
지난 3월부터 종강일까지 열심히 달려왔던 저희 팀은 긴 고민 끝에 주제를 변경하게 되었습니다....! 그동안 많은 일이 있었지만.... 거두절미하고 주제부터 소개하겠습니다😁
프로젝트 주제는,
"한국어 텍스트 모델 기반 여행 가이드 어플리케이션" 입니다.
수많은 관광지에 대한 음성 가이드와 가이드 스크립트를 제공하기 위해, 방대한 양의 관광지 관련 텍스트를 요약해주는 인공지능 모델을 만들게 되었습니다.
이번에 사용하려는 모델은 KoBart입니다.
BART(Bidirectional and Auto-Regressive Transformers)는 노이즈를 추가하여 손상된 텍스트를 인코더에 입력하고, 인코더에서 학습한 텍스트 표현을 디코더로 보내 원문으로 복구하는 방식으로 학습을 합니다. KoBart(한국어 Bart)는 STK에서 40GB 이상의 한국어 텍스트에 대해서 학습한 한국어 encoder-decoder 언어 모델입니다.

👉구현을 해보자🤔
⭐준비물⭐
1) Training data & Test data
2) Pre-trained KoBart model
3) Google colab
4) 인내심..!
✔️Step 1
Training data & (Validation data) & Test data 준비

Training data는 AI hub의 '요약문 및 레포트 생성 데이터'를 사용했습니다. (아래 링크에서 다운받을 수 있습니다.)
https://aihub.or.kr/aihubdata/data/view.do?currMenu=115&topMenu=100&aihubDataSe=realm&dataSetSn=582

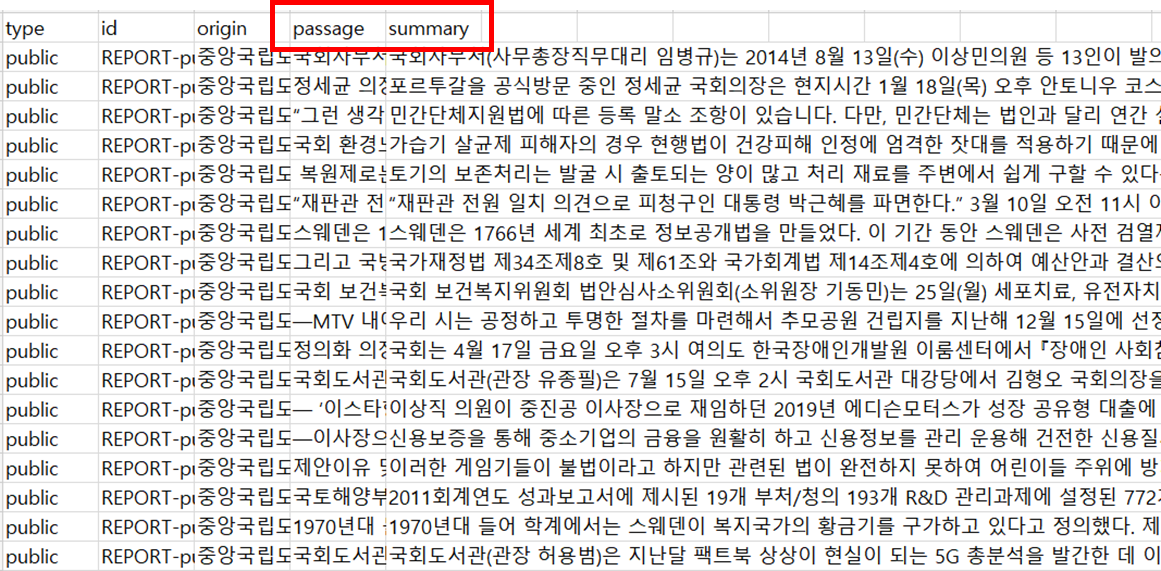
데이터 구조는 위와 같습니다. 저는 다양한 카테고리의 데이터 중에서 만들고자 하는 가이드 스크립트와 성격이 유사한 역사와 문화재 관련 문서 요약 데이터 약 10,000개만 추출하여 사용했습니다.
그리고 데이터를 잘 보면 요약문이 추출요약과 생성요약 2종류가 있는데요, 생성요약(Abstractive summary)은 불완전하고 사실 불일치한 문장을 생성할 가능성이 있다는 점을 고려하여 추출요약(extractive summary)을 사용했습니다.


다운받은 데이터를 열어보면 이렇게 생겼는데요, 학습을 시킬 때에는 데이터를 (원문 텍스트, 요약문) 쌍의 형태로 넣어줄 것이므로 약간의 전처리를 해주었습니다.

동일한 방식으로 Validation data와 Test data도 준비했습니다. 모델의 generalization error를 낮추기 위해 validation data와 test data는 역사, 문화재 카테고리와 성격이 다른 간행물 문서 데이터를 전처리하여 사용했습니다.

✔️Step 2
오픈소스 pre-trained KoBart model 준비
https://github.com/SKT-AI/KoBART
SKT에서 제공하는 오픈소스로, 위 링크에서 받을 수 있습니다.


✔️Step 3
Google colab 환경 설정 및 학습 준비
먼저 구글 드라이브를 연동합니다.
from google.colab import drive
drive.mount('/content/drive')' '안에는 mount할 구글 드라이브 경로를 써줍니다. 코드를 실행하면 아래와 같은 창이 뜨고요, 연결해주면 됩니다. 
import os
os.chdir('/content/drive/MyDrive/KoBART-summarization-main/KoBART-summarization-main')그리고 현재 위치를 pre-trained model이 있는 곳으로 변경해줍니다.
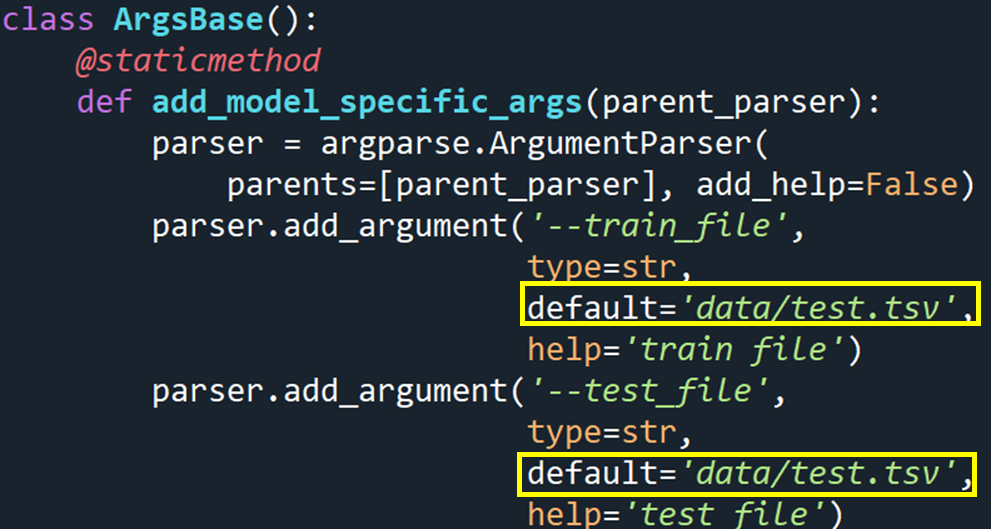
오픈소스의 train.py의 일부입니다. Training data 파일의 확장자가 기본으로 tsv로 되어 있으므로, csv로 준비했던 데이터를 tsv로 변환해주겠습니다. 코드는 아래와 같아요.
#csv는 구분자가 콤마(,)이고, tsv는 구분자가 탭(\t)
#train_data
import pandas as pd
import shutil
path = '/content/drive/MyDrive/his+public+data/TrainingPassages_his-cul.csv'
df = pd.read_csv(path, sep = ",", engine='python', encoding = "utf-8")
df.dropna(axis=0)
df.to_csv('train.tsv', sep='\t', encoding="utf-8", index=False)
# 원본 파일 경로
source_file = '/content/drive/MyDrive/KoBART-summarization-main/KoBART-summarization-main/train.tsv'
# 이동할 위치의 폴더 경로
destination_folder = '/content/drive/MyDrive/KoBART-summarization-main/KoBART-summarization-main/data/'
# 파일 이동
shutil.move(source_file, destination_folder)Training data와 Test data 모두 변환을 해주었습니다.
이제 학습에 필요한 라이브러리들을 설치해줍니다.
pip install -r requirements.txt
!pip install transformers==3.5.1
!pip install loguru
!pip install lightning==2.0.8
!pip install tokenizers==0.13.3
자, 드디어 학습을 시작할 준비가 끝났습니다~!
✔️Step 4
Finetuning
다시, train.py를 보겠습니다.

'every_n_epochs' 부분을 설정하면 몇 epoch 마다 checkpoint를 저장할 것인지를 정할 수 있습니다. 저는 사전학습된 모델을 finetuning하는 것이므로, 자주 checkpoint를 생성할 필요는 없어서 25정도로 설정해주었습니다.
이제, 다음 코드를 돌려서 학습을 시킵니다.
!python train.py --gradient_clip_val 1.0 \
--max_epochs 100 \
--checkpoint checkpoint \
--accelerator gpu \
--num_gpus 1 \
--batch_size 4 \
--num_workers 4 Gradiant clipping은 1, epoch는 100, batch size는 4, data loading에 사용되는 subprocess는 4개로 하여 1개의 GPU로 train을 했습니다.

Training이 진행되고 있는 모습입니다.




학습이 잘 된 거 같네요!😊
✔️Step 5
요약해보기
이제 학습한 모델을 사용해서 텍스트를 요약해보겠습니다.
일단 학습한 모델을 불러옵니다. 이때, 학습한 model binary 추출 작업을 해야합니다.
import torch
from transformers import PreTrainedTokenizerFast
from transformers.models.bart import BartForConditionalGeneration
!python get_model_binary.py --model_binary '/content/drive/MyDrive/KoBART-summarization-main/KoBART-summarization-main/checkpoint/summarization_final/epoch=99-val_loss=0.000.ckpt'
# 모델 바이너리 파일 경로
model_binary_path = '/content/drive/MyDrive/KoBART-summarization-main/KoBART-summarization-main/kobart_summary'
# KoBART 모델 및 토크나이저 로드
tokenizer = PreTrainedTokenizerFast.from_pretrained('gogamza/kobart-base-v1')
model = BartForConditionalGeneration.from_pretrained(model_binary_path)
저는 다음 텍스트를 요약해보겠습니다.
[원문]
광화문(光化門)은 서울특별시 종로구의 조선왕조 법궁인 경복궁의 남쪽에 있는 정문이다. "임금의 큰 덕(德)이 온 나라를 비춘다"는 의미이다. 1395년에 세워졌으며, 2층 누각 구조로 되어 있다. 경복궁의 정전인 근정전으로 가기 위해 지나야 하는 문 3개 중에서 첫째로 마주하는 문이며, 둘째는 흥례문, 셋째는 근정문이다. 광화문 앞에는 지금은 도로 건설로 사라진 월대가 자리잡고 있었으며, 양쪽에는 한 쌍의 해태 조각상이 자리잡고 있다. 광화문의 석축부에는 세 개의 홍예문(虹霓門, 아치문)이 있다. 가운데 문은 임금이 다니던 문이고, 나머지 좌우의 문은 신하들이 다니던 문이었는데, 왼쪽 문은 무신이, 오른쪽 문은 문신이 출입했다. 광화문의 가운데 문 천장에는 주작이 그려져 있고, 왼쪽 문에는 거북이가, 오른쪽 문에는 천마가 그려져 있다.
# 입력 텍스트
input_text = """
광화문(光化門)은 서울특별시 종로구의 조선왕조 법궁인 경복궁의 남쪽에 있는 정문이다. "임금의 큰 덕(德)이 온 나라를 비춘다"는 의미이다. 1395년에 세워졌으며, 2층 누각 구조로 되어 있다. 경복궁의 정전인 근정전으로 가기 위해 지나야 하는 문 3개 중에서 첫째로 마주하는 문이며, 둘째는 흥례문, 셋째는 근정문이다. 광화문 앞에는 지금은 도로 건설로 사라진 월대가 자리잡고 있었으며, 양쪽에는 한 쌍의 해태 조각상이 자리잡고 있다. 광화문의 석축부에는 세 개의 홍예문(虹霓門, 아치문)이 있다. 가운데 문은 임금이 다니던 문이고, 나머지 좌우의 문은 신하들이 다니던 문이었는데, 왼쪽 문은 무신이, 오른쪽 문은 문신이 출입했다. 광화문의 가운데 문 천장에는 주작이 그려져 있고, 왼쪽 문에는 거북이가, 오른쪽 문에는 천마가 그려져 있다.
"""
# 입력 텍스트를 토큰화하여 인코딩
input_ids = tokenizer.encode(input_text, return_tensors="pt", max_length=1024, truncation=True)
# 모델을 사용하여 요약 생성
summary_ids = model.generate(input_ids, max_length=150, min_length=40, length_penalty=2.0, num_beams=4, early_stopping=True)
# 요약 결과 디코딩
summary_text = tokenizer.decode(summary_ids[0], skip_special_tokens=True)
# 요약 출력
print("요약 텍스트:", summary_text)다음과 같이 요약이 되었네요!

[요약문]
광화문(光化門)은 서울특별시 종로구의 조선왕조 법궁인 경복궁의 남쪽에 있는 정문이다. "임금의 큰 덕(德)이 온 나라를 비춘다"는 의미이다. 광화문 앞에는 지금은 도로 건설로 사라진 월대가 자리잡고 있었으며, 양쪽에는 한 쌍의 해태 조각상이 자리잡고 있다. 광화문의 석축부에는 세 개의 홍예문(虹霓門, 아치문)이 있다. 가운데 문은 임금이 다니던 문이고, 나머지 좌우의 문은 신하들이 다니던 문이었는데, 왼쪽 문은 무신이, 오른쪽 문은 문신이 출입했다.
👇아래는 전체 코드입니다.
from google.colab import drive
drive.mount('/content/drive')
import os
# 현재 위치를 변경
os.chdir('/content/drive/MyDrive/KoBART-summarization-main/KoBART-summarization-main')
#csv는 구분자가 콤마(,)이고, tsv는 구분자가 탭(\t)
#train_data
import pandas as pd
path = '/content/drive/MyDrive/his+public+data/TrainingPassages_his-cul.csv'
df = pd.read_csv(path, sep = ",", engine='python', encoding = "utf-8")
df.dropna(axis=0)
df.to_csv('train.tsv', sep='\t', encoding="utf-8", index=False)
import shutil
# 원본 파일 경로
source_file = '/content/drive/MyDrive/KoBART-summarization-main/KoBART-summarization-main/train.tsv'
# 이동할 위치의 폴더 경로
destination_folder = '/content/drive/MyDrive/KoBART-summarization-main/KoBART-summarization-main/data/'
# 파일 이동
shutil.move(source_file, destination_folder)
#test_data
path = '/content/drive/MyDrive/his+public+data/TestPassages_public.csv'
df = pd.read_csv(path, sep = ",", engine='python', encoding="utf-8")
df.dropna(axis=0)
df.to_csv('test.tsv', sep='\t', encoding="utf-8", index=False)
source_file = '/content/drive/MyDrive/KoBART-summarization-main/KoBART-summarization-main/test.tsv'
destination_folder = '/content/drive/MyDrive/KoBART-summarization-main/KoBART-summarization-main/data/'
shutil.move(source_file, destination_folder)
pip install -r requirements.txt
!pip install transformers==3.5.1
!pip install loguru
!pip install lightning==2.0.8
!pip install tokenizers==0.13.3
# Training
!python train.py --gradient_clip_val 1.0 \
--max_epochs 100 \
--checkpoint checkpoint \
--accelerator gpu \
--num_gpus 1 \
--batch_size 4 \
--num_workers 4
!python get_model_binary.py --model_binary '/content/drive/MyDrive/KoBART-summarization-main/KoBART-summarization-main/checkpoint/summarization_final/epoch=09-val_loss=0.001_news.ckpt'
import torch
from transformers import PreTrainedTokenizerFast
from transformers.models.bart import BartForConditionalGeneration
#from transformers import BartTokenizer
# 모델 바이너리 파일 경로
model_binary_path = '/content/drive/MyDrive/KoBART-summarization-main/KoBART-summarization-main/kobart_summary'
# KoBART 모델 및 토크나이저 로드
tokenizer = PreTrainedTokenizerFast.from_pretrained('gogamza/kobart-base-v1')
model = BartForConditionalGeneration.from_pretrained(model_binary_path)
# 입력 텍스트
input_text = """
광화문(光化門)은 서울특별시 종로구의 조선왕조 법궁인 경복궁의 남쪽에 있는 정문이다. "임금의 큰 덕(德)이 온 나라를 비춘다"는 의미이다. 1395년에 세워졌으며, 2층 누각 구조로 되어 있다. 경복궁의 정전인 근정전으로 가기 위해 지나야 하는 문 3개 중에서 첫째로 마주하는 문이며, 둘째는 흥례문, 셋째는 근정문이다. 광화문 앞에는 지금은 도로 건설로 사라진 월대가 자리잡고 있었으며, 양쪽에는 한 쌍의 해태 조각상이 자리잡고 있다. 광화문의 석축부에는 세 개의 홍예문(虹霓門, 아치문)이 있다. 가운데 문은 임금이 다니던 문이고, 나머지 좌우의 문은 신하들이 다니던 문이었는데, 왼쪽 문은 무신이, 오른쪽 문은 문신이 출입했다. 광화문의 가운데 문 천장에는 주작이 그려져 있고, 왼쪽 문에는 거북이가, 오른쪽 문에는 천마가 그려져 있다.
"""
# 입력 텍스트를 토큰화하여 인코딩
input_ids = tokenizer.encode(input_text, return_tensors="pt", max_length=1024, truncation=True)
# 모델을 사용하여 요약 생성
summary_ids = model.generate(input_ids, max_length=150, min_length=40, length_penalty=2.0, num_beams=4, early_stopping=True)
# 요약 결과 디코딩
summary_text = tokenizer.decode(summary_ids[0], skip_special_tokens=True)
# 요약 출력
print("요약 텍스트:", summary_text)
안녕하세요! 혹시 파이참으로 실행해도 오류가 안날까요?