10. equals는 일반 규약을 지켜 재정의하라.
본문에 앞서 객체 식별성과 논리적 동치성에 대해 알아보자.
객체 식별성: 두 객체가 물리적으로 같은지
논리적 동치성: 두 객체가 논리적으로 같은지
간단한 예시를 통해 자세히 알아보자.
Integer a = 10;
Integer b = 10;두 인스턴스는 각자 다른 메모리에 할당된 명백히 물리적으로 다른 객체다. 즉, 객체 식별성을 만족하지 않는다.
반면에 저장된 값은 둘 다 10으로 논리적으로 동등하다.
equals 메서드는 객체의 동등성을 판단하기 위한 메서드로, Object 클래스에서 제공된다.
따라서 equals()를 오버라이딩하여 개발자의 의도대로 동등성을 제어할 수 있지만, 잘못 구현한다면 HashSet, HashMap 등의 자료 구조에서 의도와 다르게 작동될 수 있다.
이러한 문제를 회피하는 가장 간단한 방법은 equals()를 오버라이딩하지 않는 것이다.
아래와 같은 상황이라면, equals()를 오버라이딩 하지 않도록 하자.
각 인스턴스가 본질적으로 고유하다.
인스턴스의 값을 표현하기보다 동작하는 개체를 표현하는 클래스일 경우.
Thread클래스가 이러한 사례.인스턴스의 논리적 동치성을 검사할 일이 없다.
두 인스턴스간의 동등성을 검사할 필요가 없다면 오버라이딩 하지 않는다.
상위 클래스에서 오버라이딩한
equals가 하위 클래스에서 사용 가능하다.예시로
Set구현체는AbstractSet이 구현한equals()를 상속받아 사용한다.클래스가 private이거나 package-private이고, equals 메서드를 호출할 일이 없다.
equals()가 호출되는것을 막고 싶다면 호출시 런타임에러를 발생시키는것도 좋은 방법이다.
equals()의 오버라이딩이 필요한 때는 아래와 같다.
논리적 동치성을 확인해야 할 필요가 있지만 상위 클래스에서
equals()가 논리적 동치성을 비교하도록 재정의되지 않았을 때
또한, equals()를 오버라이딩할 때 반드시 아래 규약들을 지켜야 한다.
반사성:null이 아닌 모든 참조값x에 대해x.equals(x)는true다.
대칭성:null이 아닌 모든 참조값x,y에 대해x.equals(y)가true면y.equals(x)도true다.
추이성:null이 아닌 모든 참조값x,y,z에 대해x.equals(y)가true이고y.equals(z)도true라면z.equals(x)도true다.
일관성:null이 아닌 모든 참조값x,y에 대해x.equals(y)를 반복해서 호출한다면 항상true만을 반환하거나 항상false만을 반환한다. 즉,equals의 판단에 신뢰할 수 없는 자원이 끼어들면 안된다.
null-아님:null이 아닌 모든 참조값x에 대해x.equals(null)은false다.
종합적으로 equals() 메서드를 만드는 순서는 아래와 같다.
==연산자를 이용해 입력이 자기 자신의 참조인지 확인한다.특별한 의미를 갖는다기 보다는 후술할 프로세스가 복잡할 경우의 성능 최적화를 돕는다.
instanace of 연산자로 입력이 올바른 타입인지 확인한다.
보통의 경우에는
equals()가 작성되는 클래스와 일치하는지 확인하지만, 한 인터페이스를 구현한 서로 다른 클래스간 비교를 원한다면 해당 인터페이스와 비교해주면 된다.입력을 올바른 타입으로 형변환한다.
입력 객체와 자기 자신의 대응되는 핵심 필드들이 모두 일치하는지 하나씩 검사한다.
아래는 Integer 클래스의 equals() 메서드다.
public boolean equals(Object obj) {
if (obj instanceof Integer) {
return value == ((Integer)obj).intValue();
}
return false;
}타입 확인 > 형변환 > 값 비교의 세 단계를 거침을 알 수 있다.
프로세스가 간단해서인지 참조 확인은 스킵된 모양이다.
마지막으로 주의사항이다.
null을 정상 값으로 취급하는 참조 타입 필드가 있을 수 있다.
Obejct.equals(Object, Object)메서드를 이용하여NPE를 예방할 수 있다.아주 복잡한 필드를 가진 클래스
해당 필드의 표준형을 저장해둔 후 표준형끼리 비교한다면 경제적이다. 특히 불변 클래스일 때 효과적이다.
필드 비교 순서가 성능에 영향을 끼칠 수 있다.
다를 가능성이 크거나 비교하는 비용이 싼 필드를 먼저 비교하자.
equals()를 구현했다면 대칭성, 추이성, 일관성을 확인하자.
단위 테스트를 작성하여 직접 확인하는 것이 가장 바람직하다.
equals()를 재정의했다면 hashCode()도 재정의하자.
아이템 11에서 자세한 내용을 알아보자.Object 외의 타입을 매개변수로 받지 말자.
입력 타입이
Object가 아니라면equals()를 재정의한 게 아닌 다중정의한 것이다.
또한 작성자는 equals()와 hashCode()를 작성하고 테스트하는 도구로 구글의 AutoValue 프레임워크를 추천하기도 했다.
11. equals를 재정의하려거든 hashCode도 재정의하라.
equals를 재정의했지만 hashCode를 재정의하지 않는다면 hashCode 일반 규약을 어기게 되어 해당 클래스의 인스턴스를 HashMap, HashSet과 같은 컬렉션에서 사용한다면 문제가 발생할 수 있다.
아래는 Object 명세에서 발췌한 규약이다.
equals(Object)가 두 객체를 같다고 판단했다면, 두 객체의hashCode는 똑같은 값을 반환해야 한다.equals(Object)가 두 객체를 다르다고 판단했더라도, 두 객체의hashCode가 서로 다른 값을 반환할 필요는 없다. 단, 다른 객체에 대해서는 다른 값을 반환해야 해시 테이블의 성능이 좋아진다.
즉, 첫번째 규약에 의해 논리적 동치인 두 인스턴스는 반드시 같은 hashCode를 가져야 한다.
또한, 두번째 규약에 의해 모든 인스턴스에게 다른 hashCode를 반환하는 것이 적합하다. 서로 다른 인스턴스에게 32비트 정수 범위내의 hashCode를 균일하게 분배하는 것이 이상적이다.
아래는 hashCode()를 작성하는 간단한 요령이다.
int형 변수result를 선언한 후c로 초기화한다.
이 때,c는 객체 내의 첫 번째 핵심 필드를2단계를 통해 계산한 값이다.- 나머지 핵심 필드
f각각에 대해 아래 작업을 수행한다.
2.1. 기본 타입 필드라면,Type.hashCode(f)를 수행한다.
2.2. 참조 타입 필드면서 이 클래스의equals메서드가 필드의equals를 재귀적으로 호출한다면 해당 필드의hashCode를 호출한다.
2.3. 필드가 배열이라면, 원소 각각을 필드처럼 다뤄 각 핵심 원소의 해시코드를 계산한다.2단계에서 계산한 해시코드c로result를 갱신한다.result = 31 * result + c;result를 반환한다.
위와 같은 복잡한 방법이 싫다면, Objects.hash() 함수를 이용할 수 있다. 임의의 개수만큼 객체를 받아 해쉬코드를 계산해주지만, 속도는 느린 편이다.
12. toString()을 항상 재정의하라.
public class toString {
static class Pos {
int x, y;
Pos(int x, int y) {
this.x = x;
this.y = y;
}
}
public static void main(String[] args) {
Pos p = new Pos(1, 1);
System.out.println("p = " + p);
}
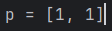
}위 코드는 좌표값을 나타내는 Pos 클래스를 생성하고 사용한다. 나는 디버깅을 위해서 p를 출력하고자 했지만, 그 결과는 아래와 같다.

이처럼 toString()을 재정의하지 않는다면 내가 원하는 정보가 아닌 {클래스}{이름}@{16진수 해시코드} 꼴의 문자열이 출력된다.
따라서 아래처럼 toString()을 재정의 해준다면 디버깅 및 사용하기에 더욱 편리하다.
static class Pos {
int x, y;
Pos(int x, int y) {
this.x = x;
this.y = y;
}
@Override
public String toString(){
return String.format("(%d, %d)", this.x, this.y);
}
}
toString()은 명시적으로 호출하지 않더라도 println(), 문자열 연결 연산자 등 묵시적으로 호출되는 경우도 많기 때문에 반드시 재정의하기를 권한다.
또한, 재정의 시 해당 객체가 가진 주요 정보를 모두 반환하는 것이 바람직하다. 추가로 toString() 재정의 시 포맷을 명확하게 문서화한다면 그 자체로 표준이 될 수 있다. 물론 포맷이 주어진다면 유연성은 그만큼 떨어질 수 있으니 주의하자.
13. clone 재정의는 주의해서 진행하라
Cloneable은 해당 클래스를 복제해도 됨을 나타내는 인터페이스다. 그렇다면 Cloneable의 구현체에 clone() 메서드를 재정의한다면 클래스를 복제할 수 있을 것이다. 아래는 Cloneable.java의 코드 전문이다.
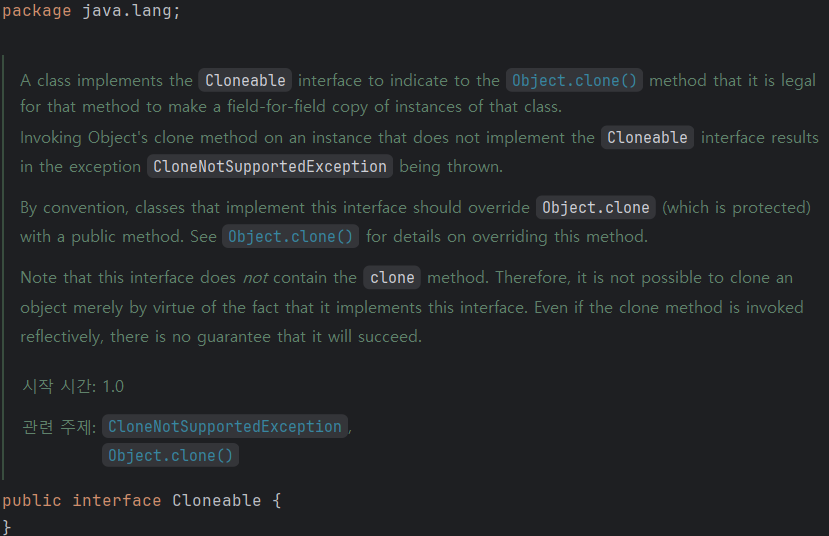
Cloneable 인터페이스에는 clone() 메서드가 없는 걸 확인할 수 있다. clone() 메서드는 사실 Cloneable이 아닌 Object에 protected 접근 제어자로 선언되어 있다.
clone()이 protected로 선언되어 있음에 유의하자. 그렇다면 clone()을 재정의하지 않은 채로 호출한다면 CloneNotSupportedException 예외가 발생할 것이다.
하지만 실제 개발 환경에서 사용자들은 Cloneable이 구현된 클래스에 clone()이 public으로 주어지며 완벽한 복사가 이루어지기를 기대할 것이다.
Object의 명세에는 clone()에 대한 규약이 서술되어 있다. 간단하게 설명한다면 임의의 객체 x와 그 복제 y는 아래와 같은 조건을 만족한다.
x != y이다. 즉, 두 객체는 독립적인 객체여야 한다.x.getClass() == y.getClass()이다.- 일반적으로
x.equals(y)는 참이다.
이 때, clone() 메서드에서 단순히 생성자를 호출한다고 해도 위의 세 조건을 모두 만족하며 컴파일러는 아무런 의심을 하지 못한다. 그렇다면 아래 상황을 가정해보자.
클래스 B는클래스 A를 상속하며, 각각Cloneable의 구현체이다.
클래스 B의clone()에서는super.clone(), 즉클래스 A의clone()을 호출한다. 그리고클래스 A의clone()에서는생성자를 호출하도록 구현하였다.그렇다면
클래스 B가clone()을 호출한 결과는A타입 객체가 반환될 것이다.
위는 명백히 개발자가 의도한 동작이 아니다. 이제 완벽한 clone()을 구현하기 위해 순차적으로 단계를 밟아 보자.
A. 완벽한 clone()이 구현된 상위 클래스를 상속받은 경우
@Override
public Node clone() {
try {
return (Node) super.clone();
} catch (CloneNotSupportedException e) {
throw new RuntimeException(e);
}
}Java의 공변 반환 타이핑에 의해 위 메서드는 정상 동작한다. super.clone()이 완벽히 구현되었다고 가정했으므로 CloneNotSupportedException이 던져질 가능성은 없지만, try-catch문으로 감싼 이유는 해당 예외가 CheckedException이기 때문이다.
B. 클래스가 가변 객체를 참조하는 경우
static class Stack {
int size;
int[] stack;
}위의 클래스에서 super.clone()을 호출한다면 기본형인 size는 문제없이 복제되겠지만, stack은 원본 객체와 복제된 객체가 같은 배열을 공유할 것이다.
stack 배열의 clone() 메서드를 재귀적으로 호출해준다면 쉽게 해결해낼 수 있다.
C. clone()의 재귀 호출만으로 복제가 이루어지지 않는 경우
static class Bucket {
Node[] nodeLinkedList;
}
static class Node {
int value;
Node nextNode;
}Bucket에는 연결 리스트를 원소로 갖는 배열이 존재하는데, 단순히 nodeLinkedList.clone() 따위의 재귀 호출로는 완전한 복제가 불가능하다.
따라서 복제 시에는 Node 클래스에 깊은 복사(Deep Copy)를 구현해 직접 복제하는 것이 바람직하다. 또한 단순한 반복문은 메모리 초과를 유발할 수 있으므로 반복자를 사용한 순회를 추천한다.
D. 복잡한 가변 객체를 복제하는 경우
C 단계에서와 같이 모든 필드를 초기화하고 원본 데이터를 완전히 복사하는 깊은 복사와 같은 고수준 API들을 사용한다면 간단하게 복제할 수 있지만, 다른 방법들에 비해 느리며 Cloneable 아키텍처가 지향하는 필드 단위 객체 복사를 만족하지 못한다.
위의 내용을 요약한다면 아래와 같다.
객체 복제 프로세스
Cloneable을 구현하는 모든 클래스는clone()을 재정의해야 한다. 이 때, 접근 제한자는public, 반환 타입은클래스 자신으로 설정해야 한다.- 재정의한
clone()은 가장 먼저super.clone()을 호출한 후 필요한 필드를 전부 적절히 수정한다. 이 때 필드에가변 객체가 있을 경우에는깊은 복사를 고려한다.
굉장히 복잡해 보이지만 다행히 대부분의 경우에는 복사 생성자와 복사 팩터리를 이용해도 족하다.
복사 생성자란 단순히 자신과 같은 클래스의 인스턴스를 인수로 받는 생성자를 의미한다. 복사 팩터리는 복사 생성자를 모방한 정적 팩터리를 가리킨다.
Comparable을 구현할지 고민하라.
static class Time implements Comparable<Time> {
int hour, minute, second;
Time(int hour, int minute, int second) {
this.hour = hour;
this.minute = minute;
this.second = second;
}
@Override
public int compareTo(Time t) {
if (this.hour != t.hour) return Integer.compare(this.hour, t.hour);
if (this.minute != t.minute) return Integer.compare(this.minute, t.minute);
return Integer.compare(this.second, t.second);
}
}Java로 알고리즘 문제를 푼다면 한 번쯤은 사용해봤을 Comparable이다. 내가 만든 Time 클래스는 compareTo를 재정의하여 우선순위를 설정해주었고, 이를 통해 수많은 제네릭 컬렉션과 알고리즘은 객체를 정렬하고 비교할 수 있다.
동일한 타입의 세 객체 x, y, z에 대해 compareTo의 규약은 아래와 같다.
sign(x.compareTo(y)) = -sign(y.compareTo(x))이다.sign(x.compareTo(y)) > 0 && sign(y.compareTo(z)) > 0이 참이라면sign(x.compareTo(z)) > 0도 반드시 참이다. 즉,추이성을 보장해야 한다.x.compareTo(y) == 0이 참이라면x.compareTo(z) == y.compareTo(z)도 반드시 참이다.(x.compareTo(y) == 0) == (x.equals(y))와 같이 구현함을 권장하며, 그렇지 않을 경우에는 그 사실을 명시해야 한다.
마지막 규약의 경우 필수는 아니지만 저자는 반드시 지키기를 권했다. 정렬된 컬렉션들은 equals가 아닌 compareTo를 이용해 동치성을 검사하기 때문에 두 메서드가 서로 다른 결과를 반환한다면 컬렉션간의 일관성을 해칠 수 있다.
필드끼리의 값을 비교할 때는 관계 연산자보다 기본 타입 클래스의 compare 메서드를 사용하는게 추천된다. 위의 예시 코드가 compare 메서드를 사용한 예시다.
또한, 클래스에 핵심 필드가 여러개라면 비교 순서에 따라 다른 결과가 나올 수 있으니 중요도에 따라 compareTo를 구현해줘야 한다. Java 8부터는 메서드 연쇄 방식으로 비교자를 생성할 수 있다. 위 코드를 메서드 연쇄 방식으로 고친다면 아래와 같다.
static class Time implements Comparable<Time> {
int hour, minute, second;
Time(int hour, int minute, int second) {
this.hour = hour;
this.minute = minute;
this.second = second;
}
private static final Comparator<Time> COMPARATOR =
comparingInt((Time t) -> t.hour)
.thenComparingInt(t -> t.minute)
.thenComparingInt(t -> t.second);
@Override
public int compareTo(Time t) {
return COMPARATOR.compare(this, t);
}
}훨씬 깔끔해졌지만 성능은 약간 느리다고 한다.
마지막으로 return this.num - o.num처럼 필드값끼리의 뺄셈을 그대로 반환하는 경우도 있는데, 언더플로우나 오버플로우 가능성도 있으며 성능도 거의 같다고 하니 Comparator나 compare 메서드를 사용하는게 바람직하다.
