이 포스팅은 제가 egoing님의 [생활코딩 Ajax강의]를 들으며 필기한 내용입니다. 수업을 그대로 따라가며 필기했기 때문에 수업 내용과 필기가 거의 동일합니다!
알 수 없는 알고리즘으로 이 게시물과 만난 분이 계신다면 우... 네... 반갑습니다! 이건 그냥 저의 공부 흔적이에요...😉 이걸 말하고 시작할게요! 다들 이고잉 하세요! 꺄호!
Ajax
Ajax는
Asynchronous JavaScript And XML의 약자이다.
(and까지 약자에 넣어주다니 너무 귀엽구만)
웹을 이용할 때 페이지가 자주 리로드되는 것은 사용자에게도 불편한 경험이고 서버 입장에서도 자원적인 낭비이다. Ajax는 바로 이럴 때 이용하기 좋은 기능이다.
Ajax를 이용하면 웹 페이지를 리로드 하지 않고도 서버와 통신하여 웹 페이지에서 변화가 필요한 부분만을 갱신할 수 있다.
Ajax로 외부에서 데이터(JSON, XML, HTML, txt ...)들을 손쉽게 건네받을 수 있다.
강의 실습환경 구축
- 기존 생활코딩 강좌의 WEB2 파일을 github에서 다운받자!
- Ajax는 보안 문제로 서버와 직접 통신을 해야 한다. 때문에 html 파일을 직접 여는 것이 아니라 웹서버를 통해 웹사이트를 열어야 한다.
웹서버를 여는 수많은 방법들이 있지만. 있지만 나는 기존에 사용해 보았던 node.js와 express를 사용해서 웹서버를 열었다. (약간 햝짝 해본 게 다지만 그래두!)
main.js파일을 생성하고
const express = require('express');
const app = express();
const port = 3000;
app.get('/', (req, res) => {
// __dirname은 현재 경로를 나타낸다.
res.sendFile(__dirname + '/index.html');
});
app.listen(port, () => {
console.log(`Example app listening at http://localhost:${port}`);
});터미널 창을 열어 node main.js 명령을 실행할 시 웹서버가 구동된다.
라우팅 문제...
대박사건 발생함. 라우팅이 되어 있지 않았기 때문에 링크가 걸린 a태그를 클릭해도 페이지를 보여주지 않고 오류가 출력되었다. 일단은 무식하게 하나하나!!! 하드하게 라우팅을 해줬다.
지금 와서 생각해보니 어라... 그러고보니 싱글페이지를 만들 거라서 라우팅 하지 않아도 괜찮았다... 하지만 7월 29일의 나는 우야꼬... 우야꼬... 하고 엉엉 울면서 하나하나 라우팅을 달아줬다. 하.ㅋㅋ 이것은 나의 귀여운 점이다 ㅋㅋ (사실 안 귀여움 그냥 바보인 부분임)
const express = require('express');
const app = express();
const port = 4000;
// 자바스크립트 코드(정적파일)를 불러오는 코드
// 이것도 사실 필요 없는 작업이었다 ^ _ ^ ;
app.use('/', express.static(__dirname + '/'));
// 메인 페이지로 가는 라우트 두개!
app.get('/', (req, res) => {
res.sendFile(__dirname + '/index.html');
});
app.get('/index.html', (req, res) => {
res.sendFile(__dirname + '/index.html');
});
// 아래는... 무식하게 걸어둔 라우트들
// I like music 아이라이크무식
app.get('/1.html', (req, res) => {
res.sendFile(__dirname + '/1.html');
});
app.get('/2.html', (req, res) => {
res.sendFile(__dirname + '/1.html');
});
app.get('/3.html', (req, res) => {
res.sendFile(__dirname + '/1.html');
});
app.listen(port, () => {
console.log(`Example app listening at http://localhost:${port}`);
}); 맨날 port 3000으로 열어서 한번 4000으로 열어보았다 히히
맨날 port 3000으로 열어서 한번 4000으로 열어보았다 히히
동적으로 컨텐츠 변경
웹서버로 실습 환경을 구축해주고 이제 본격적인 수업에 들어가게 되었다!
우선 가지고 있는 html 파일을 살펴보자.
<ol>
<li><a href="1.html">HTML</a></li>
<li><a href="2.html">CSS</a></li>
<li><a href="3.html">JavaScript</a></li>
</ol>
<!--아래 부분이 동적으로 변할 컨텐츠이다-->
<h2>HTML</h2>
<p>
<a
href="https://www.w3.org/TR/html5/"
target="_blank"
title="html5 speicification"
>Hypertext Markup Language (HTML)</a
>
is the standard markup language for
<strong>creating <u>web</u> pages</strong> and web applications.Web
browsers receive HTML documents from a web server or from local storage
and render them into multimedia web pages. HTML describes the structure of
a web page semantically and originally included cues for the appearance of
the document.
<img src="coding.jpg" width="100%" />
</p>
<p style="margin-top: 45px">
HTML elements are the building blocks of HTML pages. With HTML constructs,
images and other objects, such as interactive forms, may be embedded into
the rendered page. It provides a means to create structured documents by
denoting structural semantics for text such as headings, paragraphs,
lists, links, quotes and other items. HTML elements are delineated by
tags, written using angle brackets.
</p>
</body> (이미지 재탕하기 냐하하!)
(이미지 재탕하기 냐하하!)
리스트를 클릭하면 새로운 페이지로 이동하고(리로드), 아래의 콘텐츠가 바뀐다.
결국 리스트를 클릭할 때 변화가 필요한 컨텐츠는 일부인데 매번 페이지를 리로드하며 모든 자원을 가져오고 있다.
이럴 때 Ajax를 이용하면 변화가 필요한 데이터만을 동적으로 가져올 수 있다.
그래서 어떻게 할까!
- 우선 변화할 컨텐츠를 담을 빈 그릇이 필요하다.
(article태그를 생성) - a 태그의 href를 지워서 페이지의 리로드를 막는다. (대략 이때... 나는 아까의 라우팅을 후회했다.)
- a태그에 onclick으로 클릭이벤트를 건다.
- 클릭 이벤트로 방금 생성한 빈
article태그를 잡아낸다. innerHTML메서드를 이용하여article태그 내에 원하는 콘텐츠를 집어넣는다.
그리하여 완성된 html 파일을 보여드리겠습니다.
<ol>
<li>
<a
onclick="
document.querySelector('article').innerHTML = '<h2>HTML</h2> HTML is ...';
"
>HTML</a
>
</li>
<li>
<a
onclick="
document.querySelector('article').innerHTML = '<h2>CSS</h2> CSS is ...';
"
>CSS</a
>
</li>
<li>
<a
onclick="
document.querySelector('article').innerHTML = '<h2>JavaScript</h2> JavaScript is ...';
"
>JavaScript</a
>
</li>
</ol>
<article>
<!-- 이곳에 동적으로 변화할 넘이 들어갑니다 슝 -->
</article>
JavaSript is .......... spicy
article태그에 동적으로 컨텐츠가 생성되게 만들긴 했으나!... 최종 목표는 이게 아니다.
원하는 컨텐츠를 지금의 html 파일이 아닌 외부에서 가져오는 것이 최종 목표이다. 그러기 위해서 가져올 정보를 외부로 일단 빼내야 한다.
비동기에 대한 개념과 그 메서드(fetch, then)
이제 비동기 방식으로 외부에서 데이터를 가져올 것이다. 그에 앞서 비동기에 대한 간단한 개념을 정리하고 가겠다.
원래 자바스크립트 코드는 동기방식으로 작동한다. 동기방식이란 위에서 아래로 쭈우욱 코드를 읽어내리다가 오래 걸리는 작업이 나오면 작업이 끝날 때까지 기다리고, 다음 작업을 실행하는 방식이다.
그리고 비동기(asynchronous)란 동기 방식과 반대의 의미로 오래 걸리는 작업을 진행하면서도 그 작업이 끝나기 전에 동시에 다른 작업을 진행하는 방식이다. 내가 이해한 바로는 이렇다...
참고로 ajax의 첫번째 스펠링인 a가 바로 그 asynchronous(비동기)의 a에서 따온 것이다.
3번째 약자 a는 그냥 and 에서 따온 주제에... 좀 어이없긴 함.
하... 정말 동기와 비동기로 한 때 눈물을 좔좔 흘렸던 적이 있었는데... 아무튼 Ajax에서 사용하는 fetch와 then이 바로 비동기 방식이다.
나는 너무 반가운 나머지 만세하고 그대로 뺨때릴 뻔했다. 너 때문에 내가 얼마나 힘들었는지 아니? 하지만 반갑다 나 너 안다
실습으로 돌아가며... 비동기 체험
먼저 디렉토리에 가져올 외부파일(HTML, CSS, JavaScript)을 작성해준다.
h2태그에 타이틀을 넣고 p 태그로 설명을 달아주었다.
<h2>CSS</h2>
<p>CSS is...</p><h2>HTML</h2>
<p>HTML is...</p><h2>JavaScript</h2>
<p>JavaScript is...</p>난카 초라해...
 자세히 보면 html이 아닌 확장자명이 없는 그저 순수 텍스트 파일이다. 하지만
자세히 보면 html이 아닌 확장자명이 없는 그저 순수 텍스트 파일이다. 하지만 innerHTML 메서드를 이용하면 순수 텍스트 파일로 작성하여도 웹에서는 제 태그의 모습을 갖춰서 나타난다.
이제 a태그의 onclick 이벤트에 fetch 기능을 적용해보자.
<a onclick="
fetch(filename).then(function(response){
// 여기서 응답받은 파일의 텍스트를 가져옴
response.text().then(function(text){
document.querySelector('article').innerHTML = text
})
})
">filename</a>정렬이 아까부터 왜 이런지 몰겠다 진심.
아무튼 저 코드가 바로 비동기 방식으로 외부의 데이터를 가져오는 코드이다. 이 코드를 하나씩 뜯어보겠다.
fetch(요청)
fetch('javasript')위 코드는 인자로 들어온 javascript라는 이름의 파일을 서버에게 요청하는 코드이다.
저렇게만 입력하고 네트워크 탭을 살펴보면 실제로 네트워크탭에 해당 파일이 불러와져있는 것을 확인할 수 있는데 캡쳐는 귀찮아서 안 했다 히히.
then(응답)
요청을 하고 나서 응답이 올동안 당연히 시간이 걸릴 것이다. 그동안 가만히 있는 것이 아니라 다른 일을 할 수 있게 하는 것이 바로 then의 역할이다.
function callbackme() {
console.log('response complete!')
}
fetch('puppy').then(callbackme)
console.log(1);
console.log(2);
// 출력 결과
// 1
// 2
// response complete!
위 코드를 보자.
fetch로 puppy 파일을 요청한다.
그러면 then은 요청한 파일을 응답할 때까지 가만히 멍청이처럼 있는 게 아니라 그 밖의 다른 일(1과 2를 출력하는)을 하다가!
fetch가 완전히 불러와진 후에 callbackme함수를 실행시킨다.
그것이. 비동기니까...
Fetch API Response 객체
fetch('puppy').then(function(response){
console.log(response)
})우리가 요청을 하고 받은 응답은 어떻게 확인할까?
then이 호출하는 함수의 첫번째 인자에 자동으로 response가 들어온다. 콘솔을 찍어 확인해보자.
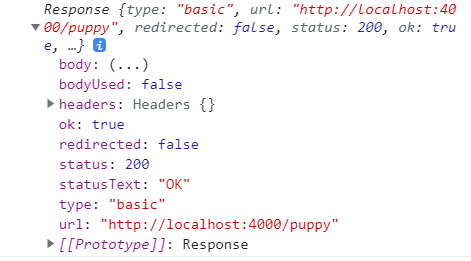
받아온 응답에 대한 정보를 알려준다.
특히나 status에는 데이터를 가져온 결과를 숫자로 나타내주는데, 대표적으로는 200(성공적으로 데이터를 불러옴)과 404(데이터를 찾을 수 없음)가 있다.
이를 응용해 response.status가 404일 시에 잘못 접근된 페이지 전용 페이지(ㅋㅋ)를 띄울 수도 있다.
아무튼 이 response 객체 친구는 HTTP강의에서 이미 한 번 들은 것이라 복습하는 기분이었다 :3
그렇게 Ajax로 수정한 코드
<ol>
<li>
<a
onclick="
fetch('html').then(function(res){
res.text().then(function(text) {
document.querySelector('article').innerHTML = text
})
})
"
>HTML</a
>
</li>
<li>
<a
onclick="
fetch('css').then(function(res){
res.text().then(function(text) {
document.querySelector('article').innerHTML = text
})
})
"
>CSS</a
>
</li>
<li>
<a
onclick="
fetch('JavaScript').then(function(res){
res.text().then(function(text) {
document.querySelector('article').innerHTML = text
})
})
"
>JavaScript</a
>
</li>
</ol>
<article>
<!-- 이곳에 동적으로 변화할 넘이 들어갑니다 슝 -->
</article>그렇다 리팩토링이 필요하다. 반복되는 부분을 쳐낼 필요가 있다. fetch를 함수로 따로 빼서 리팩토링했다.
function fetchPage(pageName) {
fetch(pageName).then(function (res) {
res.text().then(function (text) {
document.querySelector('article').innerHTML = text;
});
});
}이렇게 재사용 가능하게 빼두고
<ol>
<li>
<a onclick="fetchPage('html');">HTML</a>
</li>
<li>
<a onclick="fetchPage('css');">CSS</a>
</li>
<li>
<a onclick="fetchPage('javascript');">JavaScript</a>
</li>
</ol>
<article>
<!-- 이곳에 동적으로 변화할 넘이 들어갑니다 슝 -->
</article>사용하면 끝!
라우트와 리로드를 동시에? Hash
하지만 뭔가 아쉽다.
클릭했을 때 주소도 함께 바뀌었으면 좋겠다.
그러나 우리는 싱글페이지로 코딩했기 때문에... a태그의 href가 없어져서 주소의 이동이 불가하다.
하지만 문서당 고유한 주소가 있었으면 좋겠고... 홈페이지에선 당연히 리로드가 일어나면 안되고 어쩌구...
이를 해결하려면 어떤 식으로 접근해야 할까?
리스트 제목을 클릭할 때마다 고유한 주소로 이동하고,
그 링크를 공유해서 다른 사용자가 클릭하면 나의 사이트의 딱 그 문서로 들어올 수 있게... 하려면
Hash라는 기능을 이용하면 된다.
1. 특정 태그에 id값을 주고
2. a href에 #과 함께id이름을 입력하면?
자동으로 그 곳에 포커스가 맞춰진 채로 이동이 된다. 헐 신기해
그러고보니 얼마전에 순수 html/css로 배너 슬라이더를 만든 걸 봤는데 그것도 이 기능과 transition을 이용했던 거 같다. 암튼 이건 잡담이고...
a태그에 #id를 입력하면 그게 고유한 해시값이 되고, 클릭할 시 링크도 걸리고 이동도할 수 있는데 리로드는 안된다! 그대로 적용해보자.
<ol>
<li>
<a href="#html" onclick="fetchPage('html');">HTML</a>
</li>
<li>
<a href="#css" onclick="fetchPage('css');">CSS</a>
</li>
<li>
<a href="#javascript" onclick="fetchPage('javascript');">JavaScript</a>
</li>
</ol>그리고 리스트들(css, html, javascript)에도 모두 id값을 주었다.
<h2 id="css">CSS</h2>
<p>CSS is...</p>그 결과...
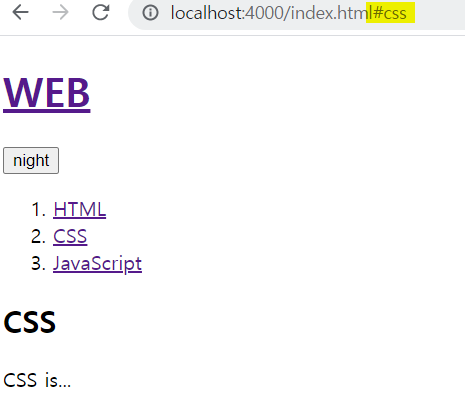
a태그 특유의 밑줄도 생기고 리스트를 클릭할 시 주소창의 링크도 hash가 붙은 링크로 변경되었다.
location.hash 로 해당 해시 값을 알아낼 수 있고
location.hash.substr(1) 으로는 #이 제거된 순수한 hash의 이름만 가져올 수 있다. hash값이 포함된 링크로 들어올때 해당 페이지로 이동시키는 코드는 아래와 같다.
if (location.hash) {
fetchPage(location.hash.substr(2));
}Hash의 단점
ajax와 hash를 이용할 시 검색엔진 최적화가 잘 안 되어서 데이터가 검색엔진에 잡히지 않는다. 웹페이지를 백엔드에서 동적으로 가져오기 때문에 당연한 일이다...
이 단점을 보완하기 위한 pjax(pushState + ajax)라는 기술이 있다. (나중에 공부해봐야지!)
글목록까지 Ajax로 가져오기
여지껏 작성한 코드를 가만 살펴보면...
<ol id="nav">
**<li>
<a href="#!html" onclick="fetchPage('html');">HTML</a>
</li>
<li>
<a href="#!css" onclick="fetchPage('css');">CSS</a>
</li>
<li>
<a href="#!javascript" onclick="fetchPage('javascript');">JavaScript</a>
</li>**
</ol>
<article>
<!-- 이곳에 동적으로 변화할 넘이 들어갑니다 슝 -->
</article>li 태그조차 '바뀔 수 있는' '데이터'의 성질을 띈다. 데이터가 바뀌었을 땐 오직 데이터 파일만이 바뀌었으면 좋겠고, 애플리케이션(메인)파일은 그대로 있으면 좋겠다.
그걸 위해 저 list들을 데이터화하여 아까 따로 생성한 css, html, javascript 파일들처럼 아예 밖으로 빼버리기로 했다. 일단 데이터가 들어갈 부모태그인 ol태그에 id를 줬다.
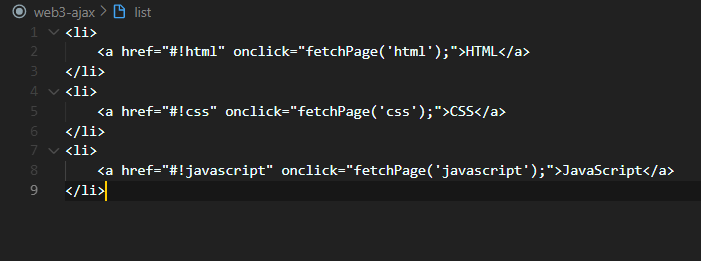
새로 list 라는 이름의 파일을 생성하여 이곳에 글 목록 list를 넣어두었다.
이렇게 애플리케이션과 컨텐츠(데이터)를 분리하면 가독성, 유지보수에 용이하다.
좀 더! 리팩토링
기존의 글 목록인 list도 반복되는 코드이다.
<li>
<a href="#`${itemName}`"
onclick="fetchPage('`${itemName}`')">{itemName}</li>위와 같이 한 줄로 만들어버리자. 그리고 실질적으로 필요한 데이터는 저 itemName에 들어가는
HTML, CSS, JavaScript일 것이다.
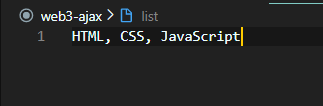
일단 list라는 새로운 파일을 만들고 저렇게 원하는 아이템 이름을 넣고 저장해두었다.
이렇게만 입력해도 자동으로 list가 생기게 할 것이다.
그렇게 하기 위해선
- list 파일에 적힌 저 string 형식의 아이템들을 가지고 와서 배열로 만들어야 한다.
- 만들어진 배열의 길이만큼 for문을 돌아
li태그를 생성해야 한다.
그것을 하기 위해 index.html의 script 태그에 새로운 함수를 추가했다.
fetch('list').then(function (res) {
res.text().then(function (text) {
// string을 배열로 만들어준다
let listArray = text.split(',');
// list tag를 합칠 공간
let listTags = '';
for (let i = 0; i < text.split(',').length; i++) {
// 공백을 제거하여 배열을 수정
listArray[i] = listArray[i].trim();
// 배열 아이템들을 list tag로 만들어 줌
let listItem = `<li><a href="#!${listArray[i]}"token interpolation">${listArray[i]}')">${listArray[i]}</li>`;
// list를 합친다
listTags = listTags + listItem;
}
document.querySelector('#nav').innerHTML = listTags;
});
});-
먼저 Ajax로 불러온 string 데이터를 불러왔다.
-
split메서드를 이용해서 첫번째로 들어온 인자 콤마(,)를 기준삼아 string을 잘라서 배열화 해줬다. -
배열 아이템들 사이에 공백이 생기는 것을 예방하기 위해
trim메서드를 사용하였다.
(강좌를 보기 전에 혼자 직접 구현해봤는데 강사님도 이 메서드를 똑같이 사용해서 몬가 기분이 좋았다 에헤헤) -
비어있는 변수(list태그를 담을)를 미리 생성하고, for문 안에서 빈 태그에 list item을 계속 추가한다
-
for문이 끝난 후 마지막엔 완성된 꽉 찬 태그를 화면에 출력되게 했다.
재밌다!
브라우저 호환성 문제 (pollyfill)
생활코딩에서 강좌가 나온 2018년 기준으로는 fetch기능을 사용할 수 없는 브라우저가 지금보다 많았다. (그래봤자 여전히 코딱지였지만...)
브라우저 호환성 문제로 알려준 pollyfill 이라는 라이브러리가 있다. fetch기능을 지원하지 않는 브라우저도 pollyfill을 이용하면 fetch를 사용할 수 있게 해준다.
웹은 여전히 앱보다는 문서의 성질을 띄고 있지만, Ajax같은 동적 기술을 이용할 시 좀 더 사용자 친화적인 문서가 될 수 있다.
2021.07.29 ~ 2021.07.30
완강.
제법 지저분한 필기인데 누가 볼 수도 있다고 생각하니 괜히 긴장된다... 나중에 다시 한번 훑고 싹 정리해봐야겠다.
붐따만큼은... 참아주세요.
