이번에 읽고 리뷰해볼 논문은 ILSVRC에서 2등의 성적을 거둔 VGG(2014) 논문에 대해
정리해보도록 하겠습니다.
정리된 내용 중 부정확하거나 설명과 다른 부분에 대해선 언제든 피드백 부탁드립니다.
Introduction
VGG는 2012년에 우승한 AlexNet에 비해 더 깊은 구조를 설계하고, 이를 안정적으로 학습하여
더욱 높은 성능을 도출해냈습니다.
일반적으로 Deep Neural Network는 깊이가 깊어질수록 빠르게 과적합되기 때문에,
ILSVRC에서 우승했던 AlexNet 또한 과적합을 방지하기 위해서, 8개의 layer를 사용했습니다.
하지만 VGG 논문의 저자는 AlexNet에 비해 2배 이상 깊은 구조를 사용했음에도, 과적합은
커녕 오히려 더욱 좋은 성능을 도출해냈습니다.
VGG가 더욱 좋은 성능을 도출할 수 있었던 이유는 무엇인지, 어떤 방법을 사용했는지
확인해보도록 하겠습니다.
Sect.1. Abstract & Introduction

본 논문의 핵심 내용을 Abstact에서 확인할 수 있었습니다.
저자가 말하고자 하는 핵심 내용은 large-scale image recognition task에서 convolution network의 depth를 증가시켰을 때의 성능 개선 효과입니다.
이러한 성능 개선을 입증하기 위해 저자는 VGG의 depth를 증가시킴과 동시에 아주 작은 3x3
크기의 filter를 사용했다고 설명합니다.
이 때, 왜 3X3 크기의 filter를 사용한건지에 대해선 아래에서 언급하도록 하겠습니다.
이후 저자는 레이어 계층을 16층에서 19층 깊이까지 증가시켰으며, 이를 통해 상당한 성능 개선을 확인할 수 있었다고 설명합니다.

본 논문의 Introduction 부분에서도 Abstact와 유사한 내용을 설명하고 있으며, 앞선 2012, 2013, 2014에서 좋은 성적을 거두었던 network의 간단한 요약과 함께 해당 network의 저자들이 사용한 방법에 대해 간단하게 설명하고 있습니다.
해당 부분 또한, network depth의 증가 및 very small convolution filter에 대해 소개하고 있습니다.

마지막으로, 각 Sect 별 소개하는 내용에 대해 담고있으며, Sect.2 에서는 VGG 구조에 대한 소개, Sect.3 에서는 VGG의 훈련 및 검증에 대한 소개, Sect.4 에서는 VGG 구조 별 비교, Sect.5 에서는 최종 결론에 대한 내용을 담는다고 설명하고 있습니다.
Sect.2. ConvNet Configurations

해당 파트에선 VGG Architecture에 대해 설명하고 있으며, 간단하게 다뤄보도록 하겠습니다.
- 입력 이미지의 width, height는 224로 고정됨.
- 입력 이미지에 대한 전처리로 각 픽셀에 대해 RGB 값의 평균(training set의 평균)을 뺌.
- 각 convolution layer의 모든 filter는 3x3 크기의 아주 작은 필터를 사용함.
- 여러 구조를 실험하며, 한 가지 구조에서 filter size가 1x1인 layer를 추가한 구조 또한 테스트함.
- 모든 convolution layer의 stride는 1로 고정함.
- 입력 이미지의 크기를 줄이는 작업은 Max-pooling으로 수행하며, 5개의 pooling layer가 존재함.
또한 각 pooling layer는 2x2 window size 및 2의 stride를 가짐.

위 설명에 이어 아래 내용 또한 VGG 구조에 대한 내용을 담고 있습니다.
- Convolution layer를 쌓은 뒤, 3개의 Fully Connected layer(Dense layer)가 따라오는데, 이는 모든 구조에서 동일하며, 각 4096, 4096, 1000의 unit을 가짐.
- 모든 hidden layer는 ReLU activation function을 사용함.
- 많은 구조 중 하나에서 Local Response Normalization을 테스트 해봤으며, 이는 성능 개선에 도움되지 않았고, 메모리 소비량 및 계산 시간을 증가시킴.

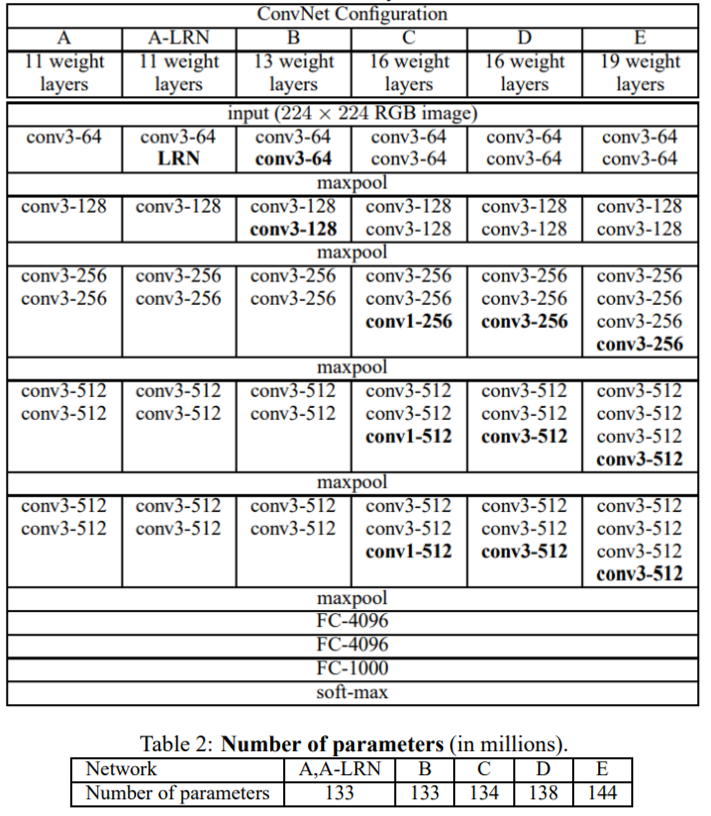
다음 내용을 살펴보면, 2개의 Table 설명과 함께, 네트워크의 구성에 대해 설명하고 있습니다.
- network 구조 별 이름은 A - E로 설정.
- network는 이전에 설명한 내용을 기반으로 구성됨.
- Depth 하나만 다르며, A 구조는 11개의 layer를 가지며, E 구조는 19개의 layer를 가짐.
- convolution layer의 채널은 64부터 시작하여 pooling layer를 거칠 때마다, 2배 씩 커짐.
또한 이렇게 깊게 쌓는다고 해도, A-E 구조의 파라미터의 수는 크게 차이나지 않는다고 설명합니다.

다음 내용으론 기존 2012, 2013년 ILSVRC에서 우수한 성적을 거둔 구조와 VGG를 비교합니다.
저자의 VGG는 앞서 개발된 SOTA 모델들과 상당히 다르며, 가장 처음의 convolution layer를 놓고 비교해보면 상당히 다른 것을 알 수 있었습니다.
기존 network들은 filter size 11x11, stride 4를 갖는 conv를 사용하거나 filter size 7x7, stride 2를 갖는 conv를 사용하는 방식을 채택했지만, VGG에서는 3x3 filter만을 사용하여 network를 구성했습니다.
큰 filter size의 conv가 아닌 작은 filter size의 conv만을 활용하여 네트워크를 구축할 수 있었던 이유를 추가적으로 설명하는데, 5x5 filter convolution은 3x3 filter 2개와 동일한 receptive field를 가지며, 7x7 filter convolution은 3x3 filter 3개와 동일한 receptive field를 갖는다고 합니다.
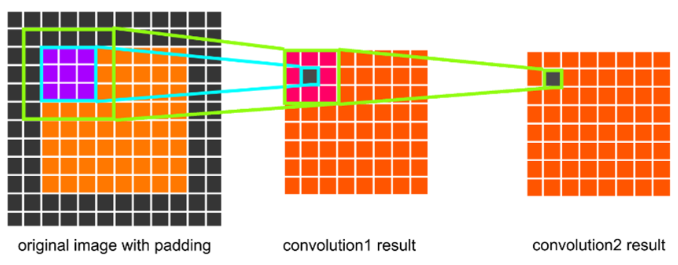
| https://linkinpark213.com/2018/04/21/vgg/
동일한 receptive field를 가질 수 있는 이유는 위 이미지에서 간단하게 확인할 수 있습니다.
또한 이러한 filter 분해 과정을 통해 얻을 수 있는 것으로는 2번의 추가적인 비선형성, 큰 filter size 대비 더 적은 수의 파라미터, 큰 filter size를 규제한 것과 같은 효과를 낸다고 설명합니다.

VGG에서 사용된 아주 작은 크기의 conv filter는 VGG 이전에도 사용되었는데, 해당 연구에서의 network depth는 깊지 않았으며, 연구 결과 또한 큰 소득은 없다고 합니다.
또한 저자는 ILSVRC 대회에서 1등을 기록한 GoogleNet에 대해서도 간단하게 설명합니다.
- 거리 번호 인식 과제에서 deep한 구조의 network를 활용함.
- GoogleNet의 결과로 인해 network의 depth가 증가할 수록 성능이 좋아지는 것을 검증해냄.
- VGG와는 개별 연구였지만, 두 network 모두 depth의 증가 및 작은 filter를 사용한 것에서는 동일.
- GoogleNet은 VGG보다 더욱 복잡하며, 첫 계층에서 해상도를 더욱 공격적으로 감소시킴을 설명.
이렇게 VGG, GoogleNet 구조에 대한 Sect.2 part는 마무리 되었으며, 다음 Sect에선 training, testing, detail에 대해 다루도록 하겠습니다.
Sect.3. Training, Testing, Implementation detail

해당 파트에선 VGG를 훈련하기 위해 지정한 하이퍼 파라미터, 규제, 콜백 등을 설명하고 있습니다.
VGG를 훈련하기 위해 사용한 여러 훈련 전략 및 하이퍼 파라미터 등은 아래와 같습니다.
- Mini-batch gradient descent를 통해 miltinomial logistic regression optimization을 수행함.
- 이 과정에서 optimizer는 SGD를 사용한 것으로 보이며, 0.9의 momentum을 추가함.
- Mini batch size는 256으로 지정했으며, 초기 learning rate는 0.01로 지정함.
- 훈련의 과적합을 방지하기 위해 전체 레이어에 0.0005의 L2 regularization을 적용했으며,
앞 2번의 fully-connected layer에선 사이사이 0.5의 dropout layer를 추가함. - 초기 learning rate에서 validation loss가 10회 이상 개선되지 않으면 lr을 감소시킴.
추가적으로 2012년에 공개된 AlexNet과 간단하게 비교를 진행했으며, AlexNet에 비해 깊은 depth 및 많은 파라미터를 갖지만 network의 수렴에는 더 적은 수의 epochs만이 필요했다고 설명합니다.
더욱 빠르게 수렴할 수 있었던 이유로는 2가지를 설명합니다.
- 더욱 깊은 깊이 및 작은 크기의 필터로 인한 규제 효과 (과적합 방지와 비선형성으로 인한 성능 개선이 동시에 이루어지는 듯함)
- 특정 계층의 사전 초기화
이 2가지 설명 중 2번째 특정 계층의 사전 초기화에 대해서 저자는 추가적으로 설명합니다.

Network의 가중치 초기화는 매우 중요하며, 이것이 제대로 이루어지지 않았을 때, 불안정한 gradient로 인해 학습이 지연될 수 있다고 설명합니다.
이러한 실패를 예방하기 위해 저자는 VGG 구성 중 A의 가중치를 랜덤하게 초기화한 뒤, 이를 1차적으로 훈련하여, 이러한 가중치를 이후 레이어의 초기 가중치로 사용하는 방식을 택했습니다.
A를 초기화할 때, 사용했던 랜덤 가중치는 평균 0, 분산 0.01을 갖는 정규 분포에서 샘플링했다고 설명합니다.
하지만 VGG 논문을 제출한 뒤, 해당 방식과 같은 사전 훈련 없이 적절한 초기 가중치를 제어할 수 있는 방법에 대해 확인했다고 하며, 이 방식이 현재의 Xavier initialization 입니다.

마지막으로 입력 이미지는 224 x 224로 고정하여 활용하고, training set에서 crop & rescale 이미지에 대해 random hirizontal flipping, random RGB color shift augmentation을 적용했다고 설명합니다.

저자는 S를 언급했는데, 이 S는 훈련에 사용한 데이터의 원본 스케일을 의미하며, VGG의 훈련 방식은 S라는 224 이상의 원본 스케일 이미지에서 랜덤하게 고정된 224 크기의 이미지로 잘라내는 것을 의미합니다.

또한 저자는 이러한 S와 함께 2가지 접근법을 제시했습니다.
- S가 고정된 단일 스케일 이미지 훈련 방식
- S가 고정되지 않고 랜덤으로 정해진 다중 스케일 이미지 훈련 방식
단일 스케일 훈련 방식에서 S 의 값을 256으로 설정하여 1차적으로 훈련한 뒤, 훈련된 가중치를 통해 S = 384 스케일을 훈련했다고 설명합니다. 이 때, 0.01의 lr 대신 0.001의 lr을 사용했다고 설명합니다.

또한 다중 스케일 훈련 방식에서는 S의 값을 256 ~ 512 사이로 설정한 뒤, 이를 랜덤하게 샘플링하여 사용했다고 하며, 이러한 방식이 augmentation에서 scale jittering과 같다고 설명했습니다.
추가적으로 속도 상의 이유로 인해 단일 스케일 S = 384 훈련과 동일하게, S = 384로 훈련된 가중치를 사용하여 다중 스케일 모델을 훈련했다고 설명합니다.

위에서 훈련된 모델에 대한 테스트를 수행할 때는 Q라는 테스트 전용 스케일이 존재하며, Q는 S와 같을 필요가 없다고 설명합니다.
또한 S에 대해 몇개의 Q를 사용하는 것이 성능 향상에 도움된다고 설명되며, 이러한 내용에 대해서는 Sect.4 에서 추가적으로 설명합니다.
추가적으로 VGG에 존재하는 3개의 FC(Fully-connected layer)는 3개의 Convolution layer로 변경되며, 각 7x7, 1x1, 1x1 크기의 filter를 갖는다고 설명합니다.
위 내용에 대해 조금 더 설명을 덧붙혀 보자면 아래와 같습니다. (해당 내용이 틀릴 수 있습니다.)
가장 첫번째 fully connected layer의 가중치를 확인했을 때, flatten layer 때문에 가중치의 shape은 (25088, 4096) 형태입니다.
이러한 가중치 형태를 reshape를 통해 flatten 이전으로 변환한다면, (7, 7, 512, 4096) 형태입니다.
만약 어떤 2d convolution layer가 4096의 채널, 7x7의 filter를 갖는다고 가정하면, 해당 convolution layer는 flatten 이전의 데이터 (7, 7, 512) 입력에 대해 (7, 7, 512, 4096)의 가중치를 갖게됩니다.
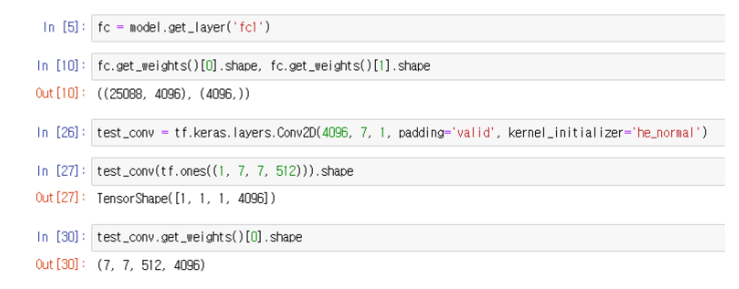
이렇게 초기화된 아무 의미 없는 가중치를 갖는 convolution layer의 가중치를 fc layer의 가중치 (25088, 4096)을 (7, 7, 512, 4096)으로 reshape한 뒤, 이를 convolution layer의 가중치로 활용하는 방법이라고 할 수 있습니다.
(7, 7, 512) 레이어 이후 2번의 1x1 convolution이 이어진다고 추가로 설명하는데, 이 내용 또한 아래 예시에서 확인할 수 있습니다.
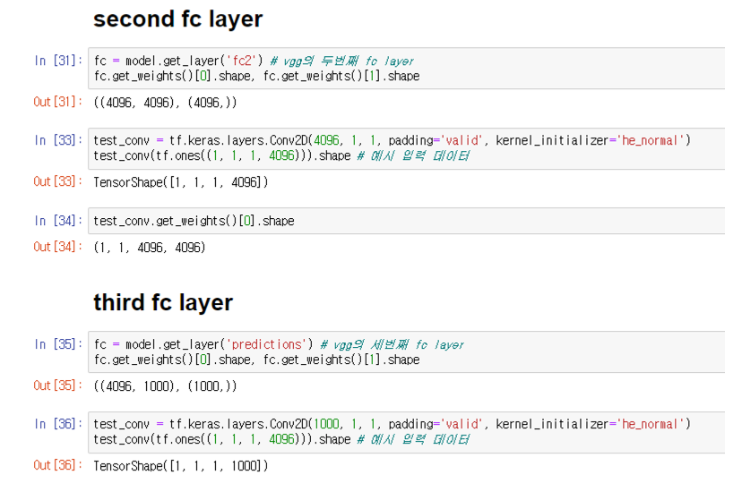
결국 이러한 내용은 새로운 convolution layer를 훈련하는 것이 아닌, fully connected layer가 갖는 가중치를 convolution layer에 적용할 수 있도록 reshape를 수행한 뒤, 이를 적용해주는 것 입니다.
이렇게 된다면, 어떠한 입력 이미지가 들어오더라도, 최종 (N, N, 1000) 형태로는 도출이 가능하며, 이후 N, N에 대해 평균을 내주면, 여러 크기의 입력 이미지에 대해 ensemble이 가능하게 됩니다.
위 내용이 저자가 활용한 FC → Conv 방법이며, 이를 통해 fc layer를 통한 여러 크기를 갖는 이미지에 대해 연산이 가능하게 됩니다.
추가적으로 저자는 test set에 대해 augmentation을 수행한 뒤, 이를 ensemble 하지만, 성능이 개선됨과 동시에 계산 효율성이 떨어지는 방법이라고 언급합니다.

VGG는 단일 GPU가 아닌 4개의 다중 GPU로 훈련되었으며, 훈련 이미지를 분할하여 각 GPU에서 Gradient를 계산하며 훈련되었다고 설명합니다.
4개의 다중 GPU에서 얻어진 Gradients는 평균으로 계산하며, 이러한 결과가 단일 GPU의 결과와 정확하게 일치했다고 설명합니다.
병렬로 처리되는 다중 GPU 시스템은 단일 GPU 시스템보다 3.75배 속도가 빠르다고 설명합니다.
Sect.4. Classification Experiments

VGG는 ILSVRC-2012 dataset을 활용했으며, 이는 1000개 이미지에 대한 정보를 담고 있습니다.
각 훈련/검증/테스트 셋으로 나뉘며, 훈련된 모델의 평가는 Top-1 error 및 Top-5 error를 사용합니다.
이 때, Top-1 error는 훈련된 모델이 새로운 테스트 이미지들에 대해 예측을 수행했을 때, 가장 높은 확률을 도출한 class(index)가 실제 정답과 동일하다면 error는 0%가 되는 방식입니다.
이렇게 테스트에 대해서 모델이 확신하는 확률과 실제 정답을 비교하며, 에러율를 도출합니다.
추가적으로 저자가 언급하는 test set은 validation set을 바꾸어 말한 것이라고 설명합니다.
→ 실제 test set은 ILSVRC 서버 내에서 자체적으로 평가되는 것 같습니다.

단일 스케일로 훈련된 네트워크와, 멀티 스케일로 훈련된 네트워크를 단일 스케일 테스트 데이터를 통해 top-1, top-5 error를 측정합니다.
테스트 데이터의 스케일은 훈련 데이터 스케일의 (min, max) * 0.5로 계산되며, 단일로 훈련된 모델이라면 S와 Q는 동일하고, 다중 스케일로 훈련된 모델이라면 다중 스케일의 평균으로 측정됩니다.
이러한 이해를 바탕으로 아래 Table.3 를 확인하도록 하겠습니다.
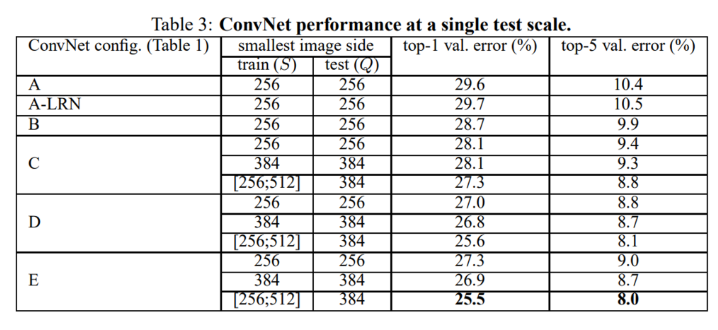
Table 3의 결과를 통해 알 수 있는 점이 몇 가지 있습니다.
- Local Response normalization 여부에 따른 성능
→ A와 A-LRN을 비교했을 때, 성능 개선이 없었기에 저자는 해당 방법을 사용하지 않습니다. - 일반적으로 보여지는 성능을 봤을 때, Depth가 깊어질수록 error가 감소합니다.
- 3개의 1x1 convolution을 추가한 C를 확인 했을 때, B보다 성능이 좋으며, 이는 비 선형성 증가로 인한 성능 향상을 검증합니다.
- C의 구조에서 3개의 1x1 convolution을 3x3 convolution으로 대체했을 때, 성능이 더욱 개선되는 것을 확인할 수 있었습니다.
→ 이는 비선형성 뿐만 아니라, 정보 자체를 잡아내는 filter 또한 매우 중요한 걸 알 수 있습니다. - 가장 깊은 구조를 갖는 E는 과적합의 위험이 있지만, 큰 규모의 데이터 셋에서는 더욱 효과적으로 작동함을 알 수 있습니다.
- B 구조에서 5x5 convolution 1개를 사용한 결과와, 3x3 convolution으로 분해해서 쓴 결과를 비교했을 때, 약 7% 가량 성능 차이가 도출되었고, 3x3이 더욱 좋은 성능을 도출한다고 설명합니다.
- 마지막으로 Scale jittering을 수행한 성능이 가장 좋았으며, 이는 training set에 대한 augmentation 효과를 입증합니다.
다음으로 테스트 셋에 대해 다중 스케일을 적용한 결과 또한 확인해보겠습니다.

여러 버전의 스케일을 테스트 이미지에 적용했으며, 이러한 test scale augmentation을 거친 뒤, 도출되는 여러 출력에 대해서는 클래스 별 평균 값을 사용했다고 설명합니다.
추가적으로 모델에서 사용한 augmentation의 scale Q는 훈련 스케일 S의 값에서 [-32, S, +32]로 계산한 값을 사용했다고 설명합니다.
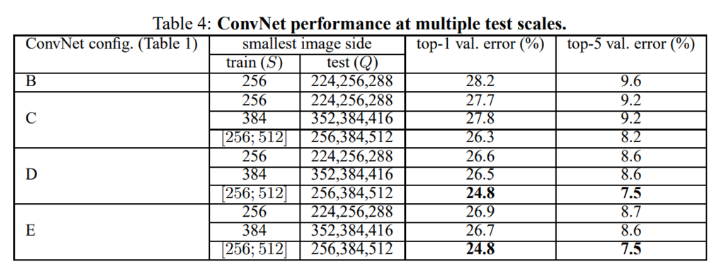
Table. 4의 결과를 확인해봤을 때, 모델을 훈련할 때, scale jittering을 적용한 방법이 가장 성능이 좋았으며, 그 이외에도 4개의 구조 중 깊은 구조를 갖는 D, E 구조가 가장 성능이 좋았다고 설명합니다.
훈련에서 고정된 scale을 활용하는 것보다, 다중 스케일을 통해 훈련하는 것이 좋은 성능을 도출한다는 것을 입증했습니다.
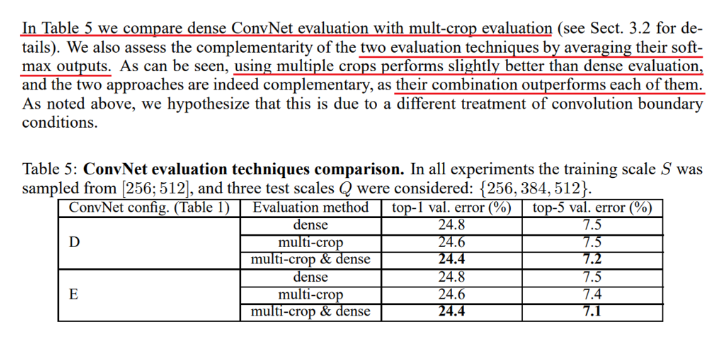
또한 Multi crop & Dense evaluation 두 방법을 결합한 방법을 통해서도 평가를 진행했습니다.
- Multi crop
- 하나의 테스트 이미지에 여러 crop을 진행하여 test 시 augmentation을 적용하는 방법
- Dense evaluation
- 여러 크기의 입력 이미지를 같이 처리하기 위해, 입력이 정해진 fully connected를 convolution layer로 변환하는 방법
이러한 2가지 방법을 조합해서 사용했을 때, 가장 성능이 좋았다고 설명합니다.

검증 데이터를 통해 여러 기법, 구조 등에 대해 테스트를 진행한 뒤, 좋은 성능을 도출한 여러 모델을 ensemble을 통해 묶어낸 뒤, 최종 성능 평가를 수행했다고 설명합니다.
공식적으로 기록된 것은 single scale로 훈련된 네트워크들이며, 이러한 네트워크들의 ensemble 결과는 top-5 test error에서 7.3을 기록했습니다.
추가적으로 대회 이후에, multi crop + dense evaluation을 사용해서 최고 성능을 도출한 네트워크의 ensemble을 진행했을땐, top-5 test error를 6.8까지 줄일 수 있었다고 설명했습니다.
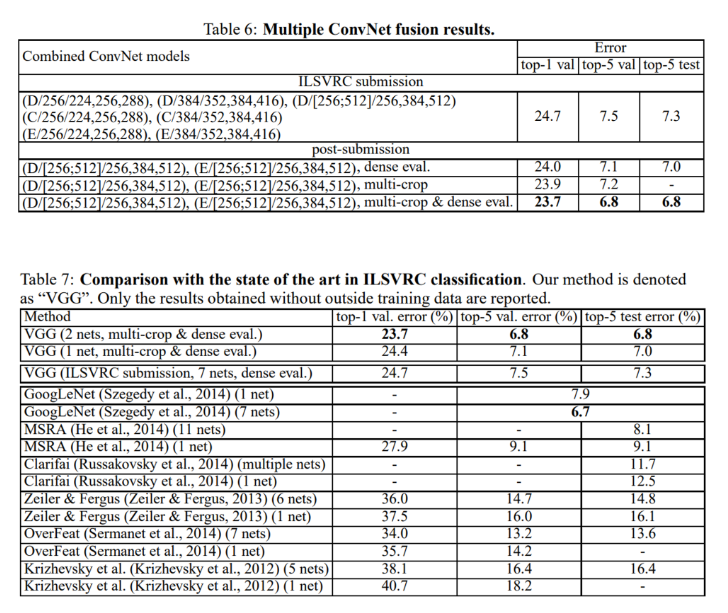
결과적으로 VGG는 ILSVRC Classification 대회에서 GoogleNet 다음인 2등의 성적을 낼 수 있었습니다.
Sect.5. Conclusion

VGG는 네트워크의 Depth, filter가 Classification에서 얼마나 중요한지 검증, 입증했습니다.
또한 이러한 네트워크의 성능을 개선할 수 있는 여러 특징은 단순 Classification task 뿐만 아니라,
다양한 task 및 데이터 셋에서 인용하고, 활용할 수 있을 것으로 생각됩니다.
다시 한번 네트워크의 깊이에 대해 강조하며, 본 논문은 마무리 됩니다.
이렇게 VGG에 대해 나름? 깊게 정리해보고 다뤄보았습니다.
업로드 자체는 2023년에 되었지만, 본문의 내용 자체는 과거에 작성되어 부족한 점이 많습니다.
향후 다양한 논문을 읽고 분석해가며, 조금 더 성장할 수 있도록 노력하겠습니다.
긴 글 읽어주셔서 감사합니다.
