Paper Review: Automatic background animation generation aligned with LLM-generated lyrics for children’s songs
paper review
Scientific Reports 2026.
Sanghyuck Lee, Timur Khairulov, Ye-Chan Park et al.,
AutoML Lab, Chung-Ang University
December 2025
💡 Key Point
가사 이해 → 이미지 생성 → 효과 합성으로 분해된 파이프라인을 통해, 동요 기반 영상에서 의미 정렬과 제어성을 동시에 확보한 방법을 제안한다.
1. Motivation
우리가 자주 접하는 애니메이션, OTT, 숏폼 영상 같은 미디어 콘텐츠 제작은 여전히 많은 시간과 인력을 요구하는 노동 집약적이고, 비용이 높은 task이다.
이러한 부담을 줄이기 위해, 최근에는 생성형 모델의 발전과 함께 미디어/언터테인먼트 산업 전반에서 자동화된 콘텐츠 생성 기술을 적극적으로 도입하는 추세다.
특히 ‘어린이 노래’는 아동의 성장기에 중요한 역할을 수행하며, 이에 따라 동요에 특화된 영상에 대한 수요 역시 증가하고 있다.
그러나 어린이 노래를 위한 배경 애니메이션을 만드는 것은 꽤나 복잡한 과정인데,
- 고유한 언어적 의미와 정서적 요소를 시각적으로 해석해야 하고, 이를 생성 모델이 이해할 수 있는 프롬프트로 변환하는 과정은 어렵다.
- 또한 대부분의 Text-to-Video 모델들은 ‘범용적인 미디어’를 위해 설계되어 어린이 콘텐츠에 필요한 제어성, 의미적 정렬, 안정성이 부족한 상태이다.
특히 기존 방식은 텍스트를 입력하면 바로 비디오를 생성하는 end-to-end + black box(내부 동작 과정의 해석,제어가 어려운 모델) 구조로, 동요 같은 세부 도메인에 맞게 디테일하게 조정하는 것은 어렵다.
⇒ 따라서 본 논문에서는 “가사의 의미와 감정을 반영하면서, 어린이에게 적합하고 안전한 영상 콘텐츠를 생성하는 방법”을 제안한다.
2. Insight
End-to-end 구조에서→ 분리된 구조로 설계
기존의 text-to-video 모델들은 black box 구조로, 입력(텍스트)에서 출력(비디오)까지를 한 번에 생성하지만, 중간 과정(가사 해석, 장면 구성 등)을 확인하거나 제어하기는 어려웠다.
따라서 어린이 동요같은 도메인 특화 과정에서 어려움이 있었고, 부적절한 요소가 생성되더라도 그 원인을 추적하거나 수정하기가 어려웠다.
⇒ 복잡한 생성 문제(가사 → 영상)는 하나의 모델이 아니라, 의미적인 단위로 분해하는게 더 좋을 수 있다.
핵심 구성 요소: prompt 엔지니어링
일반적으로 생성형 모델에서 프롬프트는 단순한 입력으로 보지만, 본 논문에서는 프롬프트 자체를 모델 성능을 결정하는 핵심 요소로 본다.
특히 가사 + 스타일 + 장면 묘사를 어떻게 결합하느냐에 따라 생성 결과의 품질이 크게 달라진다는 것을 깨달았다.
⇒ 생성 결과의 품질을 좌우하는 것은 모델 자체보다 프롬프트를 얼마나 효과적으로 표현하는지에 있다.
완전한 video 생성에서 “효과 합성”으로 전환
기존 text-to-video 모델은 계산 비용이 크고 생성 결과가 불안정하며, 세밀한 제어가 어려웠다.
하지만 본 논문에서는 diffusiond으로 정적인 이미지를 생성한 뒤, 동적인 효과를 오버레이해서 비디오를 만드는 방식을 사용한다.
⇒ 복잡한 비디오 생성 작업 대신, “static 이미지 + dynamic 효과 오버레이”의 조합이 더 효율적이고 제어 가능성이 높다.
3. Method
Overall Architecture
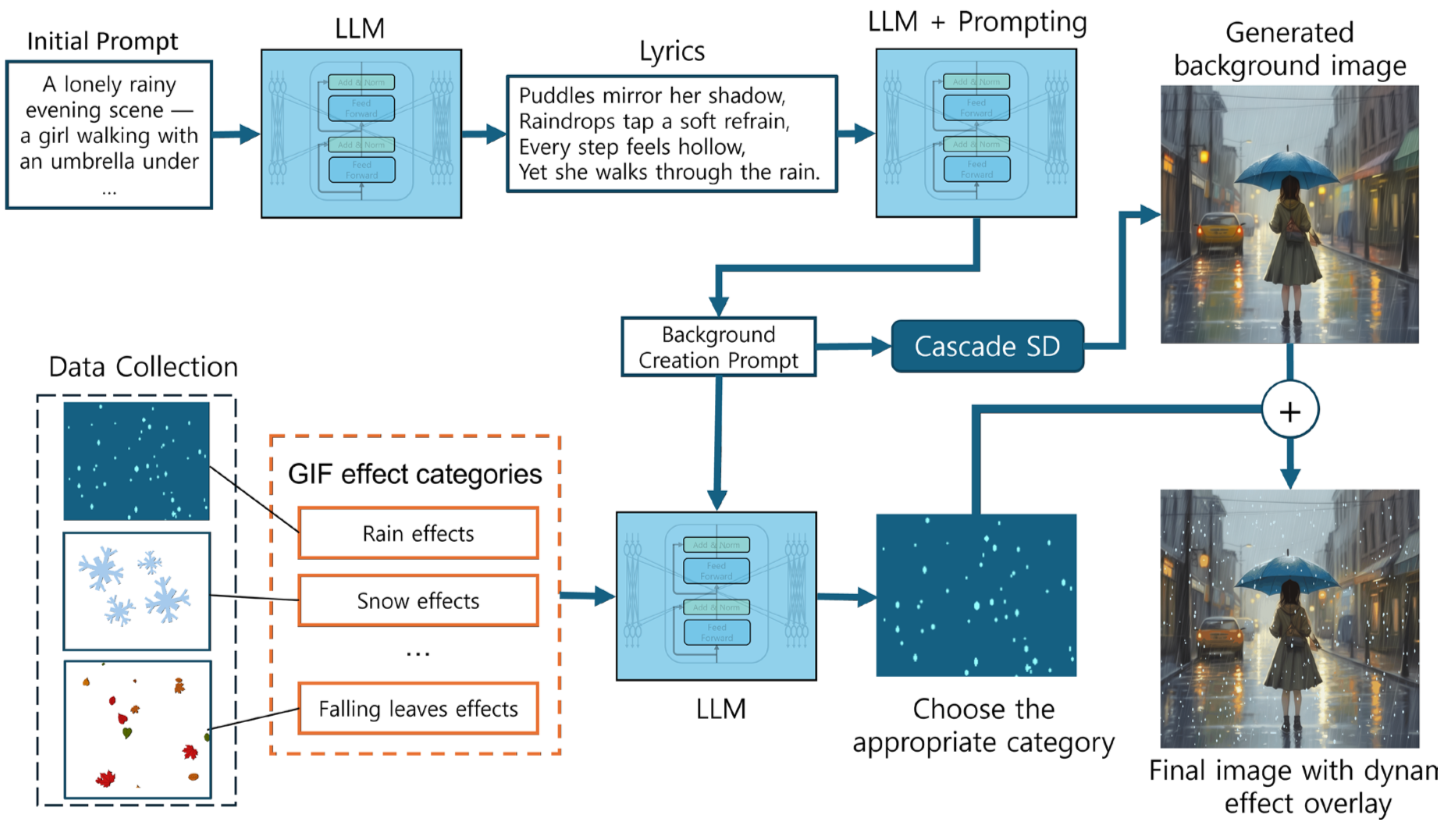
Pipeline 1: Lyrics Generation
첫 번째 단계에서는 LLM을 활용하여 동요 가사를 생성하거나 기존 가사를 기반으로 의미와 맥락을 구조화한다. 사용 모델로는,
- Pathwys Language Model / BERT / LLaMA (등 범용 LLM)
이러한 모델들은 대규모 corpus(말뭉치)로 학습되어 언어 이해 및 생성 능력이 뛰어나며, 이후 단계에서 사용할 장면 묘사, 감정 표현, 키워드 추출의 기반이 된다.
Pipeline 2: Cascade T2I Diffusion
T2I Diffusion 기반
가사로부터 생성된 프롬프트를 기반으로, T2I diffusion 모델을 사용해 배경 이미지를 생성한다.
diffusion의 핵심 원리를 복기하자면, 초기에는 랜덤 노이즈에서 시작해 점진적으로 노이즈를 제거하면서 텍스트 condition(프롬프트)에 맞는 이미지를 생성하는 과정이다. (diffusion에 대해 더 자세히 알고 싶다면 DDPM과 LDM 논문을 읽어보면 도움이 될 것이다!)
Prompt Engineering의 역할
일반적으로 T2I diffusion은 고품질의 이미지를 생성할 수 있지만, ‘동요’와 같은 특정 도메인에 적합한 스타일 제어는 어렵다.
따라서 본 논문에서는 가사에 특정 아트 스타일(cartoon, watercolor 등)이나 장면 키워드를 결합해서 동요에 적합한 이미지 생성을 유도한다.
본 논문은 여러 모델을 비교 후 CascadeSD를 채택했는데, 특징으로는
- 컴팩트한 semantic representation 기반의 모델이고
- 높은 이미지 품질을 유지하며
- GPU 오버헤드가 적고 빠른 추론 속도를 가지고 있다.
즉, 효율성 + 품질을 동시에 만족하는 모델로써 CascadeSD를 채택했다.
Pipeline 3: Overlay Effects
마지막 단계에서는 생성된 static 이미지에 낙엽, 꽃잎, 비, 눈, 반딧불이와 같은 애니메이션 효과를 오버레이하여 dynamic한 장면을 최종적으로 만든다. 이를 통해 시각적 몰입감을 높이고 가사 분위기를 강화시키는 효과를 얻을 수 있다.
효과 선택 역시 자동화되어 있으며, 선택 과정에서 LLM이 활용된다.
LLM 기반 효과 선택 과정
- 시각 효과를 주제별로 그룹화 (비, 눈 등)
- 프롬프트 + 효과 카테고리를 LLM에 입력
- LLM이 장면의 분위기를 분석
- 가장 적절한 효과 카테고리 선택
- 해당 그룹에서 랜덤 샘플링
- 선택된 효과를 이미지 위에 overlay
결과적으로 장면 맥락과 일관된 dynamic 효과를 자동으로 생성하고, LLM 기반의 가사 이해 + diffusion 기반의 이미지 생성 + 효과 기반의 애니메이션 합성이 결합되어,
⇒ 가사와 의미적으로 정렬된 시각적으로 풍부한 동요 애니메이션이 생성된다.
4. Experiment Analysis
1) Diffusion 모델 성능 비교 및 선택
본 논문에서는 이미지 생성 모델로 다양한 T2I 모델을 동일 조건에서 비교했다.
- CascadeSD, ReCo, TIME, T2I-CompBench, GlyphControl
이 중에서 CascadeSD가 CLIP Score, CLIP-IQA, TIFA 모든 지표에서 가장 안정적으로 높은 성능 달성했다.
특히 텍스트-이미지 정렬과 시각적 품질을 동시에 만족하는 균형 잡힌 결과를 보여준다.
2) Prompt Engineering의 효과
단순 가사만 입력하는 naive prompt에서는 이미지 품질 저하, 동요 스타일 반영 부족 문제가 발생한다.
스타일 키워드(cartoon, watercolor 등) 및 구조화된 프롬프트 적용 시, 이미지 품질 및 적합성이 크게 개선되었고, 특히 프롬프트 구조를 조정하여 glyph(불필요한 텍스트) 문제를 해결하였다.
⇒ 모델 성능뿐 아니라, 프롬프트 설계가 생성 품질을 결정하는 핵심 요소임을 실험적으로 확인할 수 있음
3) Text-to-Video 대비 Pipeline 접근의 효과
기존 T2V 모델(CogVideoX, WAN 등)과 비교 실험 수행한 결과, 제안 모델(BAGen)은 Text alignment, Background consistency, Aesthetic quality에서 우수한 성능을 달성했다.
이는 end-to-end video 생성보다 “이미지 생성 + 효과 합성” 방식이 더 높은 semantic alignment와 controllability를 제공함을 입증한다.
5. Significance of Paper
이 논문은 단순히 더 좋은 생성 모델을 만드는 것보다, 생성 과정을 어떻게 나누고 설계하느냐가 더 중요할 수 있다는 점을 보여준다. 기존 연구들은 보통 diffusion이나 text-to-video처럼 모델 자체의 성능을 높이는 데 집중했지만, 이 논문은 LLM, diffusion, 효과 합성으로 과정을 나누는 구조를 제안한다. 이런 방식으로 의미 정렬이나 결과 제어가 훨씬 쉬워지고, 문제가 생겼을 때 어느 단계에서 잘못됐는지도 파악할 수 있다. 즉, 복잡한 생성 문제일수록 하나의 모델에 맡기기보다는 단계별로 나눠서 해결하는 게 더 효과적이라는 것을 보여준다.
또한 이 논문은 생성형 AI를 실제로 활용할 수 있는 방향을 제시했다는 점에서도 의미가 있다. 기존 모델들은 일반적인 이미지나 영상 생성에는 강하지만, 어린이 콘텐츠처럼 의미 전달이나 안전성이 중요한 분야에서는 한계가 있었다. 반면 이 논문은 가사를 기반으로 의미를 해석하고, 그에 맞는 이미지를 만들고, 분위기에 맞는 효과까지 추가하는 방식으로 더 자연스럽고 적절한 결과를 만든다. 이런 접근은 단순한 연구 수준을 넘어서, 교육 콘텐츠나 실제 서비스에도 적용할 수 있는 가능성을 보여준다고 볼 수 있다.
