현재 진행하는 프로젝트에서 x.com을 크롤링해야 하는 기능이 있었다.
하지만 크롤링을 공부하던 중, 아래와 같은 소식을 접했다.


x.com은 비상업적 목적이거나, 단순 학습용이라도 크롤링은 명시적으로 금지했다.
이 때, 본문에 언급된 로봇 배제 표준이란 무엇일까?
robots.txt는 웹사이트에 웹 크롤러 같은 로봇들의 접근을 제어하기 위한 규약
로봇 배제 표준, 다시 말해 robots.txt는 해당 사이트의 어떤 경로를 크롤링할 수 있는지, 어떤 경로를 크롤링할 수 없는지 명시하는 문서다.
robots.txt는 웹사이트의 루트 경로를 통해 접근할 수 있다. 예를 들어 네이버의 robots.txt는 https://www.naver.com/robots.txt에 존재한다.
크롤링하고자 했던 x.com의 robots.txt를 확인해보자.
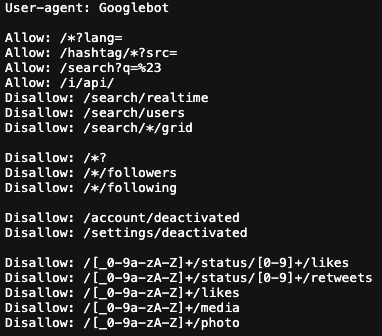
위는 Googlebot agent에 대한 경로를 명시하는 부분이다.
검색 엔진에 노출시키기 위해서 일부 경로를 허용한 것을 볼 수 있다. 하지만 팔로워, 팔로잉 등의 경로에 대해서는 접근을 금지하고 있다.
그 외에도 Facebookbot, Dicordbot에 대해서도 명시가 되어 있다.

명시되지 않은 User agent에 대해서는 전체 경로의 접근을 금지하고 있다.
그렇다면 크롤링을 할 수 없는 것일까?
결론부터 말하자면, 할 수 있다. 다시 말하자면, 해도 되는 것이 아니라 할 수는 있다에 더 가깝다.
robots.txt는 어디까지나 국제 권고안에 지나지 않으며, 당장 x.com의 robots.txt를 보더라도 위 사항을 엄격히 준수함이 아닌 respect 해달라는 의미를 담고 있다.
실제로 github에서 어렵지 않게 트위터 크롤링 오픈소스들을 확인할 수 있으며, 현재 프로젝트에서도 초기에는 트위터 크롤링 테스트를 진행했었고 정상 작동함을 확인할 수 있었다.
컨설턴트님과의 상담에서도, 트위터 크롤링을 진행한 팀들이 과거에도 많이 있었고 이로 인해 문제가 생긴 팀은 없었다고 말씀해주셨다.
그렇다면 사실 robots.txt를 무시하더라도 문제는 없는게 아닐까? 하지만 아래와 같은 이유로 해당 규약은 준수하는게 옳다.
윤리적 의무
당연히 웹 사이트를 만든 장본인의 의사를 존중해줘야 한다. 크롤링을 하길 원치 않는다면 하지 않아야 한다.
크롤링도 결국 서버에 지속적인 부담을 주는 요청이며, 이는 운영자의 비용 증가 및 서비스 사용성 저해로 이어질 수 있으니 운영자는 당연히 이를 금지할 권리가 있으며, 이 의사를 존중해야 한다.
법적 책임
robots.txt는 법적 효력을 가진 문서는 아니다. 하지만 이를 위반했을 때, 서비스 이용 약관을 침해하거나 Dos 공격으로 간주될 수 있으니 주의가 필요하다.
기술적 문제
사실 가장 와닿는 문제다. 단순히 크롤링이 안될 수 있다. 운영자가 허용하지 않은 경로를 지속적으로 접근한다면 악성 공격으로 간주, 해당 IP 혹은 계정이 차단될 수 있다.
아래는 크롤러 테스트를 진행하고 며칠 후 받은 메일이다.
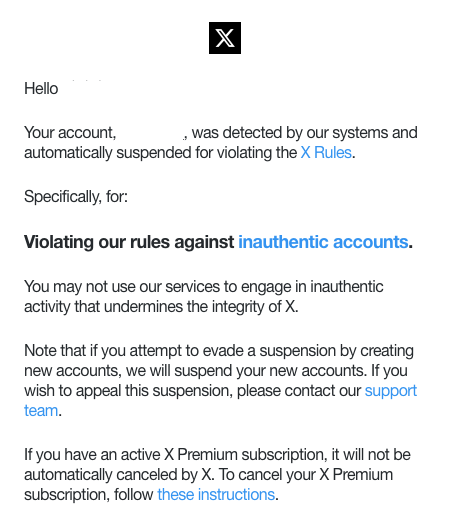
내 기억으로는 테스트 과정에서 고작 2~30회 요청을 보냈던 것 같은데, 귀신같이 잡혔다. 당연히 이렇게 차단된다면 정상적인 수집이 불가능하다.
대안
공식 API 활용
트위터의 경우 공식 API를 제공해준다. 월 200$에 API를 사용할 수 있지만 상업적 용도로는 사용하지 못하는 걸로 알고 있다.
이외에도 제공해주는 사이트가 더러 있으므로 확인해보고 유용하게 사용하도록 하자.
대체 웹사이트 사용
비슷한 정보를 제공해주며 크롤링이 허용된 사이트가 있다면 좋은 대안이다. 공연 정보를 크롤링하기 위해 x.com을 선정했지만 티켓링크 또한 공연 정보를 제공하는 동시에 크롤링을 허용하고 있었으므로 티켓링크 웹사이트 크롤링 + 수동 정보 수집 조합으로 프로젝트를 완성했다.
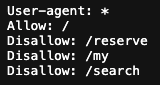
위는 티켓링크의 robots.txt다. /reserve, /my, /search 세 경로를 제외한 나머지 경로를 허용하고 있으므로 유용하게 사용하였다.
