
문제
방향성이 없는 그래프 가 주어진다. 문제는 의 최소 스패닝 트리보다는 크면서 가장 작은 스패닝 트리인 'The second minimum spanning tree'를 구하는 것이다.
입력
첫째 줄에 그래프의 정점의 수 와 간선의 수 가 들어온다.
둘째 줄부터 번째 줄까지 한 간선으로 연결된 두 정점과 그 간선의 가중치가 주어진다.
가중치는 100,000보다 작거나 같은 자연수 또는 0이고, 답은 을 넘지 않는다.
정점 번호는 1보다 크거나 같고, 보다 작거나 같은 자연수이다.
출력
두 번째로 작은 스패닝 트리의 값을 출력한다.
만약 스패닝 트리나 두 번째로 작은 스패닝 트리가 존재하지 않는다면 -1을 출력한다.
알고리즘 분류
- 그래프 이론
- 자료 구조
- 트리
- 최소 스패닝 트리
- 최소 공통 조상
- 희소 배열
풀이
최소 스패닝 트리라면 크루스칼 알고리즘만 쓰면 끝나는데 두 번째로 작은 스패닝 트리를 구하려 하니 참 어려워진다.
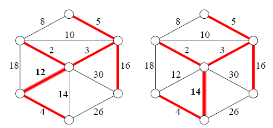
일단 최소 스패닝 트리는 쉽게 구할 수 있으니 먼저 구해보자. 최소 스패닝 트리와 두 번째로 작은 스패닝 트리가 포함하는 간선 집합은 큰 차이가 없다는 걸 짐작할 수 있다. 최소 스패닝 트리를 적절하게 변형하여 두 번째로 작은 스패닝 트리를 만드는 방향으로 접근해보자.
최소 스패닝 트리를 변형하여 두 번째로 작은 스패닝트리를 만들려면 어떻게 해야 될까? 우선 트리의 가중치 합을 늘리기 위해, 최소 스패닝 트리에 없던 간선을 하나 추가해야된다. 그러면 트리의 간선 개수가 V개가 되어버리니, 최소 스패닝 트리에 존재하는 간선 하나를 제거해야된다. 스패닝 트리의 간선 개수는 V-1개가 되어야 한다는 정의를 기억하자.
그리고 간선을 2개 이상 추가하거나 제거할 필요는 없다. 두 번째로 작은 스패닝트리를 구하기 위해서는 최소 스패닝 트리에 간선을 1개 추가하고 1개 제거하면 충분하다.
그러면, 최소 스패닝 트리에 간선을 아무거나 한번 추가해보자. 그래프의 모든 간선을 돌아가며 단순하게 한번씩 추가해보면서 두 번째로 작은 스패닝 트리를 찾아가면 된다. 이 과정에서 최소 스패닝 트리에 어떤 간선을 추가할 때 제거해야 되는 간선을 찾아야 한다. 그건 스패닝 트리라는 조건을 생각해보면 알아낼 수 있다.
예를 들어 정점 X와 Y를 잇는 간선을 최소 스패닝 트리에 추가하면, X에서 Y로 가는 경로가 하나 생긴다. 그런데 스패닝 트리의 정의에 따르면, X에서 Y로 가는 경로가 기존에도 존재하고 있을 것이다.
따라서 X에서 Y로 가는 경로가 여러 개 생긴 것인데, 트리의 정의에 따라 X에서 Y로 가는 경로는 유일하게 하나만 있어야 한다. 그러므로 스패닝 트리에서 기존에 존재하던 경로 중 간선 하나를 제거하여 경로를 없애야 한다.
근데 우리는 두 번째로 작은 스패닝 트리를 찾고 있으니까, 경로에서 가장 가중치가 큰 간선을 제거하면 된다. X에서 Y로 가는 경로에서 가장 가중치가 큰 간선을 빠르게 구하는 알고리즘은? LCA를 활용하는 기본 문제가 된다.
이렇게 풀이가 끝나면 좋은데.. 하나 더 고려할게 있다. 가장 가중치가 큰 간선을 제거하는 것이 일반적으로 맞지만, 특수 케이스 처리를 위해 가중치가 2번째로 큰 간선도 한번 제거해봐야 한다. 문제에서 요구하는 두 번째로 작은 스패닝 트리는 최소 스패닝 트리보다 strict하게 커야 된다는 조건이 있기 때문이다.
예를 들어 X와 Y를 잇는 가중치 5의 간선을 트리에 추가했을때, 트리의 X에서 Y로 가는 기존 경로에서 제거할 가장 가중치가 큰 간선의 가중치가 똑같이 5일 수도 있다. 이렇게 가중치가 동일한 간선을 추가하고 제거하면 두 번째로 작은 스패닝 트리가 아니라 그냥 최소 스패닝 트리를 구하게 된다. 최소 스패닝 트리가 여러 개 존재하는 경우일 것이다.
그러므로 가중치가 2번째로 큰 간선도 꼭 제거해보자! 그래야 진짜로 두 번째로 작은 스패닝 트리를 구할 수 있다. 정답률을 낮추는 주범이다.
코드
먼저 직접 구현을 시도해보고, 코드를 참고하는걸 권장합니다.
#include <bits/stdc++.h>
using namespace std;
int V, E;
vector<pair<int, int>> link[100005];
int parent[100005][31];
int lcaKeyValue[100005][31];
int lcaKeyValue2[100005][31];
int height[100005];
bool visited[100005];
vector<pair<int, int>> linkTree[100005];
int disjointSet[100005];
vector<pair<pair<int, int>, int>> minSpanningTreeLink;
vector<pair<pair<int, int>, int>> notIncludedLink;
long long minSpanningTreeValue;
int Find(int i) {
if (disjointSet[i])
return (disjointSet[i] = Find(disjointSet[i]));
else
return i;
}
void Union(int i, int j) {
int si = Find(i), sj = Find(j);
if (si == sj) return;
disjointSet[si] = sj;
}
void DFS(int start) {
visited[start] = true;
for (auto i : linkTree[start]) {
if (!visited[i.first]) {
parent[i.first][0] = start;
height[i.first] = height[start] + 1;
lcaKeyValue[i.first][0] = i.second;
lcaKeyValue2[i.first][0] = i.second;
DFS(i.first);
}
}
}
pair<int, int> LCA(int a, int b) {
set<int, greater<int>> answerSet;
if (height[a] > height[b]) swap(a, b);
for (int i = 30; i >= 0; i--) {
if (height[b] - height[a] >= 1 << i) {
answerSet.insert(lcaKeyValue[b][i]);
answerSet.insert(lcaKeyValue2[b][i]);
b = parent[b][i];
}
}
if (a == b) {
int fi = *answerSet.begin(), se = *answerSet.begin();
answerSet.erase(*answerSet.begin());
if (!answerSet.empty()) se = *answerSet.begin();
return {fi,se};
}
for (int i = 30; i >= 0; i--) {
if (parent[a][i] != parent[b][i]) {
answerSet.insert(lcaKeyValue[a][i]);
answerSet.insert(lcaKeyValue2[a][i]);
answerSet.insert(lcaKeyValue[b][i]);
answerSet.insert(lcaKeyValue2[b][i]);
a = parent[a][i];
b = parent[b][i];
}
}
answerSet.insert(lcaKeyValue[a][0]);
answerSet.insert(lcaKeyValue2[a][0]);
answerSet.insert(lcaKeyValue[b][0]);
answerSet.insert(lcaKeyValue2[b][0]);
int fi = *answerSet.begin(), se = *answerSet.begin();
answerSet.erase(*answerSet.begin());
if (!answerSet.empty()) se = *answerSet.begin();
return {fi,se};
}
int main() {
ios_base::sync_with_stdio(false); cin.tie(nullptr);
cin >> V >> E;
if (V == 1)
return cout << -1, 0;
priority_queue<
pair<int, pair<int, int>>,
vector<pair<int, pair<int, int>>>,
greater<pair<int, pair<int, int>>>
> pq;
for (int i = 0; i < E; i++) {
int a, b, w;
cin >> a >> b >> w;
if (a == b) continue;
link[a].push_back({b,w});
link[b].push_back({a,w});
pq.push({w,{a,b}});
}
while (!pq.empty()) {
pair<int, pair<int, int>> x = pq.top(); pq.pop();
if (Find(x.second.first) != Find(x.second.second)) {
Union(x.second.first, x.second.second);
minSpanningTreeLink.push_back({x.second, x.first});
linkTree[x.second.first].push_back({x.second.second, x.first});
linkTree[x.second.second].push_back({x.second.first, x.first});
minSpanningTreeValue += x.first;
}
else {
notIncludedLink.push_back({x.second, x.first});
}
}
if (minSpanningTreeLink.size() < V - 1) {
return cout << -1, 0;
}
DFS(1);
for (int i = 1; i <= 30; i++) {
for (int j = 1; j <= V; j++) {
parent[j][i] = parent[parent[j][i - 1]][i - 1];
lcaKeyValue[j][i] = max(
lcaKeyValue[j][i - 1],
lcaKeyValue[parent[j][i - 1]][i - 1]
);
set<int, greater<int>> tmp;
tmp.insert(lcaKeyValue[j][i - 1]);
tmp.insert(lcaKeyValue[parent[j][i - 1]][i - 1]);
tmp.insert(lcaKeyValue2[j][i - 1]);
tmp.insert(lcaKeyValue2[parent[j][i - 1]][i - 1]);
if (tmp.size() == 1) {
lcaKeyValue2[j][i] = *tmp.begin();
}
else {
tmp.erase(*tmp.begin());
lcaKeyValue2[j][i] = *tmp.begin();
}
}
}
long long ans = LLONG_MAX;
for (auto i : notIncludedLink) {
pair<int, int> lcaResult = LCA(i.first.first, i.first.second);
long long tmpAns = minSpanningTreeValue + i.second;
if (tmpAns - lcaResult.first > minSpanningTreeValue) {
ans = min(ans, tmpAns - lcaResult.first);
}
else if (tmpAns - lcaResult.second > minSpanningTreeValue) {
ans = min(ans, tmpAns - lcaResult.second);
}
}
if (ans == minSpanningTreeValue || ans == LLONG_MAX) cout << -1;
else cout << ans;
}