
Data augmentation 개요
딥러닝 모델의 성능을 개선하기 위해선 학습 데이터 추가, 모델 변경, 전처리 방안 변경 등 여러 방법이 존재하며 각각의 장단점이 존재합니다.
성능 개선 방법들 중 학습 데이터를 추가하는 방식이 가장 확실하게 성능을 개선할 수 있는 방법이지만 좋은 품질을 갖는 데이터를 구축하기 위해선 많은 노력이 필요합니다.
더불어 추가적인 학습 데이터를 수집하는 것이 제한된 의료와 같은 도메인들에선 이러한 문제가 더욱 심하게 와닿게되고, 일반화된 학습 모델 구축의 난이도가 높음을 의미합니다.
이러한 문제점을 해결할 순 없지만 최대한 개선하는 방법이 바로 데이터 증강 방법 입니다.
이번 포스트에선 이러한 데이터 증강에 대한 개념, 종류, 활용 방법과 함께 몇몇 유명한 논문들까지 소개하며 다뤄보도록 하겠습니다.
Data augmentation 종류 및 설명
Data augmentation은 데이터를 조정하는 방법에 따라 개념이 나뉘어집니다.
- Pixel-level augmentation
- 입력된 데이터에 대해 픽셀 값 자체를 변경하는 작업
- Spatial-level augmentation
- 입력된 데이터에 대해 공간을 변형, 왜곡하는 작업
먼저 이미지의 픽셀을 조정하는 Pixel-level augmentation을 다뤄보겠습니다.
Pixel-level augmentation에서의 대표적인 증강 기법
1. Blur

- Augmentation 기법 중 Blur(블러링) 기법이란 입력 이미지에 대해 흐려보이는, 초점이 맞지 않는 듯한 형태로 이미지를 변환하는 기법
- 각 픽셀간의 경계가 뚜렷한 원본 이미지에 대해, 특정 값(산술평균, 분포 기반 등)으로 만들어진 필터를 더해주는 등의 연산을 수행
- 입력된 이미지의 경계를 흐리게 만들어 부드럽게 만들어주거나, 입력에 포함된 작은 노이즈를 제거하는 용도로 활용할 수 있음
2. Histogram Equalization

- Histogram Equalization란 픽셀의 분포가 한곳에 집중되어, 이미지를 정상적으로 식별하기 어려운 경우에 적용할 수 있는 처리 기법
- 한곳에 집중되어있는 픽셀의 분포를 0~255 사이 전체적으로 고루 퍼질 수 있도록 조정해주는 기법이라 할 수 있음
3. ColorJitter

- ColorJitter augmentation이란 입력 이미지에 대해 이미지가 갖는 brightness, contrast, saturation 및 hue를 무작위로 변환하는 기법을 의미함
- 이 때, brightness는 밝기, contrast는 대비, saturation은 채도, hue는 색상을 나타내고 있음
4. CLAHE (Contrast Limited Adaptive Histogram Equalization)

- 앞서 등장한 개념인 Historgram Equalization의 개선된 처리 기법이며, Equalizaiton과 동일하게 분포를 조정하여 이미지를 조금 더 잘 식별할 수 있도록 하는 기법
- 전체 픽셀 분포에 대해 조정하던 Histogram Equalization에 비해 CLAHE 기법은 전체 데이터를 패치 단위로 분할하고, 패치(타일) 단위의 Equalization을 수행하는 알고리즘을 가짐
- Equalization을 수행한 뒤, 각 타일 경계가 어색해지는 것을 방지하기 위해 bilinear interpolation 기법을 통해 smooth하게 보완
- 또한 노이즈가 포함되어 이미지가 의도하지 않게 망가지는 것을 방지하기 위해 Contrast Limit 기법을 적용하여, Histogram의 높이를 제한. 이를 초과한다면 clipping을 통해 조정
5. Noise

- Adding noise augmentation이란 용어로 주로 사용되는 noise augmentation이란 입력 이미지에 대해 무작위 난수(noise)를 픽셀에 더해주는 기법을 의미함
- noise augmentation을 수행하는 방법엔 Gaussian, Salt and Pepper, Speckle 방법이 존재함, 주로 Gaussian noise 방법이 활용됨
6. GaussianBlur

- 앞서 등장한 개념인 Blur 기법에선 필터 내 모든 픽셀의 값에 동일하게 영향을 받는 평균 필터를 사용함
- 이는 가까이 있는 픽셀과 멀리 있는 픽셀의 가중이 동일하여, 결과물의 퀄리티가 낮아질 수 있음
- 이러한 단점을 개선하여 등장한 것이 Gaussian Blur 처리이며, 가깝게 위치한 픽셀의 가중치를 높게 설정하여 전반적인 이미지의 품질을 높이는 것을 의미
- 결과적으로 핵심 픽셀을 기준으로 거리를 계산하여, 이미지 변환에 미치는 영향을 조절한 상태로 Blur를 수행한 기법이라 할 수 있음
7. Histogram Matching

- Histogram Matching이란 이미지의 색상 등의 특징을 다른 이미지의 특징에 맞추어 변환하는 방법을 의미함
- 특히 컴퓨터비전(딥러닝)에선 학습 이미지의 특징과 검증 및 테스트 이미지의 특징이 다른 경우가 존재하며, 이미지 간 도메인이 다른 경우라고도 함
- 이러한 경우 학습 데이터를 검증 및 테스트 데이터의 특징에 맞추어 변환해주는 작업이 필요하며, 해당 알고리즘은 앞선 개념인 Histogram Equalization을 기반으로 함
- 가장 먼저 변환하고자 하는 이미지(소스 이미지)를 Histogram Equalization을 통해 변환, 이후 변환하고 싶은 이미지인 타겟 이미지를 Histogram Equalization을 통해 변환
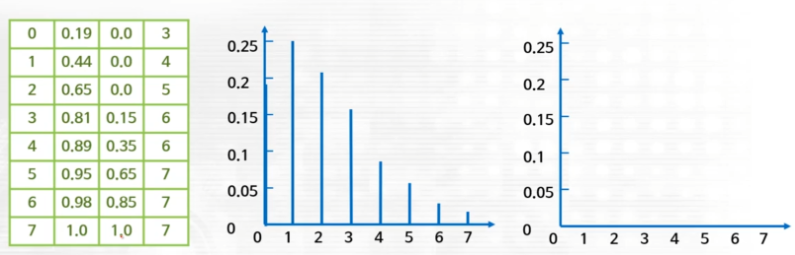
- Equalization 과정을 통해 계산된 소스 이미지의 CDF(누적밀도함수 : cumulative Distribution Function) 값을 타겟 이미지의 CDF 값과 비교
- 소스 이미지의 CDF와 가장 가까운 값의 타겟 이미지 CDF 값을 탐색한 뒤, 이를 픽셀에 대응시키는 과정을 수행하며, 이를 역평활화라 함
- 결과적으로 소스 이미지의 0 픽셀은 0.19 값을 가지며, 이는 타겟 이미지의 CDF에서 가장 가까운 값인 0.15의 픽셀 3으로 매핑되는 과정을 수행
- 이를 모든 픽셀 범주에 대해 적용해주어, 소스 이미지를 변환할 수 있으며, 적용된 결과를 본다면 소스 이미지의 분포는 타겟 이미지의 분포와 거의 유사하게 변화됨을 확인할 수 있음
8. HueSaturationValue

- RGB 색상 채널과는 다른 HSV(H : 색상, S : 채도, V : 명도) 색상 채널을 활용하여, 입력 이미지를 랜덤한 HSV 이미지로 변환하는 증강을 의미함
- HSV 표기법 이외에도 HSI(Intensity), HSB(Brightness), HSL(Lightness) 로도 표기되고 있음
9. ImageCompression

- ImageCompression 증강은 이름에서도 알 수 있다시피, 입력 데이터의 품질을 일정 범위를 기준으로 감소시키는 증강을 의미함
- 입력된 이미지에서 더욱 좋은 품질로는 불가하며, 정도에 따라 품질을 낮추는 작업만이 가능
10. Median blur

- 앞선 Bluring과 유사하게, 타겟 픽셀의 근처에 존재하는 픽셀값들을 갖는 필터를 기반으로 동작하지만 이 때, 평균 등의 값이 아닌 중앙값을 활용
- 블러링과 유사한 결과물을 도출해내며, 점토로 빚거나 AI가 생성한듯한 결과물을 도출하게 됨
11. Motion blur

Albumentations 공식 문서의 설명에 따르면, 무작위 크기를 갖는 커널(필터)를 통해 연산되며, 입력 이미지가 blur와 유사하게 흐리게 나타난다고 설명
일반적으로 특정 크기의 0 행렬을 선언한 뒤, 행렬의 중앙 부분의 값을 모두 1로 변경해준 뒤, 만들어진 필터로 입력 이미지에 대해 convolution 연산을 수행하면 motion blur 이미지를 얻을 수 있음
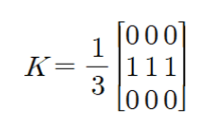
12. RGBShift

- 일반적인 이미지의 구성 요소인 R, G, B 채널 정보에 대해, 각 채널의 픽셀을 일정 범위 내에서 무작위로 조절(Shift)하는 과정을 의미 ex) R -19, G + 11, B + 4 …
13. RandomGamma, Brightness, Contrast
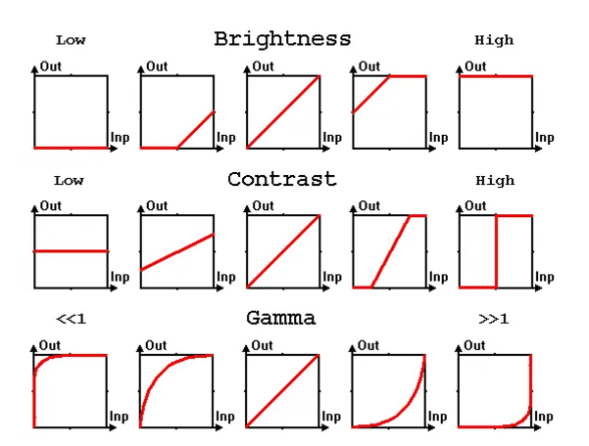
- Brightness는 입력 이미지의 픽셀에 대해 밝은 영역, 어두운 영역에 대해 구분 없이 모두 선형적으로 값을 더해주거나 빼는 과정을 의미
- RandomBrightness는 입력 이미지의 픽셀을 일정 범위의 값을 기반으로 모두 더해주거나 빼주는 과정을 의미
- Contrast는 모든 픽셀을 선형적으로 증감하는 방법 대신 밝은 영역의 값을 어두운 영역에 비해 조금 더 큰 값으로 증가시키는 과정을 의미 ex) 10, 10 → 30, 20 → 50, 30 → 100, 55 …
- RandomContrast는 입력 이미지의 픽셀에 대해 일정 범위의 값을 기반으로 증감하지만, 픽셀의 값을 기반으로 밝은 영역은 조금 더 큰 가중치를, 어두운 영역은 조금 작은 가중치를 부여하게 됨
- Gamma는 픽셀의 값을 나타내는 과정에서 변화될 영역의 방향을 결정하는 수치로, 그래프의 모양에 따라 한쪽 영역의 변화폭을 줄이거나 늘리는 방식으로 픽셀을 조절하게 됨
- 또한 앞선 Brightness 방법과는 다르게, 선형적인 증가가 아닌 픽셀 개별의 값 마다의 변화 비율을 직접적으로 조정한다는 비선형적 보정의 의미로도 이해할 수 있음
- RandomGamma는 이미지의 픽셀 값의 변화 비율을 조정하는 gamma 값을 무작위로 변경해가며, 이를 통해 비선형적으로 이미지의 밝기를 조절하는 방법이라고 할 수 있음
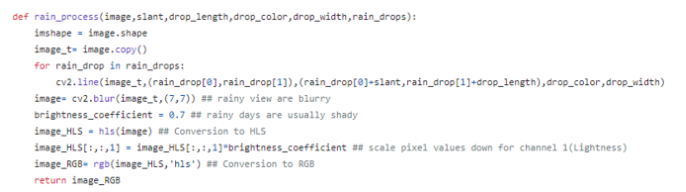
14. RandomRain, Snow, Fog

눈, 비 혹은 안개 등의 상황이 포함된 데이터를 수집하여 활용하기엔 많은 비용과 시간이 필요하기 때문에, 이러한 기상현상이 포함된 이미지 혹은 영상을 포함하기 위한 증강 기법임
구현된 깃허브를 기반으로 albumentations에서 제공되고 있으며, 각각의 기법들에 대해 실제 어떻게 구현되었는지, 간단하게 코드를 확인해봄
snow augmentation의 경우 HLS 색공간에서 Lightness를 기반으로 특정 계수만큼 이를 증폭시킨 것을 RGB 이미지로 만들어 준것으로 보여짐
rain augmentation의 경우 opencv를 기반으로 입력 이미지에 랜덤하게 선을 그어준 작업으로 보여지며, HSL 공간의 Lightness 조절을 통해 비의 색과 유사하게 만들어준 것으로 보여짐
또한 실제 비가 내리는 경우와 유사하게 이미지의 번짐을 추가해준것으로 보여짐

fog augmentation의 경우 opencv의 circle을 기반으로 랜덤한 좌표에 circle 모양의 blur를 추가해준 작업으로 보여짐
또한 실제 색을 입혀주는 과정에선 RGB 채널 중 Red 채널의 값만을 활용했다고 설명 (코드 상 너무 길어 표헌되어있지 않음)
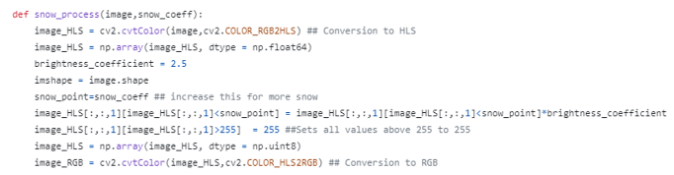
다음으론 이미지의 공간을 변형하는 Spatial-level augmentation을 다뤄보겠습니다.
Spatial-level augmentation에서의 대표적인 증강 기법
1. Affine ( Translation-move, Rotation, Scaling-zooming, Shear )

- 앞선 데이터 증강에선 이미지의 픽셀을 기준으로 증강을 수행했다면, Spatial augmentation에선 이미지의 공간 정보를 직접적으로 조정하는 증강을 의미함
- Affine augmentation은 일반적으로 Geometric transforms이라 알려져있으며, 이미지가 갖는 공간 전체를 움직이거나, 꼭짓점 좌표를 기반으로 비트는 증강을 의미함
- 이러한 Affine augmentation 안에는 Translation, Rotation, Scaling, Shear 종류가 존재하며, 이러한 증강들을 Affine 혹은 Geometric transform이라 함
2. Crop and Padding

- 입력 이미지에 대해 정해진 좌표 혹은 랜덤한 좌표를 기반으로 이미지를 잘라내는 증강을 Crop augmentation이라고 함
- Crop augmentation을 수행해준 이미지는 배치 처리를 위해 기존 이미지들과 같은 크기를 가져야하기 때문에, 후처리를 반드시 수행해주어야 함
- Crop augmentation 이후 잘려진 이미지의 사이즈를 키워 그대로 활용하면 Crop & Resize이라 정의하고, 잘려진 부분을 0 값인 Pad로 채운다면 Crop & Padding이라 함
3. ElasticTransform

- Elastic Transform 혹은 Deformation으로 알려져있으며, 입력 이미지에 대해 가우시안 필터를 활용하여, 이미지에 블러 변환을 적용한 상태로 볼 수 있음
- Elastic Transform 이후의 이미지를 확인해보았을 때, 마치 물에 비쳐진 이미지와 유사한 형태로 이미지가 표현됨을 확인할 수 있음
4. VerticalFlip, HorizontalFlip
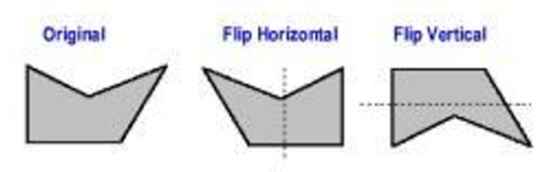
- 입력 이미지의 중심을 기준으로 이미지를 뒤집는 증강을 의미하며, 수직 혹은 수평의 방향에 따라 Horizontal 혹은 Vertical Flip으로 정의됨
5. Grid Dropout
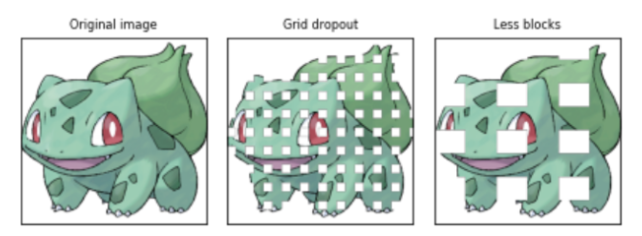
- 신경망의 학습 방법 중 과적합을 방지하기 위해 사용되는 Dropout 방법을 떠올리면 쉽게 이해할 수 있음
- 일정한 간격과 크기를 갖는 여러 Grid를 기준으로 입력 이미지의 픽셀 자체를 Drop하는 방법을 의미하며, Drop된 픽셀의 값은 255로 대체되는 것을 확인할 수 있음 (어두운 이미지라면 0으로 대체)
- 그리드와 픽셀 제거를 통해 이미지를 인식하기 위한 중요한 정보가 사라질 수도 있기 때문에, 하나의 핵심 포인트가 아닌 여러 정보를 최대한 활용하도록 학습하게 됨
6. Mask Dropout

- 앞선 Grid Dropout 방식과 유사한 형태의 이미지 증강 기법이며, Grid Drop 방법이 일정한 크기와 간격을 갖는 Grid 형태의 Dropout을 수행하는 내용과 유사하며 다름
- 무작위 크기와 좌표를 갖는 Mask box를 기반으로 이미지 내에서 무작위로 픽셀을 탈락시키는 것을 확인할 수 있음 (본 예제에선 탈락된 픽셀의 자리를 0으로 대체)
7. ShiftScaleRotate

- Spatial augmentation에 존재하는 Rotate, Shift, Scale augmentation에 대해 여러 인자를 모두 설정한 뒤, 무작위로 augmentation을 수행하는 방법을 의미함
- 기존 분리되어있던 각각의 데이터 증강 방법을 하나의 함수로 간편하게 적용할 수 있기 때문에, 특수한 이미지가 아닌 경우엔 해당 증강을 적용하는 것을 추천함
Offline vs Online augmentation
앞선 파트에서 데이터 증강의 정의와 종류에 대해서 간단하게 확인해보았으며, 이번 파트에선 이를 실제 적용하는 방법에 대해 다룸
구축된 딥러닝 모델을 성공적으로 학습시키기 위해 활용되는 데이터 증강은 데이터와 증강의 적용 방법에 따라 Online augmentation과 Offline augmentation으로 나뉘어짐
먼저 Online augmentation 방법에 대해 다뤄보자면, 이는 일반적인 모델 학습 과정에서 사용되는 데이터 증강을 의미함
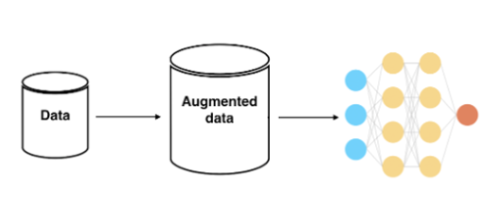
위 이미지와 같이 딥러닝 모델을 학습하는 end-to-end 과정에서, 사람의 개입 없이 사전에 정의된 무작위 증강 함수를 통해 자동적으로 데이터를 증강(변환)하는 방식을 의미함
실제 데이터의 수량이 늘어나는 방식이 아니기 때문에 저장공간 측면에서의 이점이 존재하지만, 연산 이전에 변환 작업이 있기에 속도가 더디며 증강된 결과물을 눈으로 확인하기 어려움
만약 해결하고자 하는 문제가 특수한 도메인이라고 한다면, Online 데이터 증강 과정에서 중요한 정보가 탈락할 수 있기 때문에 주의하여야 함
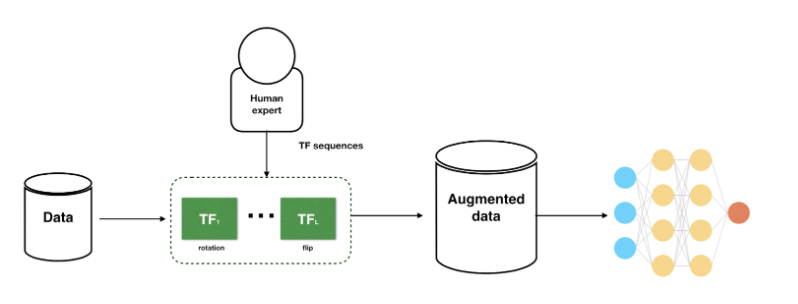
앞선 Online 데이터 증강과는 반대 개념으로 Offline 데이터 증강 개념이 존재하며, 이는 데이터 증강 과정을 사람이 직접 수행하는 것을 의미함
불균형한 데이터에서 일부 클래스에 추가적인 데이터 증강을 적용하거나, 특수한 도메인에서 증강 결과물이 매우 중요한 경우 이러한 방법을 선택할 수 있음
또한 학습에 필요한 증강 이미지를 모두 저장공간에 저장해놓은 상태로 활용하기 때문에 학습 과정에서 별도의 처리 과정은 없지만, 데이터 셋의 크기 자체가 커질 우려가 있음
경험적으로 미루어보았을 때, 데이터 셋의 크기가 작고 증강 결과물이 중요한 몇몇 도메인에선 Offline 데이터 증강이 매우 좋은 성적을 도출한다 할 수 있음
결과적으로 현재 주어진 상황, 데이터의 크기, 시간, 자원 등을 모두 고려하여, 적합한 데이터 증강 방법을 선택하는 것이 매우 중요하다 할 수 있음
Albumentations 소개 및 예제 코드 (in tensorflow, pytorch)
# in tensorflow
import numpy as np
import matplotlib.pyplot as plt
from functools import partial
# augmentations - pixel level
from albumentations import (
Compose, JpegCompression, HueSaturationValue, RandomContrast, RandomGamma, RandomBrightness,
Blur, HistogramMatching, Equalize, ColorJitter, CLAHE, GaussianBlur, GaussNoise, MedianBlur, MotionBlur, RGBShift,
RandomFog, RandomSnow, RandomRain)
# augmentations - spatial level
from albumentations import (
Affine, Crop, CropAndPad, ElasticTransform, VerticalFlip, HorizontalFlip, GridDropout, MaskDropout, GridDistortion,
ShiftScaleRotate)
# load in the tf_flowers dataset
data, info = tfds.load(name="tf_flowers", split="train", as_supervised=True, with_info=True)
# Instantiate augments
# we can apply as many augments we want and adjust the values accordingly
# here I have chosen the augments and their arguments at random
pixel_level_transforms = Compose([
RandomBrightness(limit=0.1),
JpegCompression(quality_lower=85, quality_upper=100, p=0.5),
HueSaturationValue(hue_shift_limit=20, sat_shift_limit=30, val_shift_limit=20, p=0.5),
RandomContrast(limit=0.2, p=0.5),
RandomGamma(gamma_limit=(80, 120)),
Blur(blur_limit=(3, 7)),
Equalize(),
ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2, hue=0.2),
CLAHE(clip_limit=4.0, tile_grid_size=(8, 8)),
GaussianBlur(blur_limit=(3, 7), sigma_limit=(0, 0)),
GaussNoise(var_limit=(10.0, 50.0), mean=0),
MedianBlur(blur_limit=(7, 7)),
MotionBlur(blur_limit=(7, 7)),
RGBShift(r_shift_limit=20, g_shift_limit=20, b_shift_limit=20,),
RandomFog(fog_coef_lower=0.3, fog_coef_upper=1, alpha_coef=0.08),
RandomSnow(snow_point_lower=0.1, snow_point_upper=0.3, brightness_coeff=2.5),
RandomRain(slant_lower=-10, slant_upper=10, drop_length=20, drop_width=1,
drop_color=(200, 200, 200), blur_value=7, brightness_coefficient=0.7)
])
spatial_level_transforms = Compose([
Affine(scale=0.5, translate_percent=0.5, rotate=[-180, 180], shear=[-180, 180]),
CropAndPad(px=(0, 112)),
ElasticTransform(alpha=1, sigma=50, alpha_affine=50),
VerticalFlip(),
HorizontalFlip(),
GridDropout(ratio=0.5, fill_value=0),
GridDistortion(num_steps=5, distort_limit=(-0.03, 0.03)),
ShiftScaleRotate(shift_limit=0.0625, scale_limit=0.1, rotate_limit=45,)
])
# visualizataion
for image, label in data.take(5):
fig = plt.figure(figsize=(22, 14))
for i in range(5):
ax = fig.add_subplot(1, 5, i+1, xticks=[], yticks=[])
if i in original:
ax.imshow(image)
ax.set_title(f"Label: {label}")
else:
augmented = pixel_level_transforms(image=np.array(image)) # spatial_level_transforms
ax.imshow(augmented["image"])
ax.set_title(f"Label: {label}")위의 예제는 tensorflow datasets 내 존재하는 flower dataset를 활용하여, dataloader를 구축하고 데이터 증강을 정의해준 코드입니다.
위의 예제에선 pixel-level, spatial-level에 따라 데이터 증강을 나누어 정의했으며, 실제 데이터 증강 단계에선 적절한 데이터 증강을 선택한 상태로 섞어 사용하게 됩니다.
def aug_fn(image, img_size):
data = {"image":image}
aug_data = pixel_level_transforms(**data)
aug_img = aug_data["image"]
aug_img = tf.cast(aug_img / 255.0, tf.float32)
aug_img = tf.image.resize(aug_img, size=[img_size, img_size])
return aug_img
def process_data(image, label, img_size):
aug_img = tf.numpy_function(func=aug_fn, inp=[image, img_size], Tout=tf.float32)
return aug_img, label
# create dataset
AUTOTUNE = tf.data.experimental.AUTOTUNE
ds_alb = data.map(partial(process_data, img_size=120), num_parallel_calls=AUTOTUNE).prefetch(AUTOTUNE)
def set_shapes(img, label, img_shape=(120,120,3)):
img.set_shape(img_shape)
label.set_shape([])
return img, label
ds_alb = ds_alb.map(set_shapes, num_parallel_calls=AUTOTUNE).batch(32).prefetch(AUTOTUNE)위의 코드는 증강 함수 자체를 직접 활용한 방법과는 다르게, dataloader를 활용하여, 데이터 증강과 함께 데이터를 로드하는 방법을 보여줍니다.
tensorflow에서 사용되는 dataloader는 내부에서 tensorflow로 구현된 함수 이외엔 사용할 수 없기 때문에(numpy 포함 모든 함수), tf.numpy_function()를 활용하여 데이터 셋을 구축해주어야 합니다.
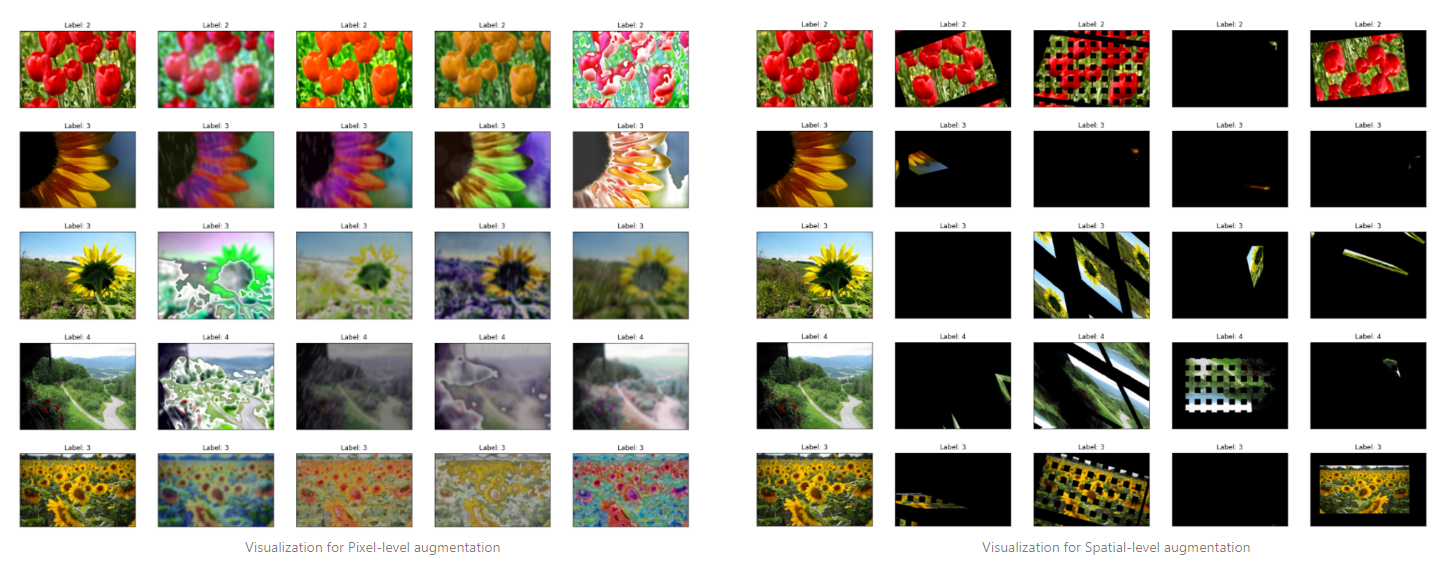
아래는 pixel-level, spatial-level 데이터 증강을 각각 적용해준 결과물이며, 각 행의 왼쪽 이미지는 원본, 오른쪽 4장의 이미지는 무작위 증강이 적용된 이미지입니다.
마지막으로 사용법이 다른 증강(전처리) 방법 중 하나인 Histogram Matching 변환의 사용법에 대해 간단하게 소개합니다.
from PIL import Image
src_img = np.array(Image.open('source.png'))
target_image = np.array(Image.open('reference.png'))
target_hm = HistogramMatching(reference_images=['reference.png'], always_apply=True)
output = target_hm(image=src_img)
# Visualization
fig = plt.figure(figsize=(20, 12))
ax = fig.add_subplot(1, 3, 1, xticks=[], yticks=[])
ax.imshow(src_img)
ax = fig.add_subplot(1, 3, 2, xticks=[], yticks=[])
ax.imshow(target_image)
ax = fig.add_subplot(1, 3, 3, xticks=[], yticks=[])
ax.imshow(output['image']);변환하고싶은 이미지(source)와 변환할때 쓸 재료 이미지(target)을 기반으로 이미지 처리를 수행하게되며, 일반적인 데이터 증강 방법과는 사용법이 약간 다름.
Histogram Matching을 정의할 때, 사용할 reference(target)들을 리스트 형태로 정의해주어야하며(데이터 경로 정의), 정의된 함수를 통해 실제 이미지를 입력하는 식으로 정의됩니다.

정의된 함수를 통해 실제 시각화를 수행했을 때, 위 이미지와 같은 결과물을 얻어낼 수 있으며, 순서대로 source image, reference image, transform output 순서입니다.
다음으론 pytorch 기반의 코드 작성 방법에 대해 다룹니다.
# in pytorch
flower_directory = "datasets/Flowers102/flowers-102/jpg/"
flower_images_filepaths = sorted([os.path.join(flower_directory, f) for f in os.listdir(flower_directory)])
images_filepaths = [*flower_images_filepaths]
correct_images_filepaths = [i for i in images_filepaths[:32] if cv2.imread(i) is not None]
# Define Datasets
class FlowerDatasets(Dataset):
def __init__(self, images_filepaths):
self.images_filepaths = images_filepaths
def __len__(self):
return len(self.images_filepaths)
def __getitem__(self, idx):
image_filepath = self.images_filepaths[idx]
image = cv2.imread(image_filepath)
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
resized_image = cv2.resize(image, dsize=(224, 224))
return resized_image
# Define Dataloader
train_dataset = FlowerDatasets(images_filepaths=correct_images_filepaths)
# Visualization
original = [0, 5, 10, 15]
cnt = 0
for image in train_dataset:
if cnt == 4:
break
fig = plt.figure(figsize=(22, 14))
for i in range(5):
ax = fig.add_subplot(1, 5, i+1, xticks=[], yticks=[])
if i in original:
ax.imshow(image)
else:
augmentation_img = transforms(image=image)["image"]
ax.imshow(augmentation_img)
cnt += 1
tensorflow dataloader와 유사한 형태로 데이터 증강 함수의 정의와 활용이 가능하며, pytorch에서 제공되는 datasets 내부에선 여러 함수를 자유롭게 사용할 수 있어 TF 대비 조금 더 자유롭습니다.
이렇게 albumentations는 두가지 라이브러리에서 모두 사용할 수 있도록 지원되고 있으며, 데이터 증강을 정의하는 transforms 부분은 고정한 상태로, dataloader만 맞추어주면 사용할 수 있습니다.
마지막 파트에선 여러 논문에서 제시되는 데이터 증강 기법들에 대해 간단히 소개하며 마치도록 하겠습니다.
Data augmentation 동향 (CutOut, Mixup, CutMix, AugMix, Adversarial)
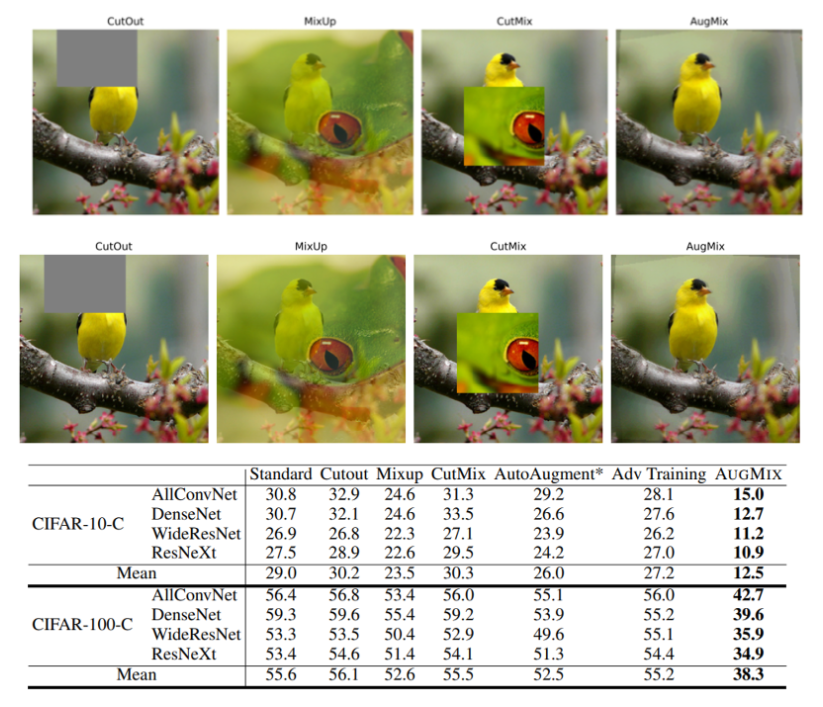
위 이미지와 표는 CutOut(2017)부터 Augmix(2020)까지 각각의 데이터 증강 방법을 적용했을 때의 예시와 성능(CIFAR datasets image classification)을 나타내고 있습니다.
물론 Image Classification task에 한정되어있기 때문에, 다양한 작업에서의 성능 개선 여부는 확인해보아야 하겠지만 Classification 과제에서 이러한 증강 기법들이 충분히 메리트있음을 시사합니다.
각각의 증강에 대해 간단하게 어떠한 방법을 사용하고, 이러한 방법을 사용했을 때의 성능은 어떠한지 확인해보겠습니다.
1. CutOut
- 이미지 내에서 특정 위치를 지정하거나, 임의의 위치에 정사각형 형태의 마스크를 덧씌워 원본 픽셀을 Drop 하는 방법
- 마스킹에서 사용되는 마스크는 0 혹은 0을 평균으로 갖는 무작위 값이 주로 사용됨
- CutOut augmentation을 적용하지 않은 베이스라인에 비해 큰 성능 개선이 없거나, 오히려 성능이 하락하는 경우도 존재하기 때문에 사용에 주의가 필요
2. Mixup
- 앞선 이미지와 같이 카멜레온 이미지와 새 이미지가 있는 경우, 두 이미지의 픽셀과 라벨을 섞어 활용하는 방법
- 파라미터 gamma를 기반으로 어느 정도의 비율로 이미지와 라벨을 혼합할지 결정하며, 모델이 데이터에 대해 크게 확신하는 상태를 줄이는 방법이라고도 할 수 있음
- Mixup augmentation을 적용하지 않는 베이스라인에 비해 큰 성능 개선이 존재하며, 베이스라인으로 제안된 모든 딥러닝 네트워크에서 좋은 성적을 도출함을 확인
3. CutMix
- 네이버 Clova에서 발표된 논문으로 앞선 CutOut, Mixup augmentation 방법의 정보 손실 문제를 제기했으며, 정보 손실 없이 효과적으로 인식 성능을 개선할 수 있다고 설명
- CutOut 방법에서 마스크를 기반으로 이미지의 정보를 Drop 시키는 방법에서 Drop된 자리에 다른 이미지의 정보를 넣어주는 방법을 활용해주었으며, 크기에 맞추어 라벨 값 또한 수정
- AugMix에서 제시한 CIFAR dataset을 기반으로 한 평가에선 CutOut과 유사하게 성능 개선이 거의 없었지만 ImageNet, Pascal VOC dataset에서 효과적인 성능 개선을 도출.
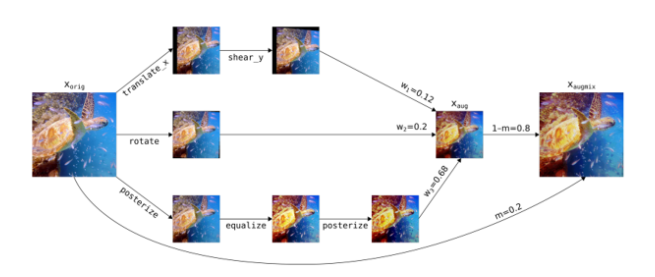
4. AugMix
- 입력 이미지를 기반으로 다양한 데이터 증강을 적용해주어 다양한 형태, 질감, 위치를 갖는 이미지를 모두 한번에 섞어 활용하는 방식을 의미
- 이러한 증강 방식의 장점은 기존 데이터 증강에서 불가능했던 Adversarial 공격에 대해 강건한 성능을 갖도록 하는것이며, 초기 입력 이미지가 다양한 변환 조합을 갖는 이미지로 변화하게 됨
- CIFAR dataset 이외에도 ImageNet을 기반으로 한 데이터 검증에서도 좋은 성적을 도출해냈지만, 하이퍼 파라미터와 계산 복잡성이 증가되기 때문에 사용함에 있어 충분한 검토가 필요
5. Augmentation based Adv(Adversarial)
- 적대적 공격(Adversarial Attack)이란 딥러닝 네트워크를 속이기 위한 방법을 의미하며, 팬더 이미지에 노이즈를 추가한 경우 긴팔원숭이로 인식되는 것이 적대적 공격의 예시임
- 적대적 공격이 포함된 상태에서 학습, 증강하는 방법을 Adversarial Training 혹은 Augmentation이라고 하며, 이를 통해 네트워크의 강건성(Robustness)을 증가시키는 것이 목적임
- 앞서 소개한 다양한 데이터 증강 연구는 물론 최근 적대적 공격을 기반으로 네트워크의 강건성을 높이고자 많은 연구가 진행되고 있음
- 이러한 적대적 공격에 대해 보완하기위해 학습된 네트워크는 clean accuracy가 상대적으로 낮아지고 robust accuracy가 높아지는 trade-off 관계에 놓여있음
이렇게 알고리즘을 기반으로 한 데이터 증강 기법에서부터 최근 사례까지 확인해보았습니다.
과거 학습 모델의 과적합을 개선하고 일반화 성능을 개선시킨다는 취지에서 시작한 것이
최근엔 학습 모델의 이미지에 대한 강건성을 개선시키는 방향으로 변해가는 것 같습니다.
마치며
높은 일반화 성능을 갖는 학습 모델을 구축하기 위한 데이터 증강 기법은 좋은 기법입니다.
하지만 내가 가진 데이터가 어떠한 특성과 도메인을 갖는지에 따라 이러한 데이터 증강이
오히려 마이너스 요소가 될 수 있기 때문에 데이터 증강과 분석은 항상 주의해야 합니다.
이번 리뷰를 통해 새로운 것들을 배워볼 수 있었으며, 뜻깊은 시간이었습니다.
이후에도 지속 가능한 배움을 위해 노력하겠으며, 제 포스트를 읽는 분들이 조금 더 많은 정보를 잘 가져가셨으면 좋겠습니다.
감사합니다.
