학부 졸업 이후에는 가짜연구소에서 일정 주기마다 발표하던 논문 리뷰를 제외하면 인공지능 모델의 메커니즘을 이해하거나, 공부하는 일은 거의 없었다. 더 정확히 표현하면, 공부를 해야 할 이유가 없다고 보는 게 맞을 것이다. 언어 모델을 학습하는 것보다는 내가 해결하고자 하는 Task를 잘 수행할 수 있는 LLM을 선택하는 것, 선택한 LLM이 원하는 출력을 뱉을 수 있도록 적절한 프롬프트 엔지니어링을 하는 것, 출력 결과에 대한 적절한 평가와 개선이 이루어지도록 LLMOps를 구성하는 것이 더 중요했기 때문이다. 하지만, 내가 사용하는 모델의 근간을 이루는 Transformer에 대해서 아직까지 수박 겉핥기 식으로 이해를 하고 있다는 사실은 계속 내 마음 한구석을 불편하게 만들었던 것 같다.
그래서 이번 기회에 Transformer 구조에 대한 정리를 해보고자 한다.
1. Attention
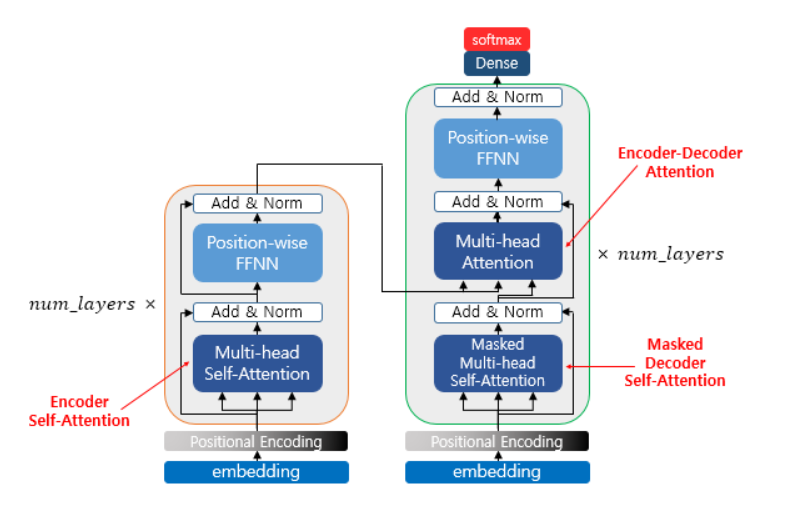
Transformer 모델의 가장 핵심은 attention이다. 사용자가 입력한 문장의 각 단어마다 문장의 모든 단어를 비교하여 어떤 단어에 주의를 기울여야 할지를 결정하고, 최종적으로 문장의 모든 의미와 맥락을 고려한 단어 정보를 표현할 수 있다.
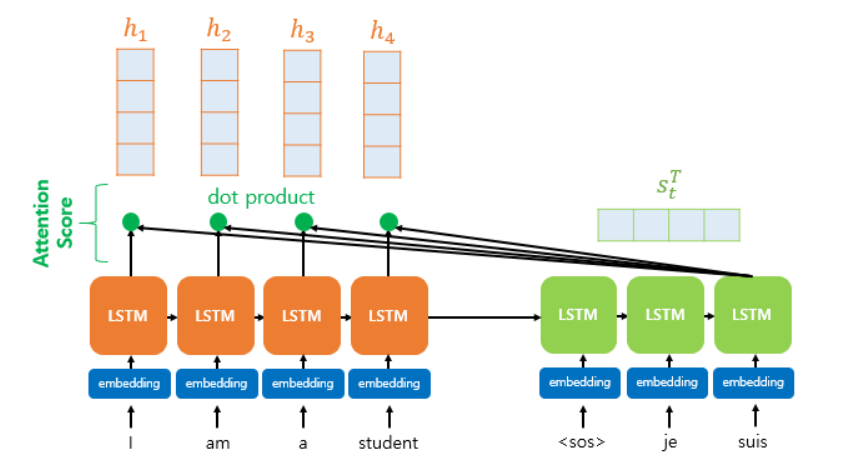
기존의 어텐션 함수는 주어진 쿼리 Q에 대해서 기존의 입력 정보 K와의 유사도를 각각 구한다. 이때 유사도를 구하기 위해서 내적이 이용되고, Attention score가 커지는 것을 방지하기 위해 스케일링을 한 뒤, Softmax를 적용하여 어떤 key를 더 집중해야 할지 확률값으로 표현한다.
마지막으로 기존 입력 정보 V에 위에서 구한 Attention weights를 곱해준다.
즉, Attention은 사용자가 입력한 문장에서 예측을 위해 중요한 단어는 가중치를 크게 부여하고, 그렇지 않은 단어는 가중치를 적게 부여하는 장치인 셈이다.
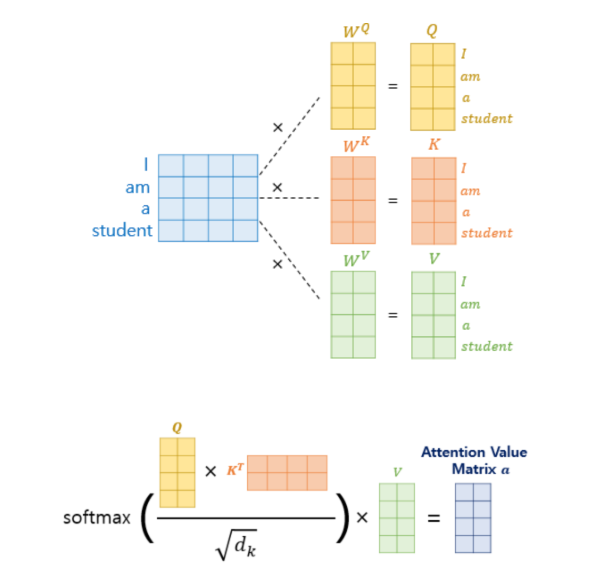
반면, Transformer의 self-attention은 입력 문장 내의 모든 단어들이 서로를 어떻게 주의 하는지를 계산한다. 따라서, 행렬 연산으로 Q, K, V벡터를 한꺼번에 계산하면 I am a student문장에 대한 가중치 정보가 담긴 하나의 Attention Value 행렬이 만들어진다.
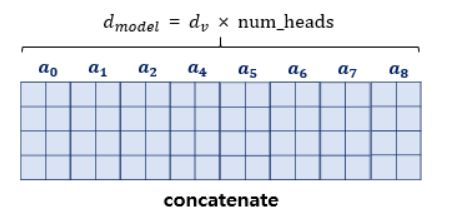
이렇게 각각 다른 관점으로 바라본 단어들에 대한 어텐션 행렬 총 8개를 concatenate한다.
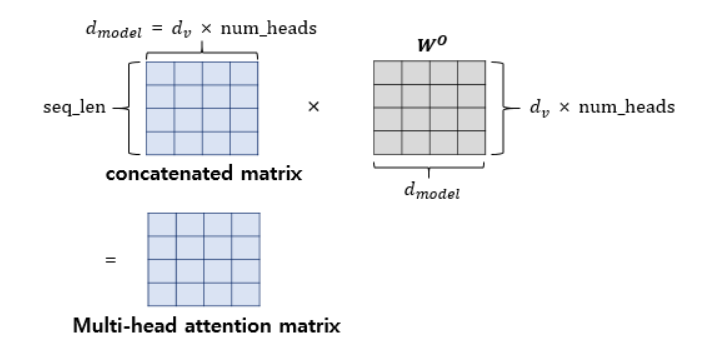
마지막으로 각각의 Attention Head 정보를 다시 하나의 통합된 표현으로 만들기 위해 가중치를 곱해서 최종적으로 attention 행렬이 된다.
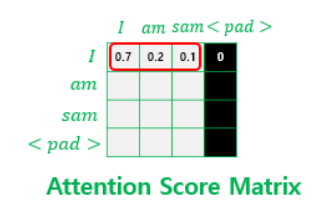
그 외에도 Multi-head Self Attention의 과정에서 입력 토큰이 고정된 길이를 가지도록 하기 위해 패딩 토큰을 사용하게 되는 데, 이 패딩 토큰은 의미가 없는 단어이기 때문에 어텐션 계산 과정에서 배제되어야 한다. 이 패딩값에는 −∞를 곱하여 Softmax 계산 시에 0에 수렴되게 하는 방법을 사용한다.
2. Position-wise FFNN
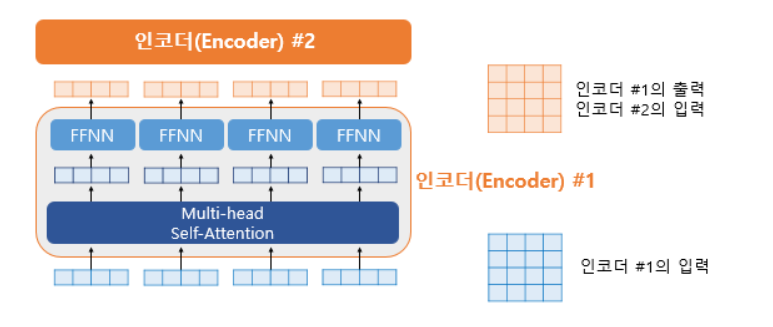
FFNN에서의 특징은 크게 2가지다.
첫 번째는 같은 층의 인코더 안에서는 다른 단어들마다 모두 같은 값으로 가중치와 바이어스가 사용되지만 다른 층의 인코더마다는 다르다. 이는 단어 간의 관계가 아닌 단어 자체의 특징을 강조하게 만드는 효과가 있다.
두 번째는 하나의 비선형 layer를 지나면 의 형태를 유지하기 위해 단순 선형 결합 과정을 다시 한번 거친다는 것.
3. Residual connection, Layer Normalization
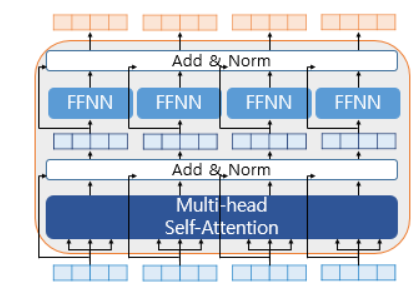
Multi-head Self Attention의 결과와 블록을 거치기 전의 input을 더하고, 이 값에 정규화를 한 값과 FFNN의 결과를 더한 다음 정규화를 해서 하나의 인코더 블록에서 두 번의 Skip connection을 거친다. 확실히 인코더 블록과 디코더 블록이 매우 많고, 학습 층이 깊으므로 안정적인 학습을 위해 사용된듯 하다.
4. Decoder Attention
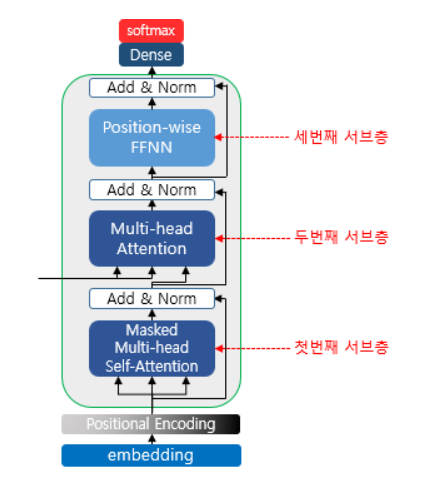
Transformer의 decoder에서는 2번의 Attention을 거치는 데, 첫 번째는 Masked Multi-head self Attention으로 encoder에서 사용된 어텐션과의 차이는 오로지 현재 시점에서 예측하고자 하는 단어를 참고하지 못하도록 패딩값과 마찬가지로 극미함수를 곱한다 .
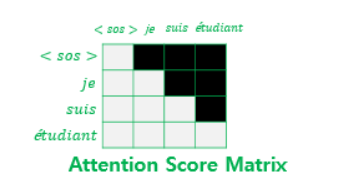
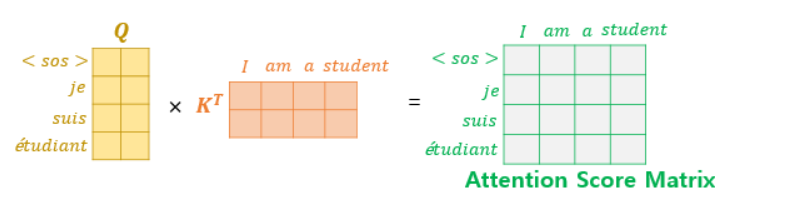
두 번째 Attention은 Q를 Masked Attenton score matrix로, K와 V는 인코더의 Attention score matrix로 계산을 수행한다.
5. Positional encoding
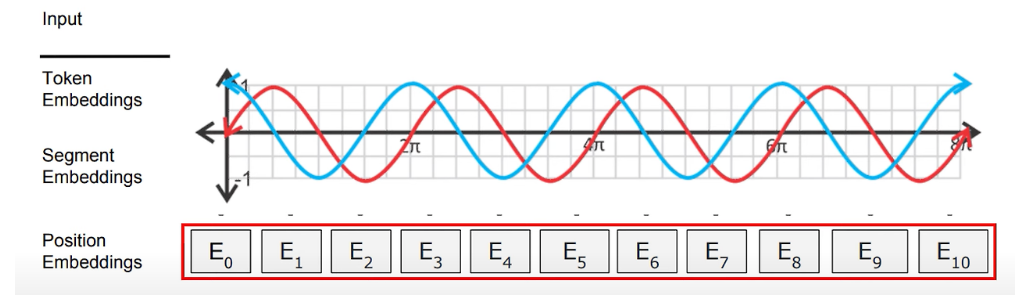
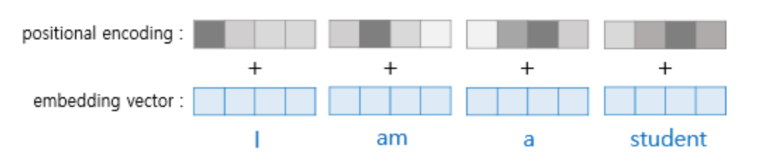
포지셔널 인코딩은 이해가 어려웠던 부분이다.
우선, self-attention은 양방향으로 모든 토큰과의 attention을 계산하기 때문에 단어의 순서는 무시된다. 따라서, 이 단어가 몇 번째 순서인지 포지셔닝을 해줘야할 필요가 있다. 이 포지셔닝은 사인과 코사인 함수와의 거리에 따라서 특정 위치의 인코딩 값이 이전 위치의 값과 일정한 관계를 유지된다고 한다.
여기서 한 가지 드는 의문점은, 위 사진과 같이 반복되는 주기가 계속되면 결국 포지셔닝도 특정 토큰마다 겹치는 게 아닌가? 하는 생각이 들었는데 이 문제를 방지하기 위해 사용자가 입력할 수 있는 최대 길이. 즉, 모델의 최대 차원을 기준으로 함수를 스케일링함으로서 해결한다고 한다.
6. 소감
트랜스포머의 핵심은 크게 2가지라고 생각한다.
첫 번째는 문장의 의미를 파악하기 위한 어텐션 계산을 self-attention을 통해 병렬로 처리하여 훈련과 추론 속도를 비약적으로 향상시켰다는 것.
두 번째는 기존의 잔차 학습, 정규화를 통해 인코더와 디코더 블록을 여러 개 쌓고, self-attention 특성 상 문장의 모든 토큰의 관계를 고려하기 때문에 속도뿐만 아니라 정확도까지 높을 수밖에 없는 구조라는 것.
계속 볼 때마다 정말 엄청나다는 생각밖에 들지 않는 논문이다..
