[논문 리뷰] How to Make your LLMs use External Data More Wisely : Level4 Hidden Rationale Queries
0
RAG and Beyond
목록 보기
4/4
6 Hidden Rationale Queries (L4)
6.1 Overview
- 질문 근거가 숨겨진 경우는 그 근거가 명시적으로 설명되지 않았을 뿐더러, 그 탐색 범위도 매우 다양하기 때문에 답변이 어려움. 보통 도메인 전문성이 필요한 질문이 이에 해당 됨.
- 이런 유형의 질문에 답변하기 위해서는 도메인 데이터와 LLM의 사전 지식을 활용하는 것이 필요.
- Level4의 질문 예시
- 경제 상황이 회사의 미래 발전에 어떤 영향을 미칠 것인가? (재무 보고서 모음이 주어지고, 경제 및 재무 근거가 필요함)
- 5, 5, 5, 1이라는 숫자를 사용하여 24점을 달성하는 방법은? (24점 게임 예시 시리즈와 해당 답안이 주어짐)
- 아프가니스탄은 부모가 해외에서 태어난 자녀에게 시민권을 부여하는 것을 허용하는가? (GLOBALCIT 시민권법 데이터셋이 주어짐)
6.2 Challenges and Solutions
- 논리적 검색 : L4 수준의 질문은 근거가 명시적으로 나타나지 않아 기존의 dense retriever, sparse retriever를 통한 검색은 의미가 없고, 답변에 도달하기까지 어떤 논리적인 추론을 해야할지, 추론을 하기 위한 주제(관점)은 어떻게 잡아야 할지가 더 중요함.
- 데이터 부족 : 관련 정보를 few-shot이나, 도메인 설명을 통해서 보충해야 함. (합성 데이터에 대한 니즈)
6.3 Offline learning
-
여기서 Offline learning은 데이터셋에서 규칙과 instruction을 직접 추출해서 관련 항목을 검색할 수 있도록 사전에 준비해두는 것을 말함.
-
STaR: Bootstrapping Reasoning With Reasoning :
- 소수의 추론 예시를 사용해 많은 문제에 대한 근거(rationale)를 생성
- 생성된 답변이 틀렸다면, 정답이 주어진 상태에서 다시 근거를 생성
- 최종적으로 정답을 도출한 모든 근거들에 대해 파인튜닝
- 개선된 모델로 다시 반복
정리하면, LLM을 이용해서 올바른 근거를 사용해 답변을 도출한 데이터만을 파인튜닝 데이터로 학습시키는 과정을 반복
-
Can Generalist Foundation Models Outcompete Special-Purpose Tuning? Case Study in Medicine:
- Dynamic Few-shot Selection: 질문과 유사한 훈련 예시를 동적으로 선택
- Self-generated Chain of Thought: CoT및 가드레일을 자동으로 생성
- Choice-shuffle Ensembling: 답변 선지를 셔플링
정리하면, 유사한 사용자의 질문과 유사한 질문, 추론, 답변을 퓨샷으로 넣어 어떻게 추론해야 하는지 LLM에게 알려주고, 셔플링을 통해 답변 선지의 편향을 줄임
6.4 In-context learning
- Self-Consistency Improves Chain of Thought Reasoning in Language Models :
- 동일한 질문을 여러 번 실행: 같은 프롬프트로 여러 개의 답변 생성
- 다양한 추론 경로 수집: 각각 다른 사고 과정을 거쳐 답변 도출
- 다수결 투표: 가장 많이 나온 답변을 최종 선택
6.5 Fine-tuning
- LoRA, promt tuning 기법을 활용한 chatDoctor, finGPT, LawLLM 등의 특정 도메인에 맞춘 파인튜닝
7 Conclusion
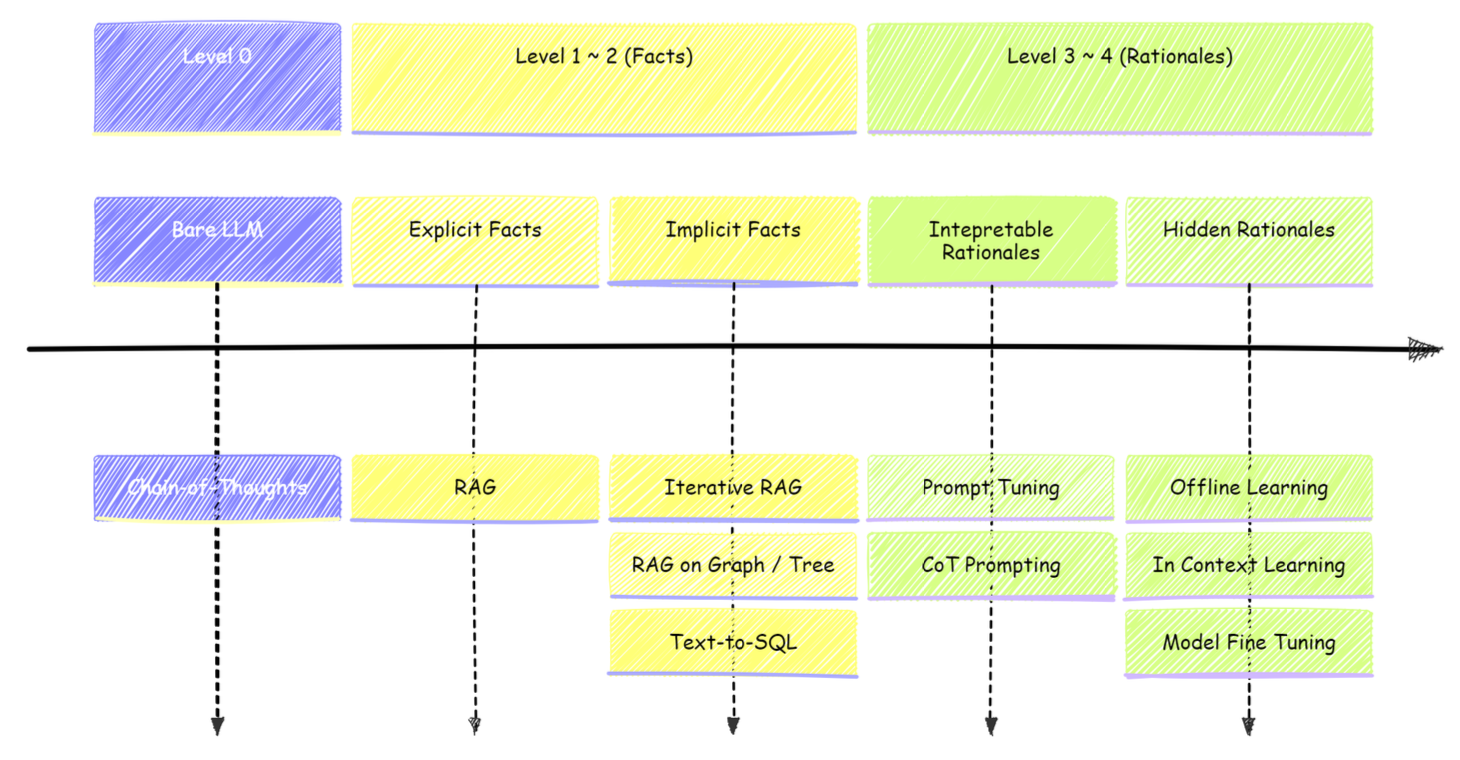
- 일반적인 지식은 CoT 방법론을 이용하여 배포
- 명시적 사실 질문은 일반적인 RAG를 사용
- 암시적 사실 질문은 Graph 및 Tree 구조의 RAG 사용
- 해석 가능한 근거가 있는 질문은 프롬프트 튜닝과 CoT 프롬프팅이 필요
- 근거가 숨겨진 질문은 offline learning, in-context learning, fine tuning이 필요
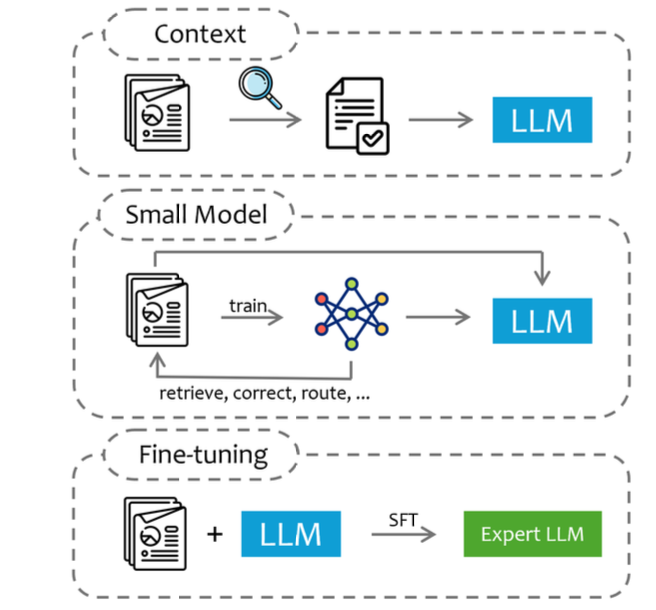
주어진 자원과 해결할 문제를 고려해서 위와 같은 3가지 기술적 접근법을 적절히 선택해야 함
1. 쿼리를 기반으로 도메인 데이터의 일부를 추출하여 LLM 컨텍스트에 입력으로 사용
2. 특정 도메인 데이터로 small model을 학습시켜 추론, 관련 정보 추출, 가이드라인 생성, 검증, 분기 로직 등에 사용
3. 미세조정

한 걸음씩 꾸준하게