
사용 기한이 지난 쿠폰은 사용자에게 보이면 안되기 때문에 매일 정시에 사용자에게 보이지 않도록 처리하는 쿠폰 만료 배치를 개발했습니다.
그러나 배치 실행에 10시간이라는 긴 시간이 소요되고 있으며, 이 과정에서 배치 작업이 DB 커넥션을 점유해 사용자의 요청이 들어왔을 때 응답 시간 지연, 응답 오류율 증가와 같은 문제가 발생하고 있어 성능 개선 작업이 필요하다고 판단하였습니다.
성능 최적화 전
테스트 조건
- 만료일이 지나 삭제해야 하는 사용자의 쿠폰 2,000,000개
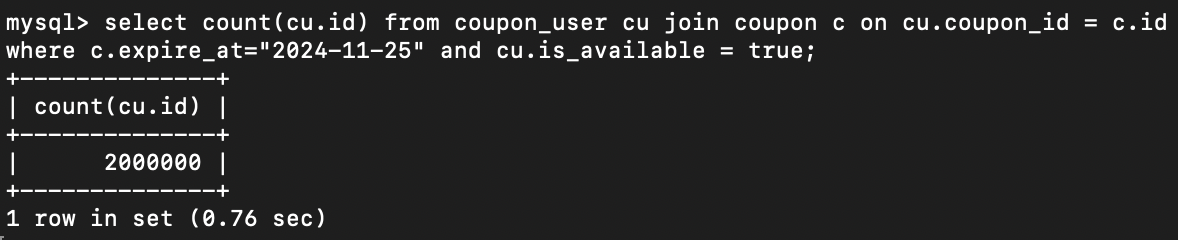
최적화 전 배치 처리 설정
- Spring Batch 5.1.2
- JpaPagingItemReader, JpaItemWriter 사용
- chunk size, page size는 기본 100으로 적용
실행 시간

약 10시간 20분 40초 소요되었습니다.
실행 시간이 긴 이유
- JPAPagingItemReader의 문제
JPAPagingItemReader는 아래와 같이 limit과 offset을 사용해 chunk만큼의 데이터를 가져옵니다.
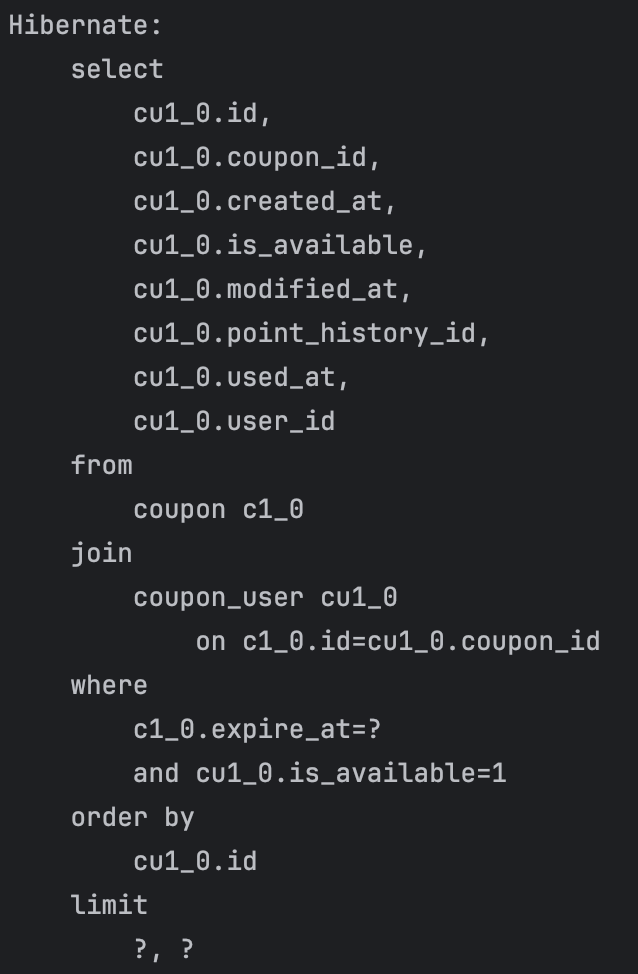
그러나 이러한 limit, offset을 사용한 방법은 태생적인 성능 한계가 존재합니다.
MySQL은 B+ Tree 알고리즘을 사용해서 데이터를 조회하는데 이로 인해 offset번의 데이터에 바로 접근하지 못하고, 리프 노드를 통해 순차적으로 탐색을 하게 됩니다.
그렇기 때문에 offset이 뒤로 갈수록 느려지는데, 이러한 점이 성능에 영향을 주었을 것으로 예상됩니다.
-
모든 컬럼을 조회한다.
사용자 쿠폰 테이블의 모든 컬럼을 조회해 가져오고 있습니다.
하지만 사용자 쿠폰 테이블에서 쿠폰 아이디를 통해 만료일을 확인하고, 사용 가능한 쿠폰인지를 확인한 뒤 해당 사용자 쿠폰의 식별자만 가져와서, 사용이 불가능하게 업데이트를 하면 되기 때문에 모든 컬럼을 조회할 필요는 없습니다.이렇게 모든 컬럼을 조회하게 되면 필요한 컬럼만 조회하는 것 대비 네트워크 전송량이 증가하고, 애플리케이션의 메모리 사용량이 늘어나며, 데이터베이스의 쿼리 처리 비용이 증가하게 됩니다. 이러한 점들이 성능에 영향을 주었을 것으로 예상됩니다.
-
JPAItemWriter의 문제
JPAItemWriter의 Dirty Checking으로 인해 단 건으로 처리되고 있어 DB와 자주 통신하게 됩니다.
( 하나의 엔티티마다 데이터베이스에 개별 쿼리를 실행하기 때문에 만약 1,000 개의 User의 변경이 감지되면 Database I/O도 동일하게 1,000 번 발생하게 됩니다. )또한, 영속성 컨텍스트를 기반으로 Dirty Checking을 진행하기 때문에 I/O 횟수뿐만 아니라 엔티티의 변경을 감지하는 비용도 발생합니다. 이러한 점들이 성능에 영향을 주었을 것으로 예상됩니다.
1차 성능 최적화
최적화 단계 요약
- Reader / Writer 변경
- chunk size 최적화
Reader / Writer 변경
-
JPAPagingItemReader에서 JdbcPagingItemReader로 변경
JdbcCursorItemReader Vs. JdbcPagingItemReader
- PagingItemReader는 Thread Safe 하며, 한 페이지를 읽을때마다 Connection을 맺고 끊는다.
- CursorItemReader는 Thread Safe 하지 않으며, 하나의 Connection으로 Batch가 끝날 때까지 사용하기 때문에 Batch가 끝나기 전에 Database와 어플리케이션의 Connection이 먼저 끊어질 수 있다.
JdbcCursorItemReader가 더 좋은 성능을 보여주지만 위와 같은 이유로 JpaPagingItemReader는 JdbcPagingItemReader로 변경했습니다.
-
JdbcPagingItemReader는 아래와 같은 쿼리를 통해 chunk만큼의 데이터를 가져오게 되는데 이는 no-offset pagination으로 offset pagination 대비 더 좋은 성능을 보입니다.

-
Projection을 통해 필요한 컬럼만 읽어오도록 수정했습니다.
- JPAItemWriter를 JdbcBatchItemWriter로 변경
JdbcBatchItemWriter는 대량 삽입 / 업데이트 / 삭제 작업을 처리하는 Writer입니다.
chunk size만큼의 쿼리를 모아서 한 번에 전달해 실행하기 때문에 JPAItemWriter 대비 더 좋은 성능을 보입니다.
chunk size 최적화
| chunk size | 실행 시간 |
|---|---|
| 100 | 2시간 27분 33초 466 |
| 500 | 31분 40초 445 |
| 1000 | 29분 45초 289 |
| 2000 | 15분 18초 652 |
| 5000 | 9분 25초 953 |
| 10000 | 7분 0초 95 |
테스트 결과, chunk size가 커질수록 실행 시간은 단축되는 것으로 보입니다.
그러나 chunk size가 커질수록 CPU 사용률과, GC 비용이 증가하는 경향을 보였기 때문에 테스트 결과, chunk size는 100 ~ 1000 사이가 적당하다고 생각했습니다.
뿐만 아니라 chunk size가 커질수록 배치 작업에서 메모리 사용량도 증가하기 때문에, 너무 큰 chunk size를 설정하면 다른 배치 작업에 영향을 미칠 수 있습니다. 이러한 점들을 고려하여 chunk size를 500으로 설정했습니다.
실행 시간

약 31분 40초 소요되었습니다.
2차 성능 최적화
최적화 단계 요약
- Multi Thread
Multi Thread
Multi Thread를 통해 병렬로 처리해 성능 개선을 할 수 있습니다.
Multi Thread
단일 작업(Job)을 여러 개의 스레드(Thread)로 나누어 동시에 실행합니다.
Reader, Processor, Writer를 동일한 스레드에서 실행하되, 여러 스레드가 서로 다른 데이터 chunk를 동시에 처리합니다.
다만, chunk 처리의 순서를 보장해주지 않기 때문에 이를 고려해야 합니다.
쿠폰 만료 처리 배치는 순서가 보장되지 않아도 되는 작업이기 때문에 Multi Thread를 적용해 병렬로 처리할 수 있습니다.
Thread Pool Size 설정
Thread Pool Size = 사용 가능한 코어 개수 x 목표 CPU 사용률 x (1 + )
사용 가능한 코어 개수는 동적으로 런타임에 사용 가능한 processor의 개수를 받도록 설정했습니다.
목표 CPU 사용률은 CPU를 과도하게 사용하지 않도록 설정하며, 보통 0.3에서 0.7로 설정하는 것이 일반적입니다. 저는 0.3으로 지정했습니다.
블로킹 계수(대기 시간 / 서비스 시간)는 I/O가 많은 작업을 고려하여 스레드 수를 조정합니다. 저는 0.2로 지정했습니다.
실행 시간

약 19분 35초 소요되었습니다.
3차 성능 최적화
최적화 단계 요약
- Partitioner
Partitioner
Partitioner를 통해 병렬로 처리해 성능 개선을 할 수 있습니다.
Partitioner
데이터를 여러 파티션으로 나누고, 각 파티션을 독립적인 스레드 또는 프로세스에서 처리합니다.
데이터를 파티션 기준(예: ID 범위)으로 나누면 각 파티션은 개별 StepExecution에서 처리합니다.
파티션 기준
단순히 사용자의 쿠폰 ID를 기준으로 파티션을 나누기엔 데이터가 불균등하게 분포될 가능성이 높기 때문에 기준을 잡기 위해 테스트가 필요하다고 생각되었습니다.
그렇기 때문에 집계함수인 ROW_NUMBER() 기준 파티션과 사용자 쿠폰 ID 기준 파티션의 실행 시간을 비교해보았습니다.
ROW_NUMBER()기준 파티셔닝
데이터를 균등하게 나누기 위해 SQL의ROW_NUMBER()함수를 활용하는 방법
ROW_NUMBER()함수는 각 행에 고유한 순번을 부여하는데 사용됩니다.
데이터의 불균등 분포 문제를 완화하기 위해 각 행에 연속적인 순번을 부여하여 파티션 분배를 균등하게 만듭니다.
현재 데이터는 ID를 기준으로 파티션을 나눴을 때 데이터가 균등하게 분포되기 때문에 임의로 불균등하게 분포된 환경을 만들고 테스트를 진행했습니다.
재설정된 테스트 조건
- 만료일이 지나 삭제해야 하는 사용자의 쿠폰 1,000,000개

테스트 결과
| 기준 | 실행 결과 |
|---|---|
| 사용자 쿠폰 ID | 1분 0초 290 |
ROW_NUMBER() | 9분 48초 288 |
ROW_NUMBER()를 사용하면 전체 데이터 스캔 및 정렬을 포함하므로 성능 저하가 발생합니다.
임시 테이블을 통해 성능 저하를 개선해보려고 했지만 임시 테이블을 유지할 방법을 찾지 못했습니다. 🥹
그렇기 때문에 파티션마다 불균등하게 분포될 수 있지만 사용자 쿠폰 ID 기반으로 파티션을 나누도록 설정하였습니다.
실행 시간

약 2분 37초 소요되었습니다.
4차 성능 최적화
최적화 단계 요약
- ChunkAfterListener
ChunkAfterListener
최적화를 진행하며 최초 10시간 이상 걸리던 배치 실행 시간이 2분대로 단축되었습니다.
실행 시간이 기존 대비 약 99.58% 개선되었지만 배치 작업은 안정적으로 수행되는 것도 중요합니다.
특히, Partitioning 적용 이후 CPU 최대 사용량과 평균 사용량이 이전 단계에 비해 크게 증가했기 때문에 안정성을 확보하기 위해 각 chunk 단위 실행 후, 0.2초의 지연 시간을 설정해주었습니다.
| Partitioning 적용 전 CPU 사용량 | Partitioning 적용 후 CPU 사용량 |
|---|---|
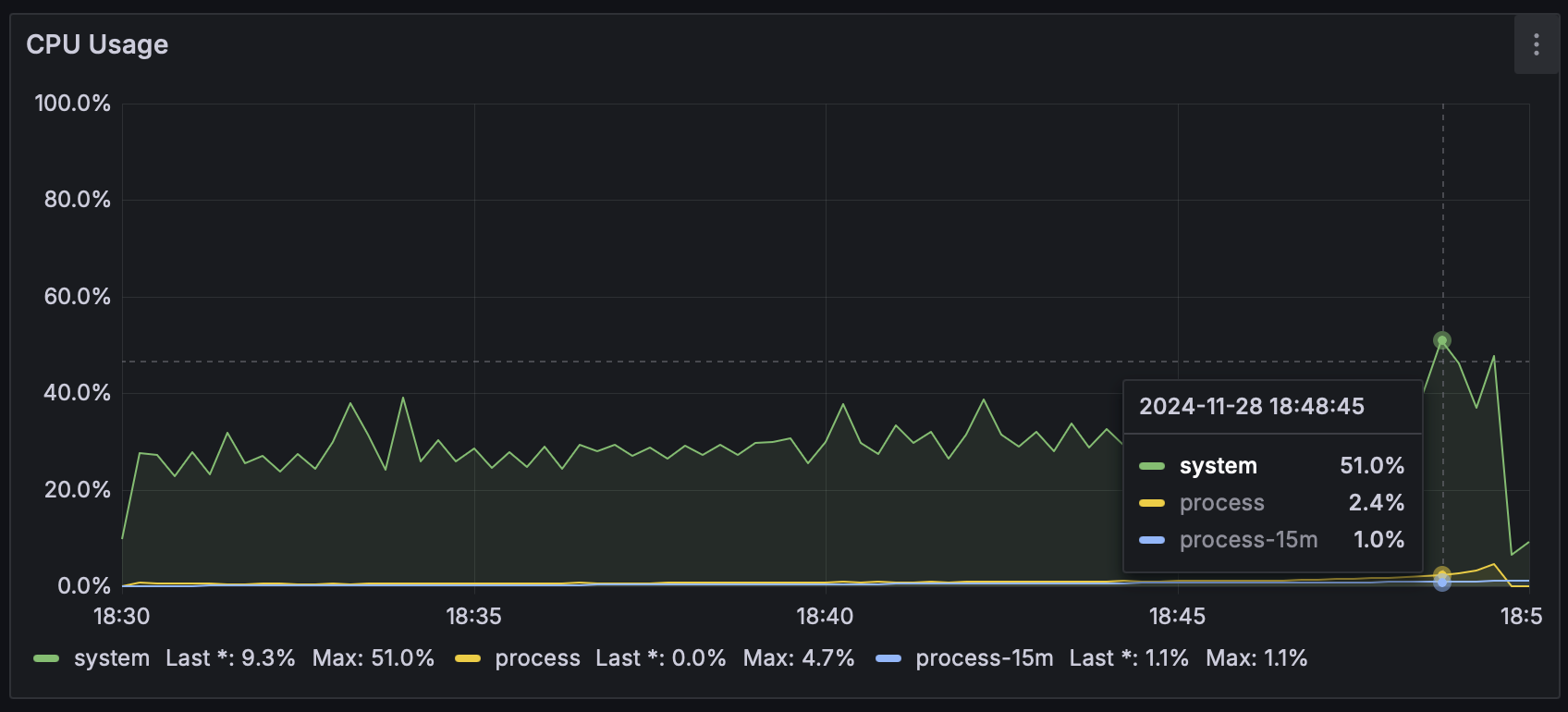 | 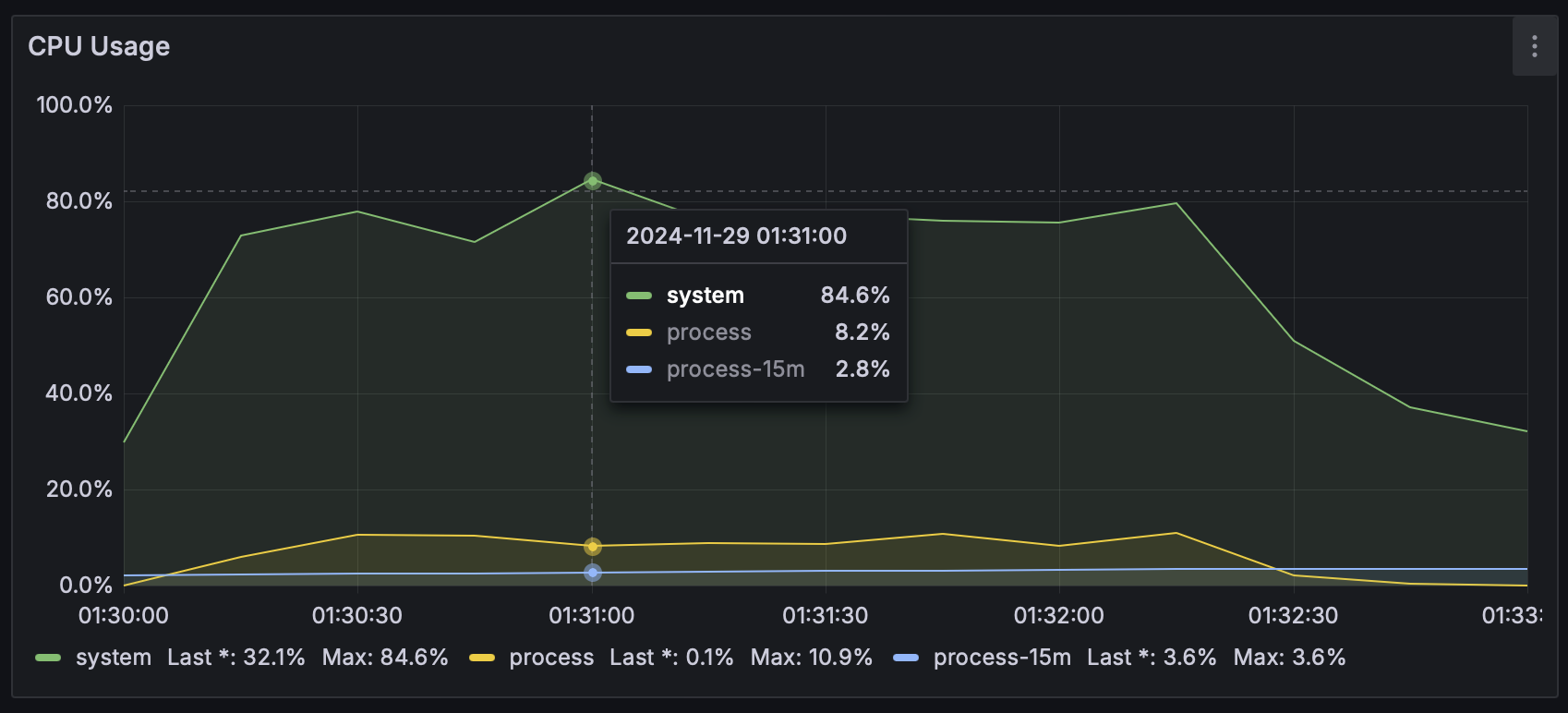 |
0.2초의 지연 시간 설정 이후, 아래처럼 CPU 최대 사용량과 평균 사용량을 낮출 수 있었습니다.
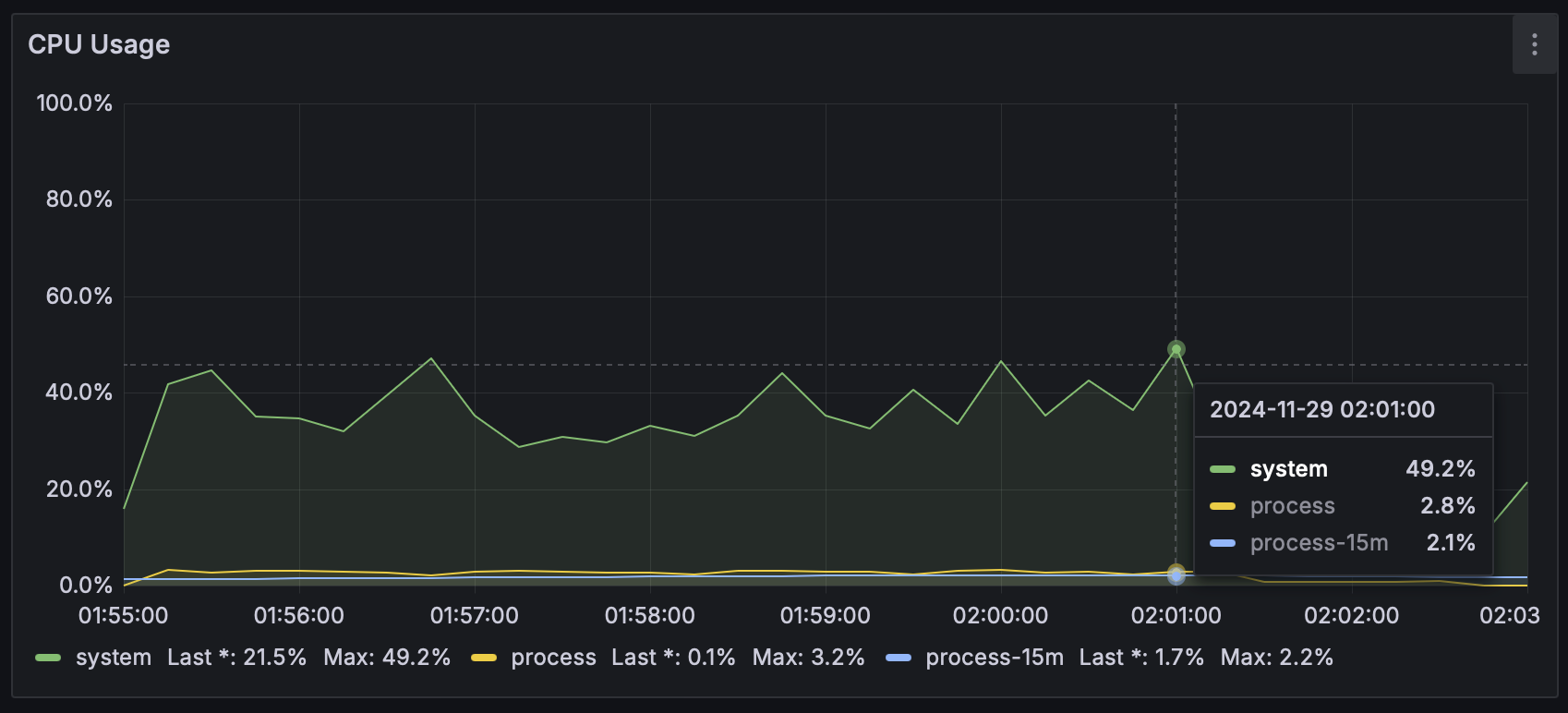
실행 시간

약 7분 31초 소요되었습니다.
성능 최적화 요약
| 최적화 단계 | 실행시간 | 개선율 |
|---|---|---|
| - | 10시간 20분 40초 180 | - |
| 1 | 31분 40초 445 | 94.90% |
| 2 | 19분 34초 472 | 38.20% |
| 3 | 2분 37초 265 | 86.61% |
| 4 | 7분 31초 692 | - |
✨ 최종 실행 시간(7분 31초 692)은 개선 전 실행 시간(10시간 20분 40초 180) 대비 약 98.1% 단축되었습니다.
실행 시간이 크게 단축되면서 DB 커넥션을 점유하는 시간이 줄어들었고,
그 결과로 응답 시간이 개선되며 응답 오류율이 감소하는 효과를 얻을 수 있었습니다.
