Introduction Data Labeling
Introduction Data Labeling
- Labeling은 확보한 원시 데이터(Raw Data)를 유의미한 작업에 사용하도록 데이터를 만드는 작업이다.
- 예시) 기계학습 또는 딥러닝에서 인공지능이 학습에 필요한 데이터를 만드는 작업이다.
- 레이블링 또는 어노테이션(Annotation), 태깅(Tagging)이라 부르기도 한다.

- Computer Vision에서는 주로 이미지에 필요한 작업(Classification, Detection, ...)에 대해 결과를 미리 입력하는 작업이다.
- 예시) Classification은 이미지에 해당하는 클래스 정보를 입력한다.
- 예시) Detection은 이미지에 대상 객체의 BBOX와 클래스 정보를 입력한다.
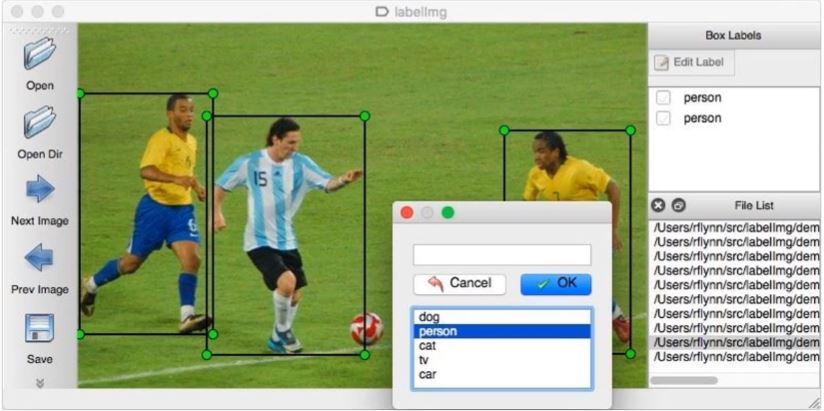
- 이렇게 만들어진 데이터는 모델이 만들어 낼 수 있는 최대 검출(또는 분류) 성능이 될 수 있고, 또 다른 데이터를 만들어내는 재료가 되기도 한다.
- 따라서 데이터를 잘 만드는 것은 매우 중요한 일이고, 잘못된 데이터를 사용하는 것은 잘못된 모델을 선택하는 것보다 결과에 영향을 크게 미친다.
- 예시) 그림과 같은 데이터를 학습한 모델은 사람과 외계인임을 정확하게 구분할 수 있을까?

- 하지만 정확한 데이터를 만드는 작업은 단순하고 반복적인 작업이라 많은 사람들이 기피하는 작업 중 하나이다.
- 이전 강의에서 사용한 BDD100K 데이터를 만들려면 시간이 얼마나 필요할까 ?
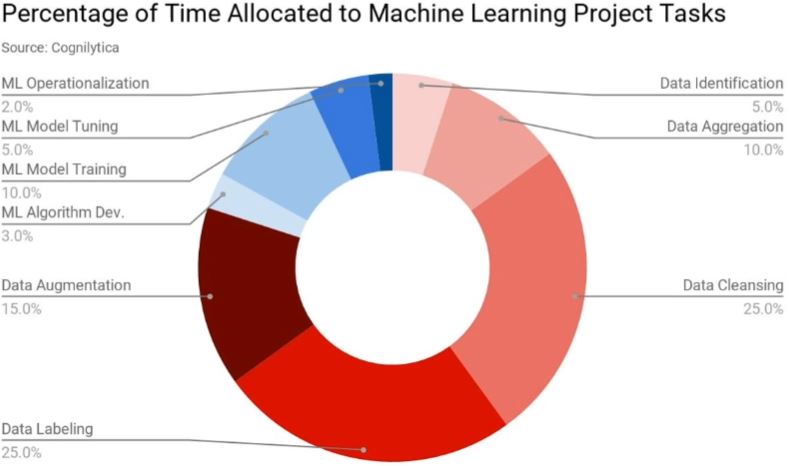
- 이러한 이유로 딥러닝, 머신러닝은 데이터와 관련된 작업을 수행하는데 대부분의 시간을 소비한다.
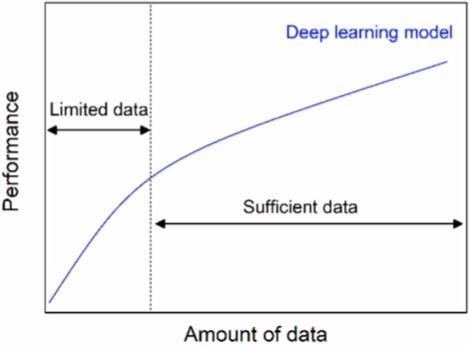
- 현실에서는 다양한 이유로 학습 데이터를 직접 만들 수밖에 없다.
- 각 회사에서 풀어야 하는 문제가 다르다.
- 공개된 데이터셋에 없는/세부적인 객체가 필요한 경우
- 주어진 환경과 조건이 다르다.
- 공개된 데이터셋과 다른 환경에서 문제를 풀어야 하는 경우
- 환경은 늘 변화한다.
- 시간, 날씨, 데이터 취득 환경과 실제 적용 환경, 대상이 변하는 경우 등
- 화창한 여름 도심지 데이터를 학습한 모델이, 눈 내리는 겨울 저녁 도심지 환경에서 사람을 잘 검출할 수 있을까?

- 데이터를 다루는 작업을 피하기란 현실적으로 불가능하다.
- 괴로운 현실을 피할 수 없으면?
작업을 위임한다.
- 어떤 작업을 위임하기 위해서는 데이터 구축 프로세스를 만들어야 한다.
Data Labeling
Data Labeling
- 이미지 데이터를 레이블링 하는 툴은 다수 존재한다.
- 공개 툴: CVAT, labelme, labelmg
- 상용 툴: 레이블링 전문 업체에 따라 다름
CVAT 사용 방법
CVAT 설치 방법(Windows)
- CVAT는 Docker Image를 제공하여 편리하게 설치할 수 있다.
- Windows 10/11 기준: WSL2를 설치하면 윈도우 커널에서 손쉽게 Linux환경을 실행할 수 있다.
- (참고)
- WSL2에서는 GPU Device를 Linux Kernel에서 사용할 수 있기 때문에, Windows환경에서 Linux/Ubuntu 기반의 TensorFlow, PyTorch, CUDA 등 다양한 환경을 구성할 수 있다.
- WSL2와 Docker를 사용하는데 익숙해진다면 환경을 구축하는데 많은 비용이 감소하고, 다른 사람들에게도 손쉽게 실행 가능한 환경을 구축할 수 있다.
(Docker와 Docker-Compose 기반으로 배포하는 이유, 컨테이너 기반 개발 & 배포 환경은 최근 기본 개발 지식으로 자리잡고 있다.)
- Ex) ununtu 18.04를 설치해야 하는데 드라이버가 지원을 안해요.
-> Ubuntu는 모든 것이 파일 시스템 기반이기 때문에 20.04에서 18.04 Docker를 띄워 컨테이너를 만들면 18.04 Ubuntu 버전을 설치할 필요가 없다. (볼륨 마운팅 활용)
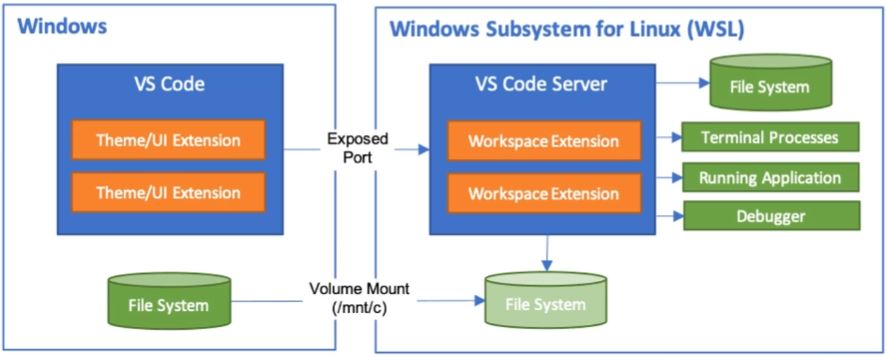
- WSL 설치 참고 홈페이지: https://docs.microsoft.com/en-us/windows/wsl/install
- 페이지를 참고하면 쉽게 설치가 가능하나, 설치 전 윈도우 버전을 반드시 확인한다.
- Docker Desktop을 설치하면 간단하게 Docker와 관련된 프로그램을 설치할 수 있다.
- Windows 10/11기준: Docker Desktop을 설치하면 간단하게 Docker와 관련된 프로그램을 설치할 수 있다.
- Docker-compose와 CVAT Repository를 받아 설치를 진행한다.
CVAT_HOST 환경변수는 만약 외부에서 CVAT에 접속이 필요하다면, CVAT를 실행하려는 컴퓨터의 IP주소를 입력한다.
- Windows: ipconfig
- Ubuntu: ifconfig
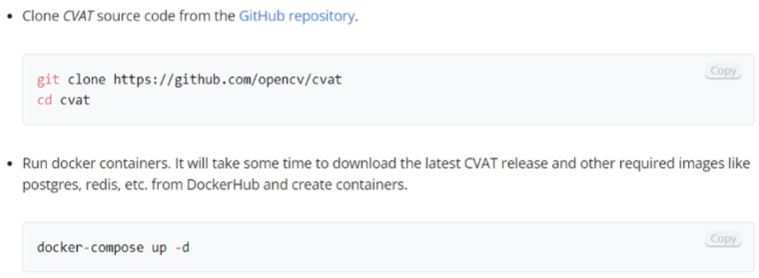
CVAT 설치 방법(Ubuntu)
- Ubuntu: Ubuntu는 Docker Desktop을 지원하지 않아, CLI(Command Line Interface)환경으로 설치해야 한다.
- 설치 홈페이지: https://docs.docker.com/engine/install/ubuntu/
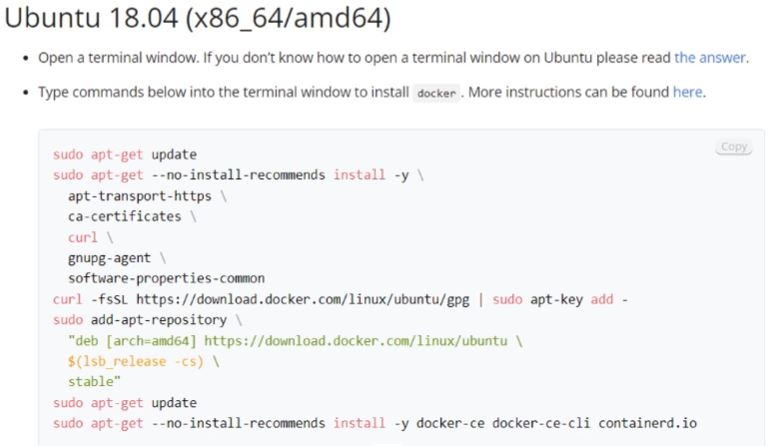
- 만약 Docker를 사용하는데 Permission Error가 발생한다면, sudo 권한 문제가 발생한 것이다.
- Docker-compose와 CVAT Repository를 받아 설치를 진행한다.
CVAT_HOST 환경변수는 만약 외부에서 CVAT에 접속이 필요하다면, CVAT를 실행하려는 컴퓨터의 IP주소를 입력한다.
- Ubuntu: ifconfig
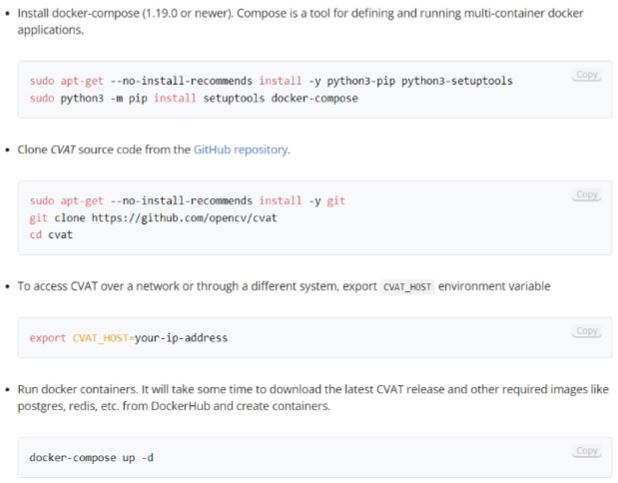
CVAT 사용 방법
- CVAT_HOST를 설정하지 않았다면, 인터넷 브라우저에 다음 주소를 입력한다.
- http://localhost:8080/auth/login
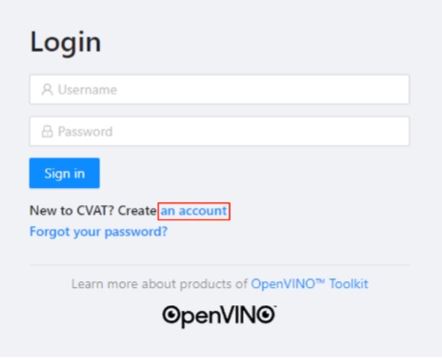
- CVAT_HOST를 설정 했다면 http://{ip주소}:PORT
- 계정을 만들고 로그인을 진행한다.
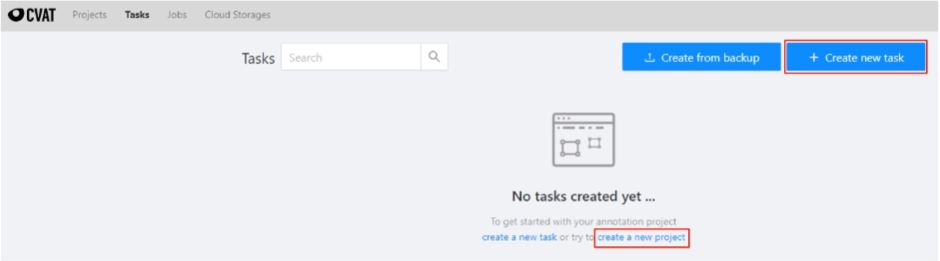
- CVAT는 Tasks 또는 Project 단위로 Labeling을 진행할 수 있다.
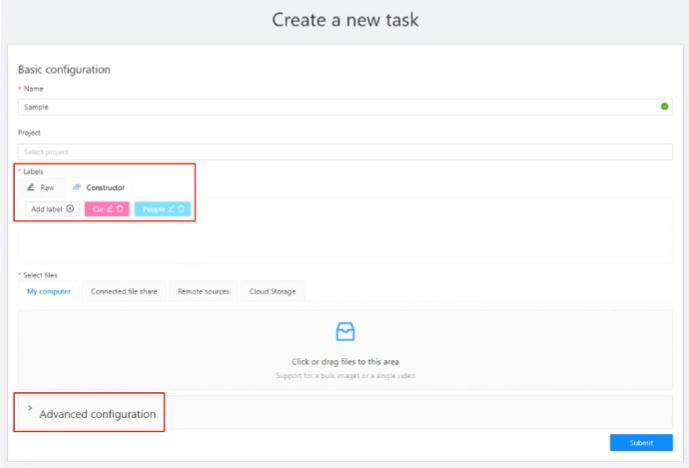
- Tasks를 만들 때 다양한 옵션을 지정할 수 있다.
- Labels: 원하는 클래스를 원하는 색상으로 추가 가능
- Selec files: 이미지를 업로드 하여 Labeling 작업 가능
- Advanced configuration: 이미지 압축 등 세부 설정 가능
- Tasks 목록에서 확인할 수 있다.

- Task는 여러 개의 Job을 가지고 있는데, Job은 Task 생성 시 설정한 이미지 개수로 생성된다.
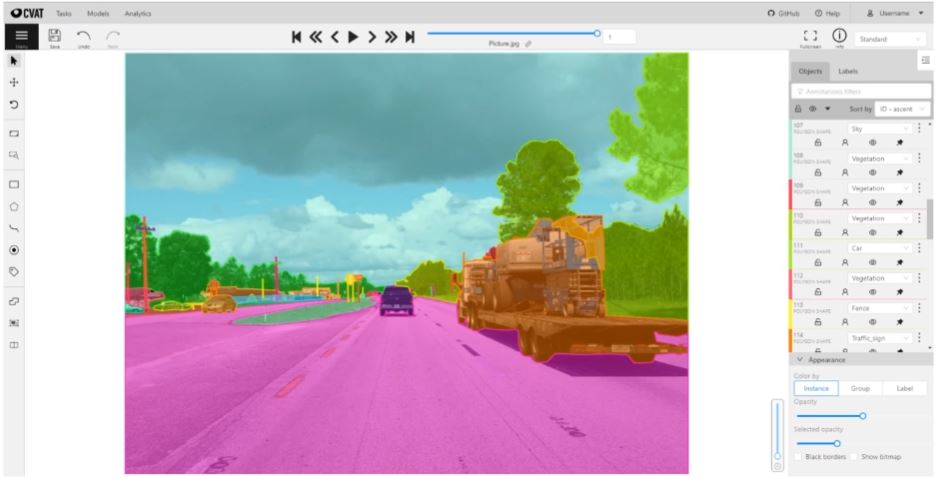
- Cityscape(segmentation) 데이터에 BBOX Labeling 예시

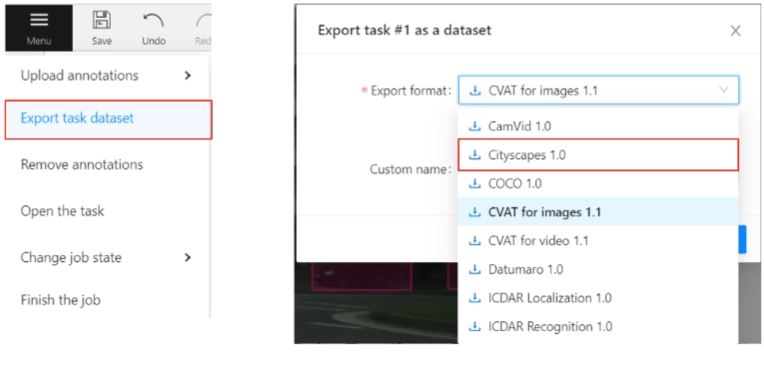
- CVAT는 Labeling 데이터 배포 시 다양한 포맷의 데이터로 변환이 가능하다.
- KITTI, Cityscape, YOLO 등 다양한 포맷이 존재한다.
Data Augmentation
Introduction Data Augmentation
- Data Labeling은 무척 중요한 작업이지만, (정말) 많은 비용과 노력이 들어가는 고단한 작업이다.

- 데이터는 많을수록 좋고, 환경은 변화하기 때문에 언제나 새로운 데이터가 필요하지만, 이 모든 것을 Data Labeling 많으로 해결할 수 없다.
- 따라서 Data Labeling을 최소화 하면서 보다 효과적인 데이터 증강(Data Augmentation) 방법들이 제안되고 있다.
- 참고 논문: A survey on Image Data Augmentation for Deep Learning
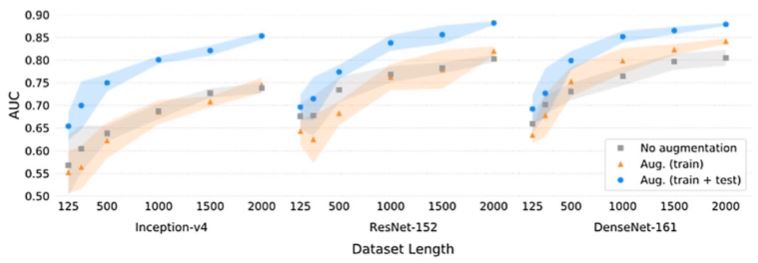
Data Augmentation
- 데이터 증강의 기본 개념은 데이터가 가지고 있는 고유한 특징/특성에 (추가/변경/제거)를 통해 새로운 이미지를 만드는 것이다.
- 대표적인 이미지 색공간(Image Color Space) 변형에 대한 예시
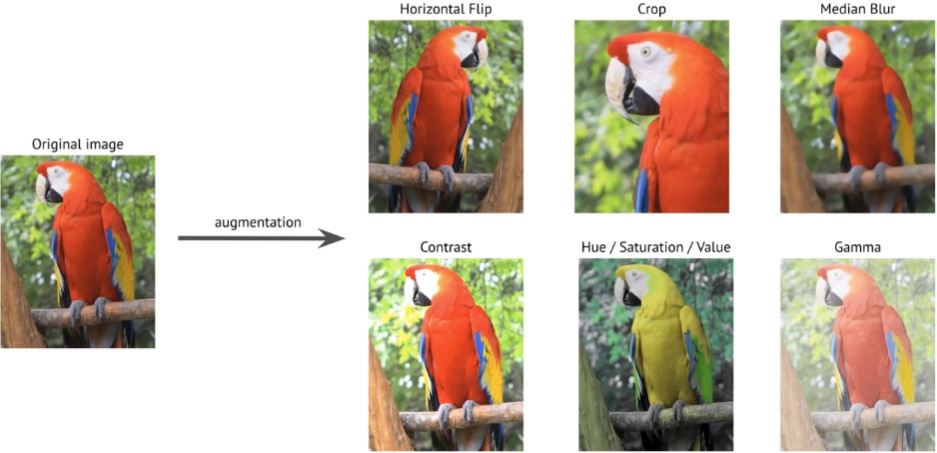

- 이미지 변형
- 색공간 뿐만 아니라 이미지가 가지는 기하학적 형태를 변형하기도 한다.

- 이미지에 왜곡을 넣기도 한다
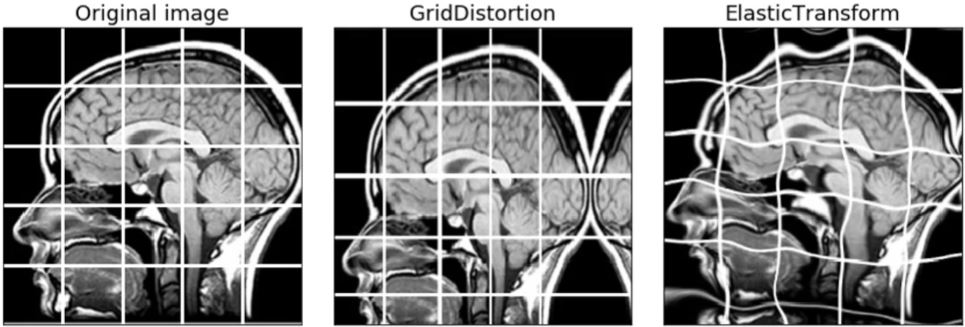
- 이미지 왜곡(Distortin), 노이즈(Noise), 가림(Masking) 등 다양한 데이터 증강 기법을 적용한다면...

- Detection & Segmentation
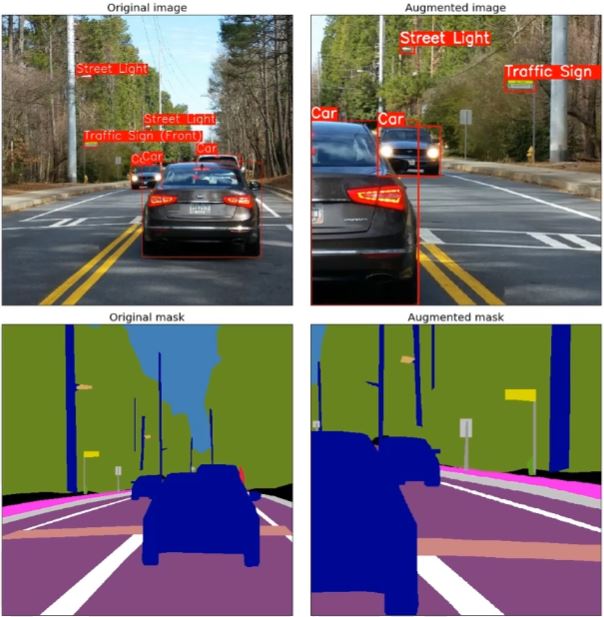
- original data가 10GB라고 가정을 하고, augmentation을 적용하여 데이터를 60배를 불렸다면 600GB일 것이다. 이렇게 적용을 하면 Disc공간을 너무 많이 차지할 것이다. augmentation을 적용하여 파일로 갖고있는 형태가 아니라, 학습단계에서 Dataload를 먼저 하고 그 후 실제 train에 input을 넣어주는 사이에 augmentation이 들어가는 방법을 많이 사용한다. 생각해야 할 것은 1epoch당 1000장을 사용한다고 하면, augmentation을 사용하여 파일 자체를 늘리는 형태이다 라고 한다면 1epoch당 60000장의 이미지를 학습하는 것. 프로그램이 동작을 할때 runtime으로 넣겠다 라고 하는것은 1epoch당 1000장이 그대로 들어가게 된다. augmentation 적용 기법에 따라서 단순한 epoch 사이즈를 늘려주어야 하는 경우도 있고, 이미지 자체, 데이터 자체를 늘려준 경우에는 동일한 1epoch를 수행하면 된다.
예를 들어 augmentation을 너무 만힝 적용하여 진행을 하였는데 dataloader 다음에 데이터를 입력으로 집어넣는 구간에 augmentation을 적용했다고 하면 1epoch당 학습하는 갯수는 전혀 늘어나지 않는다. 그렇게 되면 원본 이미지가 가장 표현력이 좋은 이미지가 될테고, augmentation을 적용하면 표현력이 떨어질 수 밖에 없을것이다.
augmentation을 적용하는 방법에 따라서 몇 epoch을 돌릴지 늘려주는 등 (기존은 10epoch을 돌렸다 -> augmentation을 적용하여 40epoch을 돌렸다) 신경을 써주어야 한다.
- 데이터 증강은 추가적인 데이터 제작 없이 모델 성능을 확보할 수 있는 방법 중 하나이지만, 사용하는데 주의가 필요하다.
- 예시) 색상 정보를 활용하는 데이터 색공간 변형이 적용되면 모델 어떻게 될까?

- 데이터 증강 기법들을 사전 검토 없이 우선 적용해보는 것이 아닌, 보유한 데이터와 모델의 목적을 고려하여 적절한 데이터 증강 기법을 적용해야 한다.
- 유용한 데이터 증강 라이브러리
- imgaug: https://github.com/aleju/imgaug
- Albumentations: https://albumentations.ai/
