MongoDB
- 대표적인 NoSQL 도큐먼트 데이터베이스
- 도큐먼트 데이터베이스
: 데이터를 테이블이 아닌 문서처럼 저장하는 데이터베이스
: JSON 유사 형식으로 데이터 문서화
: (필드 - 값 형태) * n = 컬렉션
✅NoSQL의 장점 및 특징
✅MongoDB의 도큐먼트(Document)와 컬렉션(Collection)
- JSON vs BSON
- 도큐먼트 export, import
✅MongoDB의 Atlas
- 클러스터(Cluster)와 레플리카 세트(Replica set)
- Atlas: GUI(Graphical User Interface) / shell 쿼리문 사용하기
✅MongoDB에서 CRUD
- Insert(C), Find(R), Update(U), Delete(D)에 대한 쿼리문 작성
- 연산자와 프로젝션(Projection) 사용
- 배열과 서브 도큐먼트 쿼리
✅Aggregation Framework: aggregate 명령어로 쿼리할 수 있다.
- $match, $project, $group 연산자를 사용할 수 있다.
MongoDB Basic
- 데이터가 구성되는 방법
- db에 쿼리를 사용하고 저장하는 방법
- 인덱싱 등
NoSQL이란?
- 관계형 테이블의 레거시한 방법을 사용하지 않는 데이터 저장소
- 데이터를 행과 열이 아닌 체계적인 방식으로 저장
ex. mongodb
- nosql 도큐먼트 데이터베이스
- 데이터 > 도큐먼트 > 컬렉션
NoSQL 사용하는 케이스
- 비구조적인 대용량의 데이터 저장 시 [비구조]
- 관계에 중점을 둔 sql 데이터베이스보다 자유로운 형태로 데이터 저장
- 필요에 따라 새로운 데이터 유형 추가
- SW 개발에 정형화되지 않은 많은 양의 데이터가 필요한 경우 효율적
- 클라우드 컴퓨팅 및 저장 공간 최대한 활용하는 경우 [최대한 ]
- NoSQL db는 데이터베이스를 클라우드 기반으로 쉽게 분리할 수 있도록 지원
- 저장 공간을 효율적으로 사용
- 수직적으로 확장하는 sql(관리가 어려움)로 달리 수평적으로 확장해서 증설
- 빠르게 서비스를 구축하고 데이터 구조를 자주 업데이트 할 때
-스키마를 미리 준비할 필요가 없음 -> 개발을 빠르게 해야 하는 경우에 매우 적합
: 시장에 빠르게 프로토타입 출시
: sw버전별로 많은 다운타임 없이 데이터 구조 자주 업데이트해야 하는 경우
cf.다운타임 : 데이터베이스의 서버를 오프라인으로 전환하여 적업하는 시간
: 일일이 스키마를 수정해 주어야 하는 관계형 db보다 noSQL 기반의 비관계형 db가 더 효율적
Atlas cloud
: mongoDB -> 아틀라스 -db 설정-> 클라우드
아틀라스
: 데이터를 시각화, 분석, 내보내기, 빌드하는데에 사용
: 클러스터를 배포하고, 클러스터를 그룹화된 서버에 데이터를 저장
아틀라스 사용자는 클러스터를 배포할 수 있으며
클러스터는 그룹화된 서버에 데이터를 저장한다
이 서버는 레플리카 세트로 구성되어 있으며, 레플리카 세트는 동일한 데이터를 저장하는 몇 개의 연결된 MongoDB 인스턴스의 모음이다
- 인스턴스는 특정 SW를 실행하는 로컬 또는 클라우드의 단일 머신 ㅁ
- 이 경우 인스턴스는 클라우드에서 실행되는 MongoDB 데이터베이스다
cf. 클러스터 : 인스턴스들의 모임, 하나의 시스템처럼 작동
단일 클러스터에서 각각의 인스턴스는 동일한 복제본을 가지고 있으며 이 모음을 레플리카 세트라고 한다
클러스터를 이용해 배포할 경우 자동으로 레플리카 세트 생성된다
클러스터 배포
클러스터, 레플리카 세트, 단일 클러스터
클러스터 : 인스턴스들의 모임
-> 하나의 시스템처럼 작동
단일 클러스터에서 각각의 인스턴스는 동일한 복제본을 가지고 잇다
이 모음을 레플리카 세트라고 한다
클러스터를 이용해 배포할 경우 이는 자동으로 레플리카 세트를 생성한다
레플리카 세트
: 동일한 데이터를 저장하는 몇 개의 연결된 mongodb 인스턴스의 모음
: 데이터의 사본을 저장하는 인스턴스의 모음
: 인스턴스 중 하나에 문제가 발생하더라도 데이터는 그대로 유지
나머지 레플리카 세트의 인스턴스에 저장된 데이터로 작업 가능
인스턴스 : 특정 sw를 실행하는 로컬 또는 클라우드의 단일 머신
-> 여기서는 클라우드에서 실행되는 mongoDB 데이터베이스
레플리카 세트
동일한 데이터를 저장하는 소수의 연결된 머신을 뜻합니다. 레플리카 세트 중 하나에 문제가 발생하더라도, 데이터를 그대로 유지할 수 있습니다.
인스턴스
로컬 또는 클라우드에서 특정 소프트웨어를 실행하는 단일 머신, MongoDB에서는 데이터베이스입니다.
클러스터
데이터를 저장하는 서버 그룹으로 여러 대의 컴퓨터를 네트워크를 통해 연결하여 하나의 단일 컴퓨터처럼 동작하도록 제작한 컴퓨터를 뜻합니다.
Sprint
관계형 vs NoSQL
: db를 쓸 때 선택할 기준이 있어야
데이터베이스 이전에 정보 저장 시 파일 시스템 사용
file-based system의 문제점
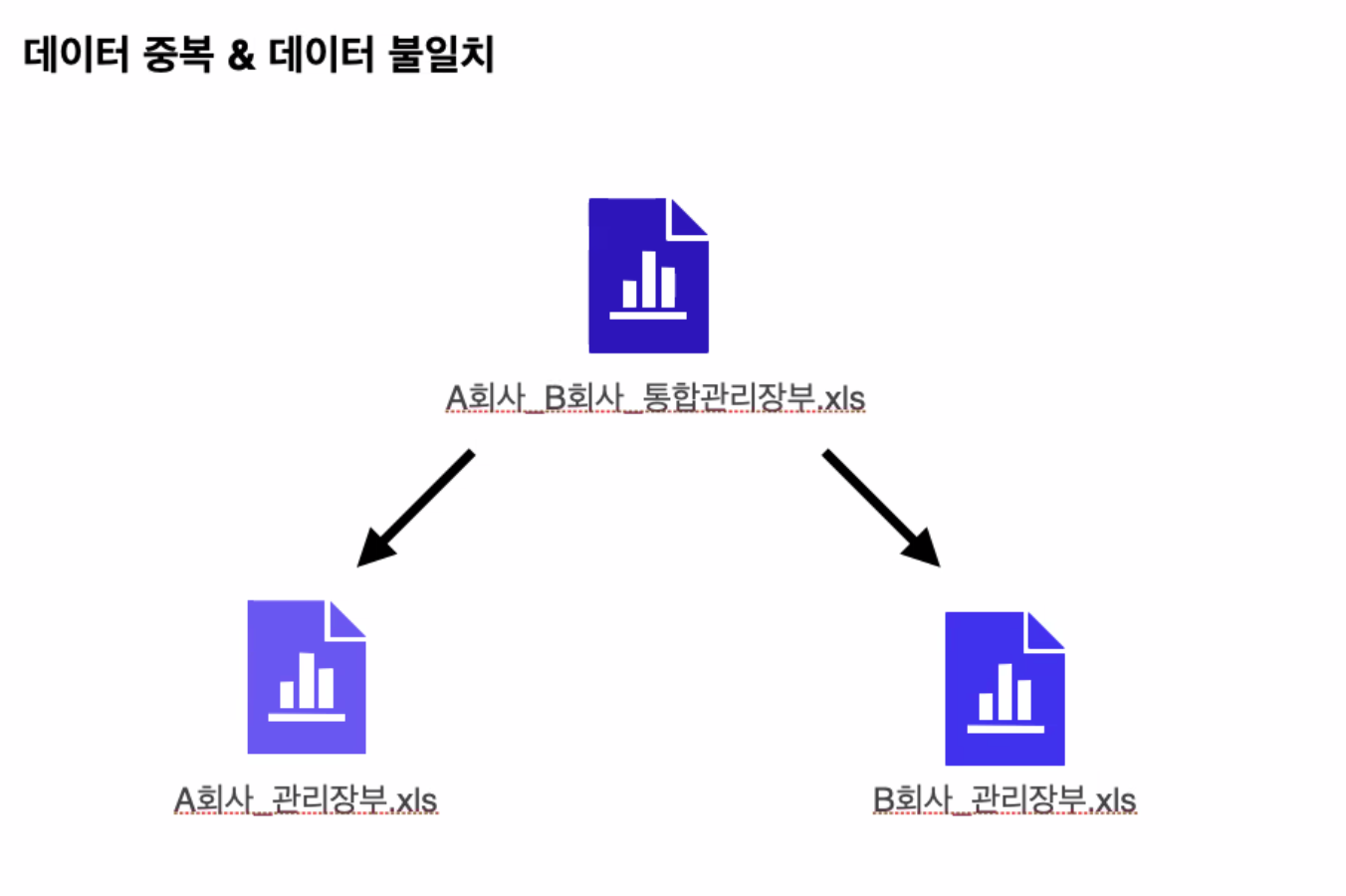
1. 데이터 중복
2. 데이터 불일치
3. 데이터 접근 어려움 : 디렉토리 이름을 타고타고 들어가야 한다 ex./dir/filename...
4. 보안 문제 : 들어가는 사람마다 admin 권한을 부여하기 때문에 누구든지 파일을 수정할 수 있다
5. 동시 접근 어려움 : 공유 드라이브에서 같은 파일에 접근하려고 하면 문제
이걸 해결하기 위해 db 시스템 만들어짐
데이터베이스란?
-데이터 관련된 데이터들의 집합으로서 공유된다
-데이터베이스는 데이터의 저장소로써 한번 정의되며 여러 사용자나 프로그램에 의해 접근된다
-사용하려고 저장된다
그러므로 데이터를 어떻게 사용할 것인지에
DBMS : database management system
ACID, 체계적,
RDBMS
sql문은 프로그래밍 언어 중에서 가장 오래된 언어 중에 하나다
처음에 db를 만들었을 때는 관계적인 집합의 관점으로 봤다
그게 지금까지도 사용하고 있기 때문에 안정적이고 최적화가 되어왔다
하지만 이제 관계형이 아닌 데이터베이스도 사용
거대한 데이터가 생기기 시작해서
관계가 아닌 관점으로 데이터를 보기 시작했다
noSQL을 사용할 때
-거대한 데이터들을 다룰 때
-엄청난 데이터 쓰기 성능이 필요할 때
-key-value 방식으로 빠르게 접근이 가능하다
-유연한 스키마와 데이터타입
: 관계형에서는 고정된 스키마(필드, 데이터타입을 모두 정해놓아야 한다)
: 빠르게 출시해서 피드백을 받아야 하는 서비스일수록 이런 방식 사용
sql
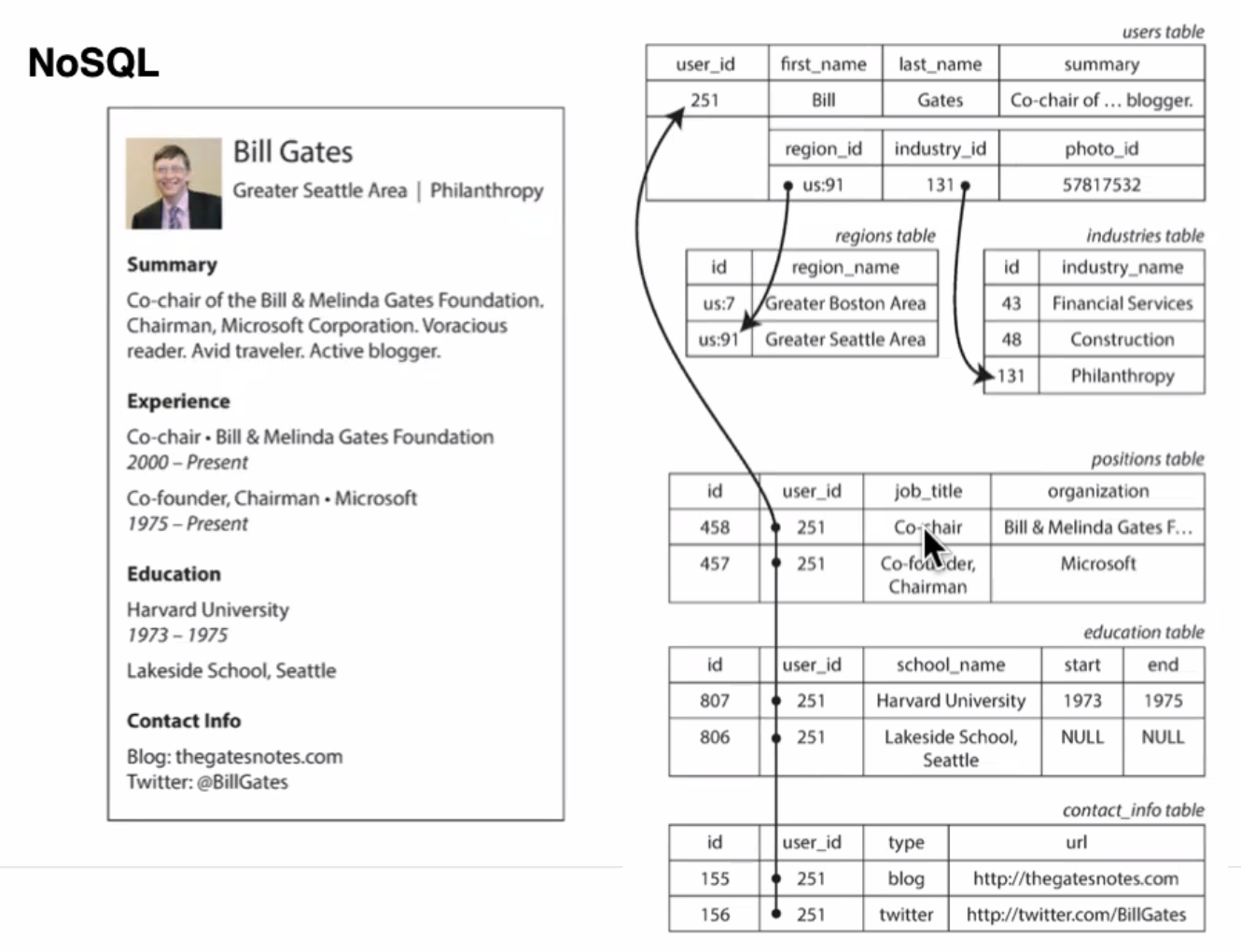
join을 여러 번 해야 한다
nosql

심플하고 직관적
개발자 입장에서 사용법이 용이하다
key-value 방식으로 빠르게 접근 가능하다
아틀라스 -> 로컬 (bson 형태로)
이때 사용할 keyword : mongodump를 사용한다
mongodump uri
이 다음에 dump를 이용
3tier 아키텍쳐
client -> server -> db
생각보다 너무 많은 트래픽이 몰리면 서버가 터진다
이럴 때는 용량을 늘리면 된다 : 스피드를 업그레이드 (수직적 확장)
수직적 확장의 문제 : 1)비싸다 2)한계가 존재한다
: 이럴 때는 컴퓨터를 더 산다(양을 늘린다)
-> 이걸 수평적 확장이라고 한다
mongoDB에서는 이런 수평적 확장을 '샤딩'이라고 한다
sql 방식도 확장 가능 : mongoDB에서 확장에 더 최적화되어 있을 뿐
Fault : 다양한 원인에 의해서 제기능을 못할 때
Failure : 어떤 기능을 수행할 수 없는 상태를 의미,
결함에 의해서 발생하지만 결함이 있다고 실패가 항상 있는 건 아님
mongoDB : 메인 컴퓨터(primary 1개)+ secondary(2개)
-> primary에서 문제가 있으면 secondary에서 받아서 해결
이렇게 컴퓨터를 모아놓은 것을 cluster라고 하고, mongoDB에서는 replica set이라고 한다
분산해서 사용하는 것
거대한 데이터들을 다룰 때 유용하다
엄청난 데이터 쓰기 성능이 필요할 대 유용하다
가용성이 높다
레플리카 set끼리 공유하는 것도 샤딩
공유하는 거 다 샤딩
primary - secondary 끼리 : 샤딩
클러스터 끼리 : 샤딩
그 외: 샤딩
crud 꼭 해보기

