인코딩과 디코딩

인코딩
컴퓨터는 0과 1로 이루어진 이진코드만 읽을 수 있다. 한글도 컴퓨터한테 전달하려면 0과 1로 변환해 줘야하는데 이런걸 인코딩이라고 한다.
인코딩의 개념은 아주 넓은데 암호화, URL인코딩, 동영상 인코딩 등 인코딩은 우리가 인식할 수 있는 것을 특정한 형식으로 변경하는 것을 통칭한다.
간단하게 URL인코딩을 눈으로 봐보자.
네이버에 태풍이라고 검색하면
https://search.naver.com/search.naver?where=nexearch&sm=top_hty&fbm=0&ie=utf8&query=태풍
같이 보일테지만 메모장에 복사해보면
https://search.naver.com/search.naver?where=nexearch&sm=top_hty&fbm=0&ie=utf8&query=%ED%83%9C%ED%92%8D
이렇게 인코딩 되서 사용된걸 알 수 있다.
디코딩
인코딩의 반대되는 개념으로 특정한 형식으로 인코딩된 것을 우리가 인지할 수 있는 것으로 변경 하는 것이다.
암호화 된 걸 읽을 수 있게 복호화하는 작업을 예로 들 수 있다.
인코딩 시스템의 종류
ASCII(아스키)
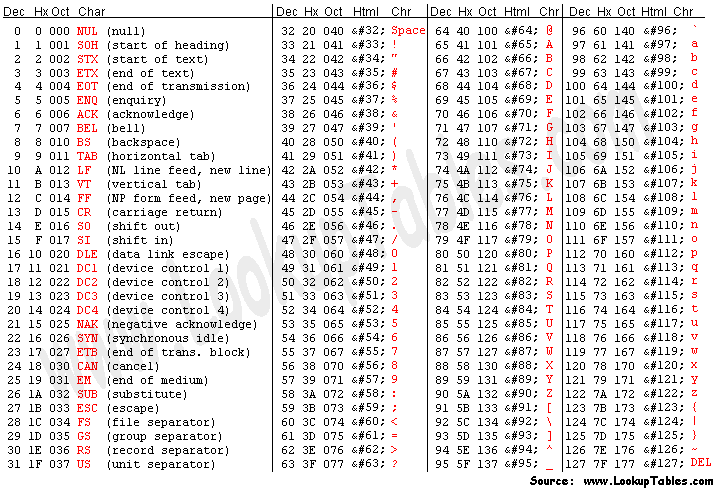
ASCII code는 컴퓨터와 다양한 전자 기기에서 문자를 표현하기 위한 표준 코드다. 7비트를 이용하여 0~127까지의 숫자와 영어, 특수문자를 맵핑하여 표현한다.
Unicode
위의 아스키 코드를 보면 영어 밖에 없다. 그래서 여러 종류의 인코딩 시스템이 생겨났고 이걸 하나로 통일 하기 위해 UniCode를 만들었다.
전세계 문자 포함이 되어있는 유니코드의 특징은 확장성이 있다. 확장성을 가지고 있는 유니코드는 새로운 문자가 생기면 추가 할 수 있다.
유니코드의 종류는 UTF-8, UTF-16, UTF-32가 대표적이다.
-
UTF-8 : 가변 길이 인코딩 방식이다. ASCII문자는 1바이트, 다국어 문자는 2바이트 이상을 사용한다. 주로 웹 페이지와 텍스트 기반 데이터 전송에 사용되며, 영어와 대부분의 기호를 효율적으로 저장한다.
-
UTF-16 : 문자마다 2바이트 또는 4바이트로 표현한다. 윈도우 환경에서 많이 사용하며, 모든 주요 언어와 기호를 효율적으로 사용 할 수 있다.
-
UTF-32 : 모든 걸 4바이트 크기로 표현한다. 처리 속도는 빠르지만 저장 공간을 많이 사용하며, 문자 조합이나 특수 문자 처리에 유리하다.
한 줄평 : 문서도 영어라서 한글로 디코딩해서 봐야하는 나...
