비용이 비싸서 사람들이 잘 못씀.
(면접 때 사용하면 좋은 용어)
First party처럼 한 구독제에서 작동하는....
Databricks 기초
카탈로그
프로젝트(카탈로그)마다 스키마와 테이블을 생성하는 곳.
명시하지 않으면 기본은 delta 테이블이 생성.
Notebook
주피터 노트북 상위호환. 여러명 동시 편집 가능.
sql, python, md 언어 동시에 한 문서에서 사용가능 (ex. %sql)
html로 export 가능.
카탈로그.스키마.테이블 순으로 접근하거나
USE CATALOG `카탈로그 이름`;
USE SCHEMA 스키마이름;
-> 실행하면 테이블 이름만으로 사용 가능
DESCRIBE HISTORY delta_students;
-> 버전 확인 후 특정 시점으로 되돌아가기 가능!
RESTORE TABLE delta_students VERSION AS OF 6;%run
명령어를 사용하여 다른 노트북에서 노트북을 실행할 수 있습니다.
실행할 노트북은 상대 경로로 지정됩니다.
참조된 노트북은 현재 노트북의 일부인 것처럼 실행되므로 호출하는 노트북에서 임시 뷰 및 기타 로컬 선언을 사용할 수 있습니다.
SQL 문법
하나의 트렌젝션으로 처리하고 싶을때
MERGE INTO beans t USING new_beans s ON t.name = s.name and t.color = s.color WHEN MATCHED THEN update set grams=t.grams+s.grams WHEN NOT MATCHED and s.delicious= true THEN insert *기본문법
CREATE TABLE beans ( name STRING, ~~ ) USING DELTA; -- INSERT INTO beans VALUES ('pinto', 'brown', 1.5, true) -- UPDATE beans SET delicious = true -- DELETE FROM beans WHERE delicious = false; -- DROP TABLE beans;
대시보드
powerBI처럼 시각화 가능. 게시해서 공유 가능.
Genie Space
도메인 특화 자연어 채팅 인터페이스.
사용자가 데이터에 질문을 하면 SQL 쿼리, 결과 테이블, 시각화를 돌려받습니다.
Compute
Photon 가속-> 더 빠르게 계산해주는 대신 비용 1.5배
auto scaling ->

Machine Learning
compute 만들때 
AutoML
사람이 직접 모델을 고르고 튜닝하는 대신,
Databricks가 알아서 여러 모델을 시도해보고 가장 좋은 걸 찾아줌!
databricks.automl.classify(...) # 분류 문제 (예: 좋은 와인 vs 나쁜 와인)
databricks.automl.regress(...) # 회귀 문제 (예: 와인 점수가 몇 점?)
databricks.automl.forecast(...) # 시계열 예측 (예: 내일 판매량?)
# 💡 timeout_minutes와 max_trials로 비용을 제어합니다
summary = databricks.automl.classify(
dataset=f"{CATALOG}.{SCHEMA}.wine_quality_lab",
target_col="is_good_quality",
primary_metric="f1", # 어떤 기준으로 모델을 평가할지
timeout_minutes=20, # 최대 20분 안에 끝내라. 시간 다 되면 그때까지 결과 중 최고를 반환
exclude_cols=["quality"], # 원본 quality 컬럼 제외 (정보 누출 방지!)
)정말 대박인 자동화
1. 데이터 전처리: 결측치, 인코딩, 스케일링 자동으로 해줌
2. 알고리즘 선택: 여러 모델 자동 학습 후 비교
3. 하이퍼 튜닝: 최적 조합을 자동 탐색
하이퍼 파라미터 탐색 전략: 베이지안 최적화 기반-> 이전 결과로 다음 후보를 확률적으로 추정하기에 적은 시도로 최적값에 근접
- 평가 & 재현: 소스 노트북 자동 생성...!
Experiments
AutoML의 결과를 Experiments에서 전부 확인가능!
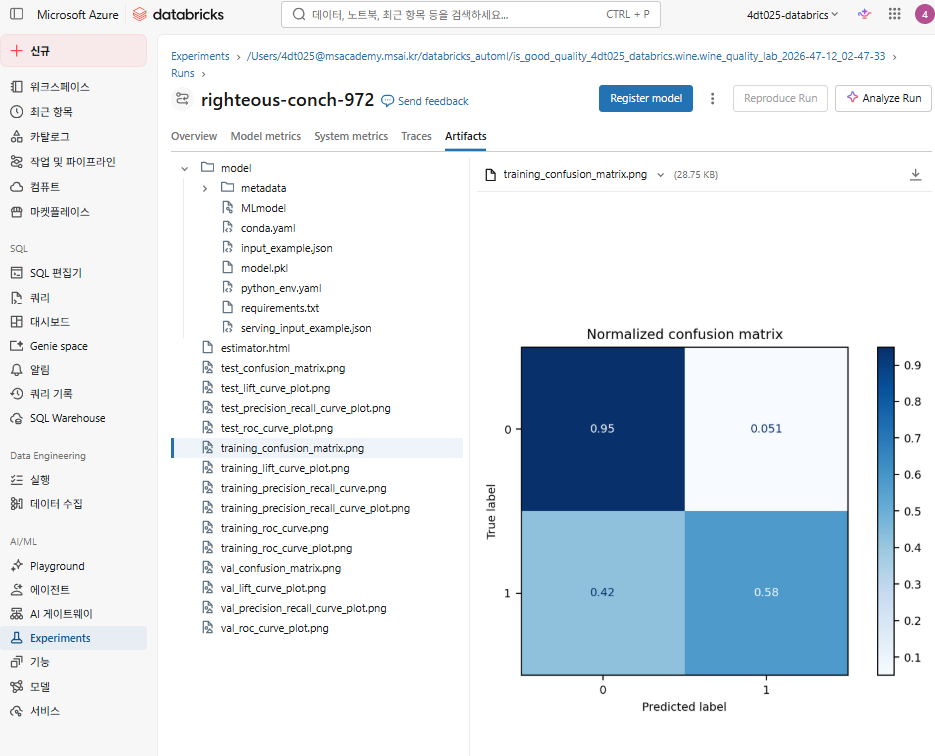

이제 개발해야지...