배경
Django를 풀스택 프레임워크가 아닌 React와 함께 사용하는 벡엔드 스텍으로만 사용할 때 헷갈리는 시리얼라이저에 대해 정리하고자 작성하였습니다. 여기서 다루는 시리얼라이저는 보통 Django를 API 서버로 사용할 때, DRF(Django REST framework)라고 불리는 범용적인 플러그인 내부에 구현된 클래스입니다.
여기에 회사 내부적으로 Dataclasses serializer 라는 것을 사용해서 장고에 서비스 아키텍처를 도입해서 사용했을때의 사용법에 대해 간단히 정리해 봅니다.
시리얼라이저의 정의
내가 가지고 있는 데이터(json, excel 등)을 네트워크상의 정보로 보내기 위해서는 string(Byte) 으로 변환하여 송신해야합니다. 이는 네트워크상의 정보가 01010110 등의 이진배열(binary)로 전달이 되기 때문입니다. 이러한 형태가 '연속물로 출판하다' 와 같은 행위와 비슷하여 serialize 라는 어원을 쓰지 않았나 추측해봅니다.
한 마디로 줄인다면 일정한 규칙에 의해 데이터를 일련의 바이트로 변형하는 작업이다. 라는 정의가 가장 이해하기 편할 것 같습니다. 역직렬화(deserialize)는 다시금 이러한 string 을 수신부 측에서 받아, 원래가지고 있었던 형태인 json, excel, table 의 형태로 바꾸는 작업이라 할 수 있겠습니다.
FE가 JS를 사용하고, BE가 JAVA, Python 등을 사용할때, 메모리에 있는 두 언어의 객체 표현방식은 분명히 다릅니다. 그러나 FE, BE를 오가는 통신은 모두 HTTP 프로토콜에서 string 방식으로 표현되기 때문에 통신이 가능합니다. 따라서 네트워크로 전송하기 위해 serialize 를 사용하고, 이를 다시 언어의 클래스나 자료구조로 변경할 때 de-serialize 를 이용합니다.
시리얼라이즈 과정
그렇다면, 네트워크 상에 가까워질수록 (Request, Response) 시리얼라이즈가 진행되고, 반대로 언어자체에 가까워질수록 (Model, class) 역직렬화가 진행된다 표현할 수 있겠습니다.
장고는 MTV라는 기존의 MVC 디자인패턴과 유사한 아키텍처를 사용합니다. 다만 API 벡엔드 서버를 만드는데 사용될 경우에는 Template을 생각하지 않기 때문에 2계층인 MV라고 봐도 무방합니다. Spring이나 rails에 익숙하셨던 분들이라면 view라는 단어를 사용하는 것이 헷갈림을 유발하기에, 이 글에서는 범용적으로 쓰이는 controller 라고 명명하여 표기하겠습니다.
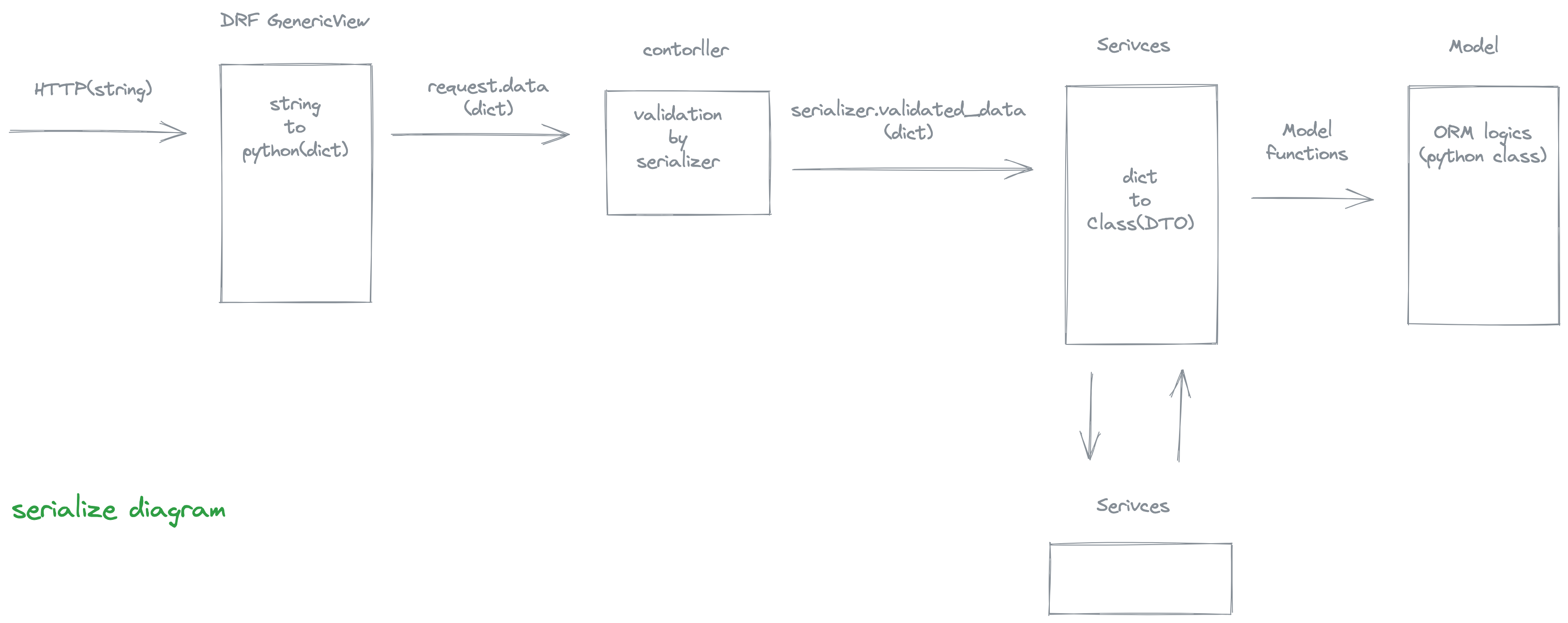
또한, 2계층으로는 로직 분리가 어렵기 때문에, service 계층을 도입하여 3계층 구조를 도입하였습니다. 이에 전체적인 시리얼라이즈 다이어그램은 아래와 같습니다.
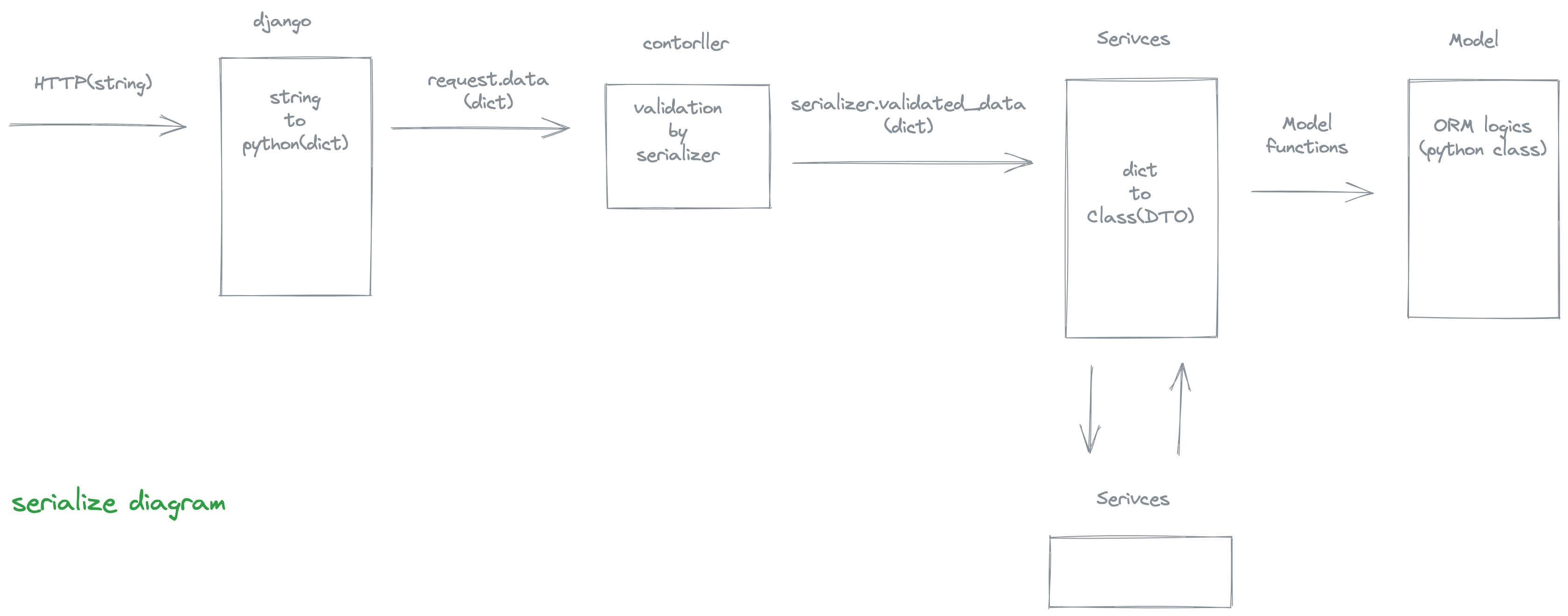
- drf를 사용한다면, json으로 보내 들어오는 데이터는 request.data로 확인할 수 있습니다.
- drf의 serializer는 순수
Serializer와ModelSerializer클래스가 있습니다.Serializer클래스로 json->json validation 하는 과정을 살펴봅니다. Serializer클래스는__init__시instance,data를 parameter 로 가집니다. instance는 python(class) 형태를, data는 python(dict)로 받아 객체를 생성합니다. 우리는 serialize 과정에 있으므로, 보통 data 에 arugment 를 주어 사용합니다.Serializer는 request.data를 받아 사용할 때.is_valid()를 거쳐야 안전합니다..is_valid()함수를 사용하면 멤버 속성으로.validated_data를 사용할 수 있습니다.- 서비스 내부에서 여러개의 서비스를 부를때 서비스간의 주고받을 데이터가 여러개라면, DTO를 통해 class 로 주고 받아 사용합니다.
디시리얼라이즈 과정
Django ORM 을 통해 Model 객체가 반환되면 이를 다시 dictionary 으로 되돌려야 HTTP 통신을 통해 나갈 수 있습니다. 이를 해결하기 위해서는 다시 반대로 과정이 진행됩니다.
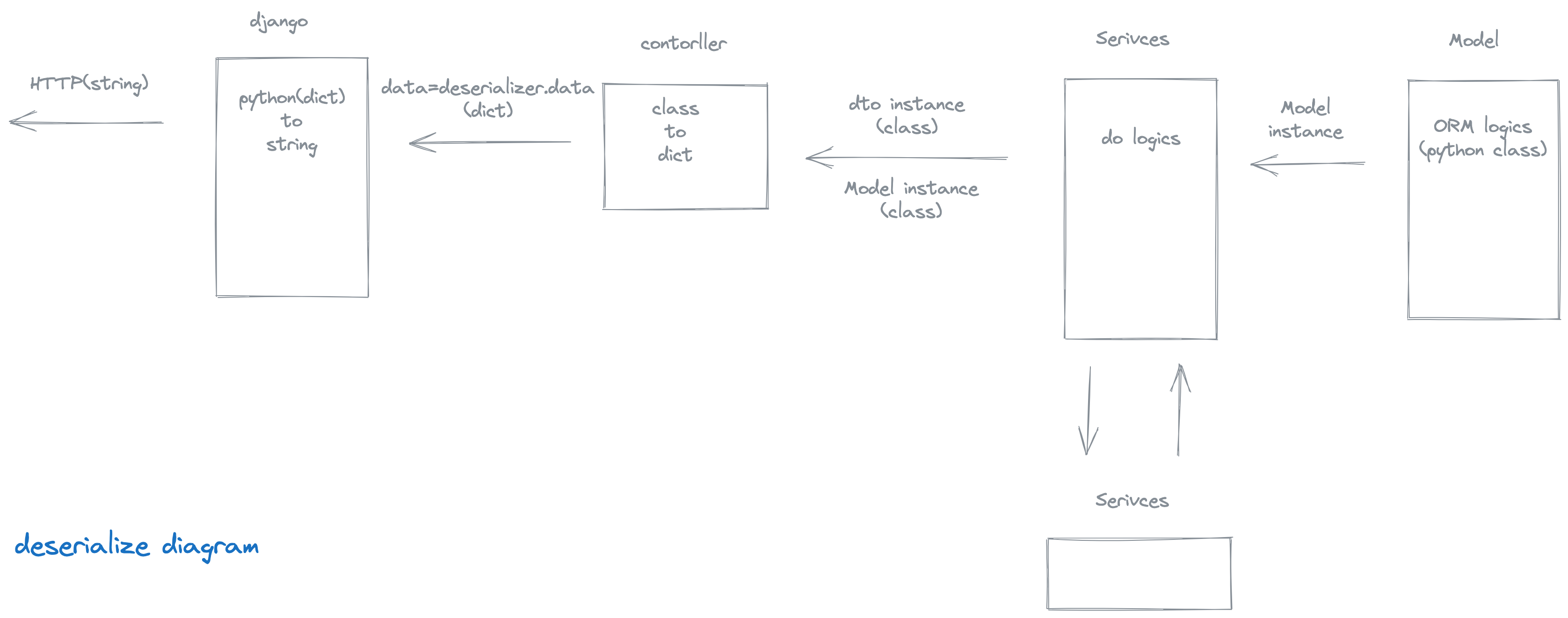
- controller 에서
data = response_serializer(instance=my_model_instance).data등을 통해Response(data=data)에 값을 넣어 사용합니다.
시리얼라이즈를 사용하며 아쉬웠던 점
시리얼라이저가 제공하는 기능에는 Serializer 외 에도 ModelSerializer 도 있습니다만, 다음과 같은 단점으로 인해 사용하지 않기로 하였습니다.
- 서비스와의 계층 분리를 어렵게 합니다.
- 로직 집중도를 생각했을 때 잃을게 더 많습니다.
이러한 컨벤션이 도입되기 전에는 누군가는 Serivce 계층에 로직을 작성하고, 누군가는 Serializer 계층에 로직을 작성하고, 누군가는 Model 계층에 로직을 작성했습니다. 따라서 로직이 어디있는지 한눈에 파악하기가 어려웠고, 계층 분리가 되지 않았습니다. 이에 DB를 히트하지 않은 INPUT 단의 검증은 모두 Seiralizer 에 작성하고, DB를 히트하거나 많은 긴 계산이 필요한 로직은 서비스에 작성하기로 하였습니다.
이러한 컨벤션이 도입되자, ModelSerializer 를 활용하기 어려웠습니다. Retrive 를 담당하는 함수의 경우에 Response 에 ModelSerializer 를 활용할 수는 있으나, 코드 통일성을 위해 Serializer 를 선택하였습니다. (물론 빠르게 API를 작성할때는 DTO와 결합하여 일부 쓰곤 하였습니다.)
시리얼라이즈는 결국 오직 Request 를 검증하고, Response 를 필터링하는데에만 사용했습니다.
시리얼라이즈의 다양한 옵션들
API를 작성하다 보면 절대 빠져서는 안될 parameter가 있는 반면, 그렇지 않은 경우도 있습니다. 이러한 경우를 다뤄주기 위해 serializer 에는 아래와 같은 옵션이 존재합니다.
- required[=True]
- allow_null[=False]
- default[=None]
위와 같은 옵션을 줄 수 있는데, 작성하고 있는 필드 타입이 CharField, DatetimeField 등에 따라 규칙이 달라지기 떄문에 유의하여 사용하여야 합니다. 특히 Django는 string을 "" 혹은 None 혹은 "abc"와 같이 3가지 형태로 받을 수 있는데, 이를 어떻게 핸들링 할지에 대해서는 컨벤션에 따라 달라집니다.
사용후의 아쉬운점
drf의 장점인 코드량 줄이기가 잘 사용되기 어려운 환경
우리는 DRF를 사용할 때 제공되는 자동 api test 문서는 거의 사용하지 않고, drf_spectacular 와 연동하여 생성되는 swagger-ui를 더 많이 이용했습니다. 또한 특정 모델객체에 적용되는 GET,POST,PUT,PATCH,DELETE 와 달리 복잡한 비지니스 로직을 이용했기 때문에, serializer_class 를 한개로 정의하여 API를 풀어내지 못했습니다.
로직 집중도를 늘리기 위해 serializer class 를 GenericView Class 안에 정의해야 했고, 이는 중첩된 Serializer 를 만들기 어려웠기 때문에 결국 dataclass, dataclass_serializer, pydantic 의 도움을 받아 구현해야 했습니다.
이에 생각보다 많은 옵션을 커스터마이징하고 수정해야 해야했습니다.
api 명세 관련
더불어 drf와 drf_spectacular가 아직 깔끔하게 연동되지않아, example을 DTO 마다가 아닌 API 별로 작성해야 했습니다. 이는 조금 아쉬웠습니다. 결국 FE가 BE를 디버깅하는 구도로 만들었고, 많은 버그는 QA로 가기전 FE쪽에서 먼저 API 명세대로 작동하지 않는다는 말을 통해 전달들을 수 있었습니다.
과연 이러한 문제를 어떻게 해결할 수 있을까 싶은데, 현재로서는 누군가에게 소개해 들은 JS 진영의 TRPC는 이러한 문제를 해결했을까? 궁금하네요
typing (python 3.5) 전에 만들어진 drf
요즈음에는 python 에서도 타입 도움을 주기 위해 빌트인으로 typing을 활발히 사용하려고 합니다. DTO를 활용했던 이유도 서비스가 모두 함수로 만들어져 있기 때문에 argument를 많이 넘기게 되면 이를 일일히 작성하기 힘들기 때문인데요. drf는 이 typing이 흐름이 되기전에 만들어져서 pydantic 이나 fastapi 가 전달하는 형태에 비해 조금 덜 fancy 하다는 생각이 많이 듭니다.
물론, 아직 예제나 실용적인 측면에서는 Django 에서는 drf 는 충분히 좋은 라이브러리이고 계속 사용할 예정입니다.
구조 변경이 어려운 Django
클린 코드를 위해 MC가 아닌 MSC 를 이용하려고 하면, 커스터마이징 할게 많습니다. 이는 Django에 대한 아쉬움이기도 한데, 누군가 클린에 가까운 구조를 내놓고 이를 표준으로 적용하기에는 어려워 보입니다.
요약
그럼에도 불구하고 python을 이용한 was 를 만들때 큰 배터리팩과 커뮤니티를 찾는다면 django 만한 것은 없습니다. drf와 더불어 serializer 를 사용해 좋은 서비스를 만들 수 있고, 빠른 Test 와 검증이 가능합니다.
이러한 장점들을 살려, 새로 다가오는 typing과 pydantic이 django에 잘 적용이 되면 좋겠습니다.
참조
- 나의 사수가 건네준 Django StyleGuide, @hoonki
- serializer 관련 구조 복습 레포 cl-django-temp
- 맨날 틀리는 명세서에 고생했던 FE 중 1명 @inkyukim
