UC Berkeley Prof. Sergey Levine의 CS285 Fall 2021 강좌를 정리한 내용입니다.(https://rail.eecs.berkeley.edu/deeprlcourse/)
강의에 대한 자세한 정보는 위 링크에서 확인하실 수 있습니다.
How is different from other machine learning topics?
- standard (supervised) machine learning의 경우
- 데이터가 i.i.d라고 가정(independant and identical distribution)
- i.i.d라는 것은 특정 출력이 다른 입력에 영향을 주지 않는다는 것을 의미한다.
- training에서의 ground truth output을 알고 있다고 가정
- 데이터가 i.i.d라고 가정(independant and identical distribution)
- 반면 RL은 data가 i.i.d가 아님. (다음 action이 이전 출력에 영향을 받는 continuous한 decision making)
- ground truth output이 있을 수도 있지만, 없을 수도 있음.
What is reinforcement learning?
- Mathematical formalism for learning-based decision making
- decision making과 control을 경험으로부터 배우는 방법
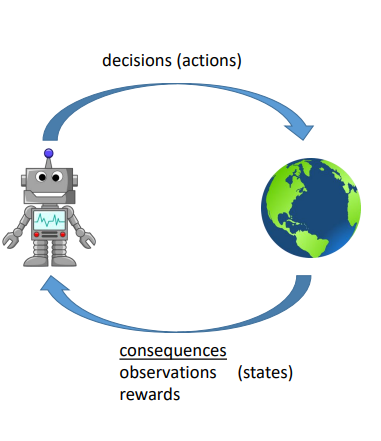 강화학습으로 학습시킬 대상을 agent라 하고, 학습이 이루어지는 공간을 environment라고 한다. 강화학습은 decision making system을 agent와 enviornment의 interaction으로 모델링한다.
강화학습으로 학습시킬 대상을 agent라 하고, 학습이 이루어지는 공간을 environment라고 한다. 강화학습은 decision making system을 agent와 enviornment의 interaction으로 모델링한다.
- agent가 action을 하면, environment에서는 observation과 reward를 돌려준다. 다시 말하면, action을 통해 agent는 다음 상태로 이동하고, 해당 action에 대한 feedback으로 reward를 받는다.
- 이러한 decision making의 순환 과정은 finite horizon이라면 한 에피소드 동안 여러 번 반복되고, infinite horizon이라면 멈추지 않고 계속 발생한다.
- observation과 state의 차이를 간단히 설명하자면, observation은 partial state라고 할 수 있다. agent가 fully observate하여 state의 정보를 모두 아는 일은 드물다.
- 강아지와 로봇, 재고관리 시스템의 예시

Wht should we care about deep RL?
- 현실 세계는 복잡하고 예측하기 어려우므로, 유연함과 적응이 필요하다.
- deep learning은 다루기 어려운 unstructured environments를 다룰 수 있도록 도와준다.
- complex problem들을 end-to-end로 접근할 수 있게 도와준다.
- example, robotics pipeline
 end-to-end로 접근해야 하는 이유는, 각 파이프라인의 단계에서 실수가 발생할 수 있고, 이는 다음 단계에 영향을 주기 때문.
end-to-end로 접근해야 하는 이유는, 각 파이프라인의 단계에서 실수가 발생할 수 있고, 이는 다음 단계에 영향을 주기 때문.
Where do rewards come from?
-
로봇은 스스로 task를 제대로 수행했는지 인식할 수 있어야 함.
-
대학의 학위 등을 예시로 들면, 보상이 굉장히 sparse함. 단순히 실수나 random한 행동을 통해 보상이 주어지지 않음.
-
Advanced topic to cover
- inferring reward from observed behavior(Inverse RL)
- Transferring knowledge between domains (transfer learning, meta-learning)
-
Imitation learning
- More than imitation(inferring intentions)
- 어떤 action을 보고, 대상의 목적을 추론하여 최적의 방법으로 수행.
- 책을 들고 있는 남자의 action을 보고 서랍 문을 열어주는 아이(심리학 실험)
How do we build intelligent machine?
-
뇌를 모방
- 각 기능을 위한 모듈의 조합이 아니라, single flexible algorithm
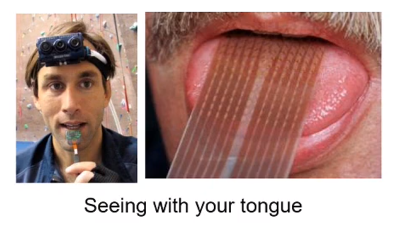
- 예시1) 전극이 부착된 카메라를 통해 혀로 볼 수 있음.
- 예시2) 아주 어린 개구리의 시신경과 시각피질의 연결을 제거한 뒤, 청각피질에 연결하였고 다 자라난 뒤에는 시력을 회복했음.
- 이러한 예시들은 뇌의 다른 부분들이 서로의 일을 대신 수행할 수 있다는 점을 시사함.
-
Challenges
- 게임과 같은 제한적인 상황에서는 좋은 성능을 보이지만, 학습이 굉장히 느림. (사람은 학습이 굉장히 빠름)
- 사람은 과거의 지식을 잘 활용할 수 있음. (Transfer leraning is an open problem)
- reward function 설정이 명확하지 않음.
마지막으로 Instructor Sergey Levine이 좋아하는 인용구.
Instead of trying to produce a program to simulate the adult mind, why not rather try to produce one which simulates the child's? If this were then subjected to an appropriate course of education one would obtaion the adult brain.
- Alan Turing
너무 좋은 글이네요. 공유해주셔서 감사합니다.