[AI로 사람 목소리를 만들어낼 수 있다고?] - Text-to-Speech (1)

아무것도 모르고 시작한 졸업 프로젝트...'어떻게든 되겠지'라는 마인드로 시작한지 벌써 3개월이 다 되어가네요. 어찌저찌 주제를 정했고(거의 10번은 넘게 바꾼 듯한 느낌이....😂) 이제 정말로 본격적으로 개발을 시작해야 하는데요, 그 과정을 포스트로 남겨보려고 합니다.
프로젝트 주제는,
"이미지 생성 AI 기반 숏폼 형식 단어 학습 플랫폼" 입니다.
소설을 만들고, 그 소설을 읽어주는 목소리를 영상이 입히려고 합니다. 이미 시중에 네이버의 클로바더빙 같은 TTS 서비스가 많이 나와있는데, 이런 서비스들은 음성을 만들 수 있는 횟수가 제한되어 있기 때문에 직접 만들어서 사용하기로 했습니다. (앱을 만들어서 출시했는데, 숏폼 하나 만들 때마다 구독료를 지불할 수는 없으니까요...!)
TTS 모델 고르기 - 1) Tacotron2 + WaveGlow
TTS는 역사가 긴 기술이고, 그래서 개발되어 있는 모델이 굉장히 많아서 어떤 모델을 사용해야할 지 정하는 게 꽤나 머리가 아팠습니다.
복잡한 절차가 필요했던 예전과 달리, 요즘은 <문장, 음성> 데이터쌍만 있으면 딥러닝으로 이를 학습해서 음성을 합성할 수 있습니다.
첫 번째로 시도해본 모델은 Tacotron2와 WaveGlow 조합입니다. 이 조합을 선택한 이유는
- 공부하는 차원에서 직접 해보면서 이해하기 위해(생각보다 신호처리 분야 개념을 잘 알아야 하더라구요...)
- NVIDIA에서 LJ Speech 음성 데이터셋으로 사전 학습한 모델을 제공하여 빠르게 만들어볼 수 있음
- Checkpoint를 제공하여 데모용으로 좋음
이정도..라고 할 수 있겠네요.
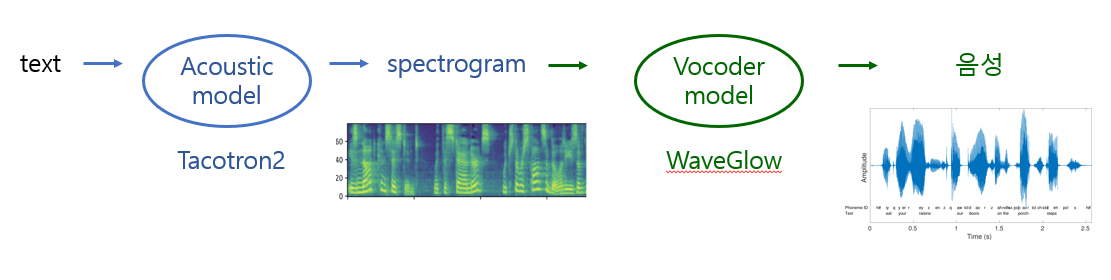
모델의 구조
이 친구는 2개의 neural net으로 구성되어 있습니다.
-> Acoustic model + Vocoder model
Acoustic model은 text를 spectrogram으로 바꾸는 작업을 하고,
Vocoder model은 spectrogram을 실제 음성(Waveform)으로 바꾸는 작업을 해요.
Acoustic model과 Vocoder model은 따로 학습을 시켜야 합니다.
이걸 그림으로 정리하면 이렇습니다.
👉구현을 해보자🤔
이제 실제로 해보겠습니다.
NVIDIA가 공개한 오픈소스를 이용하면 ⭐‼아주아주 쉽게‼⭐ 테스트해볼 수 있습니다. 저는 Google Colab으로 코드를 돌려보았는데요, Google Colab을 쓰면 ⭐‼무료로‼⭐ GPU를 사용할 수 있기 때문에 추천합니다!
라이브러리 준비하기
우선, text와 audio 데이터를 전처리하기 위해 필요한 파이썬 패키지를 설치합니다.
pip install numpy scipy librosa unidecode inflect librosa생성한 음성을 파일로 저장하기 위한 라이브러리를 import 합니다.
import numpy as np
from scipy.io.wavfile import writeAcoustic model과 Vocoder model 준비하기
Acoustic model은 Tacotron2를 사용할 것입니다.
LJ Speech 음성 데이터셋으로 학습한 Tacotron2 model을 PyTorch Hub에서 불러옵니다.
import torch
tacotron2 = torch.hub.load('nvidia/DeepLearningExamples', 'nvidia_tacotron2')
tacotron2 = tacotron2.to('cuda')
tacotron2.eval()Vocoder model은 WaveGlow를 사용합니다. 위와 똑같이 학습된 WaveGlow model를 불러옵니다.
waveglow = torch.hub.load('NVIDIA/DeepLearningExamples:torchhub', 'nvidia_waveglow')
waveglow = waveglow.remove_weightnorm(waveglow)
waveglow = waveglow.to('cuda')
waveglow.eval()스크립트 파일 불러오기
이제 내가 음성으로 합성하고 싶은 텍스트를 불러옵니다.
Google Colab에서 파일을 불러오는 방법은 2가지가 있습니다.
방법1: 로컬 파일 직접 업로드
from google.colab import files
uploaded = files.upload()다음과 같이 코드를 실행하면,
요렇게 생긴 콘솔창이 뜹니다.
저는 미리 만들어 놓은 텍스트 파일을 업로드했습니다.
방법2: 구글 드라이브 연동
from google.colab import drive
drive.mount('/content/drive')''안에는 mount할 구글 드라이브 경로를 씁니다.

코드를 실행하면 이런 창이 뜨고요, 연결하면 됩니다.
파일을 불러왔으니 파일을 읽습니다.
with open('text.txt') as file_object:
contents = file_object.read()Inference
이제 Tacotron2와 Waveglow를 chain으로 연결해서 실행합니다.
with torch.no_grad():
mel, _, _ = tacotron2.infer(sequences, lengths)
audio = waveglow.infer(mel)
audio_numpy = audio[0].data.cpu().numpy()
rate = 25000from scipy.io.wavfile import write
write("tacotron2_waveglow_test1.wav", rate, audio_numpy)그러면 합성한 음성 파일이 생긴 것을 확인할 수 있습니다‼‼
합성 결과를 들어보니 아주 약간의 노이즈가 있는 것을 제외하면 나쁘지 않았습니다. 다만, Tacotoron2는 음성 생성 길이가 약 11초 정도로 제한되어 있어서 숏폼에 입히려면 만든 음성을 여러 개 이어붙여서 사용해야할 것 같네요.
아래는 전체 코드입니다.
#라이브러리
pip install numpy scipy librosa unidecode inflect librosa
import numpy as np
from scipy.io.wavfile import write
#tacotron2 model
import torch
tacotron2 = torch.hub.load('nvidia/DeepLearningExamples', 'nvidia_tacotron2')
tacotron2 = tacotron2.to('cuda')
tacotron2.eval()
#WaveGlow model
waveglow = torch.hub.load('NVIDIA/DeepLearningExamples:torchhub', 'nvidia_waveglow')
waveglow = waveglow.remove_weightnorm(waveglow)
waveglow = waveglow.to('cuda')
waveglow.eval()
#음성으로 합성할 파일 불러오기
from google.colab import files
uploaded = files.upload()
with open('text.txt') as file_object:
contents = file_object.read()
#Inference
with torch.no_grad():
mel, _, _ = tacotron2.infer(sequences, lengths)
audio = waveglow.infer(mel)
audio_numpy = audio[0].data.cpu().numpy()
rate = 25000
from scipy.io.wavfile import write
write("tacotron2_waveglow_test1.wav", rate, audio_numpy) 👇구글 코랩 링크
https://colab.research.google.com/drive/1zHBGgWe39y6pSi7T16i54w7l3lDvX19p?usp=sharing
실제 결과가 어떻게 나왔는지 궁금하시다면, 링크를 통해 확인해보세요!
‼2탄 예고‼
두 번째로 테스트해볼 모델은 작년 9월 구글이 공개한 오디오 생성을 위한 언어모델 AudioLM입니다.
AudioLM의 구조는 첫 번째로 테스트했던 모델과 좀 다르게 생겼는데요, 자세한 이야기는 2탄에서 풀도록 하겠습니다~~~!🤩

잘 읽었어요~