
교재로 처음 접했던 Hash Table은 굉장히 어렵게만 느껴졌다.
하지만 하나씩 천천히 뜯어보니 이해할 수 있었다.
다른 입문자 분들도 포기하지말고 끝까지 파헤쳐보았으면 좋겠다.
개념 잡기
Hash Table을 사용하는 이유
우리가 python에서 흔히 사용하는 dictionary가 내부적으로는 hash table을 사용한다고 한다.
hash table이 내부적으로 어떻게 동작하는지 알아보기 전에 사용하는 이유와 이점에 대해서 정리해 보려고한다.

예시 데이터를 어벤져스 히어로와 각 히어로가 쓰는 무기로 구성하였다.
dictionary의 데이터는 key값인 히어로와 value값인 무기가 쌍으로 저장된 구조이고, array는 딱히 구분이 없어보인다.
"토르의 무기는 무엇인가?" 라는 명제를 던져보았다.
array 같은 경우는 토르에 대한 데이터가 나올 때까지 array을 순회할 것이다.
1. 아이언맨 -> key값이 토르인가? -> X
2. 헐크 -> key값이 토르인가? -> X
3. 캡틴 아메리카 -> key값이 토르인가? -> X
4. 토르 -> key값이 토르인가? -> O
네번째 데이터에 도달했을 때 토르가 나왔으니 이 값을 배열에서 꺼내온다.
이와 같은 방식을 '선형 탐색' 이라한다.
선형 탐색의 시간복잡도는 O(n)이 되고, n은 인덱스 번호와 같다.
인덱스 번호 만큼 탐색 및 비교를 시도하기 때문이다.
dictionary는 비교 없이 값에 다이렉트로 접근하기 때문에 시간복잡도가 O(1)이다.
여기서 한가지 의문이 생긴다.
key 값으로 바로 접근한다는 플로우는 이해했는데, 컴퓨터는 어떻게 바로 key를 찾아내는 걸까?
개념 형상화
Hash Table 내부 동작
dictionary에 데이터를 추가하면 아래와 같은 과정이 일어난다.
 1. dictionary 선언 및 데이터 저장
1. dictionary 선언 및 데이터 저장
 2. 해시테이블과 같은 크기의 버킷 배열
2. 해시테이블과 같은 크기의 버킷 배열
dictionacry 선언 시 파이썬이 내부적으로 빈 hash table을 만들고, 같은 크기의 버킷 배열을 생성한다. 여기서 '크기'란 python이 자동으로 지정하는 값이다.
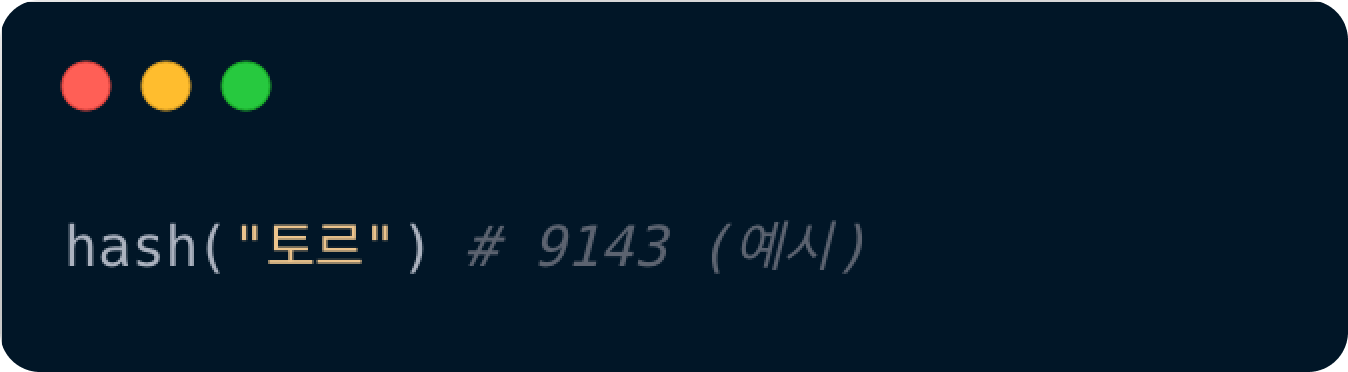 3. hash 함수 실행
3. hash 함수 실행
1번에서 저장한 데이터의 key값인 토르를 hash 함수에 넣고 돌린다.
이 과정을 통해 얻은 정수값이 '9143'은 hash table 크기만큼 나눠준다.
9143 % 8 = 32번 이미지와 같이 크기가 만약 8로 지정되었다면
hash 함수 반환값이 9143을 table 크기인 8로 나누어주는 것이다.
이때, 나머지는 3이 되고 이 숫자가 바로 버킷 배열의 인덱스 넘버가 되는 것이다.
여기서 잠깐 hash 함수가 무엇인지 짚고 넘어가자!
hash 함수는 parameter로 받은 값을 고유한 정수 값으로 반환 해준다.
토르라는 key 값을 여러번 hash 함수로 돌려도 계속 똑같은 정수가 반환된다.
예제와 같이 토르에 '9143'이라는 해시값이 부여되었다면, 토르가 아닌 다른 히어로에게는 절대 '9143'이라는 해시 값이 부여될 수 없다. 한마디로 유니크한 값이라고 이해할 수 있다.
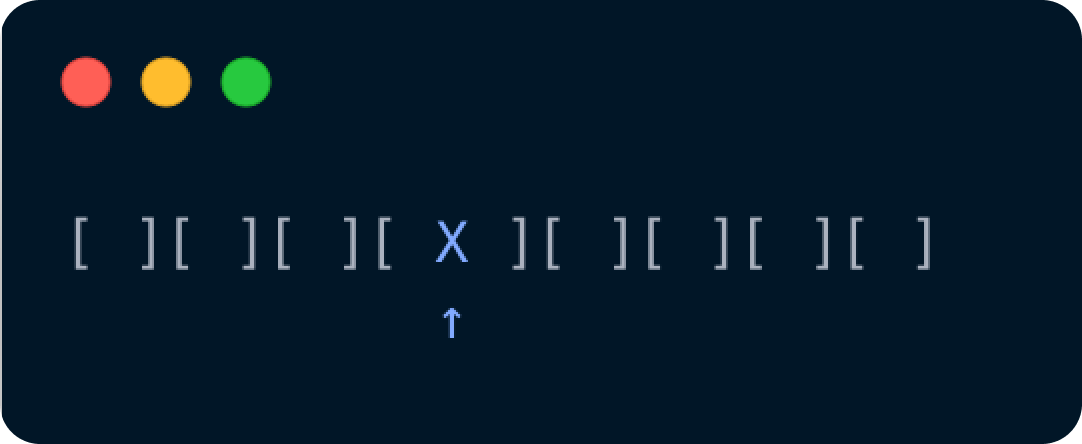 4. 빈자리인지 확인
4. 빈자리인지 확인
이 버킷 배열의 인덱스 넘버가 반환되었다면, 그 인덱스가 빈 자리인지 먼저 확인을 한다.
인덱스 3, 인덱스는 0부터 시작하니까 4번째 자리가 비어있는지 검사한다.
 5. 데이터 할당
5. 데이터 할당
자리가 비어있으니 key, value 값을 저장한다.
정리하자면, dictionary에 값을 넣을 때 python이 자동으로 hash table을 생성하고 내부적으로 처리하는 동작이 있는데,
그 과정은 key 값에 대한 hash를 뽑아내서 인덱스를 계산하고, 인덱스가 빈 칸이면 그대로 저장한다.
Hash Table 충돌 해결
이제 두번째 데이터를 넣어보려한다.
 1. 데이터 저장 + hash 함수 실행 + index 계산
1. 데이터 저장 + hash 함수 실행 + index 계산
 2. 빈 칸인지 확인
2. 빈 칸인지 확인
또 인덱스가 3이 나왔다. 이런 상황을 '충돌이 발생했다'라고 표현한다.
내부적으로는 다음 빈 칸이 비어있는지 탐색하게된다.
이런한 과정을 Open Addressing 이라 칭한다.
 3. 데이터 할당
3. 데이터 할당
인덱스 3이 차있으니까 인덱스 4를 검사하고
인덱스 4가 빈값이니, 5번째 칸에 아이언맨의 데이터를 저장하게 된다.
계속 데이터를 채우다가 hash table이 꽉차게 되면 16칸 32칸 이런식으로 크기를 늘리게된다.
이런 동작을 resize라 하고, 만약resize가 일어나게되면 모든 데이터를 다시 hash하여 재배치하게 된다.
table 크기를 조절하고, 데이터를 재배치하는 과정은 python이 자동으로 해주는 것이다.
서로 다른 value가 같은 key를 가진다면?
이번에 알아본 충돌 해결 방식인 Open Addressing을 썼을 때 단점도 존재한다.
아래와 같은 학생 명단을 dictionary에 저장해보자.

만약에 키값이 학생 이름이라면 어떻게 처리해야할까?
예시와 같이 김민수라는 동명이인이 존재했을 때
김민수의 생일은 최종으로 추가한 10월 12일이 생일인 데이터로 덮어씌워질 것이다.
그래서 이런 것들을 방지하려면 파이썬에서 해시테이블을 직접 구현해서
chaning 충돌 방식을 적용하는 방법도 있겠지만,
간단하게 처리하는 방법으로는 유니크한 값을 키 값으로 사용하는 것이다.
그래서 실무에서는 학번이나 사번 같은 것들을 사용하게 되는 것 같다.
