< 해시? >
해시란 데이터를 다루는 기법 중에 하나로 검색과 저장이 아주 빠르게 진행된다. 데이터를 검색할 때 사용할 Key와 실제 데이터의 값(Value)이 한 쌍으로 존재하고, Key값이 배열의 인덱스로 변환되기 때문에 검색과 저장의 평균적인 시간 복잡도가 O(1)에 수렴하게 된다.
즉 데이터를 효율적으로 관리하기 위해, 임의의 길이 데이터를 고정된 길이의 데이터로 매핑하는 것
해시 함수(키값을 인덱스로 보낸다)를 구현하여 데이터 값을 해시 값으로 매핑한다.
즉, 해시 = 키에 대응되는 값을 저장하는 자료구조
< 특징 >
- insert, update, erase, find 가 모두 O(1)의 시간복잡도를 가진다
- 단, 충돌이 없는 상황에서..!
< 충돌 >
- 서로 다른 2개의 입력값을 넘겼는데 같은 출력값이 오는 경우
- 서로 다른 키가 같은 해시값을 가지는 경우!!!
< 충돌 해결 - 1.Chaining >
- 각 인덱스마다 연결리스트를 하나씩 둔다
- 실제 STL의 해시 자료구조 또한 Chaining 사용
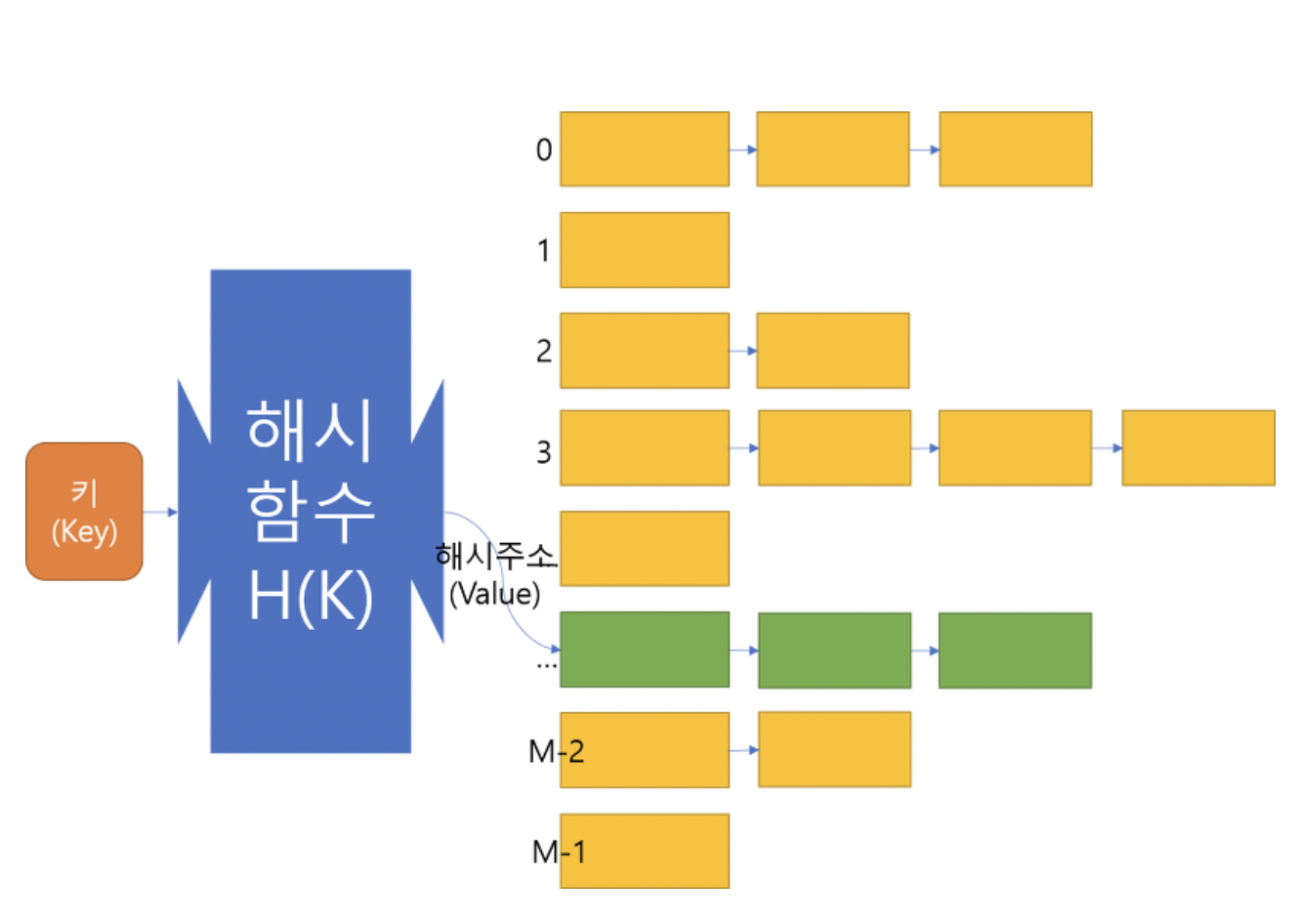
(출처 : https://twinparadox.tistory.com/518)
- 모든 키의 해시 값이 같은 최악의 상황에서는 O(N)의 시간 복잡도
< 충돌 해결 - 2.Open Addressing >
- 충돌 발생 시 다른 공간 탐색(Probing)
< Linear Probing >
- 해싱한 뒤 해당 슬롯에 이미 데이터가 있는 경우에 다음 슬롯을 확인하는 것으로 가장 빨리 찾은 빈 슬롯에 데이터를 저장하는 방법
- 장점 : Cache hit rate가 높다
- 단점 : Clustering이 생겨 성능에 영향을 줄 수 있다
< Quadratic Probing >
- 충돌이 발생하는 경우 다음 Slot을 1^2 -> 2^2 -> 3^2 등으로 증가하며 찾는 방법이다
- 장점 : Clustering 을 어느 정도 회피할 수 있다
- 단점 : 해시 값이 같을 경우 여전히 Clutering 발생 가능
< Double Hashing >
- 충돌 발생 시 이동할 칸의 수를 새로 해시 함수로 계산하는 방법
- 장점 : Clustering을 효과적으로 피할 수 있다
- 단점 : Cache hit rate 가 낮다
< STL unordered_set >
- <unordered_set> 헤더
#include <string>
#include <vector>
#include <unordered_set>
#include <iostream>
using namespace std;
int main() {
unordered_set<int> us;
us.insert(1); // 삽입
us.insert(2);
us.insert(3);
us.insert(4);
us.insert(5);
us.insert(6);
// 순회1
unordered_set<int>::iterator iter;
for(iter = us.begin(); iter != us.end(); iter++) {
cout << *iter << "\n";
}
cout << "/////\n";
cout << us.size() << "\n"; // 6 출력
us.insert(1);
cout << us.size() << "\n"; // 6 출력
cout << us.erase(2) << "\n"; // 1 출력, 2는 set에 들어있었으므로 지운 후 1 출력
cout << us.erase(7) << "\n"; // 0 출력, 7는 set에 들어있지 않았으므로 0 출력
// find : 값을 찾고 iterator 반환, 값이 없다면 end() 반환
if(us.find(3) != us.end()) {
cout << "find 3\n";
}
if(us.find(2) == us.end()) {
cout << "2 already erased\n";
}
cout << us.count(1) << "\n";
// count : 해당 원소 몇개인지 -> 중복허용 없으므로 사실상 0 아니면 1
// 순회2
cout << "/////\n";
for(auto it : us) { // range-based for loop
cout << it << "\n";
}
return 0;
}< STL unordered_multiset>
- <unordered_set> 헤더
- 중복허용
#include <string>
#include <vector>
#include <unordered_set>
#include <iostream>
using namespace std;
int main() {
unordered_multiset<int> ms;
ms.insert(-10);
ms.insert(100);
ms.insert(15); // {-10, 100, 15}
ms.insert(-10);
ms.insert(15); // {-10, -10, 100, 15, 15}
cout << ms.size() << '\n'; // 5
for (auto e : ms)
cout << e << ' ';
cout << '\n';
cout << ms.erase(15) << '\n'; // {-10, -10, 100}, 2 / 15가 여러 개 존재하면 모두 지워진다
ms.erase(ms.find(-10)); // {-10, 100} // 하나만 지우고 싶은 경우 iterator 전달
ms.insert(100); // {-10, 100, 100}
cout << ms.count(100) << '\n'; // 2
return 0;
}< 참고링크 >
https://yang-droid.tistory.com/45

매 순간 최선을 다하자