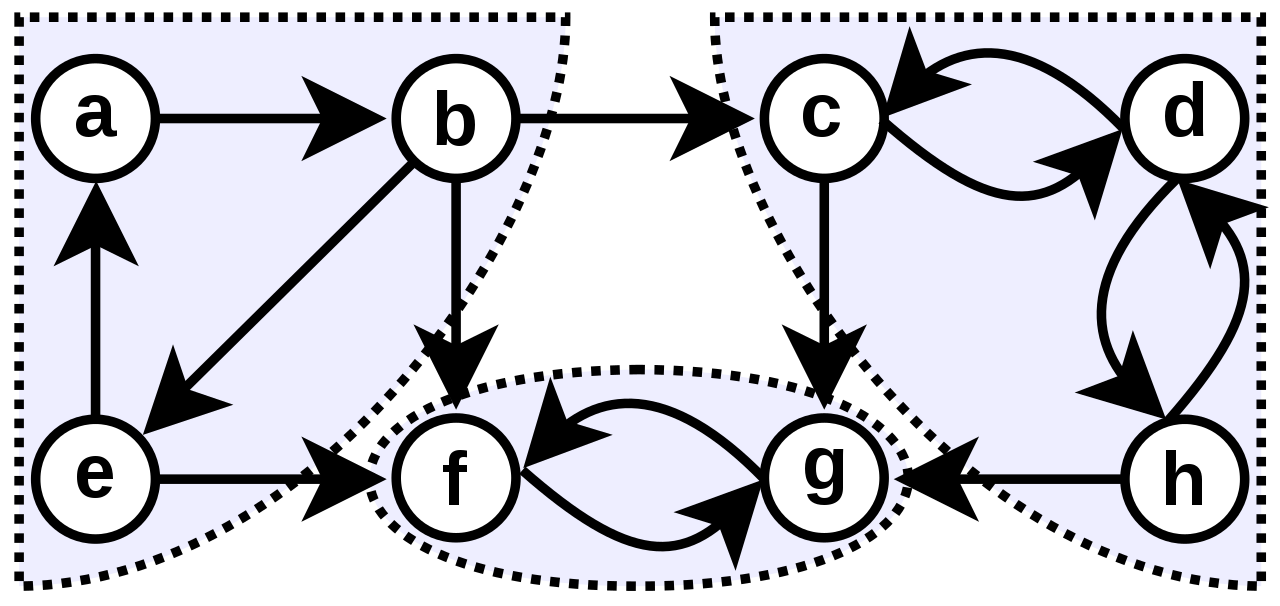
설명
강한 연결 요소(Strongly Connected Component, SCC)는 유향 그래프가 주어졌을 때, 그래프의 노드들 중에서 다른 모든 노드로 이동이 가능한 노드들의 집합을 뜻한다. 즉, 그래프 내의 집합에서 임의의 두 점을 골랐을 때, 그 두 점 사이의 경로가 항상 존재하면 이 집합을 강한 연결 요소라고 한다.
정의에 따라, 임의의 유향 그래프가 주어졌을 때 다음과 같이 여러 개의 강한 연결 요소로 나눌 수 있다.
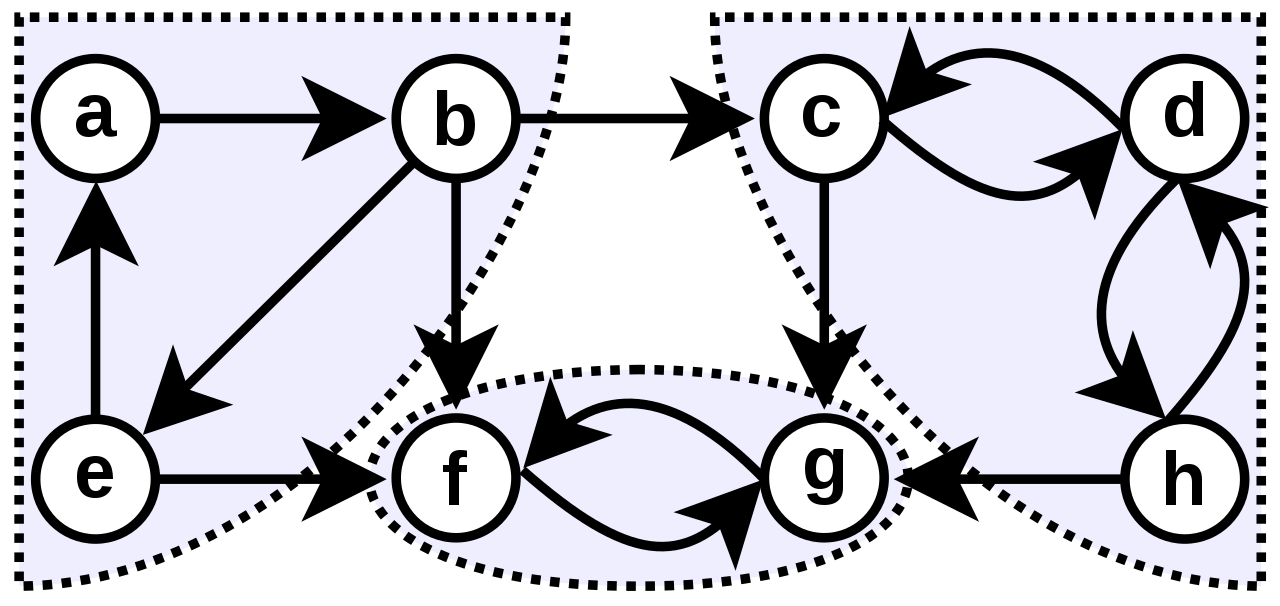
임의의 그래프 내에서 강한 연결 요소를 찾아 분류하는 효율적인 알고리즘이 몇 가지 존재하는데, 여기서는 코사라주 알고리즘(Kosaraju's Algorithm)과 타잔 알고리즘(Tarjan's Algorithm)을 다룬다.
코사라주 알고리즘
코사라주 알고리즘(Kosaraju's Algorithm)은 주어진 그래프를 정방향으로 한번 DFS 탐색 후, 역방향으로 한번 더 DFS 탐색을 하며 SCC를 찾아간다. 이에 대해 구체적인 구현 방식은 레퍼런스별로 차이가 있지만, 여기서는 영문판 위키피디아 항목에 제시된 알고리즘 구현 방식을 소개한다.
- 주어진 그래프의 정점들에 대한 변수를 선언하고, 스택 을 선언한다.
- 그래프의 각각의 정점들 대해 를 실행한다. 는 다음과 같이 정의된다.
- 정점 가 아직 되어있지 않다면,
1) 를 처리한다.
2) 에서 이어지는 각각의 인접 정점 v에 대해 를 시행한다.
3) 에 를 push한다.- 실행 후, 에 들어있는 정점 에 대해 순서대로 pop하면서 를 실행한다. 함수는 다음과 같이 정의된다.
- 아직 가 SCC에 속해있지 않는 경우,
1) 기준점이 인 SCC에 를 넣는다.
2) 에서 이어지는 각각의 인접 정점 에 대해 를 실행한다.
여기서 함수는 정방향 DFS 탐색, 함수는 역방향 DFS 탐색에 대응된다. 즉, 먼저 DFS 탐색을 통해 SCC 체크를 할 노드 순서를 에 저장하고, 그 다음 함수를 통해 에서 노드를 순차적으로 꺼내면서 SCC를 만들어 나가는 알고리즘이다.
이 때, 를 통해 역방향 DFS 탐색으로 처리되는 노드의 집합은 SCC가 됨이 수학적으로 증명이 되어 있다.
위 알고리즘의 시간복잡도는 이다.
위 알고리즘을 파이썬 코드로 구현하면 다음과 같다. (출처 : Rosetta Code)
def kosaraju(g):
size = len(g)
vis = [False] * size
l = [0] * size
x = size
t = [[] for _ in range(size)]
def visit(u):
nonlocal x
if not vis[u]:
vis[u] = True
for v in g[u]:
visit(v)
t[v].append(u)
x -= 1
l[x] = u
for u in range(size):
visit(u)
c = [0] * size
def assign(u, root):
if vis[u]:
vis[u] = False
c[u] = root
for v in t[u]:
assign(v, root)
for u in l:
assign(u, u)
return c
g = [[1], [2], [0], [1, 2, 4], [3, 5], [2, 6], [5], [4, 6, 7]]
print(kosaraju(g))타잔 알고리즘
타잔 알고리즘(Tarjan's Algorithm)은 한 번의 DFS 탐색을 통해 구현된다. 여기서도 영문 위키피디아 페이지에 소개된 구현 방식을 다룬다.
- 주어진 그래프의 각각의 정점 에 대해, DFS 탐색 순서 번호를 붙일 변수 와 , 탐색 과정에서 사용할 스택 를 선언한다.
- 그래프의 각각의 정점 에 대해, 에 가 붙어있지 않다면, 함수 를 실행한다. 는 다음과 같이 정의된다.
- 를 에 push한다.
- 의 인접 노드들 에 대해,
1) 만약 에 가 붙어있지 않다면 를 실행 후, 의 값을 로 지정한다.
2) 그 외에, 가 내에 존재하지 않을 시, 이는 이미 SCC 처리 되어있음을 의미하므로 의 값만 로 갱신한다.- 위 재귀 탐색 후, 에서 정점을 pop하면서 SCC를 만들어 나간다.
1) 만약 의 와 값이 같을 때,에서 노드 를 계속 뽑으면서 와 가 같아질 때까지 SCC로 묶어서 처리한다.
타잔 알고리즘의 기본적인 아이디어는, DFS 탐색을 하면서 각각의 노드에 탐색한 순서를 붙이면서 스택에 넣는데, 이 과정에서 이미 탐색이 된 노드 and 아직 SCC로 결정이 되지 않은 노드를 발견 시 그 노드가 나올 때까지 스택에서 pop을 하며 SCC 처리를 하는 것이다. 주의할 점은, 이 과정에서 DFS 탐색 자체를 해당 지점까지 거슬러 올라가는 것은 아니다.
구현 난이도는 타잔 알고리즘 쪽이 조금 더 높고 직관적이지 않지만, 실제 알고리즘 문제를 풀 때에는 타잔 알고리즘이 자주 이용되는 편이다.
위 알고리즘의 시간복잡도는 코사라주 알고리즘과 마찬가지로 이다.
위 알고리즘을 파이썬 코드로 구현하면 다음과 같다. (출처 : Rosetta Code)
from collections import defaultdict
def from_edges(edges):
'''translate list of edges to list of nodes'''
class Node:
def __init__(self):
# root is one of:
# None: not yet visited
# -1: already processed
# non-negative integer: what Wikipedia pseudo code calls 'lowlink'
self.root = None
self.succ = []
nodes = defaultdict(Node)
for v,w in edges:
nodes[v].succ.append(nodes[w])
for i,v in nodes.items(): # name the nodes for final output
v.id = i
return nodes.values()
def trajan(V):
def strongconnect(v, S):
v.root = pos = len(S)
S.append(v)
for w in v.succ:
if w.root is None: # not yet visited
yield from strongconnect(w, S)
if w.root >= 0: # still on stack
v.root = min(v.root, w.root)
if v.root == pos: # v is the root, return everything above
res, S[pos:] = S[pos:], []
for w in res:
w.root = -1
yield [r.id for r in res]
for v in V:
if v.root is None:
yield from strongconnect(v, [])
tables = [ # table 1
[(1,2), (3,1), (3,6), (6,7), (7,6), (2,3), (4,2),
(4,3), (4,5), (5,6), (5,4), (8,5), (8,7), (8,6)],
# table 2
[('A', 'B'), ('B', 'C'), ('C', 'A'), ('A', 'Other')]]
for table in (tables):
for g in trajan(from_edges(table)):
print(g)
print()