
1. 객체배열
객체 여러 개 생성
여러 개의 객체를 배열로 관리하기 위함이다.
* 배열
* 같은 타입의 여러개의 데이터 관리하려고
*
* 구조체(자바에는 없음)
* 여러개의 데이터 관리(타입 상관 x)
*
* 클래스(c언어 구조체의 단점을 보완)
* 여러개의 데이터 + 메소드
*
* 객체배열
* 여러개의 객체를 관리하려고 (같은타입)
-
객체배열을 사용하게 되면
Person p1 = new Person();
Person p2 = new Person();
Person p3 = new Person();
Person p4 = new Person();
Person p5 = new Person();
p1.name = "피원";
p2.name = "피투";
p3.name = "피삼";
p4.name = "피사";
p5.name = "피오";
p1.introduce();
p2.introduce();
p3.introduce();
p4.introduce();
p5.introduce();
다음과 같이 번거롭게 객체를 일일이 만들지 않아도 배열을 통해 객체를 만들어 코드사용을 줄일 수 있다. for문과 반복문을 사용할 수 있는 장점도 있다.
.
.
.
.
객체배열을 만들게 되면...
5개의 객체(Person 타입) 를 관리할 예정, 배열을 이용해서 생성
즉,
--->
객체배열 ======== 클래스명 배열명 [] =new 클래스명[객체 수];
**Person [] pArr = new Person[5];**
pArr[0] = new Person();
pArr[1] = new Person();
pArr[2] = new Person();
pArr[3] = new Person();
pArr[4] = new Person();
(for 문을 사용한다면
for(int i = 0; i < pArr.length; i++) {
pArr[i] = new Person();
}
처럼 만들 수도 있다.)
pArr[0].name ="피원";
pArr[1].name ="피투";
pArr[2].name ="피삼";
pArr[3].name ="피사";
pArr[4].name ="피오";
pArr[0].introduce();
pArr[1].introduce();
pArr[2].introduce();
pArr[3].introduce();
pArr[4].introduce();
가독성과, 코드사용 부분에서 객체배열을 사용했을 때 더 깔끔하게 정리된 것을 알 수 있다.
2. 생성자
- (1) 생성자
[접근제한자] 클래스명(매개변수는 0개 이상) {객체가 생성되늰 순간 실행하고 싶은 내용}
객체를 생성하려면 생성자를 호출해야 한다. 어떤 것이 객체를 만드는 것인가? 생성자 !!
-
(2) <기본생성자>
(== 즉, 호출자임, 객체를 만들기만 하고 호출을 안하면 생성이 안된다.)
ex) public Test() { }
-->new Test();가 이 기본생성자를 호출하게 되면 객체가 생성되는 것이다.. -
(3) <매개변수가 있는 생성자>
(==생성자 오버로딩)
ex) public Test(int x){}
-->자바에서는 클래스 이름이 같아도 매개변수가 다르면 에러가 나지 않는다 -
✅ 정리 ✅
클래스에 매개변수가 있는 생성자를 만들면 기본생성자가 자동으로 생기지 않는다.기본생성자가 항상 자동으로 생기는 것은 아니고, 아무런 생성자를 작성하지 않았을 때만 생긴다.(클래스 내에 생성자가 하나도 없을 때 생기는 것이다.
따라서 매개변수가 있는 생성자가 클래스 내에 있으면 기본생성자가 따로 생기는 것이 아니다.)
3. 오버로딩
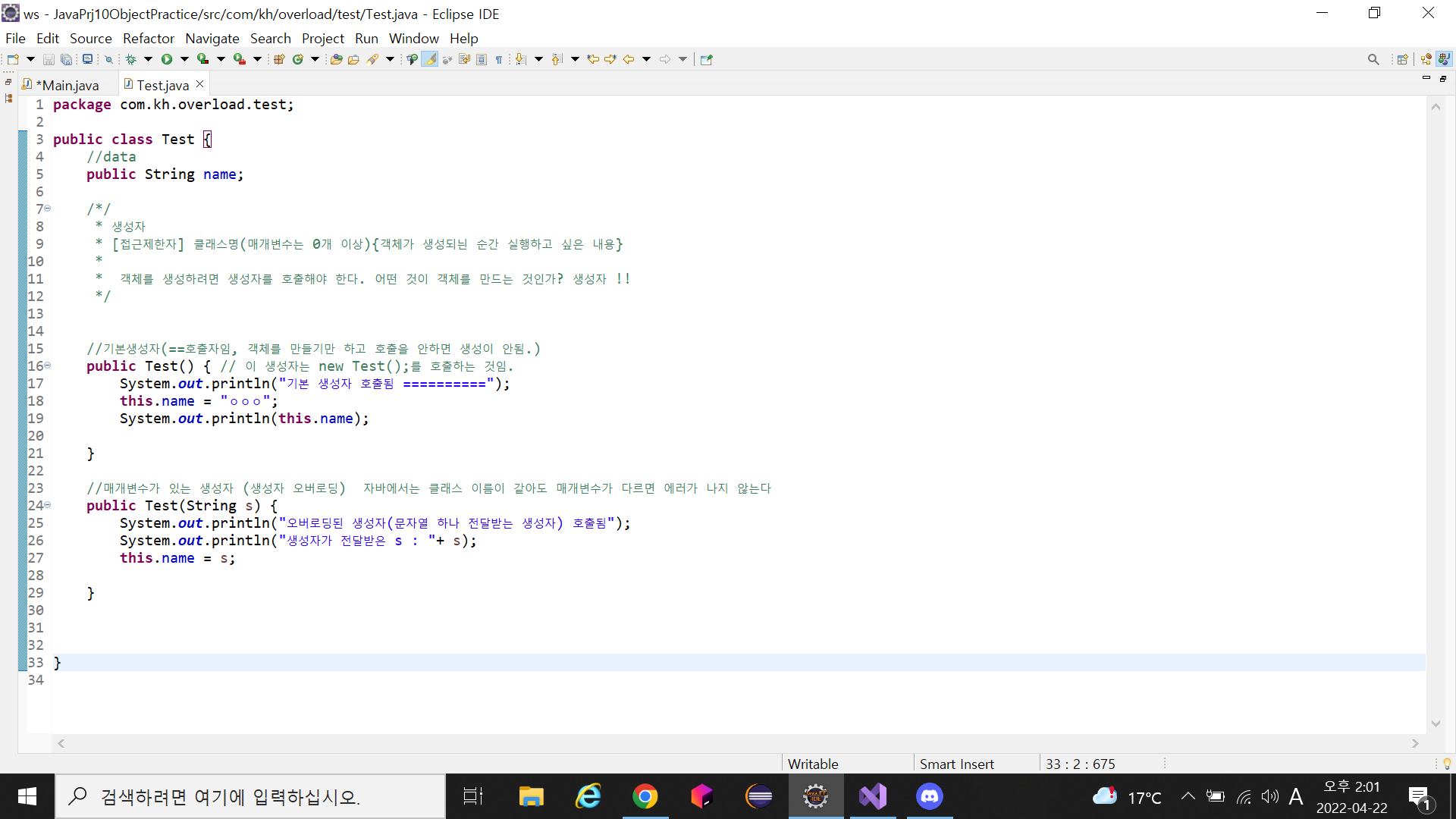
이때, 그림처럼 같은 Test 클래스 내에 똑같은 Test메소드가 있어도 에러가 나지 않는 것은 매개변수가 있으면 컴퓨터는 이름이 같은 메소드라도 다른 것으로 인식을 하기 때문이다.
이를 메서드 오버로딩이라고 한다.
(쉽게 같은 이름의 메소드를 여러 개 만드는 것이라고 생각하면 된다.)
(이때, 리턴타입은 오버로딩과는 상관없다.
-->public void hi(); 이거나 public int hi(); 이거나 컴퓨터는 같게 인식한다.)
오버로딩이 안되는 경우
동일한 메소드를 만들 경우
반환 자료형만 다를 경우
접근 제한자를 다르게 만들 경우
접근 제한자와 반환자료형은 오버로딩과 상관 없다. 달라도 의미가 없다는 것.
