문자열
인코딩 방식
2010~: 유니코드로 통일
하지만 프로그래밍 언어마다 문자열을 다루는 자료형이 다르다
ex. string, varchar 등
-> 이를 이해하기 위해 문자열을 다루는 기본적인 방식을 알고 있어야 한다
유니코드란?
유니코드 협회(Unicode Consortium)가 제정하는 전 세계의 모든 문자를 컴퓨터에서 일관되게 표현하고 다룰 수 있도록 설계된 산업 표준.
: ex. ISO 10646 문자 집합, 문자 인코딩, 문자 정보 데이터베이스, 문자를 다루기 위한 알고리즘 등을 포함
이전에는 같은 한글이라도 적힌 텍스트 파일 표현 방식이 제각각
그러므로 어떤 파일이 지원하지 않는 다른 인코딩 형식으로 저장되어 있는 경우 파일을 제대로 불러올 수 없음
-> 그러므로 유니코드 통해 현존 문자 인코딩 방법을 통일
인코딩(부호화)이란?
어떤 문자나 기호를 -> 컴퓨터가 이용할 수 있는 신호로 만드는 것입니다.
인코딩: 입력, 암호화
디코딩 : 복호화, 해독
그러므로 미리 정해진 기준을 바탕으로 입력과 해독이 처리되어야 합니다.
문자셋(문자열 세트) : 인코딩과 디코딩 기준
-> 유니코드 : 문자셋의 국제 표준
ASCII 문자란?
: 영문 알파벳을 사용하는 대표적인 문자 인코딩
: 7 비트로 모든 영어 알파벳을 표현
: 52개의 영문 알파벳 대소문자, 10개의 숫자, 32개의 특수 문자, 하나의 공백 문자 포함
유니코드는 ASCII를 확장한 형태입니다.
UTF-8 vs UTF-16
- 인코딩 방식의 차이
- UTF: Universal Coded Character Set + Transformation Format
- UTF- 뒤에 등장하는 숫자: 비트(bit)
- UTF-8
특징: 가변 길이 인코딩
UTF-8은 유니코드 한 문자를 나타내기 위해 1 byte(= 8 bits) ~ 4 bytes까지 사용
원리
ex. '코'
유니코드 : U+CF54 (16진수, HEX)
이진법(binary number): 1100-1111-0101-0100
UTF-8:
1110xxxx 10xxxxxx 10xxxxxx # x 안에 순서대로 값을 채워넣습니다.
11101100 10111101 10010100 (3byte)UTF-8로 인코딩하는 과정
let encoder = new TextEncoder(); // 기본 인코딩은 'utf-8'
encoder.encode('코') // Uint8Array(3) [236, 189, 148](236).toString(2) // "11101100"
(189).toString(2) // "10111101"
(148).toString(2) // "10010100"ASCII 코드는 7비트로 표현되고,
UTF-8에서는 다음과 같이 1 byte의 결과로 만들 수 있습니다.
다음 예제는 b 라는 문자를 UTF-8로 인코딩한 결과입니다.
0xxxxxxx
01100010
[데이터] UTF-8로 표현된 'b'
encoder.encode('b') // Uint8Array [98]
(98).toString(2) // "1100010"
[코드] 'b'라는 문자를 UTF-8로 표현할 수 있습니다.UTF-8
- 1 byte~ 4 bytes까지의 가변 길이를 가지는 인코딩 방식
- 네트워크를 통해 전송되는 텍스트는 주로 UTF-8로 인코딩
: 사용된 문자에 따라 더 작은 크기의 문자열을 표현할 수 있기 때문 - ASCII 코드의 경우 1 byte
- 크게 영어 외 글자는 2byte, 3byte
- 보조 글자는 4byte를 차지합니다.
: 이모지는 보조 글자에 해당하기 때문에 4byte가 필요합니다.
- UTF-8 특징
- 바이트 순서가 고정됨
- UTF-16 특징
- 코드 그대로 바이트로 표현 가능
- 바이트 순서가 다양함
-유니코드 코드 대부분(U+0000부터 U+FFFF; BMP) 을 16 bits로 표현
대부분에 속하지 않는 기타 문자는 32 bit(4 bytes)로 표현
UTF-16도 가변 길이라고 할 수 있으나, 대부분은 2 바이트로 표현
U+ABCD라는 16진수를 있는 그대로 이진법으로 변환
-> 1010-1011-1100-1101
이 이진법으로 표현된 문자를 16 bits(2 bytes)로 그대로 사용
바이트 순서(엔디언)에 따라 UTF-16의 종류도 달라진다
UTF-8에서는 한글은 3 바이트, UTF-16에서는 2 바이트를 차지합니다.
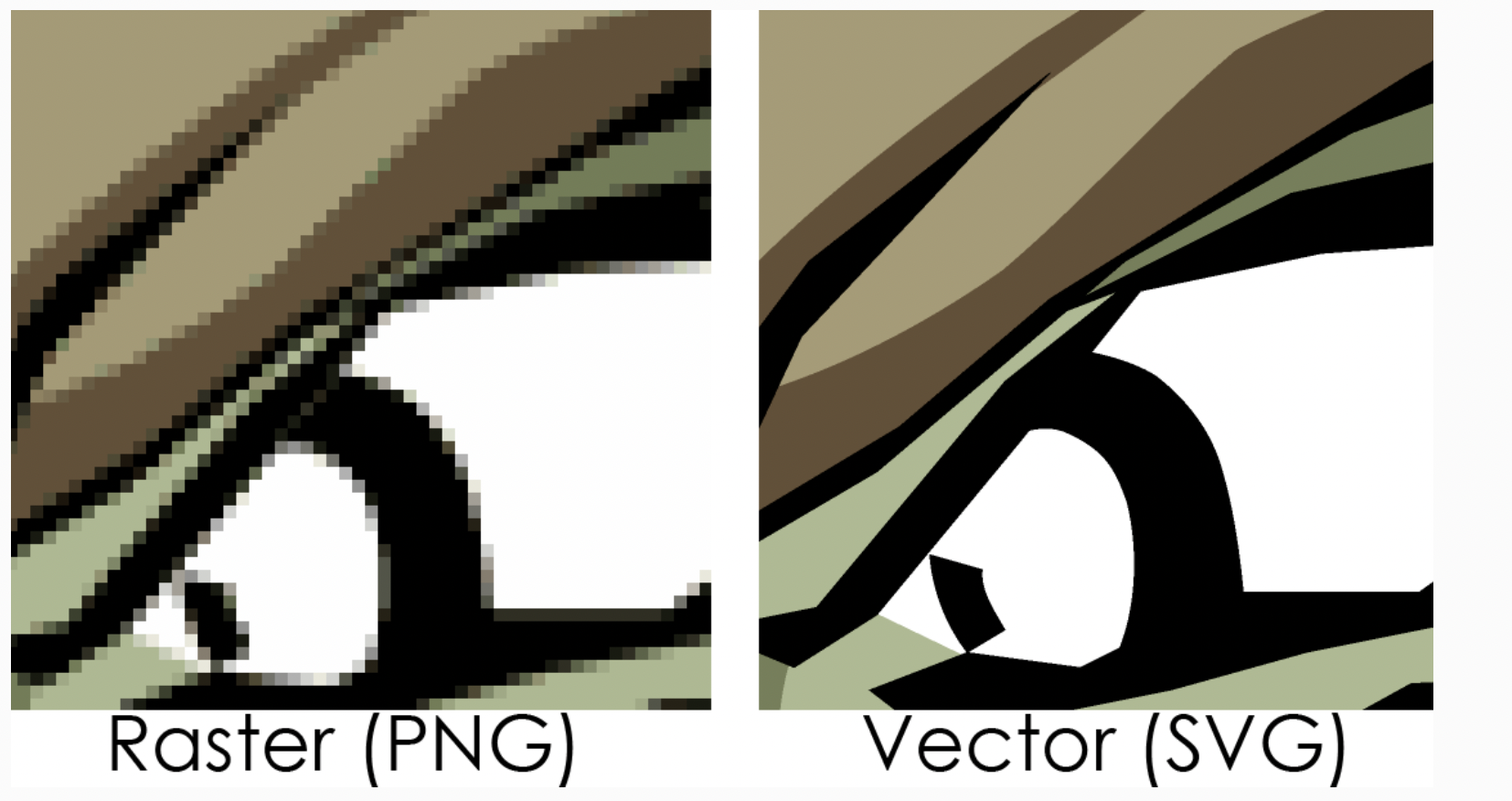
그래픽
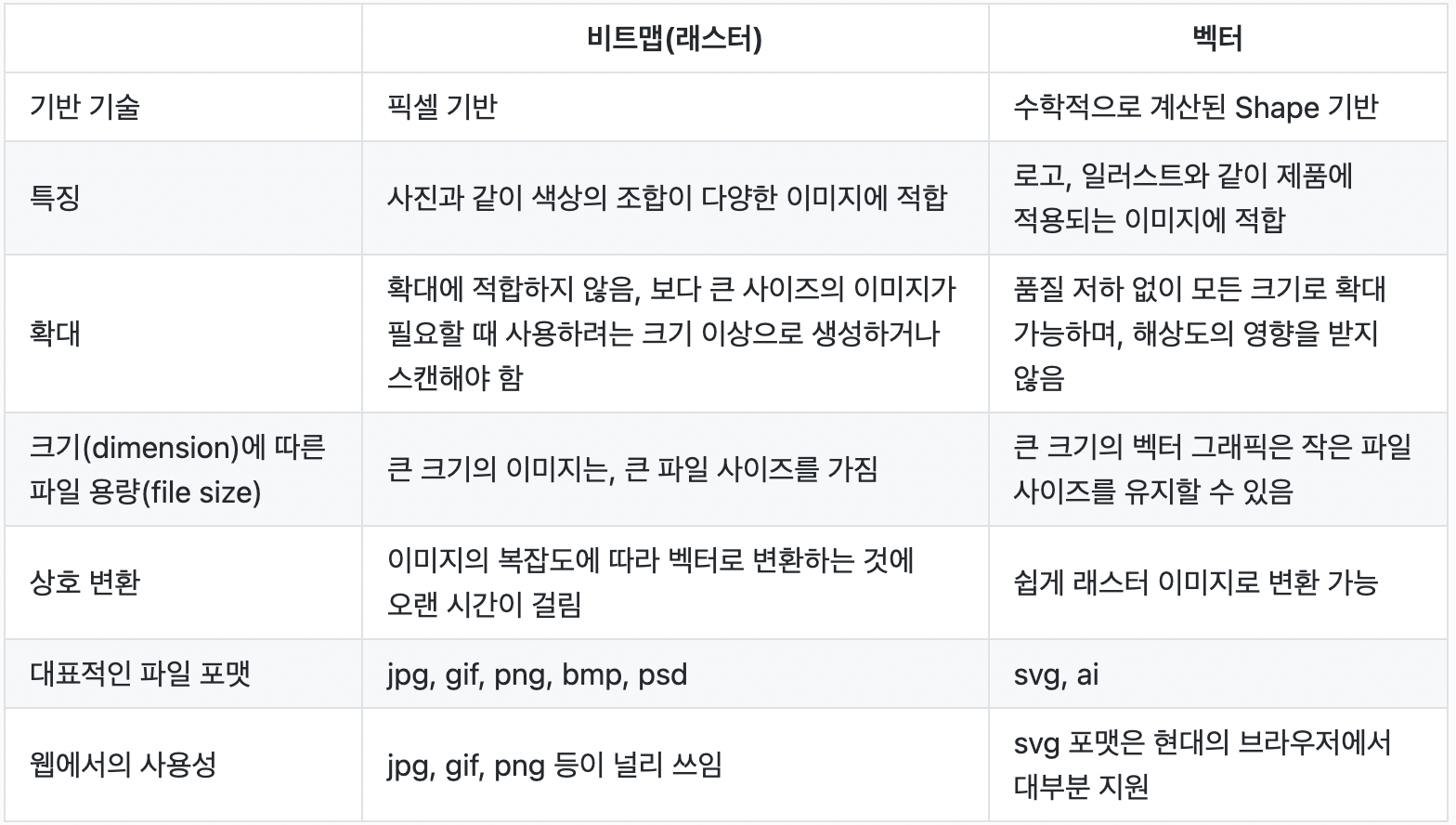
비트맵(래스터) vs 벡터 이미지
운영체제 개요
운영체제 : 하드웨어에게 일을 시키는 주체
-> 운영체제 없이는 하드웨어가 sw의 명령을 들을 수 없다
1. 운영체제
시스템 자원 관리
응용프로그램 : 컴퓨터를 이용해 다양한 작업을 한다
운영체제 : 응용 프로그램이 하드웨어에게 일을 시킬 수 있도록 도움
응용 프로그램 --- 운영체제 ---> 하드웨어
시스템의 자원이랑 하드웨어의 차이?
CPU, RAM, 디스크 등은 하드웨어??
- 프로세스 관리(CPU)
- 메모리 관리(RAM)
- I/O(입출력) 관리 (디스크, 네트워크 등)
-> 이런 시스템 자원을 관리하는 주체가 바로 운영체제
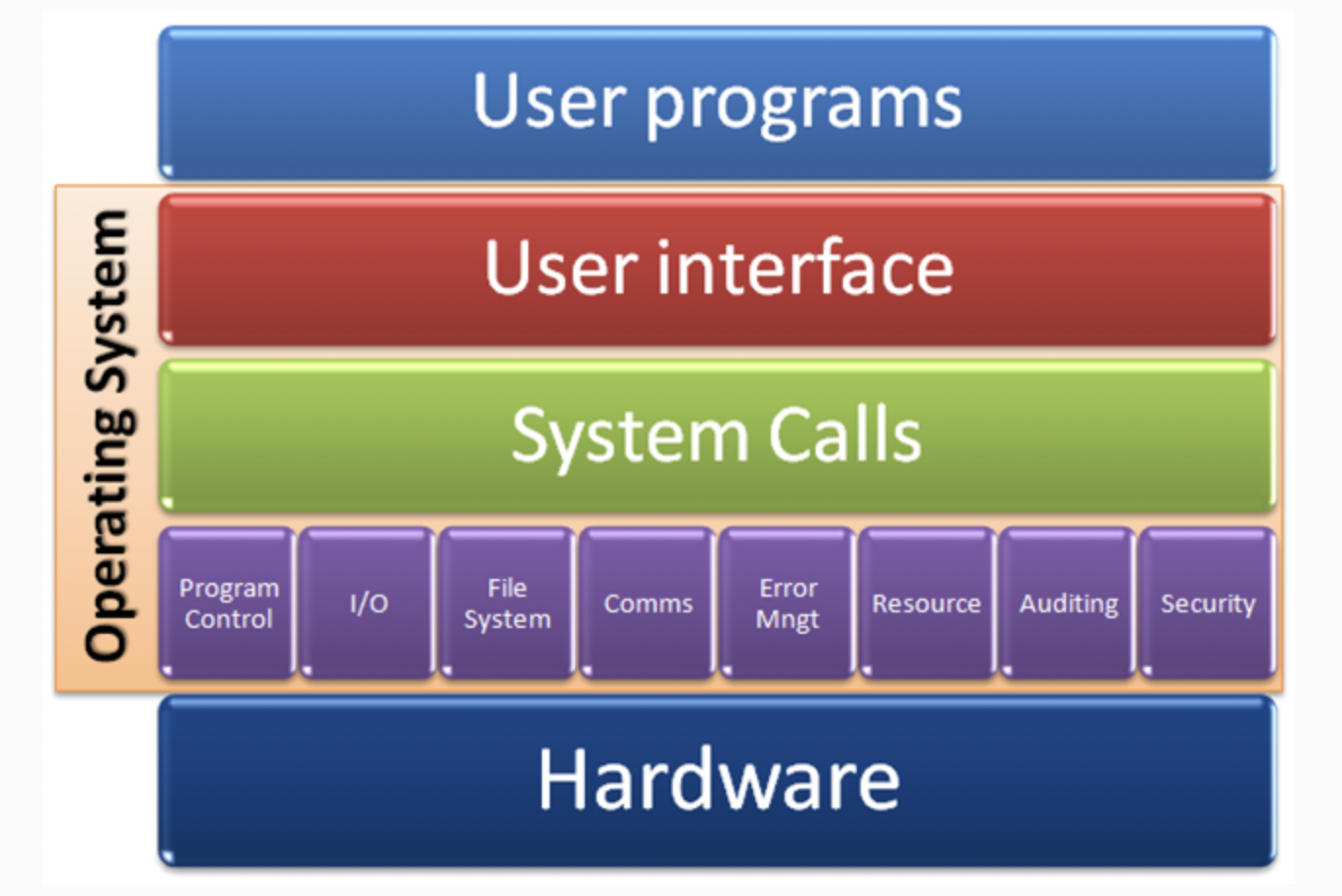
프로그램이 있으면 UI 등등의 것들을 통해 하드웨어에 주문 전달
응용 프로그램 관리
응용 프로그램은 운영체제를 통해 시스템 자원에 접근, 컴퓨터에게 명령 가능
문제1. 해킹 당하기 굉장히 쉬워짐
ex. 악의적인 목적을 가진 프로그램
-> 디스크 등에 접근 가능하면 정보 유출
문제2. 여러 사람이 하나의 기기를 사용하는 경우
그러므로 응용 프로그램에서 권한에 대한 관리 필요
이 권한은 운영체제로부터 부여 받는다
응용 프로그램 - API(인터페이스) - 운영체제
: 응용 프로그램이 컴퓨터에 접근하기 위해서 운영체제 필요
: 응용 프로그램이 운영체제와 소통하기 위해
- API 필요
- 운영체제에서 다양한 함수 제공(시스템 콜)
ex. 스마트폰에서 사용자에게 어떤 디바이스(카메라 등)의 사용을 허락받는 화면
응용 프로그램 역시 운영체제가 프린터 사용을 허가해 주지 않는다면 사용할 수 없습니다.
워드프로세서 프로그램 -> 프린터를 사용
워드프로세서 프로그램 -> 운영체제로부터 프린터 사용에 대한 권한을 부여
-> 프린터를 사용할 때 필요한 API를 호출해( API는 시스템 콜로 구성 )
How to learn?
소위 공룡책이라 불리는 Operating System Concepts 책을 추천합니다. 정리된 한글 문서도 존재합니다.
응용 프로그램
-> 운영체제 (하드웨어 접근 권한 부여) + API 호출(시스템 콜(함수))
-> 하드웨어에 시스템 콜로 조작 가능
프로세스, 스레드, 멀티 스레드
1. 프로세스(Process)
프로세스란?
운영체제에서 실행 중인 하나의 애플리케이션
애플리케이션 실행 -> 운영체제로부터 실행에 필요한 메모리 할당 -> 애플리케이션 코드 실행
이때 실행되는 애플리케이션: 프로세스
하나의 애플리케이션으로 여러 프로세스 생성 가능
ex. Chrome 브라우저를 두 개 실행하면, 두 개의 프로세스가 생성
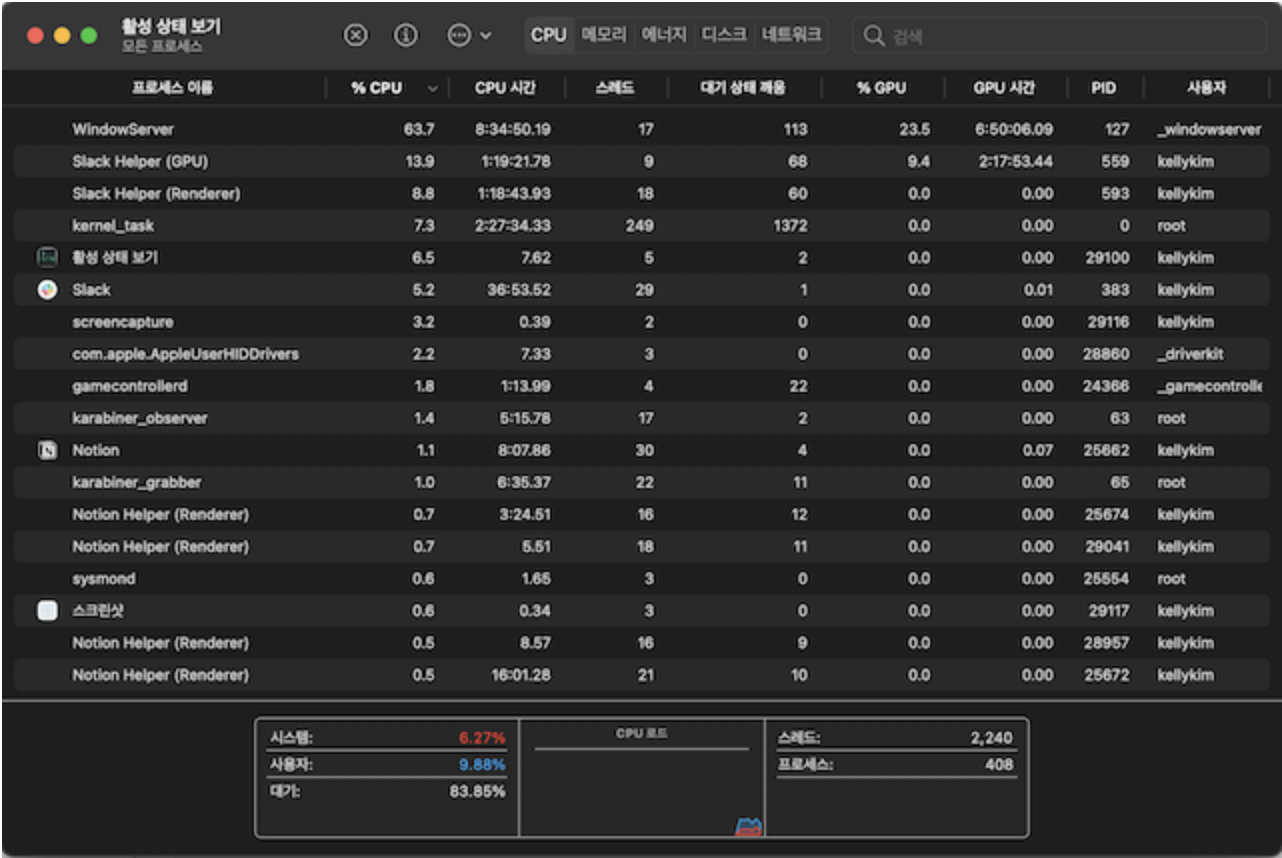
활성 상태창(macOS, Windows에서는 작업관리자) 예시
: 항목 다 프로세스
2. 스레드(Thread)
스레드
: 한 가닥의 실
: 한 가지 작업을 실행하기 위해 순차적으로 실행한 코드를 실처럼 이어 놓았다고 해서 유래된 이름
하나의 스레드는 코드가 실행되는 하나의 흐름
-> 한 프로세스 내에 스레드가 두 개라면 코드가 실행되는 흐름이 두 개 생긴다는 의미
3. 멀티 스레드(Multi-Thread)
멀티 태스킹
: 두 가지 이상의 작업을 동시에 처리하는 것
: 멀티 프로세스 또는 하나의 프로세스 내에서 멀티 태스킹
ex. 동시에 워드로 문서작업 + Chrome 브라우저에서 음악
하나의 프로세스가 두 가지 이상의 작업을 처리하는 방법
: 멀티 스레드
멀티 프로세스 : 애플리케이션 단위의 멀티 태스킹
멀티 스레드 : 애플리케이션 내부에서의 멀티 태스킹
운영체제는 멀티 태스킹을 할 수 있도록, 프로세스마다
1)CPU 및 메모리 자원을 적절히 할당
2)병렬로 실행
멀티 스레드
- 대용량 데이터의 처리시간을 줄이기 위해
-> 데이터를 분할하여 병렬로 처리하는 데에 사용(??) - UI를 가지고 있는 애플리케이션에서 네트워크 통신을 하기 위해 사용(??)
- 여러 클라이언트의 요청을 처리하는 서버를 개발할 때에도 사용
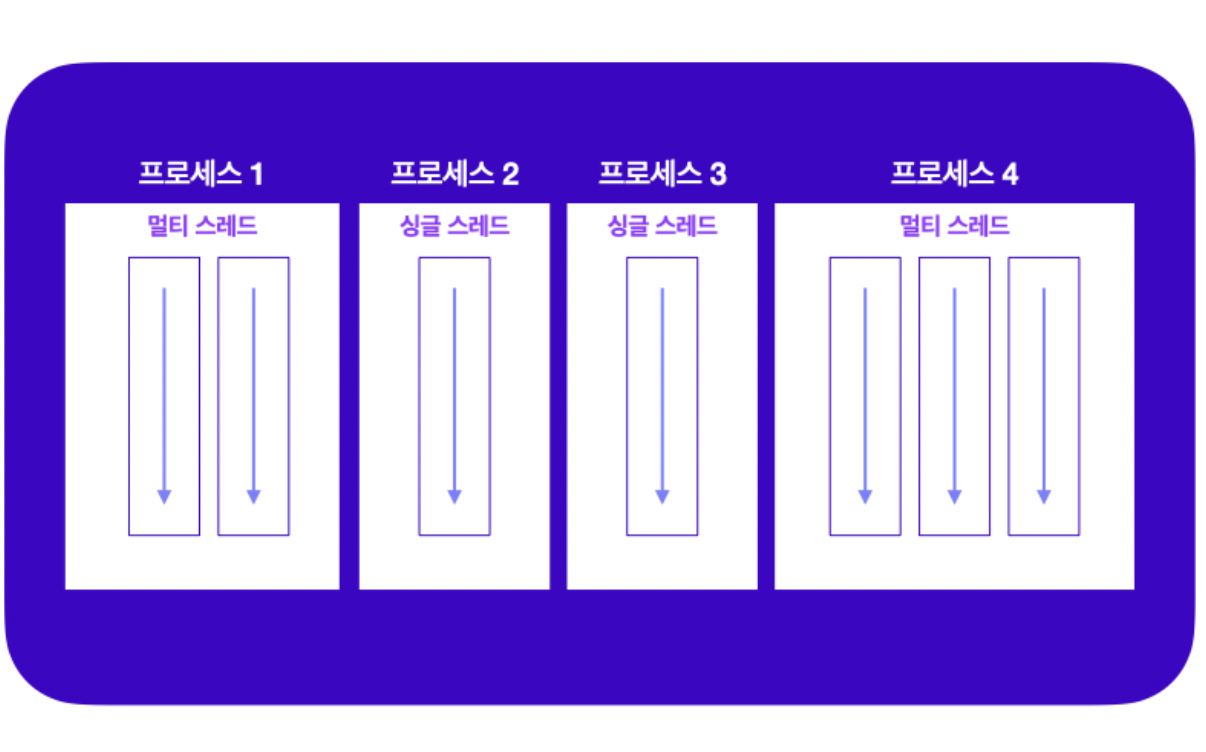
멀티 스레드
 하나의 프로세스 안에 여러 스레드 가능
하나의 프로세스 안에 여러 스레드 가능
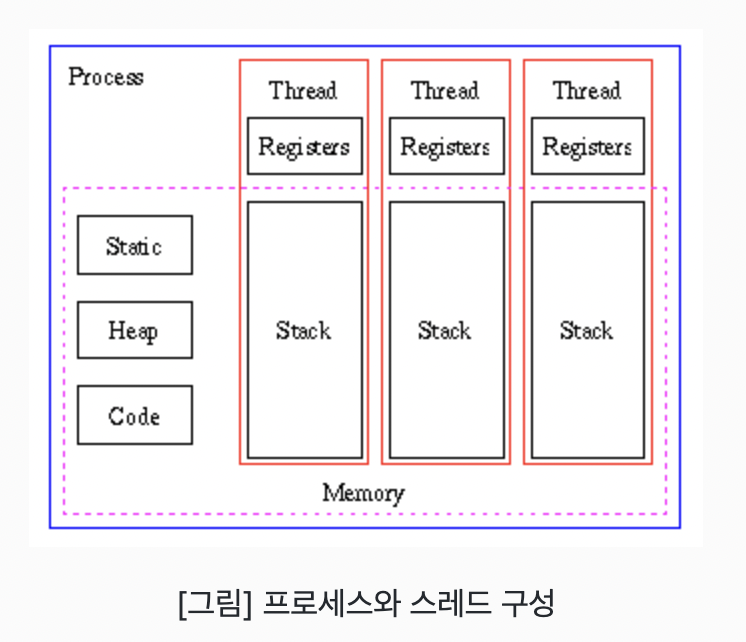
1. 스레드의 특징
- 프로세스 내에서 실행되는 흐름의 단위
- 각 스레드마다 call stack이 존재
(call stack: 실행 중인 서브루틴을 저장하는 자료 구조) - 스레드는 다른 스레드와 독립적으로 동작
2. 멀티 스레딩의 장점
다른 프로세스를 이용하여 동시에 처리하던 일을 스레드로 구현할 경우,
1) 메모리 공간과 시스템 자원의 소모 감소
: 스레드 간의 통신이 필요한 경우에도 별도의 자원을 이용하는 것이 아니라, (1)전역 변수의 공간 or
(2)동적으로 할당된 공간
: Heap 영역을 이용
따라서, 다른 프로세스 간 통신 방법(IPC)에 비해 스레드 간의 통신 방법이 훨씬 간단!
2)프로그램의 응답 시간 단축
시스템의 처리량(Throughput)이 향상, 자원 소모가 감소 되므로
3. 멀티 스레딩의 문제점
1)멀티 프로세스 기반
:프로세스 간 공유하는 자원이 없으므로 동일한 자원에 동시 접근 X
2)멀티 스레딩 기반
서로 다른 스레드가 (1)같은 데이터에 접근 가능 (2)힙 영역 공유
-> 서로 사용 중인 변수나 자료구조에 접근하여 엉뚱한 값을 읽어오거나 수정하는 일이 발생 가능
=> 동기화 작업이 필요합니다.
1) 작업 처리 순서를 제어 2)공유 자원에 대한 접근을 제어
관련 키워드
데드락(Deadlock, 교착 상태)
뮤텍스(Mutex), 세마포어(Semaphore)
4. 동시성과 병렬성의 차이
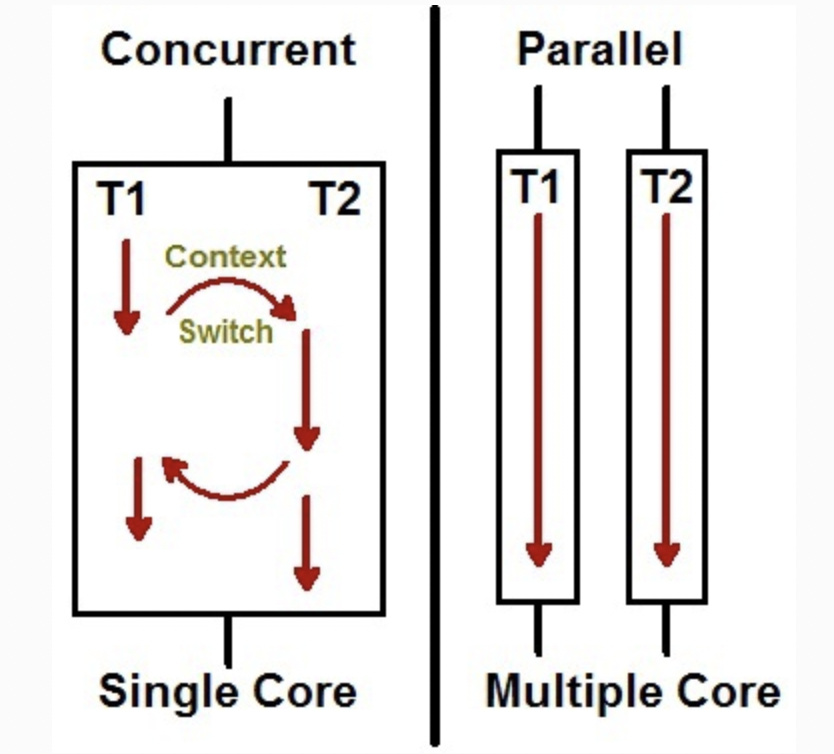
[싱글 코어와 멀티 코어 예시]동시에 돌릴 수 있는 스레드 수
: 컴퓨터에 있는 코어 개수로 제한 (코어가 뭐얌)
운영체제(또는 가상 머신)는 각 스레드를 시간에 따라 분할하여, 여러 스레드가 일정 시간마다 돌아가면서 실행되도록 한다
이런 방식을 시분할이라고 합니다.
Concurrency(동시성, 병행성)
: 여러 개의 스레드가 시분할 방식으로 동시에 수행되는 것처럼 착각을 불러일으킴 (돌아가면서 실행)
Parallelism(병렬성)
: 멀티 코어 환경에서 여러 개의 스레드가 실제로 동시에 수행됨
5. Context Switching이란?
다른 태스크(프로세스, 스레드)가 시작할 수 있도록 이미 실행 중인 태스크(프로세스, 스레드)를 멈추는 것
가비지 컬렉션
1. 가비지 컬렉션이란?
: 프로그램에서 더 이상 사용하지 않는 메모리를 자동으로 정리하는 것
이 기능을 가진 언어(혹은 엔진): 자바, C#, 자바스크립트 등
2. 대표적인 가비지 컬렉션의 방법
1)트레이싱
: 한 객체에 flag를 두고,
가비지 컬렉션 사이클(??)마다 flag에 표시 후 삭제하는 mark and sweep
객체에 in-use flag를 두고, 사이클마다 메모리 관리자가 모든 객체를 추적해서 사용 중인지 아닌지를 표시(mark)합니다.
그 후 표시되지 않은 객체를 삭제(sweep)하는 단계를 통해 메모리를 해제합니다.
2)레퍼런스 카운팅
: 한 객체를 참조하는 변수의 수를 추적하는 방법
: 객체를 참조하는 변수는 처음에는 특정 메모리에 대해 레퍼런스가 하나뿐이지만, 변수의 레퍼런스가 복사될 때마다 레퍼런스 카운트가 늘어난다.
객체를 참조하고 있던 변수의 값이 바뀌거나, 변수 스코프를 벗어나면 레퍼런스 카운트는 줄어듭니다.
레퍼런스 카운트가 0이 되면, 그 객체와 관련한 메모리는 비울 수 있습니다.
레퍼런스 카운트가 0이 된다는 말은 아무도 그 객체에 대한 레퍼런스를 가지고 있지 않다는 말과 같습니다.
질문
크롬 브라우저 및 node.js의 v8 엔진은, 어떻게 가비지 컬렉팅을 하고 있나요?
Memory terminology를 읽어보세요.
캐시
1.캐시란?
많은 시간이나 연산이 필요한 작업의 결과를 저장해두는 것
컴퓨팅에서 캐시는 일반적으로 일시적인(temporarily) 데이터를 저장하기 위한 목적으로 존재하는 고속의 데이터 저장 공간
같은 작업을 또 해야할 때는 저장해두고 접근만 하면 됨!
-> 첫 작업 이후에 이 데이터에 대한 요청이 있을 경우,
데이터의 기본 저장 공간에 접근할 때보다 더 빠르게 요청 처리 가능
-> 캐싱을 사용하면 이전에 검색하거나 계산한 데이터를 효율적으로 재사용 가능
2. 캐시의 일반적인 작동원리
캐시의 데이터
: 일반적으로 RAM(Random Access Memory)과 같이 빠르게 액세스할 수 있는 하드웨어에 저장
: 소프트웨어 구성 요소와 함께 사용 가능
느리게 엑세스하는 하드웨어
: 기본 스토리지 계층(SSD, HDD)
=> 여기에 액세스하여 데이터를 가져오는 더 느린 작업의 요구를 줄인다
+데이터 검색의 성능을 높입니다.
캐시는 속도를 위해 용량 절충
-> 일반적으로 데이터의 하위 집합을 일시적으로 저장합니다.
!== 완전하고 영구적인 데이터가 있는 데이터베이스
3. 캐시의 장점은 무엇인가요?
- 애플리케이션 성능 개선
- 데이터베이스 비용 절감
- 백엔드 부하 감소
- 예측 가능한 성능
- 데이터베이스 핫스팟 제거
- 읽기 처리량 증가
- 읽기 처리량: IOPS; Input/output operations per second. HDD, SSD 등의 컴퓨터 저장 장치의 성능 측정 단위
4. 웹서비스에서 캐시가 적용되는 예제
- 클라이언트: HTTP 캐시 헤더, 브라우저
- 네트워크: DNS 서버, HTTP 캐시 헤더, CDN, 리버스 프록시
- 서버 및 데이터베이스: 키-값 데이터 스토어(e.g. Redis), 로컬 캐시(인-메모리, 디스크)
Reference
https://aws.amazon.com/ko/caching/
