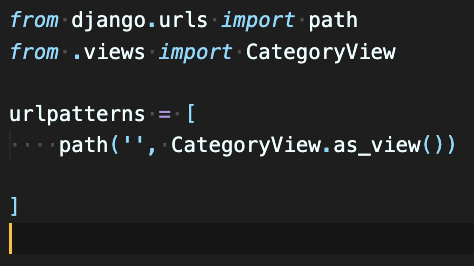
위 사진에서 path('products') 라고 되어 있는데, 저 부분이 url 에서 추가로 시작하는 부분,
ex)www.naver.com/products <<< naver.com 부터 슬래쉬 / 다음으로 시작
그리고 import include를 해서 그 url로 가라~
path('product'), include('products.urls')) <<< products 앱폴더 안에 urls.py로 가라~
근데 지금은 products 앱폴더 안에 urls.py가 없으니까 하나 만들어주고 들어간다.
들어가서
지금 products앱안에 있는 urls.py 입니다.
from django.urls import path 를 해주고
똑같이 urlpatterns = [] 를 만들어 주는데,
path('/register') << 이제 이건 (위 예시 포함) www.naver.com/products/???
물음표가 들어갈 자리에 위치함. www.naver.com/products/register
근데 여기서는 / 슬래쉬를 붙여야한다.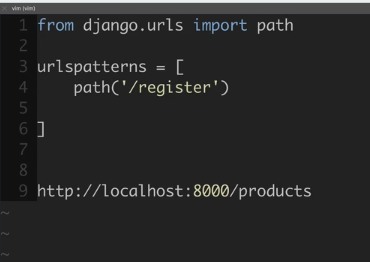 예를 들어 지금 상태가 www.naver.com/products << 이런 상태라서 그렇다.
예를 들어 지금 상태가 www.naver.com/products << 이런 상태라서 그렇다.
urlpatterns = [
path('', ????) <<<< ???? 자리에 뭐가 들어가냐면,,, 여기 왔을 때 어쩌라는건지 써주는 것
이제 view 클래스를 쓴다.
그럴려면 import를 해야한다.
as_view() 장고에 있는것.
이제 views 파일에 가서 CategoryView라는 클래스 만들어야함
 views파일에 처음 가면 import render 어쩌고 있는데 그건 template이랑 관련있기 때문에 지우면 된다.
views파일에 처음 가면 import render 어쩌고 있는데 그건 template이랑 관련있기 때문에 지우면 된다.
from django.views import View를 쓰고
아까 products.urls 에 있던 class CategoryView를 만든다.
models와 달리 여긴 뭔가를 하는 로직을 담는 곳이라
get, post같은 명령어가 있다.
as_view
아까 as_view라는 함수를 썼는데 as_view가 이걸 해준다.
get요청이면 get method를 일로와서 부르게 해주는 그런 역할이다.
post요청이면 post method를 불러서 구동하게 하는 역할
CategoryView라는 클래스로 가는건 아니까 , 그 클래스에 가서, 어떤 요청인지에 따라 그 메쏘드를 불러주는 것!!!!! 그게 as_view!!!!!
post는 지금 안쓸거니까 지우고, get 함수를 써보겠다. 처음 인자는 self이며 request를 받겠다.
이제 할일은 .all() or filter()를 써서 , 테이블에서 내가 원하는걸 다 긁어와서 프론트엔드가 보기 편하게 가공을 해서 리턴을 해준다.
json으로 리턴 그래서 jsonresponse를 import해준다
!! 그리고 jsonresponse가 필요없는 경우에 그냥 HTTP response만 보내줘도 된다. 그럴때 import HTTPresponse 쓰면 된다. 근데 연습할때는 안쓴다.
프론트에서 HTTP리스폰스 처리하기 처음엔 어려워서.
이제 get함수를 써야하는데, models.py 에 있는 테이블에서 카테고리 이름을 다 가져오고 싶다 << 이걸 수행할려면, models.py import 해야합니다 (중요...)
 이렇게 하면 카테고리에 있는거 다가져와!! 했는데 아무일도 일어나지 않는다. Jsonresponse로 리턴을 해줘야하기 때문.
이렇게 하면 카테고리에 있는거 다가져와!! 했는데 아무일도 일어나지 않는다. Jsonresponse로 리턴을 해줘야하기 때문.
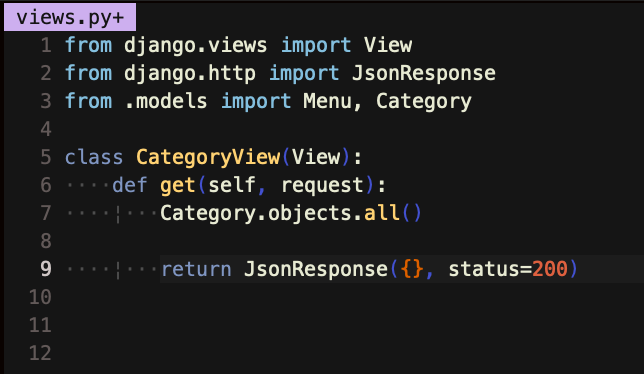
첫 번째 인자를 객체로 받고{}, 뒤에 잘되면 200 이라는 상태표시
json 객체안에는 전부 스트링,
convention 이 있다 (개발자 모두 통일하게 하는것)
 딕셔너리의 key에 "result"or"results"를 넣는게 컨벤션이다.
딕셔너리의 key에 "result"or"results"를 넣는게 컨벤션이다.
많이 나오는거
201 Created 회원가입 성공!
400 이상한 요청 보냈을 때 (에러나면 거의 400)
500 내 서버가 터지면
401 인증오류 (비번 잘못친거)
Category.objects.all()라고 하면 쿼리셋이 나온다(디비에서 필요한걸 꺼내서). 리스트 처럼 보이지만 파이썬 리스트와 다르다!!
그래서 쿼리셋을 딕셔너리형태로 만들고 그걸 리스트에 넣어서 보낸다 <<<
진짜 중요 개념임 위 3중 진짜!!
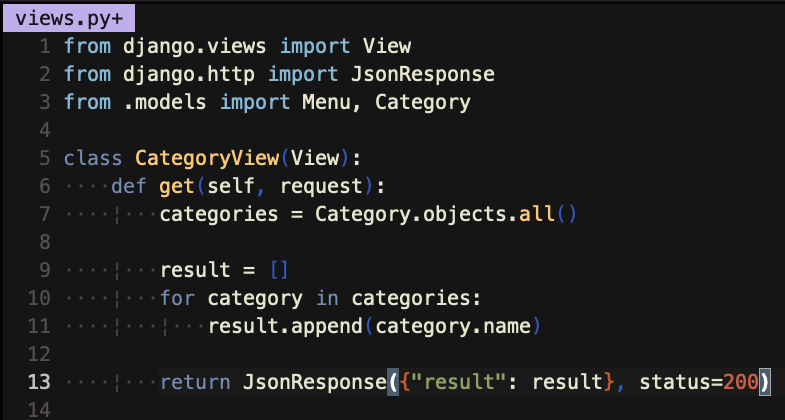
Category.objects.all() <<쿼리셋 리턴
result = [] <<< 빈 리스트 만들고
for category in categories:
result.append(category.name) <<< 쿼리셋에서 이름을 리스트에 하나하나씩 넣어라
그리고 return JsonResponse({"result": result}, status =200) <<< 딕셔너리에 넣어서 보내라, 잘 넣었으면 200오케!!
이제 runserver한다.
python manage.py runserver
그리고 
http 로컬호스트에 products 앱으로 들어가면 무엇을 하는가? 어떻게 되는가?
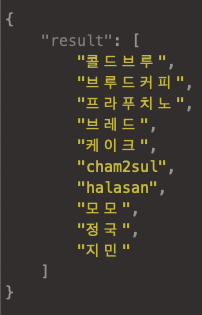
위 두 이미지처럼 나온다. 서버 켜놓은 터미널엔
 200 !!!!!!!!!!!!!!!!!!!!!!
200 !!!!!!!!!!!!!!!!!!!!!!소리벗고 팬티질러!!!

http -v GET 127.0.0.1:8000/products <<<
-v 는 있어도 되고 없어도 된다. (더 많은 것을 보여주는 옵션일 뿐)
127.0.0.1:8000 대신 localhost 라고 써도 된다.
http GET << workflow: GET 메쏘드 --> CategoryView.as_view() --> as_view() 뜻: 저 클래스안에가서 def get ( ) 겟 메쏘드 찾아서 수행해라!
그래서 def get << 이거 스펠링 중요함 아무거나 막쓰면 as_view가 못찾음
웹 크롤링 (BeautifulSoup4)
우리가 배우는건 scraping에 좀더 가깝다.
크롤링을 한다는건 , 오리지널 웹사이트가 변경되면, 내가 크롤링한 정보가 자동으로 업데이트 되는 걸 뜻한다.
스크래이핑은 그 시점에서 내가 필요한걸 긁어오는 것.
크롤링을 잘 할려면 웹을 분석을 잘해야한다.
보그 코리아 웹사이트를 연습할 것.
Beautiful Soup
웹을 구성하는 html의 id , class 와 같은 selector를 분석하여 변수로 사용할수 있도록 도와주는 라이브러리
Selenium
브라우져를 실행시켜 동적인 입력이 필요한 웹을 구동할 수있는 라이브러리
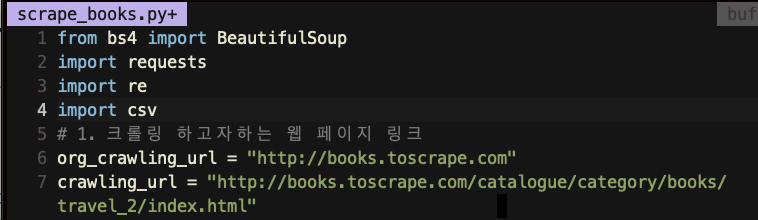
위 이미지의 org_crawling_url and crawling_url 이 왜 필요하냐면
저 주소를 GET을 하는거에용
HTTP GET method를 사용해가지구
저 주소를 따라 GET method를 보내는 거에요
그러면 bookstoscrape서버가 자기 html코드를 보여주는 거죠
그래서 사용하는 코드가!
requests.get(crawling_url)
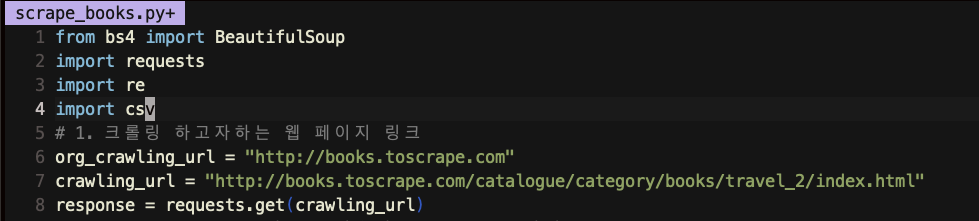
Line 2에서 받은 모듈안에 있는get method에다가 crawling_url을 넣고,,, 그 받은 결과를 response라는 변수에 저장
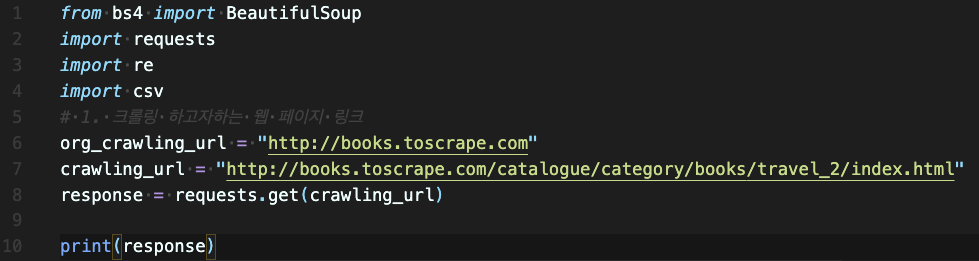
여기서 response를 프린트 해보면.

status code만 오는게 아니라 response 객체가 온것이다.
print(response.text) << 이렇게 해야 html 코드들이 나온다.
(엄청 나올텐데 에러가 아니고, 그 브라우져의 html코드다)
만약 브라우져였으면 html css언어를 이해하기 때문에 이쁘게 나올텐데
터미널은 두 언어를 이해 못하니까 그냥 주구장창 코드만 나열한다.
그래서! 이렇게 오는 엄청많은 텍스트들을 변수에 넣기 위해 한 것! --> BeautifulSoup4
클래스 이름을 변수로 쓰고싶어서 그렇다
next step

bs4 가 html 의 태그들 (class, p, id, form, etc..)를 변수로 알아들어서 쓸 수 있다.
CSS selector를 이용해서 가져올 건데
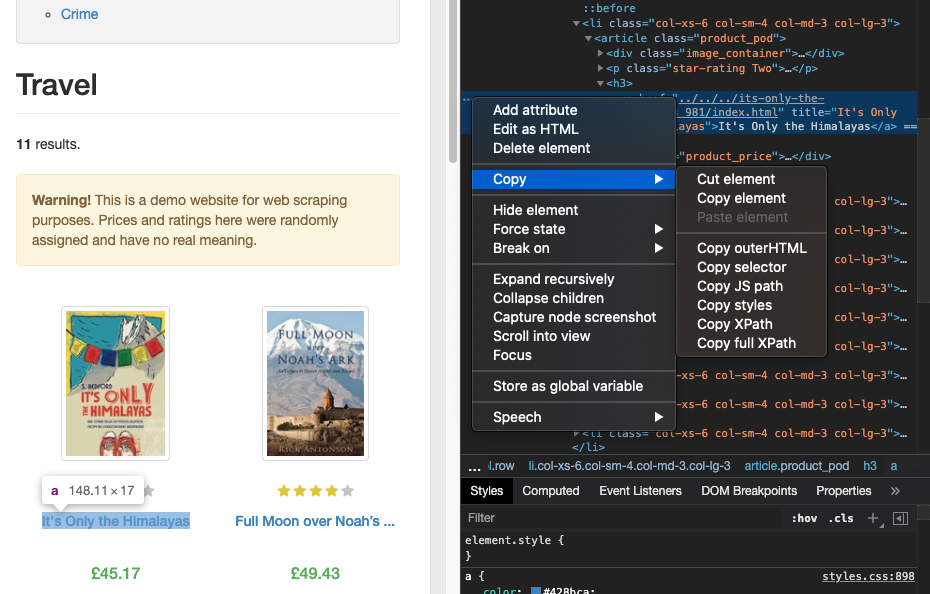
위 사진 처럼 긁어오고 싶은 것을 클릭하고 하이라이트 된 line 의 왼쪽에 점 3개를 누르면 copy > copy selector를 누르면 된다.

bs.select_one << 하나만 선택해서 가져온다. 저 select element
CSS selector 구글에 치면 나온다. 외울 필요없다. 원리만 외우면 된다.


실제로 a태그가 왔다. element 가 온것 (글자가온게 아님)
우리는 글자를 가져와야함
print("one_title:", one_title['title']) 이렇게 해주면 딕셔너리값,

select_one말고
select를 할 수 있다. (여러개 불러올 때)
그리고 print("one_title: ", one_title)
print("one_title: ", len(one_title))
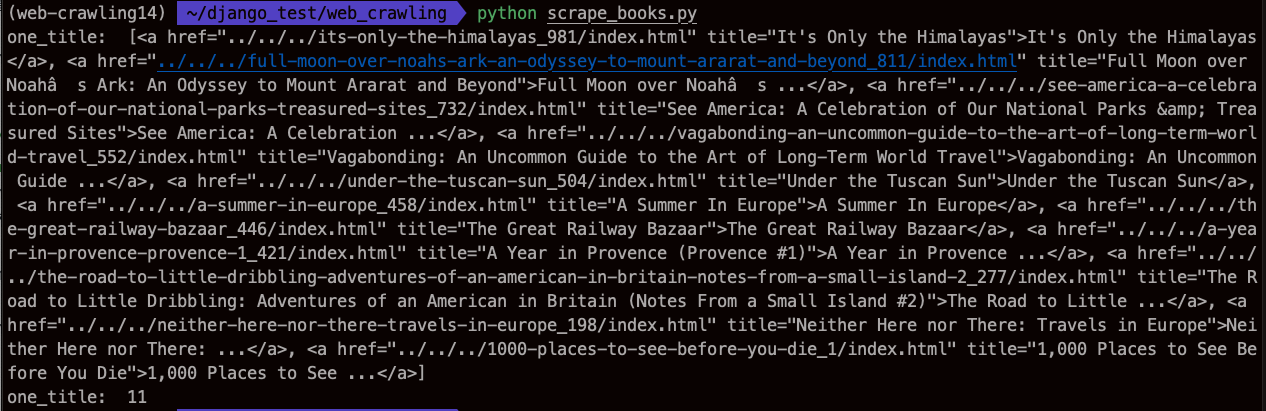
11개 모두 가져왔다.

이렇게 image_urls들 다 가져왔을때 화면

중간에 ../../../../ 의 뜻,
지금 crawling_url = "http://books.toscrape.com/catalogue/category/books/travel_2/index.html"
에서 가져왔는데 사실 , 이미지는 저기 있는게 아니라, 4단계 상위 폴더로 가서 media폴더에 있다는 걸 알려주는 것
그래서 완전 초기 페이지로 가서 이미지를 inspect 해보면
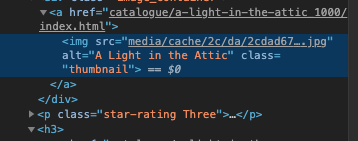
media앞에 ../../../../이 없는 것을 알 수 있다.
이럴 때, 코드카타처럼, 저거 빼고 뒷부분만 가져온다.

쉽지 않다. 파이썬 공부 열심히 하자
for title in image_urls:
print('image_url: ', title['src'].split('/') [4:])src인 이유 : 주소가 src에 들어있어서
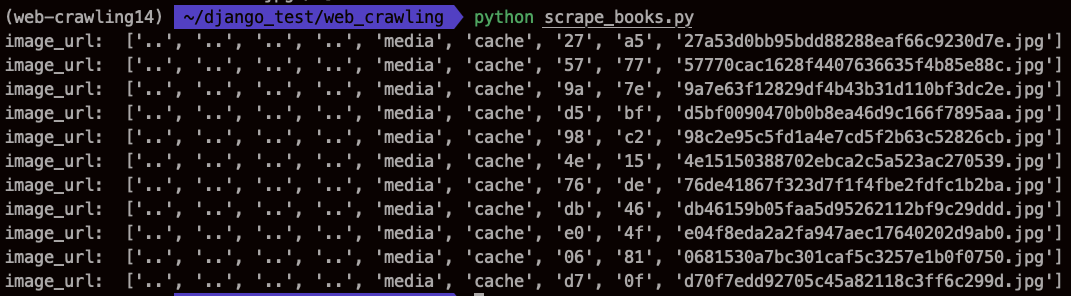
스플릿, split('') 여기에 뭘 넣는지의 기준으로 쪼개 주는 것.
그다음에 [4:]을 넣어서 앞에 4개 버리고 시작
그리고 다시 붙힌다. join method
print('true_image_url: ',
org_crawling_url + '/' + '/'.join(title['src'].split('/')[4:]))진짜 최종...
이름 가지고 오는 건 쉽다. 가져와서 부터 시작이다.
파이썬 로직으로 위 처럼 하나하나 짜고 깔끔하게 만들어야하기 때문에
이 때 파이썬 로직이 많이 는다.
이제 Selenium
conda activate web-crwaling14 해주고
pip install seleniuim
pip install webdriver-manager
크롬 드라이버 띄우고 셀레니움으로 접속하고 다 뜨면
그때 부터 BS4 사용
