Google I/O Extened 2023 Incheon 백엔드 방문기


약 한시간 반 정도에 걸쳐 방문한 스타트업파크는 넓고 쾌적한 환경을 자랑했습니다. 비록 가는데까지 시간이 걸리긴했지만, 쿠키와 아아 Swag를 처음부터 받으니 기분이 좋아졌습니다. 많은 스텝분들이 활동하고 계셨고 입장도 QR코드로 빠르게 진행되서 줄이 빠르게 줄어들어 수속을 마칠 수 있었습니다. 핸드폰 배터리가 다 닳은 덕분에 노트북과 핸드폰을 연결하는 기지에도 불구하고 노트북의 QR코드를 이용해야 했지만 잠깐의 뻘쭘함을 뒤로하고 잘 해결되었습니다. 스텝분들은 친절하고 훈훈한 분위기를 조성해 주셨습니다.
수속 중 만났던 AI 그림들은 흥미롭고 멋있긴 했지만 가끔 보는 예술의 유명한 그림을 거의 그대로 카피한 것도 있었기 때문에 사람이 그렸나 싶다가도 그려려니 하게 되었습니다.
미리 문자로 안내받은 노션을 통해 지도를 확인할 수 있었고 그럼에도 세션장을 헷갈린 탓에 web 세션에 앉아있다가 backend 세션으로 이동하였습니다. 마이크 연결이 원할하지 않은지 키노트를 듣는게 조금 힘들긴 했지만 나머지는 좌석도 인원수보다 조금 많았고 깔끔한 분위기에 진행되었습니다.
1. DEADLOCK 과 REDIS 대기열 사용하기
데드락에 대해한 간단한 설명을 했습니다. MySQL을 사용하는데 데드락이 발생할 수 있다고 했는데 추상화된 그림으로 이해는 했지만 정확한 시나리오가 설명되지 않아 무슨상황에서 시나리오가 발생할 수 있을까 상상했습니다. 이를 REDIS로 해결하는 과정을 담은 발표라 생각하고 DB에 접근하기 전에 REDIS에서 락을 관리하는 건지, 아니면 REDIS 자체를 DB로 사용하며 락을 관리하는 것인지 유의하여 살펴보았으나 역량이 부족한 저로서는 확실히 답을 내리지 못하고 전자의 경우로 사용한다 가정했습니다.
Rosie 님이 데드락을 피하는 방법으로 발표를 시작했습니다.
- (로직) 로직의 순서를 뒤 바꾸기
- (트랜젝션) 트랜젝션의 크기를 줄이기
- (트랜젝션) 격리수준을 낮추기 (CRUD 말고 R이나 W만 적용하기)
- (인프라) REDIS read/write 서버를 분리하기
- (인프라) 캐시서버를 두기
- (인프라) 대기열과 분산락을 활용하기 -> 오늘의 메인주제로 발표될 내용입니다.
현재 트렌드에서 key-value 범위에서는 Redis가 1등을 차지하고 있었습니다. 레디스의 역사와 버전별 차이를 쭉 설명하셨는데, 비록 레디스가 싱글쓰레드지만 멀티쓰레드로 실행할 수 있는 기능도 있어 놀랐습니다. 기타 성능지표와 간단한 기능들은 눈길이 가지 않았지만 Set을 저장하면서도 Score를 매겨 Sorted Set으로 저장 할 수 있다는 장점은 유용해 보였습니다.
Entry 라고 key-value 쌍으로 정의된 자료구조로 관리되는 Redis 는 엔트리가 128개 미만이고, value 가 모두 64바이트 미만일 경우에는 Zip List 구조로, 그렇지 않을 경우에는 Skip List 라는 구조로 정의한다고 합니다.
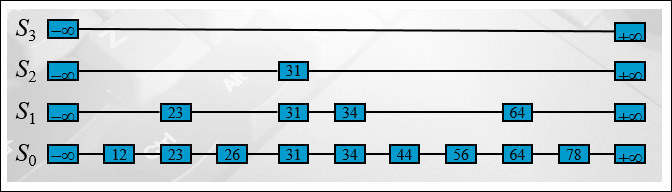
이 Skip List 구조가 굉장히 신기했고, 개괄적으로 설명해 주셨지만 워낙 신기한 구조다 보니 어떤점에서 유용할지 바로 다가오진 않았습니다. 그래도 자료구조의 일부다 보니 나중에 공부해야 할 것이 늘었습니다.
이후 레디스에서 사용가능한 락의 종류에대 해서 설명했는데, 비관적락, 낙관적락, 스핀락, 분산락 등의 키워드가 등장하였습니다. 스핀락을 설명하기 위해서 지속적으로 방문을 열기 위한 톰과제리의 톰의 GIF 을 곁들여 설명했는데, 굉장히 적절한 그림이였습니다.
이후는 이러한 락의 성능을 비교하기 위해 Jmeter와 SpringBoot 를 통해 직접 테스트를 구현하였습니다. 간단한 예제코드와 함께 모든 락의 종류를 비교하여 성능을 비교했는데, 정확한 수치가 표로 나와있었고 차트가 없어 읽는데 조금 힘들긴했지만 모든 종류를 구현하고 비교했다는 점에서 대단했습니다. 몇가지 성능테스트의 지표가 일관적으로 크게 떨어졌었는데, 이를 QNA에서 명확하게 풀지는 못했고, 어떠한 환경에서 진행했는지 궁금해 나중에 질문을 드려 로컬에서 진행되었다는 점을 알았습니다.
마지막으로 이러한 Redis를 사용하면서 더 고려해야 할 점으로 단일장애지점, 메모리를 모니터링, 로그 활성화, 자동세션정리, AWS 제품 사용 등을 이야기 했습니다.
소감
개인적으로 2만명의 동접자를 보유한 수강신청 페이지를 효율적으로 무리없이 설계하고 싶다는 마음가짐이 있었는데, 이를 위해서는 Redis 는 필수로 가져가야 합니다. 이때 DeadLock 이나 영속성에 대한 신뢰성을 확보하기 위해 공부가 필요했는데, 아직 갈길은 멀지만 이번 자료를 통해 시간이 단축되었습니다.
2. 레가시에서 살아남기
크고 코드베이스가 복잡한 멜론에서 근무하시는 분이였습니다. 코드는 많은데 시간은 많지않아 장애를 줄이기 위한 방법론을 모두 적용하기 힘든 상황이였고, 장애를 내기 매우 쉬운 환경에서 살아남기 위해 피쳐플래그를 활용하셨다는 이야기로 발표를 시작했습니다.
마틴파울러의 블로그로 부터 피쳐플래그의 내용을 소개했습니다. 코드를 수정하지 않고 시스템 동작을 변경하는 기술로 쉽게 말하면 거대한 조건문이였습니다.
새로운 결제시스템을 구축한 시나리오를 통해 여러가지 방법을 소개했습니다.
- (권한) 임직원 테스트
- (카나리) 1% 미만 사용자에게 기능 오픈
- (A/B) 결제율의 차이 비교
- (인프라) 2개 모두 활성화 한 다음에 장애 감지시 비활성화
비지니스 관심사에 따른 플래그의 종류도 설명했습니다.
- 릴리즈 플래그: GitHub Flow 에서 우선 머지 하고 기능은 나중에 활성화 할 때
- 실험 플래그: 실험적인 기능에 대해 사용 여부를 조정하는 플래그
- 운영 플래그: 본인인증 업체 3곳 중 장애난 곳을 비활성화 하는 플래그, 트래픽이 많이 몰리는 시점에서 개인추천 로직등 비용이 많은 기능을 일시적으로 비활성화 하는 플래그
플래그를 구성하는 How To는 다음과 같습니다.
- 하드코딩 -> 환경변수 -> DB -> Config -> 관리도구 | 이렇게 순차적으로 접근
- 관리도구 사용시 여러가지 툴이 있었습니다.
- Firebase Remote Config 와 같은 Real-time 지원 구성
- GrowthBook 과 같은 좋은 오픈소스 툴 이용
- cloud event
어떤 개념으로 관리 되는가는 다음과 같습니다.
- 토글포인트 (if/else 등의 분기문)
- 토글라우터 (토글을 결정하는 객체나 디자인패턴, 알고리즘, 수단등)
- 토글설정 (설정파일)
이러한 구성이 어떤 원칙에 따라 적용되어야하는지 설명했습니다.
- 언제든지 바뀔 수 있어야 하지만 코드에는 변경이 없어야 한다
간단하게 SpringBoot 와 Anntaion 을 활용하여 boolean 변수를 통해 해당 기능이 꺼져있을 경우 Callback으로 지정한 함수를 찾아 대신 실행하는 것을 시연하였습니다.
단점은 관리해야할 코드가 2배 이상 늘어나지만, 장애방지에는 효과적이기에 단점이 비교적으로 사소해 보였습니다.
느낀점
확실히 살아남는 자가 강자가 된다고, 이미 잘 쓰고 있는 방법론과 노하우에 대해 공유하시면서 고수의 티가 여기저기 묻어나왔습니다. 코드베이스가 크면 클 수록 오래된 코드를 걷어내기가 쉽지 않습니다. 오래된 코드를 새로운 코드로 포팅하면서 기능이 완벽하게 동작하는 경우는 많지 않습니다. 오래된 코드를 걷어내고 싶지 않을 때가 있는데, 굉장히 적절하고 좋은 해결책인 것 같아 새로운 비급서를 얻은 느낌이였습니다.
3. Redis 와 Sentinel 의 ping-pong 이야기
Redis-Sentinel 구조로 설계된 시스템에서 장애가 발생했고, 이러한 장애를 해결하는 과정에서 어떤식으로 장애를 인식하는지 궁금해서 발표가 마련되었습니다.
Redis가 NoSQL 이므로 전통적인 RDB와 NoSQL 의 차이에 대해 설명했습니다. Redis와 Memcached 도 비교했습니다. Replication 을 지원여부 자료구조 차이 싱글쓰레드, 멀티쓰레드, 메모리 부족시 일어나는 전략, 트렌드 비교등을 진행했습니다.
그 중 직접적인 코드를 비교하며 어떤 라이브러리를 사용했는지 비교했는데, jemalloc 과 slab의 작동방식을 설명하며 메모리 안정성과 파편화 여부에 대해 인사이트를 공유하는 것이 인상깊었습니다.
레플리케이션을 구성하는 방식에서 Master 한대, Slave 2대로 구성하여 Read와 Write를 분리하고, 백업을 Slave 에서만 진행하여 Master에 부담을 주지 않는등의 방식을 설명했습니다. 백업방식에서 스냅샷을 저장하는 RDB방식과 로그를 이용한 백업방식인 AOP에 대해서도 비교하였습니다.
클러스터를 구성하는 방식에서 3대의 기준 구성을 마탕으로 Slave를 Master와 같은 서버에 두어야 할지 다른 서버에 두어야 할지 유즈케이스에 따라 고민을 많이 해봐야한다고 하셨습니다. 유즈케이스는 제공해주지 않으셔서 조금 아쉬웠습니다.
Sentinel을 설명했습니다. 별로의 설치 없이도 이미 내장된 기능이라 Configuration 만 진행하면 된다고 합니다. 모니터링, 알림, 장애복구, 공급자에 대해 관리를 진행한다고 하며 투표를 위해 최소 3개, 홀수의 인스턴스로 구성되어야 합니다. 도커사용시에는 각별히 주의를 기울어야 하는데, 서비스가 재실행되어 포트가 달라졌을 때에 갱신해줘야 합니다.
소규모 단에서는 Redis-Sentinel, 대규모시에는 Sharding/Cluster 구조가 적합하다고 했는데, 장애를 감지해서 복구를 하는 과정은 소규모 대규모에서도 필요하지 않은가 싶어 갸웃했습니다.
모니터링시 사용할 수 있는 명령어도 소개했습니다. 인스턴스 메모리, 레디스 메모리, 커넥션 수, CPU 성능 체크 등을 진행할 수 있습니다.
이후에는 직접 이곳저곳의 소스코드를 까서 확인했습니다. 여러가지 스트럭쳐와 명령어 집합을 확인 할 수 있었는데, 코드를 직접까서 보여줘서 크게 어려움이 없는 것을 확인했습니다. 막연한 진입장벽도 낮아졌습니다. 코드를 당장에 이해하긴 어렵고 높은 집중력을 요하는지라 조금 힘들었습니다. 많은 소스코드에서 Ping을 보내 액션을 취하기 전에 Redis의 상태를 확인하는 것을 찾을 수 있었습니다.
느낀점
아주 중요한 서비스의 경우 Redis의 Failover를 염두에 두어야 합니다. 아직 대규모의 캐싱데이터를 다뤄본일이 없어 Read와 Write를 분리하고 3대를 BackUp으로 구성할 만큼 중요한 비즈니스를 만나지 못했지만, 왜 이러한 회사가 Redis 를 잘 이용하는 사람을 우대조건으로 넣는지 간접적으로 느껴볼 수 있었습니다.
4. Netty 와 Ameriaca 소스 코드 뜯어보기
우리나라에서 쓰이지 않고 있는 Line Open Chat 을 개발하는 개발자로써 Java 생태계에서 비동기 서버를 운영하기 위해 Netty와 Armeria 오픈 소스를 개발하고 운영하는 Line 에서 100억건의 리퀘스트, 오픈챗당 20만건 이상의 처리를 하기위해 어떤 구조를 취하고 있는지 나와서 설명하였습니다. 실제 Nety에 PR을 올리고, Nety를 창안하신 분께 리뷰를 받는다는 것이 인상적이고, 만나기 쉽지 않은 고수라고 생각했습니다.
NodeJS의 libuv, Redis 소스 코드에는 모두 이벤트 루프 구조체와 관련된 로직이 있고, 이를 Java에서 비슷하게 구현한게 Nety 소스코드 입니다. 기존 멀티쓰레드를 이용할 경우 유저가 많아지면 쓰레드 관리측면에서 성능이 급격히 나빠지기 때문에 Nonblockig IO(NIO) 를 통해 Socket Channel과 같은 구조로 추상화하여 채널 핸들러와 채널 파이프라인, 채널디스패쳐들을 통해 관리 할 수 있도록 로직이 구성 되었습니다.
NIO의 핵심은 EventLoop를 무한 루프를 통해 관리하면서 준비된 Channel을 처리하고, Schedule된 이벤트를 처리하고, 계속해서 루프를 도는 것입니다. 특히 이후 소스코드를 소개할 때 진입점에 있는 소스코드에서 try-final 그리고 무한 루프밖에 업는 요약된 3줄짜리 코드만 존재하는 것을 보고 굉장히 재밌고 신선했습니다.
이벤트 루프를 일반적으로 구성할때 CPU의 코어수에 2배에 해당하는 이벤트 루프가 일반적으로 좋은 성능을 보여주었습니다. 이벤트루프들의 그룹이 생기는데 이를 이벤트 루프 그룹이라는 개념으로 관리하여 채널핸들러들에게 이벤트를 넘겨주는 방식을 정한다고 합니다. 이 부분은 역량이 부족하여 잘 듣지 못했습니다.
10K 프로블럼을 이러한 방식으로 해결할수 있었고, 이후는 소스코드들을 직접까서 보여주셨습니다.
NIO RUN 방식을 통해 커넥션이 준비되었는지를 확인하는 상태확인 로직(OP_READ), unsafe 메소드(일반개발자가 호출하지 말게 설게된), pipeline.fireChannelRead 등의 핵심 코드에 대해 간단히 설명했습니다.
스케줄된 태스크를 처리할때, 현재 시간기준으로 실행가능한 Task를 모두 TaskQueue 에 복사한 뒤, 순차적으로 처리하는데, Priority Queue를 활용하여 처리합니다. 발표자분은 이러한 스케줄링을 많이 쓸경우 Priority Queue는 문제가 생길 수 있기에 CPU 스케줄링과 비슷한 로직을 도입해서 Task가 과도하게 많아지더라도 일정하게 성능을 유지 할 수 있는 커스텀 큐를 활용할 수 있도록 PR을 올렸습니다. 생각보다 쉽게 말하셔서 놀랐습니다. 그리고 누군가가 쉽게 무언가를 한다면 고수라는 말이 기억났습니다.
이벤트 루프를 절대 블록킹하지 말라는 이유와 함께 Nodejs의 공식문서도 같이 보여주셨습니다. 효율적인 상태관리를 위해 싱글쓰레드로 이벤트 루프를 관리하는데 (동시성문제 제외) 만약 멀티쓰레딩과 동기화를 이러한 이벤트 루프 로직안에서 실행하게 되면 모든 로직에 문제가 생기기 때문에 반드시 별도의 쓰레드를 만들어 처리한뒤 반환하는 방법으로 주도권이 항상 Nety의 로직에 있어야 한다고 설명했습니다.
이후 Armeria와 SpringBoot를 활용하여 Nety 베이스의 로직에서 gRPC, healthcheck, LB, 호환성 보장, 자동문서화를 사용하는 개괄적인 구조도를 Layer을 지어 설명했습니다. SpringBoot가 Armeria 를 이용할 수 도있지만, Armeria는 독자적으로 사용가능한 프레임워크기 때문에 Line은 SpringBoot가 아닌 Armeria을 직접 만들어가며 사용중이라고 했습니다.
이후 여러가지 장표를 통해 실제적인 사용방법과 설정방법에 대해 개괄적으로 설명했지만, 쉬워보이는 장표에 비해 SpringBoot, Socket 추상화에 대한 이해도가 떨어져 어떤 식으로 Event Loop가 효과적으로 동작하는지에 대해서는 이해하지 못했습니다.
느낀점
나라면 이벤트 루프를 사용하기 위해 Node를 배웠을 것 같은데, 이분들은 소스코드도 까보고 핵심 내용을 이해하여 안정적인 Java 위에서 해당 프레임워크를 새로 짜며 만드는 과정이 신기하면서도 동경에 빠지게 했습니다. 훌륭한 프로그래머들이 모인 집단에서는 필요한 것이 있으면 만들고, 배워야 할 것이 있으면 학습하면서 좋은 코드베이스를 만드는 것이 가능한 것 같습니다.
5. 모듈러 모놀리스 살펴보기
쿠팡에서 쿠팡이츠 배달 파트너 백엔드를 개발중이신 개발자분이 발표를 진행했습니다. 2020 우아한 모노리스라는 발표주제에서 해당 주제를 소스코드에 적용하면서 여기까지 오신 것 같습니다. 특히 2023.05월 모듈러 모노리스를 통해 90% 비용을 절감한 아마존 비디오의 사례를 소개하고, 스프링에서 23.08.21 부터 정식버전으로 도입된 모듈러 소식을 통해 모듈러 모놀리스가 전체적인 트렌드라는 것을 확인하였습니다. 모놀리스, MSA 그 뒤에 오는 더 좋은 방식인가 기대하게 되었습니다.
모듈러 모놀리스란, 각각의 세부사항을 별개로 관리할 수 있는 모듈과 통일된 하나의 객체를 의하는 모놀리스의 합성어입니다. 모순적인 두 가지의 말이 붙었지만 MSA와 모놀리스 아키텍처를 고민하는 와중이라 크게 어렵지 않았습니다. 해당언어를 설명하기 위해 스페이스 오디세이의 모놀리스 물체와 팬파인애플애플팬의 유머등을 가져오셨습니다. 발표를 잘 이끄시는 분이였습니다.
모놀리스
- 한개의DB
- 고전개발방식
- Method Call
- 트랜젝션이 쉽다
- 일부 서비스를 분리하거나 개별관리가 어렵다
- 단순하다
MSA
- 여러개의 DB, WAS 를 가진다
- 큰 규모의 기업이 선택한다
- Network Call 을 이요한다
- 트랜젝션을 사용할 수 없어 최종적 일관성을 지향한다
- 매우 높은 운영비용이 든다
- 일부 구성의 교체/변경 관리가 쉽다.
다시 마틴파울러가 나와 어떤 아키텍처를 선택할지 고민할 때 절때 마이크로서비스로 서비스를 시작하지 말라고 주장하는 블로그를 확인했습니다. 모놀리스가 초기에 유리하고 어느 순간에 마이크로 서비스가 유리한데, 그렇다고 마이크로 서비스로 시작하면 LV1에 드래곤을 상대하는 것처럼 매우 험난한 길이 있다고 했습니다. 그래서 모놀리스로 설계하고 이후에 어떤 과정을 거치는지 면밀히 분석한다음 분리가 필요한 서비스를 점차적으로 분리하는 것이 옳다고 합니다.
일반적으로 컨트롤러, 서비스, 레포지토리로 구성되는 레이어드 아키텍처를 소개하여 이들이 의존성을 복잡하게 가지는 도표를 소개했습니다. 이렇게 복잡해지면 의존성의 복잡함이 크게 증대되어 서비스 분리의 발목을 잡기 때문에 미리 모듈러 모놀리스를 지향하여 분리가 쉬운형태로 진행하는 것이 좋다고 소개했습니다.
잘 분리되었는지 확인하는 방법으로는 비즈니스적으로 물리적으로 분리되었는지, 개념적으로 분리되었는지 명확히 하는 것입니다.
- 비즈니스별 물리적 분리 X X O
- 비즈니스별 개념적 분리 X O O
- (순서대로 모놀리스, 모듈러 모놀리스, 마이크로 서비스)
이후에는 모듈러 모놀리스를 SpringBoot 를 통해 예를 들었습니다. 모듈별로 jar 파일로 떨어진 뒤, 이를 다시 모아 하나의 jar 파일을 만들 수 있으면 모놀리스가 됩니다. 이렇게 만들기 위해서는 코드의 레이어를 잘 분리하여 의존성과 복잡도를 낮춰야 합니다.
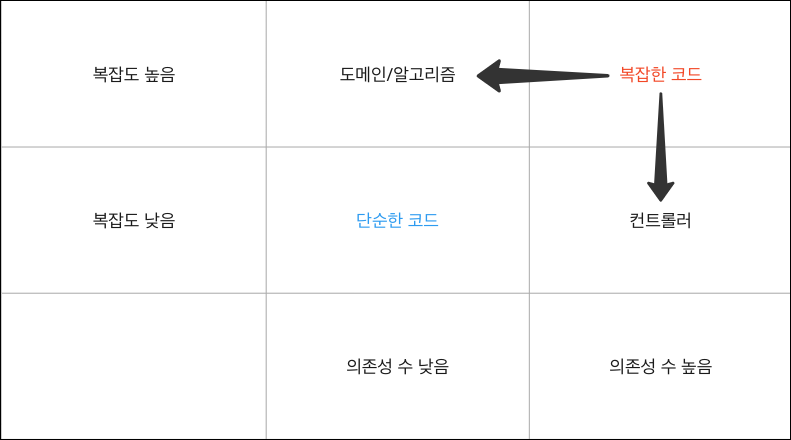
도메인 분리를 잘 하는 것은 개발자의 몫이고 정답이 없기 때문에 해당 분리가 잘 이루어지게 되면 스프링 자동완성을 통해 구분할때 레이어를 implements 로 의존성을 넘기면 아예 자동완성에서도 뜨지 않아 계속해서 생각하며 import를 하지 않아 생산성이 늘어날 수 있다고 합니다.
그러나 단점으로 모듈러 모놀리스에서 한 개의 서비스 트래픽이 10배 늘었다고 해도 따로 분리하거나 해당 서비스의 가용성을 늘리기 쉽지 않기 때문에 적절한 시점에서 MSA 사용이 고려되어야 합니다.
Bounded Context를 통해 기능이 아닌 비즈니스 개념으로 나누고, 모듈마다 테이블 분리를 적절히 진행해서 다른 비지니스 도메인간 끼리의 JOIN이 일어나지 않도록 설계를 해야 잘 분리되었다고 구성할 수 있다고 합니다. 각 과정을 도식화하여 좋은 그림으로 그려주셔서 이해하기 적절하였습니다.
순환참조는 이러한 모듈러 구성에서 일어나기 쉬운데, 순환참조를 한다면 트래픽이 10배, 20배, 30배 씩 늘어나기 때문에 명확한 위계질서를 (아키텍처) 설정하여 위에서 아래로만 참조하게 하여 구성하면 순환참조의 방지가 쉽습니다. 이를 위해 발표자 분께서는 컨트롤러, 서비스 외에 어플리케이션 레이어, quote...Service 라는 다른 어플리케이션에서 사용가능한 서비스를 따로 작성하여 참조가능함을 명확히 정의했다고 합니다.
느낀점
발표자분을 보니 대학교 시절 최고의 강의력으로 뽑혔던 백모 교수님의 풍모가 느껴졌습니다. 단어를 적게쓰고, 명확한 구두체를 쓰며 아주 간단한 장표에도 강약조절을 통해 말하고자 하는 키워드를 강조하면서도 집중이 쉬웠습니다. 발표에 빠져들어 다음주제와 이전 주제를 정리하지 않아도 다음주제 연결이 자연스러워서 의식의 흐름이 일치했고, 적절한 그림과 장표를 통해 이해를 도왔습니다.
덕분에 QNA에서 가장 많은 질문이 나왔고 질문 내용도 알찼으며, 줄서서 질문하는 기염까지 토했습니다.
정말 잘 짠 구조로 느껴지며, 그래들을 열심히 공부해서 어떤식으로 의존성을 관리하는지, 어떤식의 레이어분리가 일어나는지 등을 확실하게 배워놓아야 겠다는 다짐을 하며, 가끔 비슷한 분위기를 풍기는 분이 비슷한 발표를 한다는 것이 신기했던 발표였습니다.
6. 이제 비싼 닷넷이 아닙니다.
FOW 에서 개발을 맡으신 분이 오셨습니다. 예전에 롤할 때 전적을 참고했던 적이 있어 반가웠습니다.
C# 컴파일 결과물인 CIL을 가지고 CLR 위에서 돌아가는 방식은 java와 비슷했습니다. 관련하여 .NET 생태계와 구조에 대해 설명했습니다. .NET Framework를 통해 윈도우 어플리케이션 뿐만아니라 웹프레임워크도 개발할 수 있음을 설명했습니다.
물론 예전에는 Window에서만 개발이 가능했기 때문에 불친절하고 비싸다는 이야기를 들었습니다. 하지만 2016년도에 모든 플랫폼 지원이 가능한 .NET Core 가 발표되었습니다. .NET Framework에서 지원었던 기능들이 모두 .NET Core 에서도 지원되면서 .NET으로 합쳐지면서 현재는 VSC와 Rider에서도 개발이 가능한 상태가 되었습니다. 이러한 컴파일 결과에서는 CLR을 자체적으로 내포할 수 있기 때문에 모든 플랫폼에서도 실행이 가능합니다.
현재는 .NET7버전을 지원하며 곧 11월에 NET8 LTS 버전이 나온다고 하며 간략한 역사에 대해 소개하였습니다. C#은 WebAssembly 지원하기 때문에 이러한 기능을 마탕으로 Rider를 통해 간략한 웹서비스를 시연하였습니다.
이 과정에서 SpringBoot와 비슷하고 Vue와 비슷한 C# 백엔드 프론트엔드 프레임워크가 어떤식으로 구성되어있는지 확인 할 수 있어 신기했습니다. 구조가 비슷하기도 하지만, 사용방법이나 개념이 다른 것들이 있어 C#에 익숙해져야 적응이 가능할 것 같았습니다. 토이 프로젝트 하나를 발표를 위해 다 짜오신것 같은데, 중간에 에러도 났지만 쿨하게 넘어가는 등 애로사항과 함께 재미있는 시연이였습니다.
느낀점
비싸다는 느낌때문에 처음에는 AWS, GCP 다음으로 Azure에서 비용절감을 하는 내용일줄 알았습니다. C#을 통해서도 웹 프레임워크가 시연가능하고, 또 구조가 비슷하다는 점에서 재미있는 발표였습니다.
언어는 수단일 뿐이고, 개념을 어떻게 구성하고 만드는지가 중요하다는 모 시니어의 말이 떠오릅니다.
마지막으로
마지막으로 벡엔드 세션에서 의자를 옮기고 인사를 받으면서 이상한 기분이 들었습니다. 분명 돈을 냈지만 그보다 많은 시간과 경험을 얻어갔습니다. 카톡에서도 한참동안 이러한 행사를 열어주셔서 감사하다는 인사가 계속되었습니다. 직접적인 도움은 아니지만 동기부여와 함께 개괄적인 개념을 잡는데 많은 도움이 되었습니다.
장소를 대관하고, 발표자를 섭외하고, 기념품과 간단한 마실것을 제공하는데에 많은 사람이 함께 했을 것 같습니다. 감사한 마음을 뒤로하며 지하철을 타고 다시 일상으로 돌아왔습니다.
