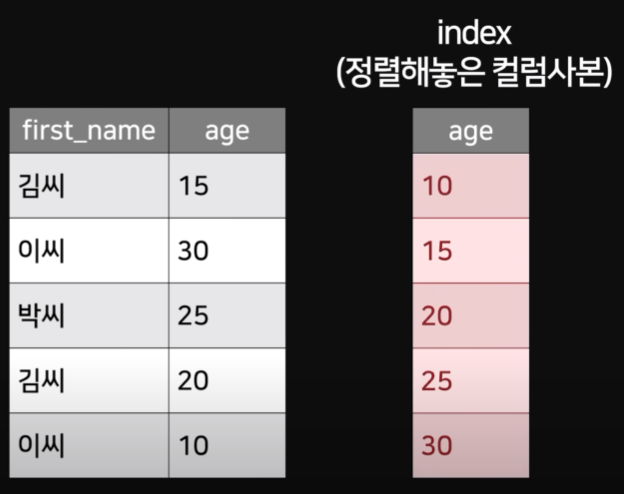
1. Index란?
RDBMS에서 INDEX란 검색 속도를 높이기 위한 기술
- DB에서 조회를 위해서는 Full Scan이 일어난다
- 효율적인 이분법적 Scan을 위해선 정렬된 사본이 필요하다
- Table에서 특정 Column을 정렬해 놓은 사본을 INDEX라고 한다
2. 사용 이유
조건 검색에서 굉장한 장점
- Where와 같은 조건문에서 조건에 맞는 열을 빨리 찾기 위해
- Join 실행 시 다른 테이블에서 열을 추출하기 위해
- Min() 혹은 Max() 값을 빨리 찾기 위해
- Order by 절의 효율
💡 그럼 조회(SELECT)말고 수정(UPDATE), 삭제(DELETE), 삽입(INSERT) 시에도 효율적인가?
A. 인덱스 종류에 따라 효율적일 수도 아닐 수도 있다
3. 인덱스의 종류
- B-Tree 인덱스 : 가장 일반적인 인덱스. 데이터를 효율적으로 정렬하고 범위 검색과 정렬된 결과 반환에 효과적
 |  |
|---|
- Hash 인덱스 : 해시 함수를 사용하여 칼럼의 값으로 해시값을 계산해내 매핑된 데이터를 찾는 방식. 동등 조건에서만 사용 가능

💡 Hash 인덱스 사용 시 동등 조건에서만 사용 가능하기 때문에(시간 복잡도 O(1))
수정, 삭제, 삽입에서도 효율적이지만 부등호 연산이 불가능 하다는 점 때문에 데이터베이스 자료구조에 부적합
-
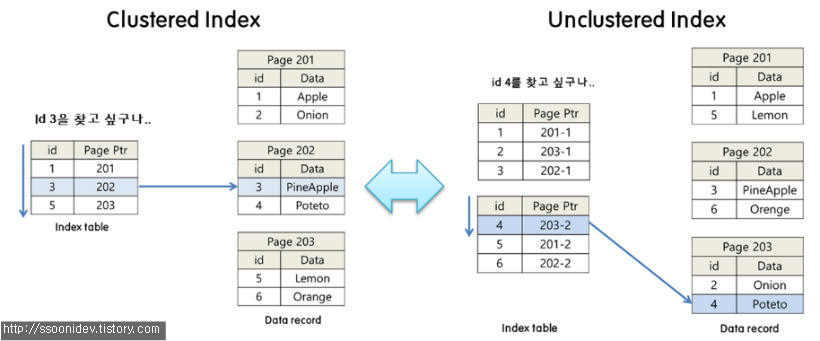
Clustered 인덱스 : 테이블에 Primary Key 설정 시 자동으로 생성. 물리적으로 정렬되어 있음. 한 테이블에 오직 하나만 존재 할 수 있다
-
Unclustered 인덱스 : Date Record가 정렬되지 않고 index table에 키값에 해당 하는 데이터의 위치를 저장하여 이를 통해 데이터를 찾아가는 방법
4. 작동 방식
- 인덱스가 없는 경우 → Full Scan
- 인덱스가 있는 경우 → index 테이블에서 원하는 값 or 범위 탐색 → 해당 값으로 본래 테이블에서 행 가져옴
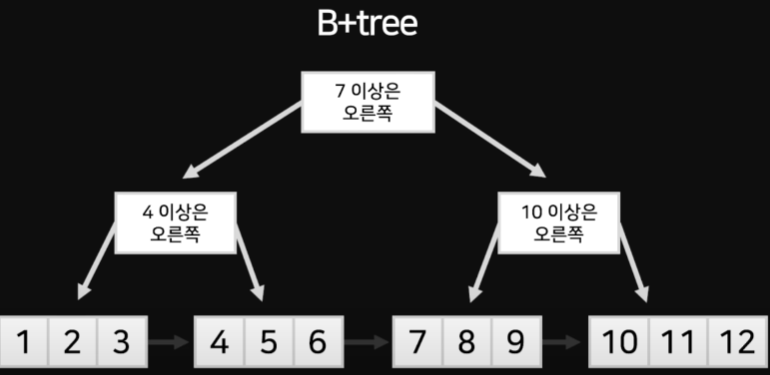
4.1 B-Tree와 B+Tree
 |  |
|---|
- B+Tree는 루트 노드와 내부 노드에는 가이드만 적어놓고 데이터는 리프노드에만 저장해 놓는다
- 리프노트 간 연결로 이동이 가능하다 → 범위 탐색에 효과적
- Mysql은 주로 B+tree 구조를 사용한다
5. INDEX 단점
-
오버헤드
insert, update, delete 될 때 인덱스 역시 갱신이 이루어진다. 이때 인덱스를 갱신하는 것을 오버헤드라고 표현하는데, 그만큼 insert, update, delete 작업이 느려질 수 있다. 대신 그만큼 select는 빨라진다.
-
추가적인 저장 공간 요구
데이터베이스 공간을 차지하기 때문에 추가적인 공간이 필요해진다
(DB의 10퍼센트 내외의 공간이 추가로 필요하다)
6. Example
books 테이블

기존 테이블에 index 생성
1. CREATE INDEX 사용 시
CREATE INDEX idx_book ON books (writer); // writer를 기준으로 index 생성
2. ALTER TABLE 사용 시
ALTER TABLE books ADD INDEX idx_test (writer); // writer를 기준으로 index 생성
- 둘의 차이점 : CREATE INDEX는 동일한 이름의 index가 있다면 오류를 반환
ALTER TABLE은 동일한 이름의 index가 있어도 오류 반환 X
테이블 생성 시 index 생성
CREATE TABLE `books` ( `id` varchar(5) NOT NULL, `name` varchar(20) NOT NULL, `writer` varchar(20) NOT NULL, `price` decimal(10,2) DEFAULT '0.00', `genre` varchar(20) NOT NULL, `publisher` varchar(20) NOT NULL, `discount_yn` char(1) NOT NULL, `discount_rate` decimal(10,0) DEFAULT '0', `cnt` decimal(10,0) DEFAULT '0', `sale_date` datetime DEFAULT NULL, PRIMARY KEY (`id`), INDEX `idx_test` (`writer`) );
7. INDEX REBUILD
- 인덱스 생성 후 insert, update, delete가 오랫동안 반복되면 트리의 한쪽이 무거워져 트리의 깊이가 깊어지는 문제가 생긴다
- 이러한 현상으로 인해 인덱스의 검색속도가 떨어지므로 주기적으로 리빌딩하는 작업을 거치는 것이 좋다
ALTER INDEX [인덱스명] REBUILD;
8. 마무리
- 조회가 자주 일어나는 테이블에 생성
- 단일 테이블에 인덱스가 많으면 속도가 느려진다
- 추가적인 저장공간이 필요하기 때문에 남발하지 말고 쿼리문을 효율적으로 짜는 것을 우선으로 해라
문답
혹시 리빌딩하는 주기를 짧게 가져가거나 해도 또 추가적인 문제가 생길까요?(홍영민)
기본적으로 삽입, 수정, 삭제 시 자동으로 인덱스 리빌딩이 이뤄지며 내부 문제에 의해 오랜 기간이 지나 균형이 잡히지 않을 때 수동으로 리빌딩을 해줄 수 있습니다.
당연히 리빌딩에는 리소스가 들기 때문에 자동으로 리빌딩해주는 것 말고 수동으로 리빌딩을 자주하게 되면 비효율적일 것입니다,
1. 클러스터드 인덱스(테이블 당 1개)를 제외한 다른 인덱스는 단일 테이블에 여러개 만들 수 있습니다. 예를 들어 학생 테이블에 ‘학번’을 기준으로 한 인덱스와 ‘수학 성적’을 기준으로 한 인덱스를 각각 만들수 있습니다.
2. 다중 칼럼 인덱스를 생성할 수 있습니다. 예를 들어 ‘학번’ 과 ‘수학 성적’ 두개의 칼럼으로 이루어진 하나의 인덱스 테이블을 만들 수 있습니다. 하지만 이 경우에 칼럼의 순서가 중요합니다 보통 조회해야하는 값의 범위가 적은 칼럼일수록 앞에 배치해야 효율적입니다,(동등 조건 ’=’ 이 자주 걸리는 칼럼을 앞으로)
인덱스에 직접 접근하는 sql은 없습니다. 일반적인 쿼리를 날렸을 때 '옵티마이저'라고 하는 SQL의 실행계획을 결정하는 역할을 하는 파트가 쿼리문을 읽고 해당 테이블에 인덱스가 있는지 확인해서 있다면 인덱스를 통해 조회하고 없다면 해당 테이블을 조회하는 방식으로 동작합니다
참고문헌

88888888