서버를 재시작하였더니 저장했던 유저의 정보가 사라지는 일이 발생한다. POST API를 통해 생긴 유저 정보는 RAM에 저장이 되는데, 서버가 종료되면 RAM에 있는 정보(단기기억)이 사라진다.
그래서 DataBase를 사용하여 유저 정보를 저장하면 이 문제를 해결할 수 있다.
여기서 사용할 DataBase는 MySQL이고 관계형 데이터베이스인 RDB에 속한다.
관계형 데이터 베이스란 데이터를 표처럼 구조화시켜 저장하며 SQL이라는 언어를 사용하여 데이터를 조회한다.
Intellij 유료 버전을 사용하면 Intellij 내에서 MySQL을 사용할 수 있지만, 무료 버전이기 때문에 Command Line Client(CLI)를 사용하여 MySQL을 사용하겠다.
1. MySQL에서 테이블 만들기
데이터베이스를 엑셀 문서를 만드는 것에 비유하면 이해하기 편하다.
엑셀 문서를 만들기 전 폴더를 생성하고 그 폴더에 새로운 엑셀 파일을 생성한다. 데이터베이스도 비슷한 과정으로 저장 공간을 생성한다.
1) 테이블의 형식
우선, 이름을 지정하여 새로운 데이터베이스를 만들고(=폴더 생성) 생성한 데이터베이스 내부에 새로운 테이블을 생성한다.
테이블이 생성할 때 특정한 형식을 맞추어야 한다.
create table 테이블 이름(
필드1 이름 + 타입 + 부가조건,
필드2 이름 + 타입 + 부가조건,
필드3 이름 + 타입 + 부가조건,
....
primary key([필드이름])
);
필드는 변수명이라 생각하면 되고 임의로 지어도 상관없다. 하지만, 타입은 정해져 있다. 자바에서 변수 타입이 있듯이 MySQL에도 필드 타입이 있는데 자바와 조금 다르다.
대표적인 예로 자바의 int, long, String 타입이 MySQL에서는 int, bigint, varchar(글자수)로 사용하며 날짜를 의미하는 타입인 date도 있다.
<MySQL 필드 타입>
1.정수타입
tinyint 1바이트 정수
int 4바이트 정수
bigint 8바이트 정수
2.실수타입
double 8바이트 정수
decimal(A,B) 소수점을 B개 가지고 있는 전체 A자릿수 실수
3.문자열 타입
char(A) A개의 글자가 들어갈 수 있는 문자열
varchar(A) 최대 A 글자가 들어갈 수 있는 문자열
4.날짜, 시간 타입
date 날짜
time 시간
datetime 날짜 + 시간
부가 조건은 필수적으로 입력하지 않아도 되며 필요시 사용한다. 대표적인 예로 auto_increment를 사용하면 데이터를 명시적으로 넣지 않더라도 1부터 시작해서 1씩 증가하여 자동으로 기록된다.
마지막으로 primary key(필드) 는 어떤 기능을 할까?
사과라는 데이터를 2개 생성하였다고 가정해보자. 가격과 이름 등 모든 필드가 값이 동일할 때 이 두 데이터를 어떻게 구별할까? id라는 필드를 생성해서 auto_increment를 부가조건으로 사용하면 먼저 만들어진 순서대로 고유의 id가 부여된다.
그러면 사과1, 사과2는 모든 필드가 동일해도 id만은 다를 것이다. 이때 이 id가 구별하는 기준이 되는 것이고, primary key에 들어가는 필드가 그 구별의 기준으로 사용되는 것이다.
쉽게 엑셀 파일에 비유하자면 이렇다.
엑셀 파일의 폴더 = 데이터베이스
엑셀 파일 = 테이블
엑셀 파일의 헤더 = 필드 정의
엑셀 파일의 서식 = 타입
2) 테이블 생성
이제 테이블 생성하는 것을 직접해보자.
가장 먼저 CLI를 실행시킨다.

이렇게 패스워드를 입력하는 창이 표시되는데 처음 입력했던 패스워드를 사용해야 데이터베이스를 사용할 수 있다. 나는 여기서 1234로 입력하였다.
패스워드를 입력하면 명령어를 사용할 수 있는 화면이 나오는데 여기서 주의해야 할 점은 모든 명령어 마지막에는 세미콜론 ; 이 입력되어야 한다.
가장 먼저, 데이터베이스를 생성해보자. create database db1;
db1 이라는 이름의 데이터베이스를 생성하였다.
잘 생성되었는지 확인하려면 show databases; 를 입력하면 내가 생성한 모든 데이터베이스가 출력된다.
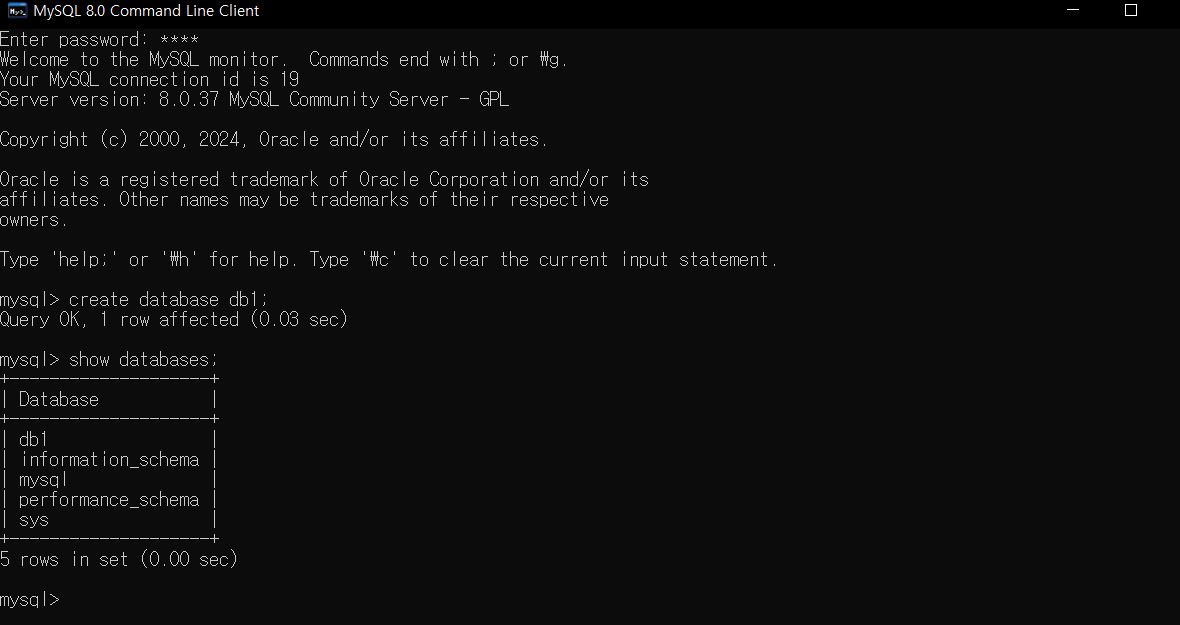
데이터베이스 즉, 폴더를 생성하였으면 파일을 생성해야 한다. 파일을 생성하려면 우선 그 폴더에 들어가야 한다.
MySQL에서는 데이터베이스에 들어갈 때 use 데이터베이스의 이름; 을 사용한다. 데이터베이스에 접속했으면 위에서 언급한 테이블의 양식에 맞춰 테이블을 생성한다.
create table product1(
id int auto_increment,
price bigint,
name varchar(20),
primary key(id)
);예시로 만든 테이블인데 무엇을 의미하는지 알아보자. 우선 id는 4바이트 정수 타입인 필드이고 부가 조건으로 auto_increment를 사용하여 데이터를 생성할 때마다 1씩 증가하며 id가 부여된다(1부터 시작한다). 즉, 필드에 값을 넣지 않더라도 자동으로 1씩 증가하여 추가되며 값을 넣어도 된다.
price는 얼마가 될지 모르니 8바이트 정수 타입으로 정의하였고 name은 글자수 20자로 제한하였다.
마지막으로 primary key에 필드로 id를 입력하여 같은 조건의 데이터에서 id값으로 구별할 수 있도록 하였다.
테이블 생성이 완료되면 잘 생성되었는지 확인하기 위해 show tables; 라는 명령어를 사용하면 다음과 같이 출력이 된다.
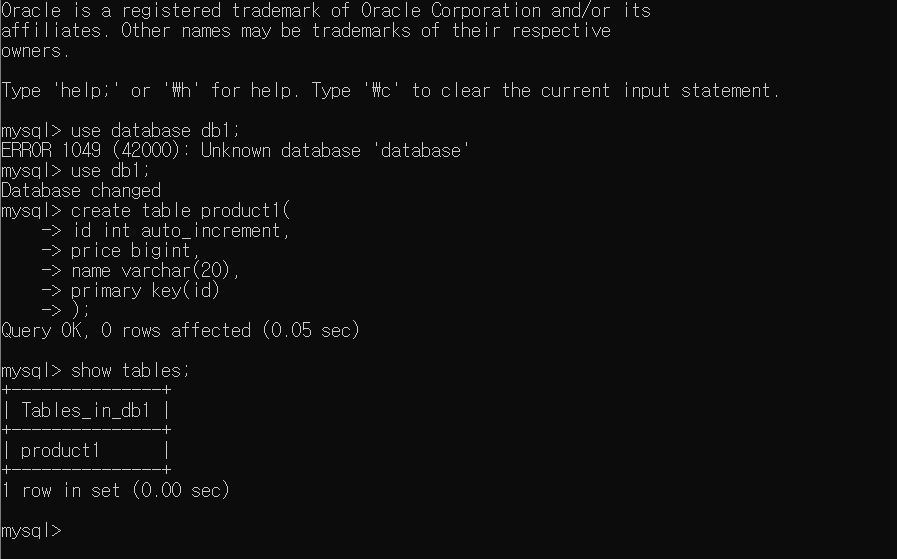
3) 명령어
앞에서 데이터베이스, 테이블 생성 시에 사용한 명령어를 포함해서 다른 명령어를 정리해보자.
<데이터베이스>
1. 데이터베이스 생성 - create database 데이터베이스명;
2. 데이터베이스 목록보기 - show databases;
3. 데이터베이스 지우기 - drop database 데이터베이스명;
4. 데이터베이스 접속 - use 데이터베이스명;
<테이블>
1. 테이블 생성 - create table 테이블명(필드명 타입 부가조건, primary key(필드명));
2. 테이블 목록보기 - show tables;
3. 테이블 지우기 - drop table 테이블명;
2. 테이블의 데이터 조작(CRUD)
테이블을 생성하였으면 데이터를 저장, 조회, 수정, 삭제할 수 있고 이를 CRUD라 한다.
1) 데이터 저장(Create)
데이터를 넣는다고도 표현하며 데이터에 값을 입력하는 행위다.
insert into 테이블명(필드1, 필드2, 필드3,...) value(값1, 값2, 값3,...);
이 형태로 데이터를 저장하고 만약 예를 들어 필드3에는 데이터를 저장하지 않고 싶을 경우 소괄호 안에 입력하지 않으면 된다. 대신 값의 개수는 필드의 개수와 맞춰야 한다.
student 라는 테이블을 생성하고 id,이름,나이,신장,출생일을 필드로 만들어 데이터를 저장해보겠다.
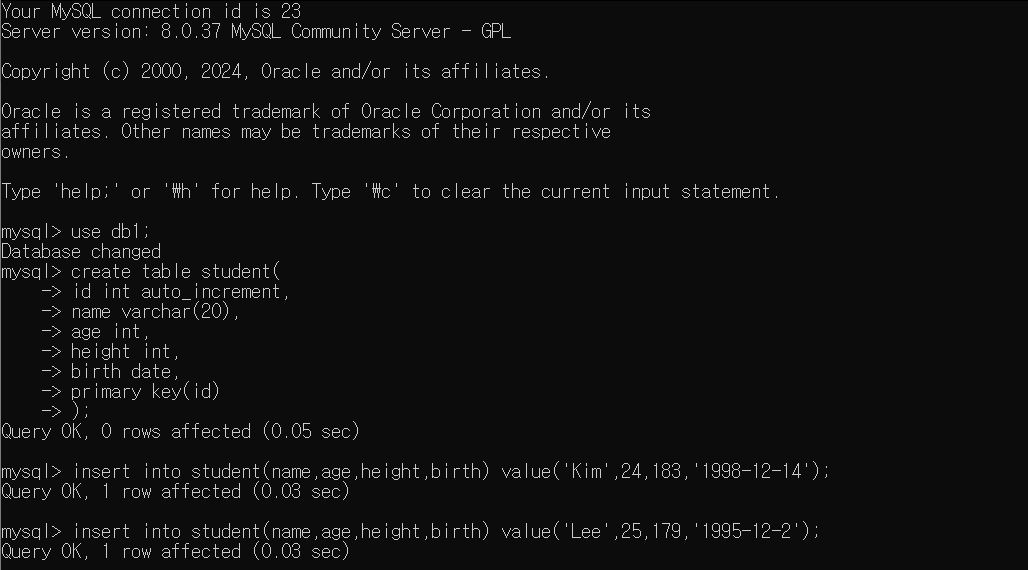
각기 다른 필드의 데이터값을 입력하여 2명의 student 데이터를 만들었다.
2) 데이터 조회(Read)
데이터를 저장했으면 저장이 잘되었는지 확인이 필요하다. 이를 데이터 조회라고 하는데 방법이 여러가지이다.
가장 간단한 전체 데이터를 조회하고 싶을 경우
select*from 테이블명;
으로 데이터 전체를 조회할 수 있다.
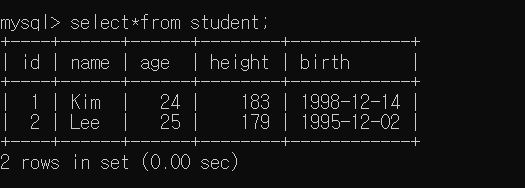
하지만, 전체 데이터가 아닌 특정 데이터만 조회하고 싶을 경우가 있다.
name 필드만 조회하고 싶을 경우 select name from student; 이런식으로 입력하면 된다.
name이 Kim인 사람의 데이터만 조회하고 싶을 경우에는 select*name from student where name = 'Kim';을 입력한다. 전체 데이터 중 조건에 해당하는 데이터만 가지고 오는 것이다.
전체 데이터 조회 : select from 테이블명;
특정 필드만 조회 : select 필드명 from 테이블명;
조건에 부합하는 데이터만 조회 : select from 테이블명 where 조건;
조건에는 =, <=, !=, <, >, >=, between, in, not in 등도 사용가능하다.
전체 데이터 중 name이 'Kim' 또는 'Lee'에 해당하는 데이터를 가져오고 싶을 경우 다음과 같이 입력하면 된다.

3) 데이터 수정(Update)
저장되어 있는 데이터를 수정 즉, 데이터 값을 변경하고 싶을 경우 사용한다.
update 테이블명 set 필드1 = 변경하려는 값, 필드2 = 변경하려는 값...where 조건;
여기서 주의할 점은 조건을 명시하지 않으면 모든 데이터 값들이 변경된다.
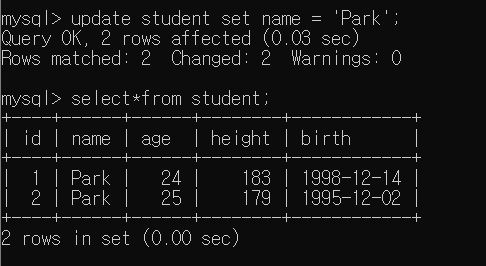
학생1, 학생2 데이터가 있는데 조건을 명시하지 않고 필드값을 변경하면 학생1, 학생2의 필드값이 동일하게 변경된다.
물론 전체 데이터값을 변경하고 싶을 때는 조건을 명시하지 않으면 되지만 특정 데이터만 변경하고 싶을 경우 조건을 반드시 입력해야 한다.
조건을 추가하지 않아 모든 데이터의 name이 변경되었으니 다시 원래대로 변경해보자.
id 값을 조건으로 하여 1번째 학생의 name만 Lee로 변경해보겠다.
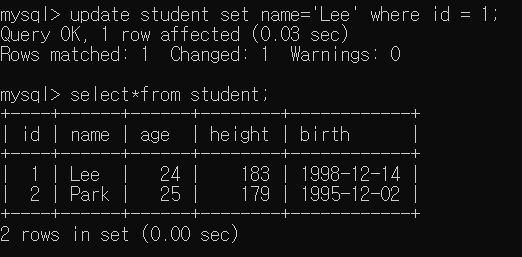
4) 데이터 삭제(Delete)
데이터 수정과 동일하게 조건 없이 delete해버리면 테이블 자체가 사라질 수 있으니 주의하자.
delete 테이블명 where 조건;
2번째 학생 데이터를 삭제하고 싶으니 조건은 name이 Park인 데이터나 아니면 구별점이 되는 id값으로 하는 것이 가장 무난하다.
정리
- 데이터 저장 : insert into 테이블명(필드1,필드2,...) value(값1,값2,...);
- 데이터 조회 : (전체) select * from 테이블명 where 조건 / (특정 필드) select 필드명 from 테이블명 where 조건
- 데이터 수정 : update 테이블명 set 필드1=값1, 필드2=값2,...where 조건
- 데이터 삭제 : delete (from) 테이블명 where 조건
*from은 생략 가능
명령어를 전부 외울 필요는 없고 필요할 때마다 구글링해서 찾아 사용하면 된다.
