"딥러닝은 '가중치() 곱하기'와 '활성화() 함수'라는 두 개의 릴레이 바톤을 서로 다른 층(Layer)에 걸쳐 무한히 이어가는 과정입니다."
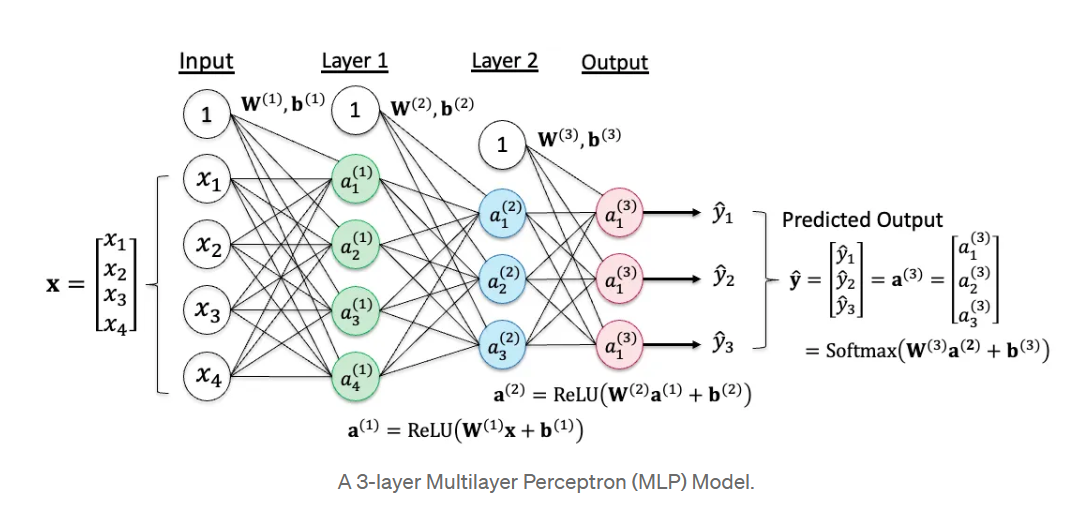
이 모델은 데이터를 받아서 예측값()을 내놓기까지, 서로 다른 3개의 함수(Layer)가 꼬리에 꼬리를 무는 합성함수 구조입니다.
- '층(Layer)'을 세는 국제 표준: 가중치(Weight) 기준딥러닝에서 레이어를 셀 때는 데이터를 담는 '노드 층'이 아니라, 데이터를 변형시키는 '파라미터(가중치) 층'을 기준으로 합니다.
- 첫 번째 가중치 뭉치 (): Input Layer 1 사이 (1층)
- 두 번째 가중치 뭉치 (): Layer 1 Layer 2 사이 (2층)
- 세 번째 가중치 뭉치 (): Layer 2 Output 사이 (3층)
즉, 변환(Transformation)이 세 번 일어나기 때문에 3-Layer라고 부르는 것입니다.
'학습 가능한 층'만 세여 입력층은 학습하지 않으므로 제외합니다.
- 각 레이어의 노드 개수:
- 입력층 (Input Layer): 데이터를 받는 곳입니다. 바이어스 노드(1)를 제외하고 4개의 입력()이 있습니다.
- 레이어 1 (Hidden Layer 1 - 초록색): 데이터를 특징으로 변환하는 첫 번째 층입니다. 4개의 노드()로 구성됩니다.
- 레이어 2 (Hidden Layer 2 - 파란색): 더 복잡한 추상적 특징을 추출하는 두 번째 층입니다. 3개의 노드()로 구성됩니다.
- 출력층 (Output Layer - 빨간색): 최종 예측 결과를 내놓는 곳입니다. 우리가 분류하려는 클래스의 개수와 같은 3개의 노드()로 구성됩니다.
| 레이어 이름 | 수학적 인덱스 | 노드 개수 (바이어스 제외) | 특징 |
|---|---|---|---|
| Input Layer | Layer 0 (보통 안 침) | 4개 () | 입력 데이터 그 자체 (함수 연산 없음) |
| Hidden Layer 1 | Layer 1 | 4개 () | 첫 번째 함수 의 결과물 |
| Hidden Layer 2 | Layer 2 | 3개 () | 두 번째 함수 의 결과물 |
| Output Layer | Layer 3 | 3개 () | 세 번째 함수 의 결과물 (예측값) |
많은 분이 중간에 있는 'Hidden Layer'의 개수만 세어 이 모델을 2층이라고 생각하곤 합니다. 하지만 딥러닝에서 레이어의 숫자는 '데이터가 가중치()라는 필터를 몇 번 통과하느냐'를 의미합니다.
이 모델에서는 입력 데이터가 출력층에 도달하기까지 총 3번의 선형 결합(내적)과 활성화 함수를 거칩니다. 따라서 수학적으로는 3개의 함수가 중첩된 구조, 즉 3-Layer 모델이 정답입니다!
2. 그림의 수학적 표기법 (Notation)
블로그 글에 이 표를 복사해서 넣으면 독자들이 수식을 읽는 데 큰 도움이 됩니다.
| 표기 (Notation) | 정체 | 해석 (Interpretation) |
|---|---|---|
| 입력 벡터 | 모델에 들어가는 4차원 원본 데이터 ()입니다. | |
| 활성화 벡터 | 번째 레이어를 통과한 결과물(Activation)입니다. | |
| 가중치 행렬 | 번째 레이어의 입력과 출력을 연결하는 '지식'입니다. (선들의 집합) | |
| 바이어스 벡터 | 번째 레이어에 더해지는 '고정 편향'입니다. (그림에서 '1' 노드) | |
| ReLU | 활성화 함수 | 데이터를 비선형으로 변환하는 함수입니다. (가 0보다 작으면 0, 크면 그대로) |
| Softmax | 최종 활성화 함수 | 출력값을 0~1 사이의 확률값으로 변환하여 합이 1이 되게 만듭니다. |
| 예측값 벡터 | 모델이 최종적으로 내놓은 예측 확률()입니다. |
3. 수학적 관계 해석 (Forward Pass)
1. 노드 하나는 '벡터 내적'의 결과물입니다
그림에서 Layer 1의 초록색 노드 을 자세히 보세요. 입력층의 모든 노드()에서 선이 들어오고 있죠? 이 선 하나하나가 바로 가중치()입니다.
이 관계를 인덱스를 써서 내적으로 표현하면 다음과 같습니다.
- ① 선형 결합 (Linear Combination)
먼저 활성화 함수를 통과하기 전의 값()을 구합니다.- : 번째 입력값 (데이터)
- : 번째 입력이 1번 레이어의 1번 노드로 갈 때 곱해지는 가중치
- : 1번 레이어의 1번 노드에 더해지는 바이어스
- ② 비선형 활성화 (Non-linear Activation)
2. 레이어 전체로 확장하기 (General Form)
-
이를 일반화해서 번째 레이어의 번째 노드가 출력하는 값 를 정의합니다.
-
- : 이전 레이어의 노드 개수
- : 이전 레이어의 번째 노드에서 보내온 신호
- : 이전 레이어의 번째 노드에서 현재 레이어의 번째 노드로 연결된 가중치
- : 활성화 함수 (ReLU, Softmax 등)
-
MLP 3-Layer
그림에 나온 수식을 벡터 내적 관점으로 '체인 룰'을 다시 쓰면 이렇습니다.
① 입력층 레이어 1 (초록색) ():
- 원본 데이터 에 가중치 행렬 을 곱하고 바이어스 를 더합니다. (선형 연산)
- 그 결과에 비선형 활성화 함수인 ReLU를 씌워 첫 번째 특징 벡터 을 만듭니다.
② 레이어 1 (초록색) 레이어 2 (파란색) ():
- Output Layer ():
- 1층의 결과물 을 입력으로 받습니다.
- 여기에 다시 가중치 와 바이어스 를 연산하고, ReLU를 씌워 더 고차원적인 특징 벡터 를 만듭니다.
③ 레이어 2 (파란색) 출력층 (빨간색)():
-
-
최종 단계입니다. 2층의 결과물 에 가중치 와 바이어스 를 연산합니다.
-
마지막으로 활성화 함수를 ReLU가 아닌 Softmax를 사용합니다. 이는 결과물()을 "이 데이터가 1번 클래스일 확률은 70%, 2번은 20%..."와 같이 확률로 해석하기 위해서입니다.
왜 '내적'으로 이해하는 게 중요한가요?
"벡터 내적은 두 벡터의 '유사도'를 측정하는 도구입니다."
- 가중치 벡터()를 하나의 '필터(Pattern)'라고 생각해보세요.
- 입력 데이터()가 들어왔을 때, 가중치와 데이터의 내적값이 크다는 것은 "내가 찾던 패턴이 데이터에 들어있다!"라고 노드가 외치는 것과 같습니다.
- 결국 딥러닝은 수많은 가중치 벡터()들을 조정하여, 데이터 속에 숨겨진 다양한 패턴들을 가장 잘 찾아내도록 내적의 결과값을 최적화하는 과정인 셈입니다.
