소개
분산 시스템에서 ID는 데이터의 중복이나 키 생성 등 다양한 용도로 사용할 수 있기 떄문에 고유한 ID를 생성하는 것은 중요합니다.
이번 글에서는 고유 ID 생성의 장단점을 포함해 트위터의 Snowflake 알고리즘을 구현해보겠습니다. 또한 이 글의 내용 대부분은 <대규모 시스템 설계 기초, 알렉스 쉬>를 참고했습니다.
추가로, 이 글은 이전에 작성한 글을 재작성했습니다.
고유 ID의 특성
고유 ID의 특성을 장점과 단점 두 가지 측면에서 비교해보겠습니다.
장점
- 중복 방지: 분산 환경에서 여러 서버가 동시에 작업하는 경우 서로 다른 서버에서 생성된 ID가 겹칠 수 있습니다. 하지만 ID 생성기를 사용하면 이러한 중복을 방지할 수 있습니다.
- 독립성 보장: ID 생성기를 사용하면 분산 환경에서 서버가 타임스탬프 또는 기타 방법을 사용하여 독립적으로 ID를 생성할 수 있습니다.
- 분산 DB 키 생성: ID 생성기를 사용하여 분산 환경에서 데이터베이스의 키를 생성할 수 있습니다. 이렇게 하면 각 서버에서 데이터를 생성하고 동기화할 필요가 없어져 데이터베이스 성능이 향상됩니다.
- 고성능: ID 생성기는 속도에 최적화된 알고리즘을 사용하여 분산 환경에서 ID를 빠르게 생성할 수 있습니다.
- 추적성: ID 생성기는 앞서 언급한 값을 사용하여 ID를 생성합니다. 이를 통해 ID의 생성 시간, 생성자 등의 정보를 추적할 수 있습니다.
따라서 분산 시스템에서 ID 생성기를 사용하면 중복 방지, 독립성 보장, DB 키 생성 분산, 고성능, 추적성 등의 이점을 얻을 수 있습니다.
단점
반면 장점이 있다면 단점도 있습니다.
-
의존성 문제: 아이디 생성기를 활용하게 되면, 시스템의 아이디 생성 과정이 이 생성기에 종속적이게 됩니다. 따라서 만약 생성기에 문제가 생긴다면, 시스템 일부가 제대로 작동하지 않을 위험이 있습니다.
-
시스템 복잡성 증가: ID 생성기는 보통 다른 시스템들과 함께 운영되는데, 이로 인해 전체 시스템의 복잡도가 높아질 수 있습니다. 이는 유지보수와 문제 해결을 더 어렵게 만들 수 있습니다.
-
대역폭 및 지연 시간 문제: ID 생성기가 분산 환경에서 동작하기 때문에, 각 서버가 생성기에 접속하는 과정에서 대역폭과 지연 시간이 생깁니다. 이런 현상은 전반적인 성능 저하를 초래할 수 있습니다.
-
예측할 수 없는 ID 값: 아이디 생성기가 임의의 값을 사용하여 아이디를 생성하는 경우 예측할 수 없는 아이디 값이 생성될 수 있으며, 이로 인해 아이디 값을 추적하거나 유지하기가 어려운 경우가 발생할 수 있습니다.
-
보안: ID 생성기는 데이터의 식별자를 생성하는 데 사용되므로 보안 문제가 발생할 수 있습니다. ID 값이 예측 가능한 경우 보안 위험이 발생할 수 있습니다. 예를 들어 공격자가 시스템에 악의적으로 액세스하여 데이터를 변경하거나 삭제할 수 있습니다.
ID 생성기를 사용하면 몇 가지 단점도 있지만 대부분 충분히 처리할 수 있습니다. 따라서 ID 생성 시스템을 도입 여부를 결정할 때는 시스템의 대규모 운영, 보안, 성능 등 다양한 요소를 고려하는 것이 중요합니다.
구현
고유 ID 생성기를 만드는 방법은 다양합니다. UUID, 티켓 서버 그리고 트위터의 Snowflake 알고리즘이 있는데요, 여기서는 Snowflake를 직접 구현해보겠습니다.
Snowflake

Snowflake 알고리즘은 트위터에서 게시글(트윗)이나 다른 데이터 객체의 고유 ID를 생성하는데 사용합니다. 이 알고리즘은 타임스탬프, machine identifier, 시퀀스 번호로 구성되있습니다. 이때 시퀀스 번호는 고유하고 정렬가능한(sortable) 64비트 정수입니다.
비록 최근에 트위터의 시스템이 이상해져서 이 글을 쓰는게 맞나 싶긴한데, 그래도 ID 생성 시스템에 맛이 간건 아니라서 그대로 진행해도 될 것 같네요.
명세
Snowflake는 타임스탬프, machine identifier, 시퀀스 번호로 구성되있습니다. 각 요소의 특성은 다음과 같습니다.
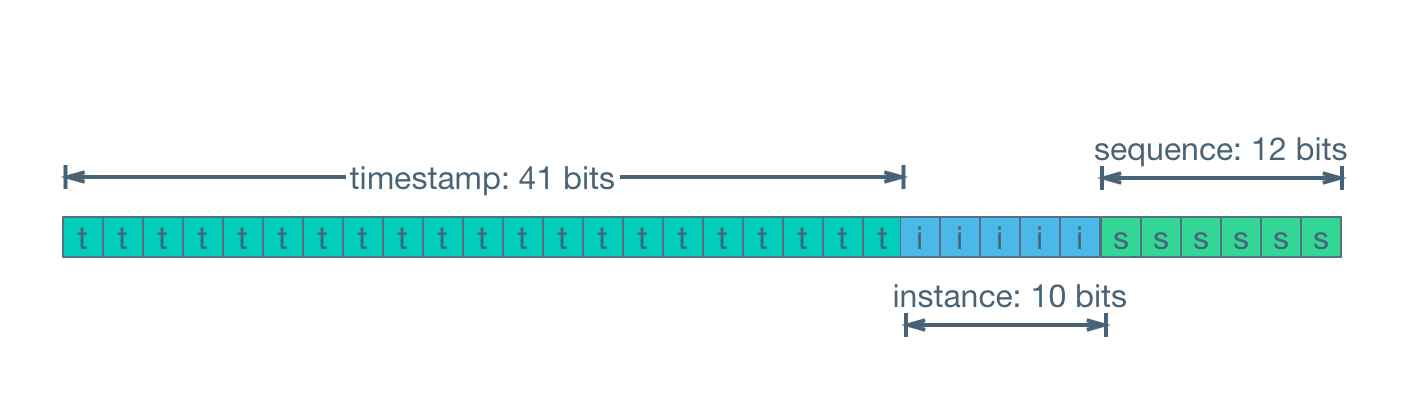
-
타임스탬프: ID의 유일성을 보장합니다. 타임스탬프는 밀리초 단위로 측정되며 현재 UNIX 시간을 기준으로 합니다. 다만, 저번 나이스(NEIS) 유출 사태에서 원인이 타임스탬프만 그대로 사용한 것이 원인이라는 의견들이 있어, 단순히 이것만 가져다 쓰는건 무리가 있습니다. 그렇기 때문에 다른 정보들도 포함해야 안정성을 높일 수 있습니다.
-
Worker ID(인스턴스): 이 ID는 서버 ID와 machine ID로 구성되어 있습니다(각각 5비트). ID를 생성하도록 할당된 각 작업자(worker)에게는 고유한 ID가 할당됩니다. 작업자 ID는 서로 다른 작업자가 생성한 ID가 겹치지 않도록 보장합니다.
-
시퀀스 번호: 동일한 작업자가 동일한 밀리초 내에 생성한 ID를 구분하는 데 사용됩니다. 이 시퀀스는 새 ID가 생성될 때마다 증가합니다.
<대규모 시스템 설계 기초> 책에서는 알고리즘을 구현할 때 제약 사항을 아래와 같이 설정했기 때문에 이번 구현에서는 이 사항들을 따를 것입니다.
- 64비트 정수로 ID를 생성
- 밀리초당 최대 4096개의 고유 ID를 생성
- ID가 고유하고 시간별로 정렬 가능한지 확인
그럼 이제 코드로 구현해보겠습니다.
Snowflake 구현
스노우플레이크의 사양을 참조하여 러스트로 실시간으로 ID를 생성하는 자체 알고리즘을 만들어 보겠습니다. 전체 코드는 링크에서 확인할 수 있습니다.
먼저, 기본 뼈대를 잡아야합니다.
const MAX_IDS_PER_MILLISECOND: usize = 4096;
#[derive(Debug, Clone, Copy)]
pub struct IdGenerator {
epoch: SystemTime,
timestamp: i64,
machine_id: i32,
server_id: i32,
index: usize,
}epoch는 UNIX 시간을 가져오고, 이후에 타임스탬프로 처리됩니다. machine)id와 server_id 필드는 worker ID의 역할을 합니다. 마지막으로 index는 시퀀스 번호입니다.
이제 생성기의 코드입니다. 다만, 여기서 get_epoch()나 get_timestamp()의 설명은 생략하겠습니다.
impl IdGenerator {
pub fn new(machine_id: i32, server_id: i32) -> Self {
let epoch = get_epoch();
Self::with_epochs(machine_id, server_id, epoch)
}
fn with_epochs(
machine_id: i32,
server_id: i32,
epoch: SystemTime
) -> Self {
let timestamp = get_timestamp(epoch);
Self {
epoch,
timestamp,
machine_id,
server_id,
index: 0,
}
}
/// 단일 ID를 실시간으로 생성
pub fn generate_id(&mut self) -> i64 {
// 1밀리초 마다 4096개의 ID를 생성해야 하기 때문에
// 시간을 4096으로 나눠야 합니다.
self.index = (self.index + 1) % MAX_IDS_PER_MILLISECOND
let mut now = get_timestamp(self.epoch);
// 시간이 마지만 시간과 다르면 인덱스를 재설정합니다.
// 아니면, 그냥 인덱스를 증가하면 됩니다.
match now.cmp(&self.timestamp) {
Ordering::Equal => {
if self.index == 0 {
now = bind_time(now, self.epoch);
self.timestamp = now;
}
}
_ => {
self.timestamp = now;
self.index = 0;
}
}
// `self.timestamp`는 64비트이고, 22비트를 왼쪽으로 이동하여 42비트로 만듭니다.
// `self.machine_id`는 17비트를 왼쪽 시프트하여 12비트로 만듭니다.
// `self.server_id`는 12비트를 왼쪽 시프트하여 12비트로 만듭니다.
// `self.index`는 보완(complement) 비트입니다.
self.timestamp << 22
| (self.machine_id as i64) << 17
| (self.server_id as i64) << 12
| self.index as i64
}
}이 코드를 검증하기 위해 테스트를 작성했습니다.
#[cfg(test)]
mod tests {
use super::*;
use std::time::Instant;
const MAX_CAPACITY: usize = 10_000;
#[test]
fn test_id_generator() {
let mut id_gen = IdGenerator::new(1, 2);
let mut ids: Vec<i64> = Vec::with_capacity(MAX_CAPACITY);
for _ in 0..99 {
for _ in 0..MAX_CAPACITY {
ids.push(id_gen.generate_id_by_time());
}
ids.sort();
ids.dedup();
assert_eq!(ids.len(), MAX_CAPACITY);
println!("{}", ids[9999]);
ids.clear();
}
}
}결과는 실행할 때마다 다르지만 아래와 같은 형태를 띕니다.
// ...
7034777258942410107
7034777258954990731
7034777258963381147
test tests::test_id_generator ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.24s마무리
이것으로 고유 ID 생성의 특징과 장단점, Snowflake 알고리즘의 구조와 코드 구현에 대해 알아보았습니다.
참고 자료
- <가상 면접 사례로 배우는 대규모 시스템 설계 기초>, 알렉스 쉬, 옮긴이: 이병준, 인사이트
