부트스트랩 Bootstrap
부트스트랩은 표본에서 복원추출 방식으로 표본을 뽑아 전체 표본을 늘리는 방법입니다. 주로 데이터 수집 비용이 매우 비싸거나, 수집이 어려운 상황에서 통계적으로 모델 파라미터의 분포를 추정할 수 있습니다.
구체적인 방법은 다음과 같습니다.
(1) 개의 데이터로 이루어진 표본 집합 에서 개의 표본집합 를 번 복원추출합니다.
(2) 추출한 각각의 표본집합 를 모델(estimator)에 넣습니다.
(3) 출력된 결과 통계량을 가지고 모델 파라미터의 분포를 추정합니다.
참고로 부트스트랩을 통해 얻은 데이터의 신뢰도를 어느 정도 보장하기 위해서는 최소 5000번, 일반적으로 1만 번 이상의 샘플링을 수행해야 한다고 알려져 있습니다.
Examples
예를 들어 다음과 같은 두 분포를 따르는 데이터가 있다고 가정해봅시다.
이라고 하면 아래와 같은 그래프를 그릴 수 있습니다.
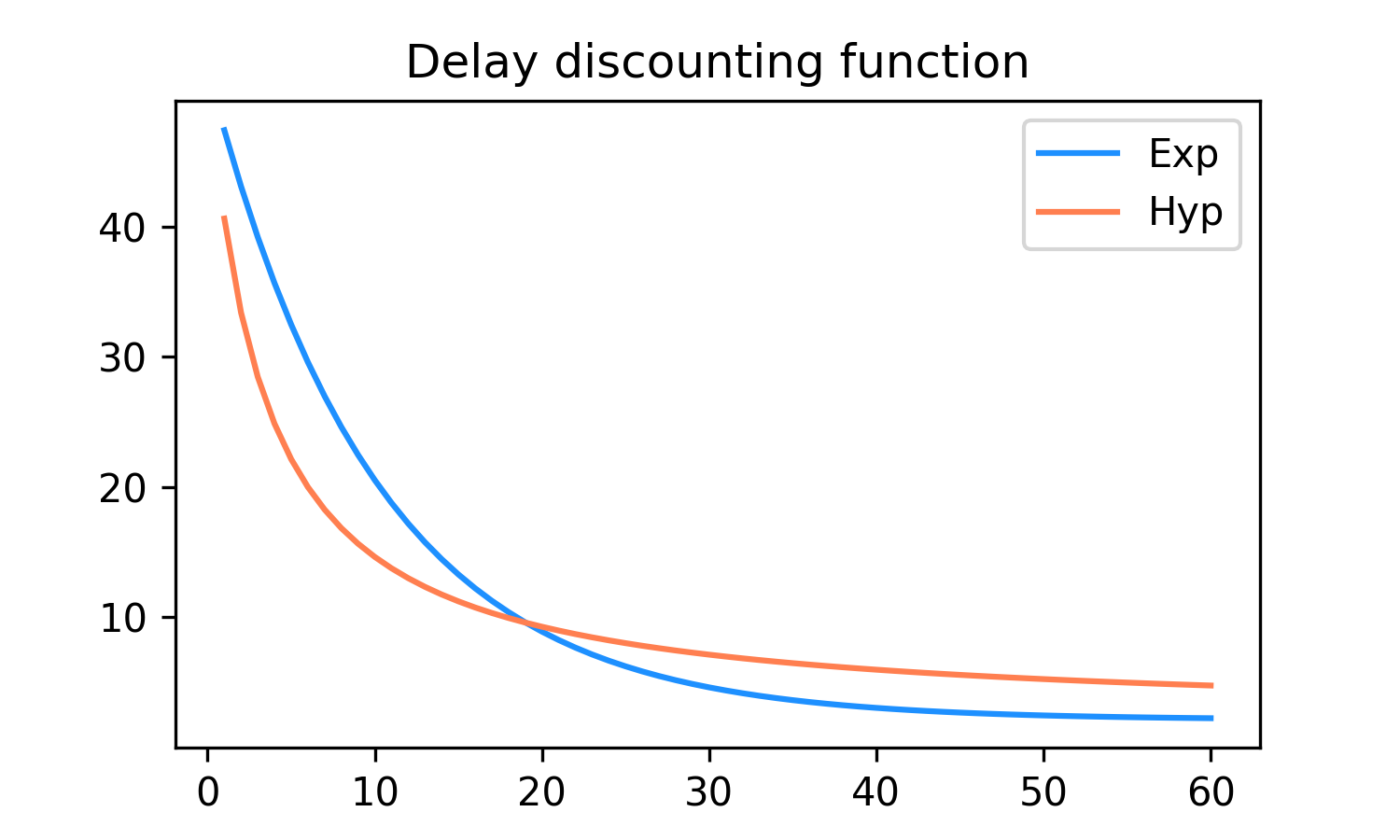
다음은 1만개의 샘플을 생성하는 부트스트래핑 예시 코드입니다.
def bootstrapping(data, num):
sample = np.random.choice(data, num, replace=True)
return sample
def data_loader(data, iters, num):
dataset = []
for _ in range(iters):
sample = bootstrapping(data, num)
dataset.append(sample)
return np.array(dataset)
num = 60
iters = 10000
exponential_dataset = data_loader(data_exp, iters, num)
hyperbolic_dataset = data_loader(data_hyp, iters, num)
print(exponential_dataset.shape)
>>> (10000, 60)
print(hyperbolic_dataset.shape)
>>> (10000, 60)부트스트랩 사용 예시에 관한 좋은 글도 참고해 보세요.
부트스트랩의 신뢰도
부트스트랩은 복원추출을 통해 가지고 있는 데이터를 늘리는 방법입니다. 그래서 만약 주어진 데이터 자체가 편향돼 있다면 아무리 부트스트랩을 하더라도 편향된 데이터밖에 얻을 수 없다는 문제가 있습니다.
따라서 부트스트랩을 사용할 때는 주어진 데이터가 모집단의 특성을 잘 반영하고 있다는 전제가 필요합니다. 또, 부트스트랩을 통해 얻은 데이터로 분포의 범위를 추정할 수는 있지만 정확한 데이터 포인트를 찾아낼 수는 없습니다. 이러한 관점에서 어떻게 샘플링되었는지 알 수 없는 데이터에 대해 부트스트랩을 사용한다는 것은 사실 꽤 naive한 접근일 수 있습니다.
간단한 예를 살펴봅시다.
실제값 , 추정량 에 대해 오차 는 다음과 같습니다.
그런데 를 알 수 없으므로 부트스트랩을 통해 을 얻는다고 가정하면 실제 오차 에 대한 추정 오차 는 다음과 같습니다.
각각의 분산을 구하면 은 변하지 않으므로 상수취급하여 다음과 같이 나타낼 수 있습니다. (상수의 분산은 0)
즉, 부트스트랩을 아주 많이 수행하더라도 에 매우 가까운 값으로 근사할 수는 있지만 해당 값을 정확히 알아낼 수는 없습니다.
Reference
