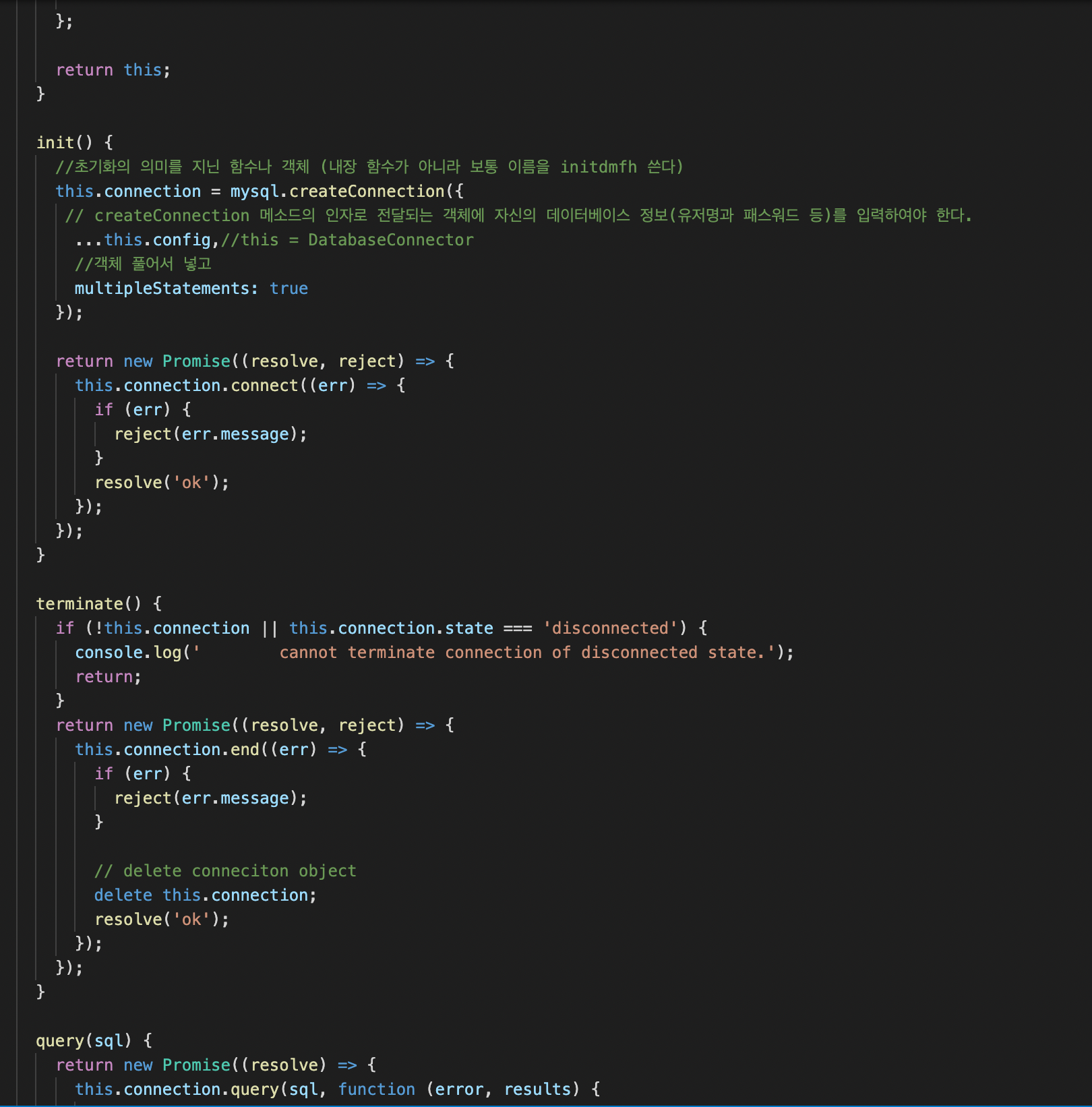
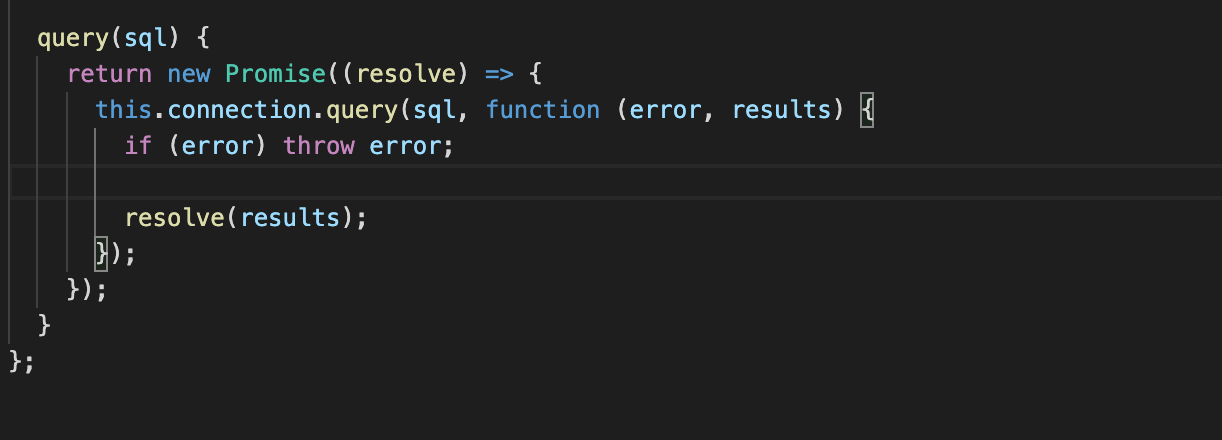
=> mydatabaseconnector, databaseconnector, factoryService까지 상속 받아서 사용하는 메소드
: db 서버에서 createConnection을 이용한 결과물에 대해 query()를 사용
=> 클래스.query()의 인자로 넣은 sql을 (두번째 인자인 콜백함수의 두번째 인자인 results에 넣어서 resolve()의 인자로) then에서 사용 가능
/migration/schema.sql
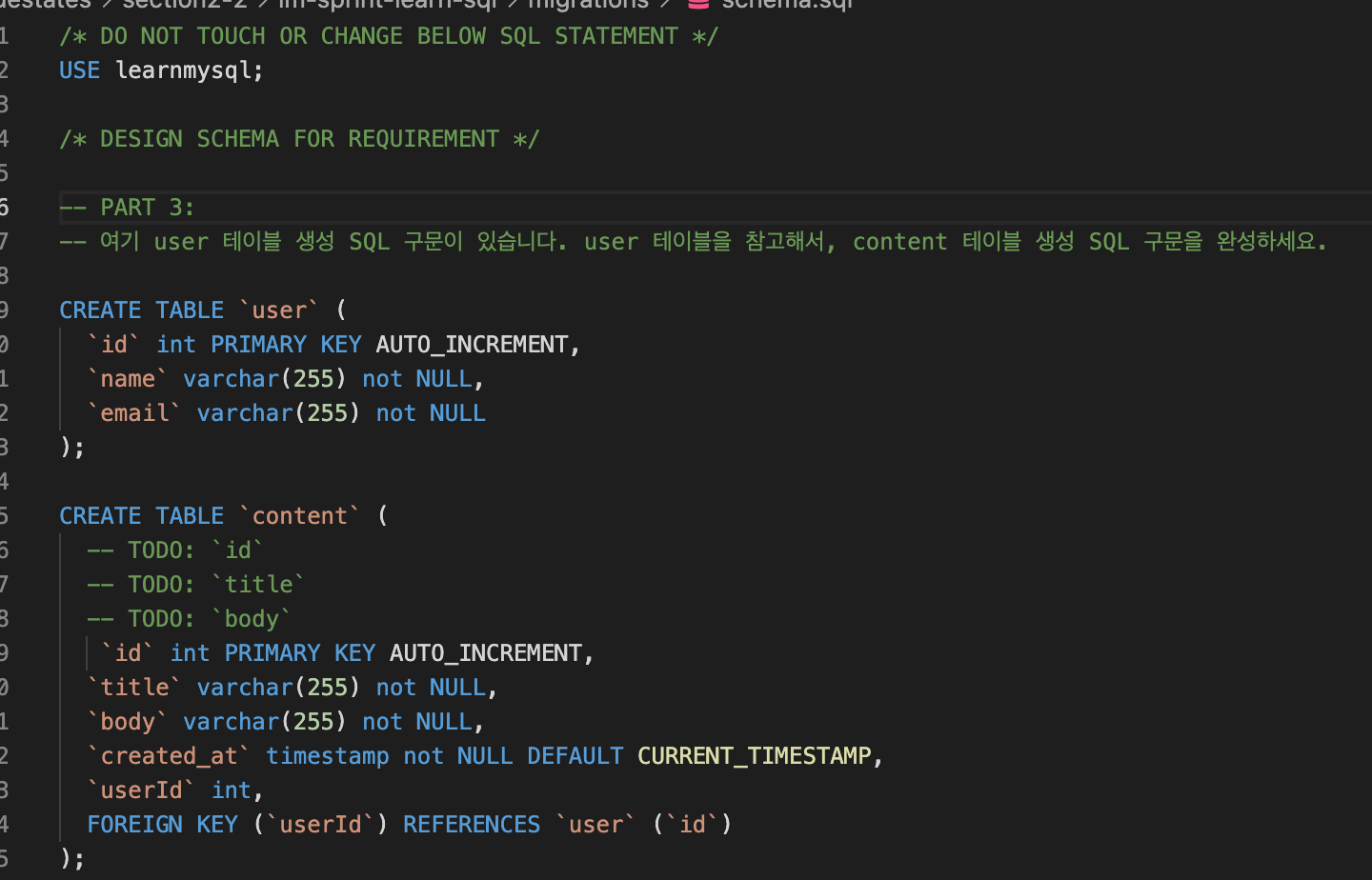
.SQL는 구조적 쿼리 언어 (SQL)에 의해 작성된 파일입니다. 그것은 데이터베이스 구조를 만들거나 수정하는 명령과 문이 포함되어 있습니다. 그것은 SQL 호환 데이터베이스 프로그램에서 읽을 수 및 텍스트 편집기로 편집 할 수 있습니다.
test/helper/FactoryService.js.
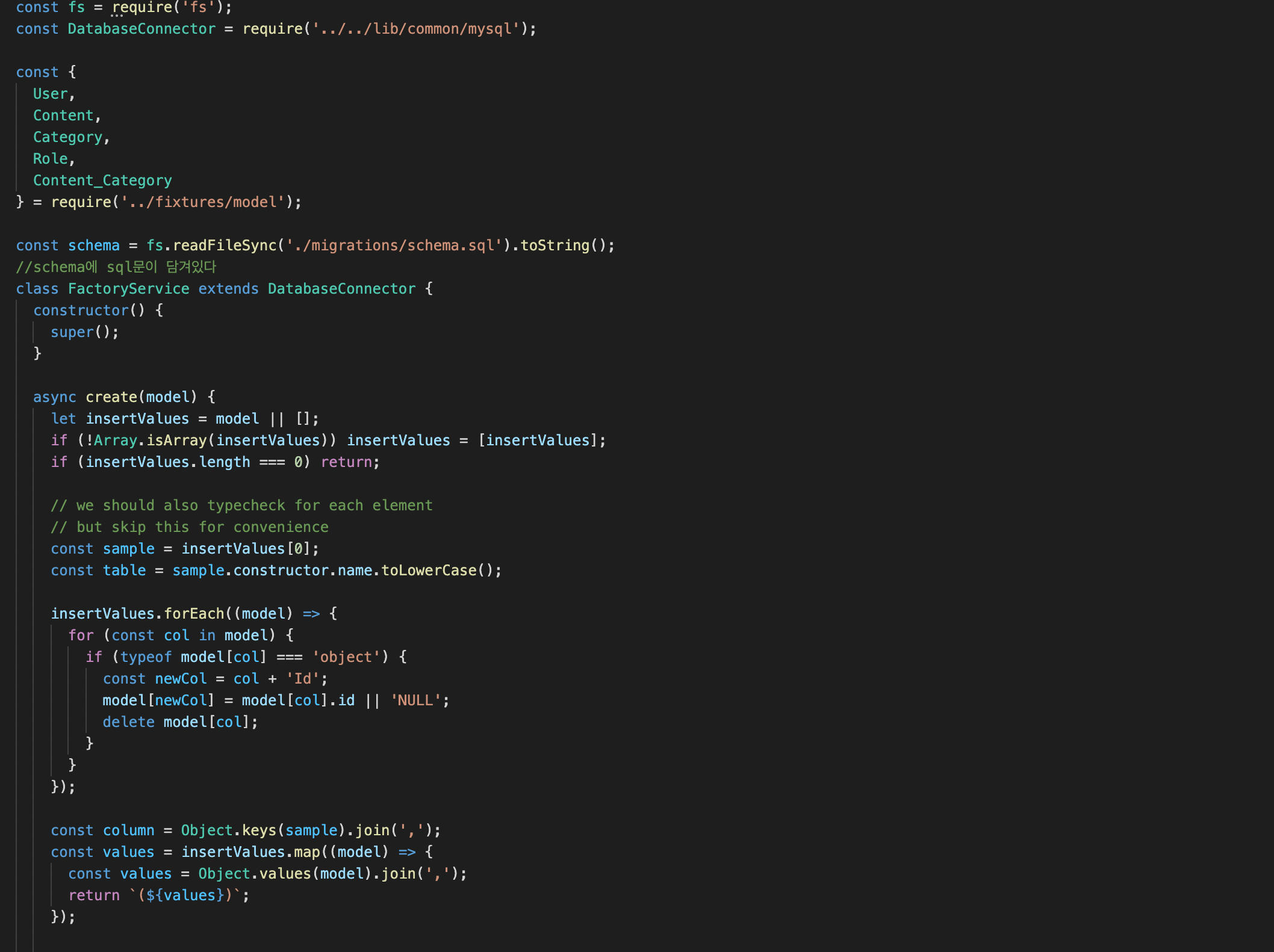

schema 변수에 schema.sql파일에 있는 내용을 string으로 변환해서 넣는다
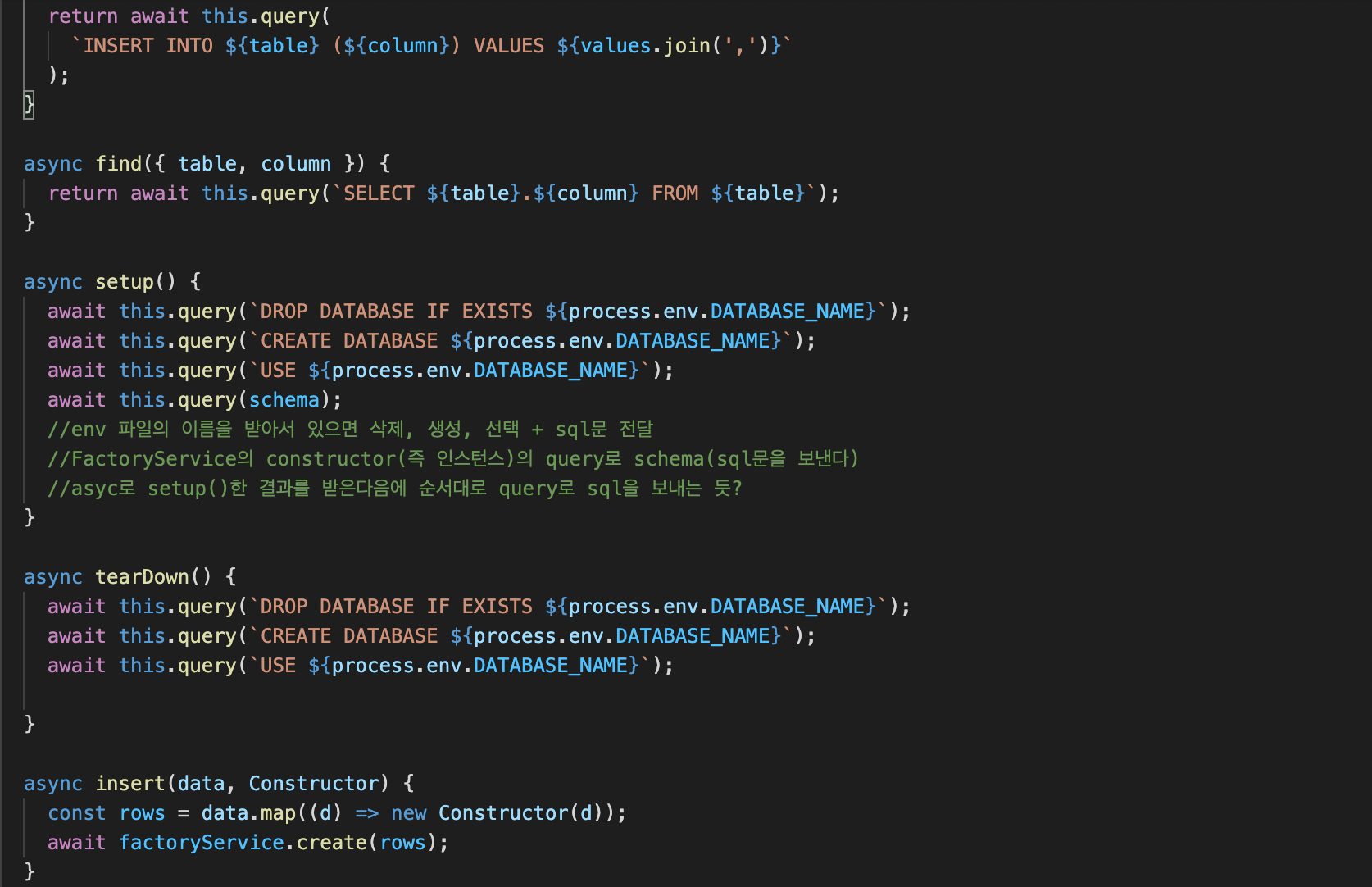
setup 메소드에서 this.query(schema)로 sql문을 보낸다
cf.singletonCase의 메소드 상속??
sql구문 사용한 파일
create table '테이블 이름'(
field이름?? 타입 내용
field이름 내용
field이름 내용
field이름 내용
)
cf. varchar(255) : 255는 1바이트, 즉 최소 단위
int PRIMARY KEY AUTO_INCREMENT (알아서 +1씩)
FOREIGN KEY (userid) REFERENCES user(id)
//userid는 user 테이블의 id를 참조한다
/script/part3
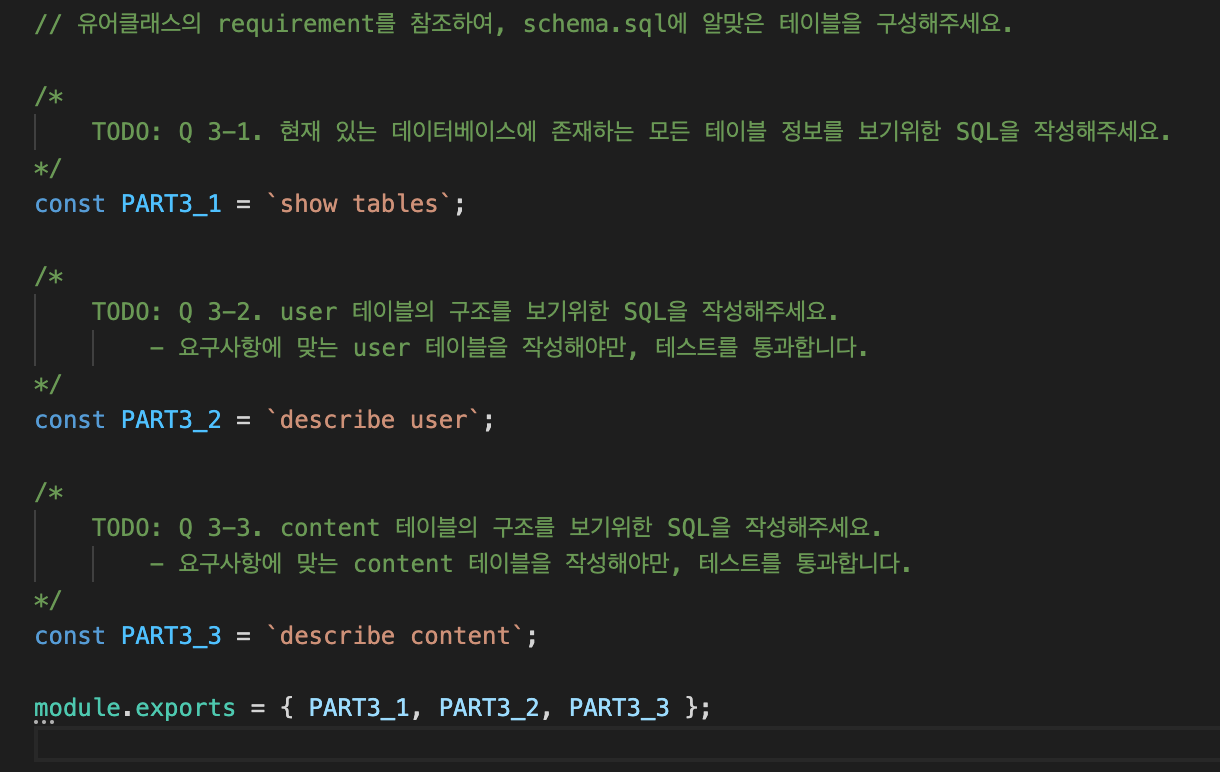
/test/part3.test.js

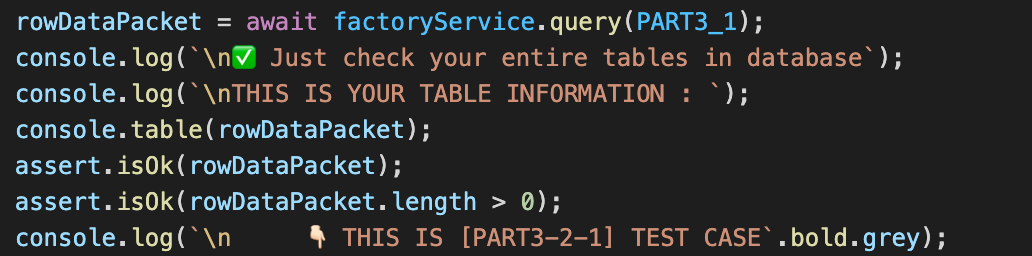
rowDataPacket은 factoryService의 query로 PART3_1을 넣는다
query : 조상 클래스인 singletonCase부터 있었던 메소드
인자로 받은 sql 문을 내부의 콜백함수에게 전달해 resolve(인자)로 넣는다
그러므로 await해서 rowDataPacket에 sql문(PART3_1)을 넣은 것에 대한 result가 담긴다
console.table을 하면 표 모양으로 나온다
