JDBC
DB에 접근하는 방법
클라이언트가 DB에 접근하는 방법
클라이언트는 서버를 통해 DB에 접근한다.
간단하게 그림으로 표현하자면 다음과 같은 형태일 것이다.
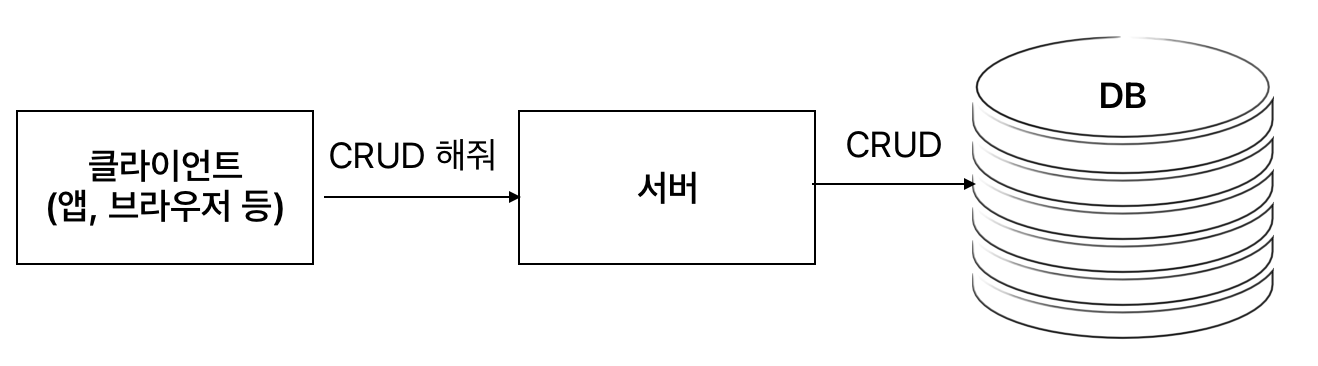
클라이언트에서 서버로 어떤 이벤트를 발생시켜 CRUD를 요청하면, 서버에서 DB에 접근하여 요청을 수행한다.
서버가 DB에 접근하는 방법
그렇다면 클라이언트와 DB의 중간다리역할을 하는 서버는 어떻게 작동할까? 역시 간단한 그림으로 보자면 다음과 같다.
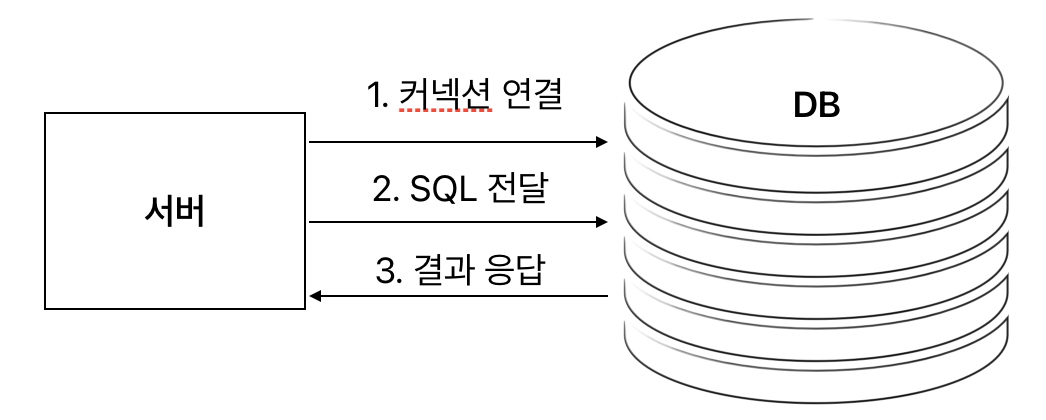
서버는 DB에 커넥션 연결을 시도한다. 그리고 SQL문을 사용하여 DB를 조작하고 그에 대한 응답을 DB로 부터 받게된다.
💡 서버와 DB 주로 TCP/IP를 사용해서 커넥션을 연결한다.
기존 방식의 문제점
현재 DBMS가 MySQL이라고 가정해보자.
그렇다면 서버에서 MySQL을 사용하기 위한 코드들을 사용하여 개발하였을 것이다. 그러다 만약 Oracle이나 PostgreSQL로 DBMS를 변경해야할 필요가 생겼다면...
끔찍하다. DB에 접근하는 MySQL 관련 모든 코드를 변경하고자 하는 DBMS의 코드로 변경해야할 것이다.
그럼 어떻게 해야하느냐? 이런 문제를 해결하기 위해 오늘의 주인공 JDBC가 등장했다.
JDBC 표준 인터페이스
JDBC(Java DataBase Connectivity)는 자바에서 데이터베이스에 접속할 수 있도록 도와주는 API이다.
서로 다른 DBMS여도 JDBC API에 구현체인 경우 호환이 가능하도록 해주는 인터페이스이다. 각각의 구현체들은 각 DBMS에 접근할 수 있도록 도와주는데, DBMS 회사에서 드라이버라는 이름으로 설치할 수 있다.
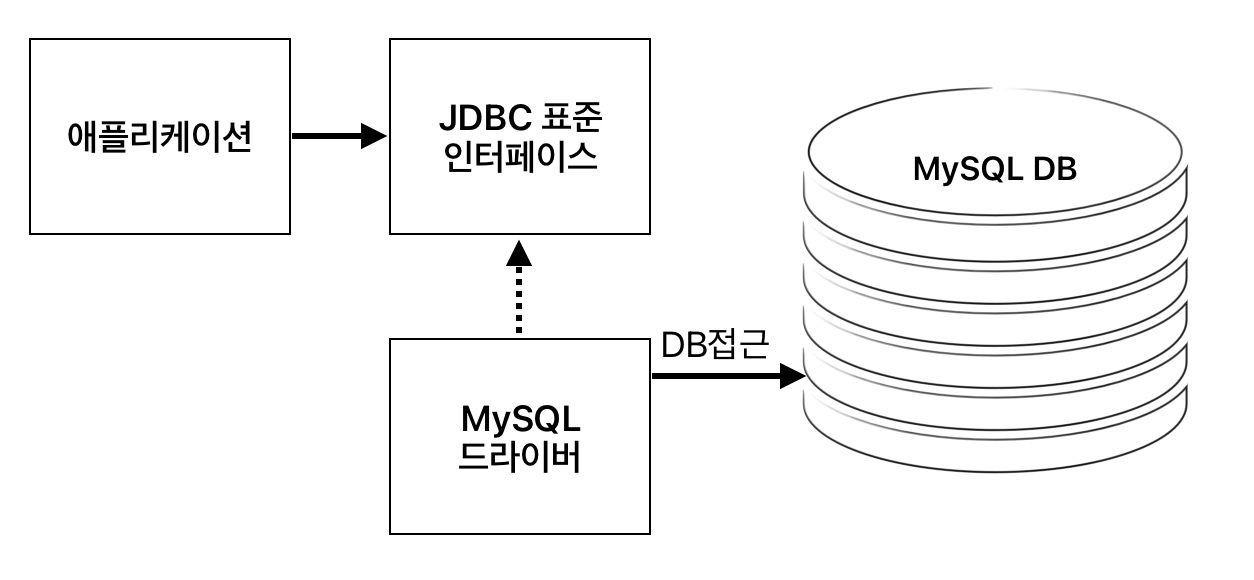
애플리케이션의 코드는 JDBC 표준 인터페이스를 의존하여 사용하지만 실제로는 그 구현체는 MySQL 드라이버가 DB에 접근한다.
Oracle이어도 마찬가지이다. 개발자는 JDBC 표준 인터페이스를 사용하면 DBMS가 변경되더라도 코드를 수정할 필요가 없다.
Connection Pool
기존 방식의 문제점
DB와 통신할 때마다 DB와 TCP/IP를 새로 연결하여 커넥션을 구하는 것은 매우 비효율적이다. 만약 백만명의 사용자가 DB에 접근하려고할 때 TCP/IP 3 way handshake가 백만번 일어나고 말도 안되는 성능저하가 발생할 것이다. 이러한 문제를 해결하기 위해 발생한 것이 Connection Pool이다.
Connection Pool이란?
직역하면 Connection의 수영장이다. Connection Pool은 여러 개의 Connection을 미리 만들어놓고 사용할 때 가져갔다가 사용 후 반환하여 TCP/IP 연결을 최소화하는 것이다. 만약 Connection Pool에 Connection이 10개있다면, 11번의 커넥션 연결 시 가장 최악이 아니라면 11번의 TCP/IP 연결은 필요없을 것이다. Connection Pool이 없다면 커넥션이 필요할 때마다 새로 연결해야하기 때문에 무조건 11번의 통신이 발생한다.
Connection Pool의 초기화
커넥션 풀은 애플리케이션을 시작하는 시점에 필요한 만큼 확보한다. 필요한 커넥션의 개수는 개발자가 직접 지정할 수 있는데, 기본값은 보통 10개이다.
Connection Pool의 연결 상태
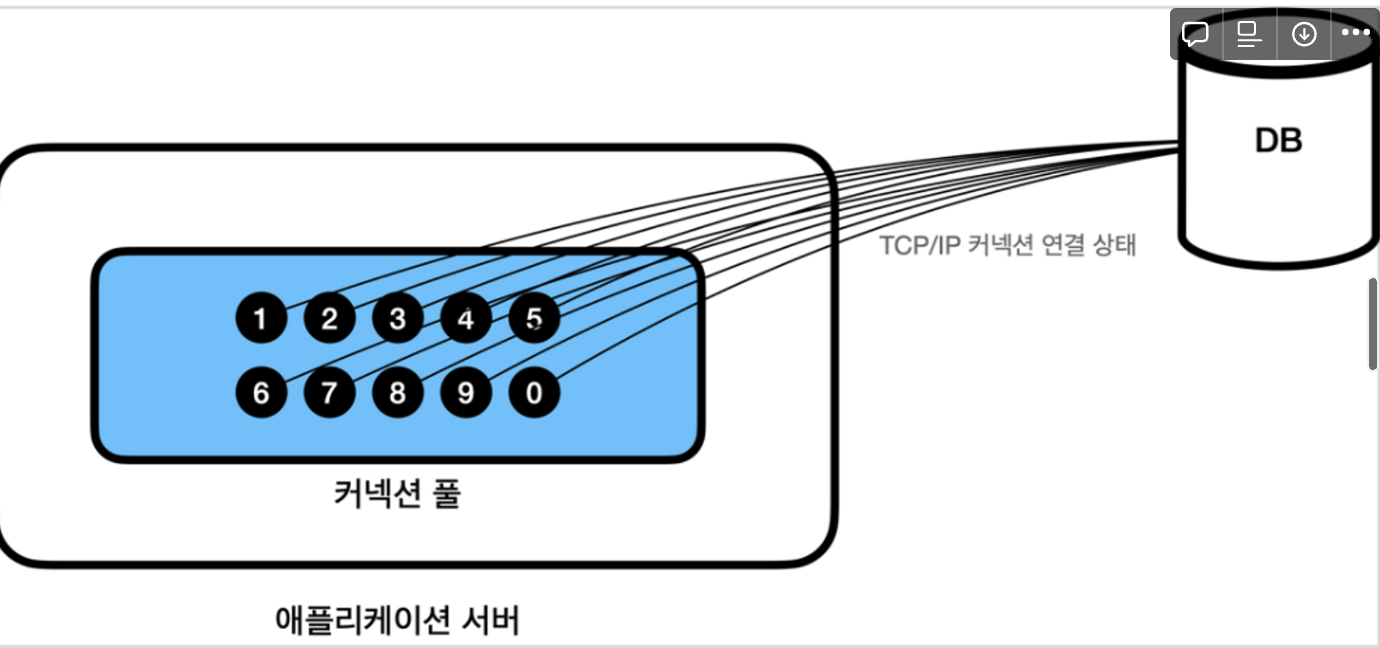 (출처: 김영한의 스프링 DB 접근-1)
(출처: 김영한의 스프링 DB 접근-1)
커넥션은 위의 그림과 같이 각각 DB와 TCP/IP로 연결되어있다. 즉, 언제든 각각의 커넥션이 DB와 통신할 수 있다는 뜻이다.
DB 세션
DB에 커넥션이 연결되면 세션이 하나 생긴다. DB 세션은 DB 사용자와 비슷한 개념이다. 일반적으로 한 세션은 하나의 트랜잭션을 가진다.
DataSource
커넥션을 얻는 방법은 다양하다. 커넥션 풀을 사용하지 않고, DriverManager를 통해 하나씩 생성하는 방법도 있고 커넥션 풀을 사용하는 방법도 있다. 커넥션 풀에도 Hikari CP, DBCP2 등 여러가지다. 만약 DriverManager를 사용해 커넥션을 사용하다가 Hikari CP를 사용하고 싶다면 코드를 모두 바꿔야할 것이다. 이러한 문제를 해결하기위해 DataSource 인터페이스가 등장한다.
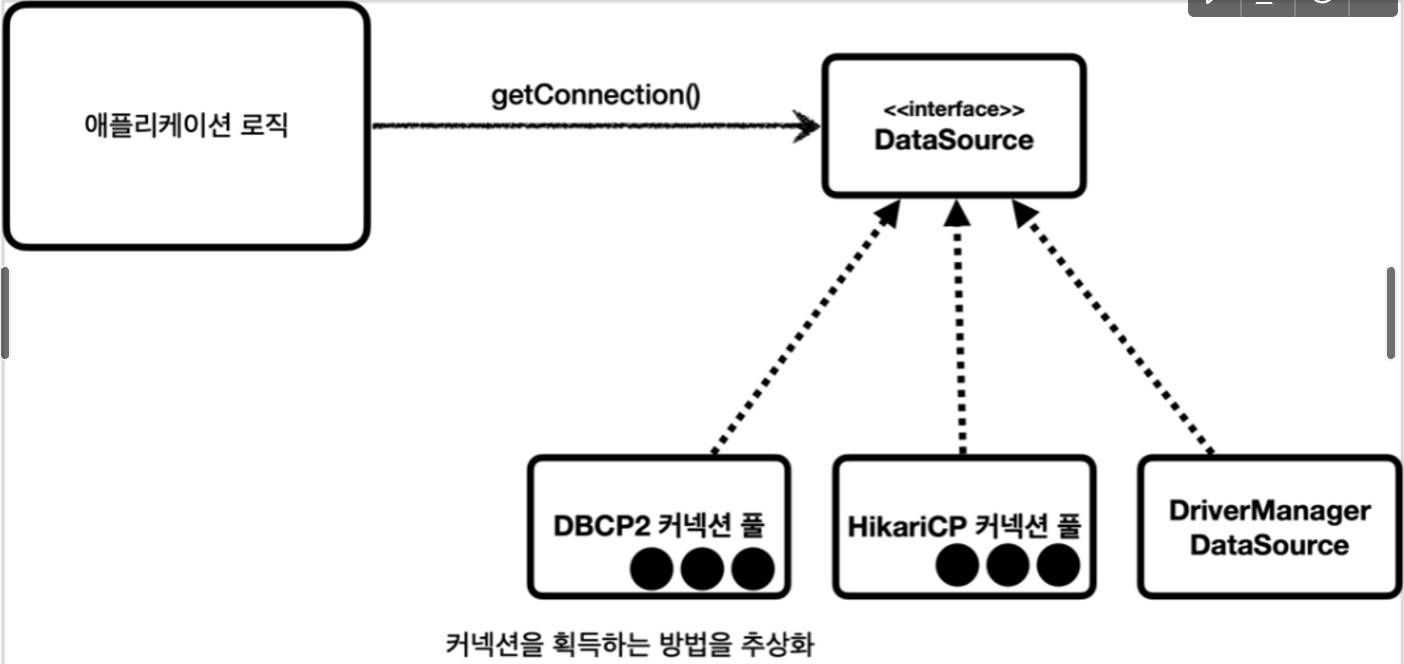
커넥션을 얻는 방법을 getConnection() 메서드로 추상화한 인터페이스이다. 어떤 방법으로 구현하든 getConnection()만 잘 사용하면 커넥션을 얻을 수 있다.
