[Computer Vision] 딥러닝 시각화 (Feature Visualization vs Activation Map vs Grad-CAM)
deeplearning
혹시 딥러닝 관련 논문이나 자료에서 이런 이미지를 보신 적이 있나요?

그림 1. Feature Visualization - CNN의 층이 깊어질수록 추출되는 특징이 단순한 선에서 구체적인 얼굴 형태로 변해가는 과정
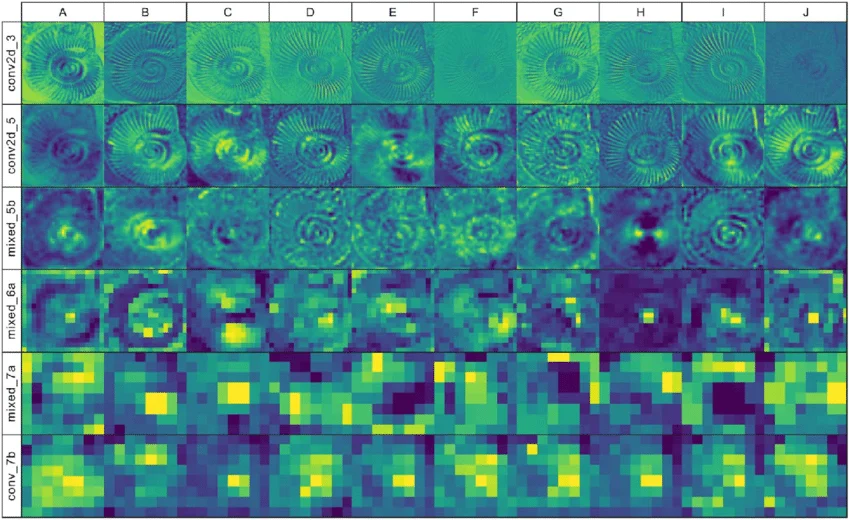
"그림 2. 입력 이미지에 따른 계층별 Feature Map(Activation Map) 시각화. 층이 깊어질수록 해상도가 낮아지며 정보가 추상화(Abstracted)되어 가는 과정."
그림 1을 보면 한 가지 의문이 생깁니다. 보통 "딥러닝은 데이터를 압축하고 추상화하는 과정 (그림2)"이라고 배우는데, 왜 이 그림은 뒤로 갈수록 추상적이기는커녕 우리 눈에 더 선명한 '얼굴'로 변해가는 걸까요? 원본 데이터에 더 가까워지는 것처럼 보이지 않나요?
오늘 포스팅에서는 이 직관적인 의문을 수학적 원리와 함께 명쾌하게 풀어보겠습니다. 그리고 많은 분들이 혼동하는 Activation Map, Feature Visualization, 그리고 Grad-CAM의 결정적인 차이까지 완벽하게 정리해 드릴게요.
1. 직관의 오류: 추상화 vs 표현의 구체화
우리가 흔히 오해하는 것 중 하나는 '추상화 = 형체가 뭉개짐'이라고 생각하는 것입니다. 하지만 딥러닝에서, 특히 합성곱 신경망(CNN)에서 깊은 층으로 갈수록 일어나는 일은 '개념의 구체화'에 가깝습니다.
계층적 특징 학습 (Hierarchical Feature Learning)
CNN은 레고 블록을 쌓듯이 학습합니다.
- 저층 (Low-level): 점, 선, 대각선 등 아주 단순한 에지(Edge) 패턴을 찾습니다. (블록 하나)
- 중층 (Mid-level): 앞선 선들을 조합해 눈, 코, 입 모양 같은 부분적 형태를 인식합니다. (블록 결합)
- 고층 (High-level): 부분들을 다시 조합해 '얼굴 전체'라는 복합적인 객체의 개념을 완성합니다. (완성된 작품)
질문하신 그림은 바로 이 '모델의 머릿속에 완성되어 가는 개념'을 꺼내서 보여준 것입니다. 모델의 지식이 깊어질수록 더 복잡하고 구체적인 형태(예: 얼굴)를 다루게 되므로, 이를 시각화하면 뒤로 갈수록 더 원본(전체 객체)에 가까운 정교한 그림이 나오는 것입니다.
2. 수학으로 보는 차이: Activation Map vs Feature Visualization
여기서 가장 중요한 개념을 정리해야 합니다. 많은 분들이 필터(가중치) 값을 보여주는 것이라고 뭉뚱그려 생각하지만, 둘은 수학적으로 완전히 다른 대상을 바라봅니다.
① Feature Visualization (특징 시각화): "네가 생각하는 이상형은 뭐니?"
그림 1. Feature Visualization - CNN의 층이 깊어질수록 추출되는 특징이 단순한 선에서 구체적인 얼굴 형태로 변해가는 과정
입력 사진(사람이 찍은 실제 사진(고양이, 자동차 등))이 필요 없습니다. 대신, 모델의 가중치()를 고정시킨 채, 특정 뉴런의 활성값을 최대화하는 가상의 입력 이미지 를 찾아내는 과정입니다.
- 목적 함수:
- 최적화 대상: 입력
- 아무 의미 없는 랜덤 노이즈에서 시작해, 모델을 만족시키기 위해 수정(Optimization)해나감
- 핵심 지표: 활성값 를 최대화하기 위한 이미지의 변화량()
- 수학적 흐름:
- 임의의 노이즈 이미지 를 투입합니다.
- 특정 레이어 의 번째 필터 활성값 를 구합니다.
- 이 활성값을 높이기 위해 이미지의 각 픽셀을 미분합니다:
- 픽셀 값을 업데이트합니다:
- 결과: 모델 내부의 필터가 '가장 선호하는 패턴'이 이미지 형태로 형상화됩니다.
- 노이즈였던 이미지가 점점 모델이 좋아하는 '눈', '코', '얼굴' 형태로 변해갑니다.
- 깊은 층일수록 수용 영역(Receptive Field)이 넓어지기 때문에, 더 넓고 복잡한 '얼굴 전체' 구조를 그려내게 되는 것입니다.
단계별 생성 과정 (Gradient Ascent)
모델의 가중치()를 업데이트하는 일반적인 학습과 달리, 여기서는 가중치를 고정하고 입력 이미지()를 업데이트합니다.
- 초기화 (Initialization): 아무런 형태가 없는 랜덤 노이즈 이미지 를 투입합니다.
- 활성값 계산 (Forward): 특정 레이어 의 번째 필터 활성값 를 구합니다. (처음엔 노이즈이므로 매우 낮은 값이 나옵니다.)
- 이미지 미분 (Gradient): 이 활성값을 높이기 위해 이미지의 각 픽셀을 어떻게 바꿔야 할지 계산합니다:
- 픽셀 업데이트 (Update): 계산된 방향으로 픽셀값을 조금씩 수정합니다:
- 반복 (Iteration): 이 과정을 수백 번 반복하면, 모델 내부의 필터가 '가장 선호하는 패턴'이 이미지 형태로 형상화됩니다.
왜 뒤로 갈수록 구체적인 얼굴이 나올까?
그림 1(얼굴 그림)에서 층이 깊어질수록 원본에 가까워지는 이유는 뉴런의 책임 범위 때문입니다.
- 낮은 층의 뉴런: 아주 좁은 영역만 보기 때문에 "대각선 하나만 있으면 돼!"라고 반응합니다. 그래서 시각화 결과도 단순한 선으로 나타납니다.
- 깊은 층의 뉴런: 수용 영역(Receptive Field)이 이미지 전체를 아우를 만큼 넓습니다. 이 뉴런을 만족시키려면 단순한 선이 아니라 눈, 코, 입이 조화롭게 배치된 '얼굴 전체' 구조가 필요합니다. 따라서 수학적으로 최적화된 결과물 가 훨씬 구체적인 형태를 띠게 됩니다.
② Activation Map (활성 지도): "이 사진 어디에 반응했니?"
"그림 2. 입력 이미지에 따른 계층별 Feature Map(Activation Map) 시각화. 층이 깊어질수록 해상도가 낮아지며 정보가 추상화(Abstracted)되어 가는 과정."
Activation Map은 모델의 지식을 묻는 것이 아니라, 특정 입력 데이터()가 모델을 통과할 때 각 층(Layer)의 필터들이 "여기 내가 좋아하는 거 있다!"라고 반응한 흔적을 시각화한 것입니다.다시 말해, 입력 사진이 모델을 통과할 때, 각 층의 뉴런들이 어디서 크게 반응(Activation)했는지를 보여줍니다.
- 목적함수 :
- 입력(): 실제 사진 (예: 암모나이트, 고양이)
- 상수(Constant)이며 연산 과정에서 변하지 않습니다.
- 최적화 대상: 없음 (수동적 관찰)
- 핵심 지표: 특정 입력 에 의해 결정된 활성값 (i.e. 입력에 반응하여 생성된 특징값(Feature value, ))
- 의미: "주어진 사진 가 필터 를 통과했을 때, 최종적으로 어떤 숫자()들이 찍혀 나왔는가?"
- 결과: 입력 사진의 특정 패턴(선, 질감, 형태)이 강조된 히트맵.
- 층이 깊어질수록 해상도가 낮아지고 정보가 요약되어 점차 추상적인 점들로 변합니다. (우리가 흔히 생각하는 '뭉개지는' 과정)
단계별 생성 과정 (Forward Pass)
Feature Visualization이 반복적인 최적화(Iterative) 과정이라면, Activation Map은 단 한 번의 순전파(Single Forward Pass)로 결정됩니다.
- 데이터 투입 (Input): 실제 세계의 데이터 를 모델의 입력층에 넣습니다. (예: 크기의 컬러 사진)
- 특징 추출 (Extraction): 학습된 필터()가 이미지 위를 슬라이딩하며 연산을 수행합니다.
- 저층 필터가 대각선을 찾는 필터라면, 사진 속 대각선이 있는 위치의 값이 커집니다.
- 차원 축소 (Downsampling): 풀링(Pooling)이나 스트라이드(Stride) 연산을 거칩니다.
- 이 과정에서 연산 효율을 위해 해상도가 강제로 줄어듭니다 ().
- 시각화 (Rendering): 계산된 값(Feature 값)을 이미지 형태로 출력합니다. 보통 값이 클수록 밝은 노란색, 작을수록 어두운 보라색으로 표현합니다.
왜 뒤로 갈수록 '뭉개지는' 것처럼 보일까? (수학적 이유)
- 공간 정보의 손실 (Spatial Compression): 층을 거칠수록 픽셀 수가 줄어듭니다. 크기의 마지막 맵에서는 더 이상 섬세한 암모나이트의 무늬를 표현할 공간이 없습니다.
- 의미론적 추상화 (Semantic Abstraction): 수학적으로 깊은 층의 값은 "여기에 선이 있다"가 아니라 "이 근처 어딘가에 암모나이트라는 개념이 존재한다"라는 고차원적인 정보를 담습니다. 즉, '시각적 디테일'을 버리고 '클래스의 정체성'을 선택한 결과입니다.
| 비교 항목 | Feature Visualization (얼굴 그림) | Activation Map (암모나이트 그림) |
|---|---|---|
| 핵심 질문 | "너(모델)는 뭘 알고 있니?" | "이 사진()의 어디를 보고 있니?" |
| 수학적 타겟의 차이 | (픽셀 수정) | (중요도 측정) |
| 결과물의 방향성 | 이미지 생성 - 구체화(Synthesis) | 정보 압축 - 추상화(Abstraction) |
| 이미지 | 변수. 노이즈에서 정답지로 최적화. | 상수. 실제 사진을 그대로 사용. |
| 가중치 | 고정 (지식의 근원) | 고정 (분석의 도구) |
| 변화 양상 | 뒤로 갈수록 구체적 (개념 완성) | 뒤로 갈수록 추상적 (정보 압축) |
3. Grad-CAM은 또 뭐가 다를까?
여기에 또 다른 시각화 기법인 Grad-CAM이 등장하면 더 혼란스러워집니다. 결국 두 기법 모두 경사도(Gradient)를 사용하지만, 그 미분값이 향하는 대상이 다릅니다. '무엇을 고정하고(Constant)', '무엇을 미분하여 업데이트(Optimize)' 하는지 수학적 관점에서 명확히 비교해 드릴게요.
Feature Visualization (이미지 생성)
- "이미지() 공간"에서의 최적화입니다. 미분을 통해 존재하지 않던 이미지를 빚어내는 조각 과정입니다.
- 의 상태: 변수 (Variable). 노이즈에서 시작해 점점 '정답지'로 변해감.
- 수식:
- 결과: 존재하지 않던 새로운 이미지 가 탄생함.
Grad-CAM (영역 표시)
- "특징() 공간"에서의 가중치 계산입니다. 이미 나온 결과물을 두고 어떤 특징이 기여했는지 지분을 나누는 회계 과정입니다.
- 의 상태: 상수 (Constant). 사람이 준 실제 사진이며, 절대 변하지 않음.
- 수식:
- 결과: 사진 위 어디가 중요한지 나타내는 '지도(Map)'가 나옴.
Grad-CAM은 일종의 설명 가능한 AI(XAI) 기법입니다. "이 모델이 이 사진을 보고 '고양이'라고 판단했다면, 사진의 어느 부분이 결정적이었니?"를 보여줍니다.
Grad-CAM: 특징 맵(Feature Map)의 기여도 계산
Grad-CAM은 이미 존재하는 특정 입력 사진 에 대해, 모델이 내린 결론(클래스 점수 )이 어떤 특징 맵() 덕분인지 가중치()를 구하는 기법입니다.
- 목적 함수:
- 최적화 대상: 없음 (이미지 와 가중치 모두 고정)
- 수학적 흐름:
- 실제 사진 를 넣어 클래스 에 대한 점수 를 얻습니다.
- 마지막 컨볼루션 레이어의 번째 특징 맵 가 점수 에 얼마나 기여하는지 미분합니다:
- 이 미분값을 전역 평균 풀링(GAP)하여 특징 맵의 중요도 가중치 를 구합니다.
- 이 를 각 특징 맵에 곱해 선형 결합한 뒤 ReLU를 씌워 히트맵을 만듭니다.
- 결과: "고양이 점수를 높이는 데 이 특징 맵들이 이만큼 기여했어"라는 영역 표시가 나옵니다.
요약 및 결론
| 비교 항목 | Feature Visualization (얼굴 그림) | Activation Map (암모나이트 그림) | Grad-CAM (영역 표시) |
|---|---|---|---|
| 분석 성격 | 생성 및 합성 (Synthesis) | 단순 관찰 (Observation) | 사후 해석 (Attribution) |
| 미분 대상 (Denominator) | 입력 이미지의 픽셀 () | 없음 (미분하지 않음) | 특징 맵의 활성값 () |
| 최적화 루프 | 여러 번 반복 (Iterative) | 단 한 번의 연산 (Forward Pass) | 단 한 번의 연산 (Single Pass) |
| 입력 의 존재 | 를 노이즈에서 만들어냄 | 주어진 를 투입함 | 주어진 를 고정함 |
| 주요 연산 | |||
| 변화 양상 | 뒤로 갈수록 구체화 (개념 완성) | 뒤로 갈수록 추상화 (정보 압축) | 뒤로 갈수록 집중됨 (중요 부위) |
- Activation Map 열을 보시면 '미분 대상'이 없습니다. 이는 모델을 학습시키거나 수정하는 과정 없이, 데이터가 흐르는 길목(레이어)에서 그저 결과값 를 가로채서 보여주기 때문입니다.
- 반면 Feature Visualization은 "어떤 가 들어와야 가 커질까?"를 알아내기 위해 방향으로 미분을 수행하며 이미지를 깎아 나갑니다.
- Grad-CAM은 "이미 나온 결과 가 어떤 덕분일까?"를 알기 위해 방향으로 미분하여 기여도(지분)를 계산합니다.
- Feature Visualization: 고정, 를 변수로 둠 가 커지도록 를 계속 업데이트 (생성)
- Activation Map: 고정, 고정 를 계산해서 보여줌 (관찰)
- Grad-CAM: 고정, 고정 최종 점수 에 대한 의 기여도(지분)를 계산해서 보여줌 (해석)
