
페이징 기능
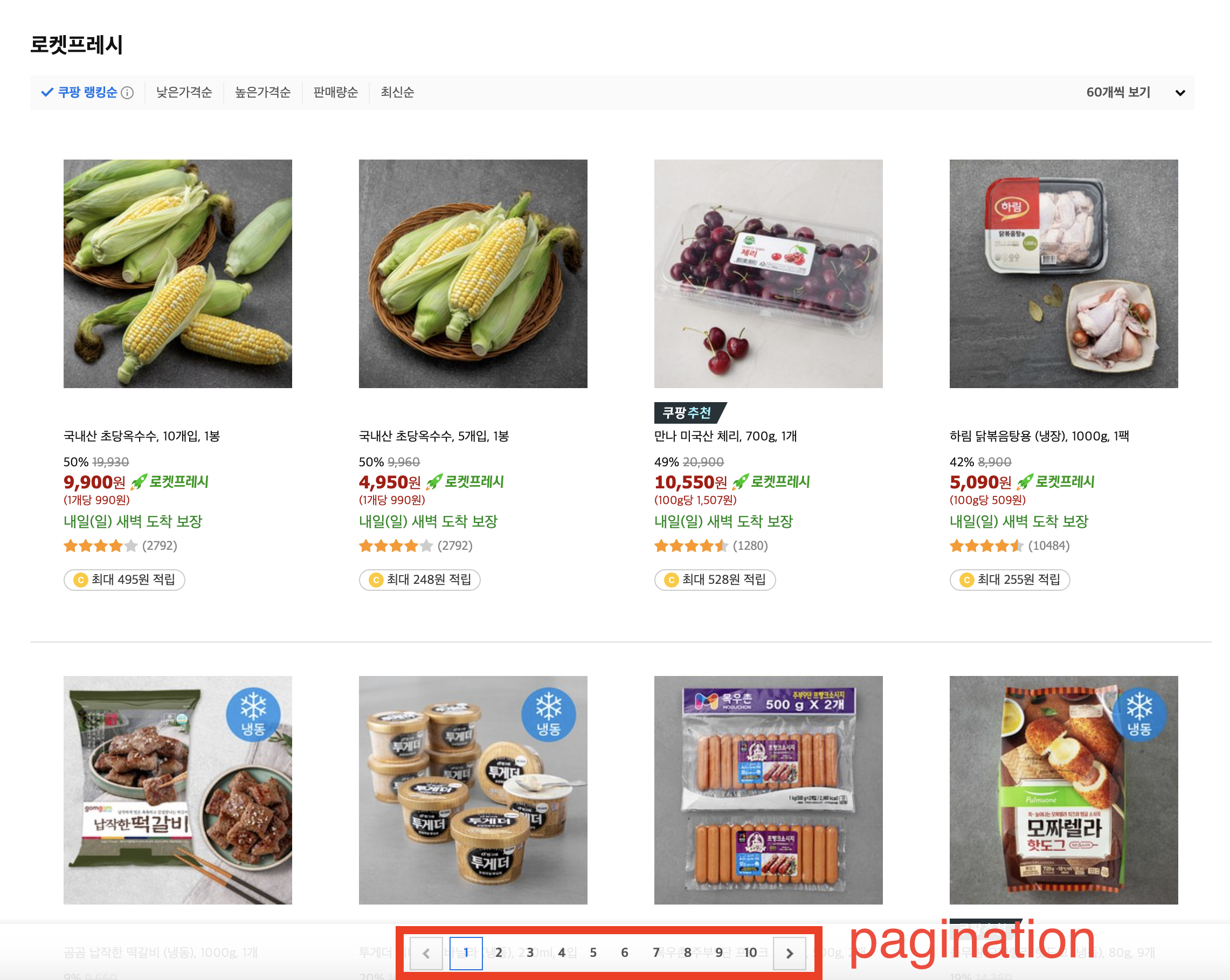
우리가 따라하고 있는 쿠팡에서는 페이징 기능이 있다!
그래서 상품 목록을 조회하는 API 에서 페이지 번호와 상품 개수를 함께 돌려줘야 하기 때문에
페이징 기능을 구현해보기로 했다 😀
어떻게 하면, 대용량 데이터에서도 빠르게 페이지 정보와 상품 정보를 가져올 수 있을까?
1. Offset 기반 페이징
- 가장 일반적인 페이징 방식으로서,
OFFSET과LIMIT을 이용한다. - 그러나, 이 방법에는 큰 문제점이 있다. 앞에서 읽었던 행을 다시 읽어야 하기 때문에 페이징 쿼리가 뒤로갈수록 느려진다. 뒤로 갈수록 버리지만 읽어야 할 행의 개수가 많아 점점 뒤로 갈수록 느려지는 것이다!

쿼리
SELECT *
FROM coupang.PRODUCT
WHERE is_rocket = 1
LIMIT 120
OFFSET 30000000;성능 테스트
- 전체 데이터
- 약 5천만개
- execution time
- 29 sec
- 실행 계획

2. JOIN 을 활용한 페이징
- 기본적으로 mysql 은 인덱스가 가르키는 row 에 접근하여 가져오는
Row lookup를 사용한다. - 그런데,
Inner Select문에서 최대한 인덱스로 검색해서 id 를 가져온 다음에JOIN하여Row lookup을 최대한 늦추는Late row lookup을 활용하면, 성능을 향상 시킬 수 있다.
쿼리
SELECT *
FROM coupang.PRODUCT as p
JOIN (
SELECT id
FROM coupang.PRODUCT
LIMIT 120
OFFSET 30000000
) AS t
ON p.id = t.id;성능 테스트
- 전체 데이터
- 약 5천만개
- execution time
- 9.408 sec
offest방식보다 약 70% 정도 성능이 향상되었다.- 그러나, 아직 너무 느리다!
- 실행 계획

3. Cursor 기반 페이징
Cursor기반 페이징 방식은 조회 시작 부분을 인덱스로 빠르게 찾아 매번 첫 페이지만 읽도록 하는 방식이다.- 아무리 페이지가 뒤로 가더라도 처음 페이지를 읽은 것과 동일한 성능을 가지게 되므로,
Offset방식보다 훨씬 성능이 개선된다. - 그러나, 이 방식은 원래 페이지 번호가 없고, 다음 페이지를 호출할 수 있는 키워드 등을 제공하는 페이징 기능이다. 아래와 같은 시스템 (흔히 SNS 게시물 조회 API에서 많이 볼 수 있다) 에서 사용한다.

- 즉,
직전 조회 결과의 마지막 ID를 넘겨서 다음 페이지를 조회하는 방식인 것이다.
SELECT *
FROM coupang.PRODUCT
WHERE id < 직전_조회_결과의_마지막_id
LIMIT 페이지 사이즈- 쿠팡에서는 아래처럼 페이지 네비게이터를 사용하기 때문에, 반드시 바로 다음 페이지를 요청할 것이라는 보장이 없다. 1번 페이지를 조회했다가도, 5번 페이지를 조회할 수 있어야 했다!

cursor방식은 성능 면에서 압도적이기 때문에 최대한 활용해보려고 노력했고,이전 페이지 목록 마지막 커서,현재 페이지 목록의 조회 커서 목록,다음 페이지 목록 시작 커서를 가져오는 방법 등을 생각했다. 하지만, 결국 모두 한계가 있어서 사용하기는 힘들었다.
쿼리
SELECT *
FROM coupang.PRODUCT
WHERE id >= 조회_시작점_id AND is_rocket = 1
LIMIT 120;성능 테스트
- 전체 데이터
- 약 5천만개
- execution time
- 0.035 sec
offest방식보다 약 80배 이상 성능이 향상되었다.- 커서 목록을 가져오는 쿼리의 오버헤드가 있겠지만, 그것을 감안해도 압도적인 성능이다!
- 실행 계획

4. 테이블의 분리
처음으로 돌아와서, "쿠팡에서는 어떻게 하고 있을까?" 추측해보기로 했다. 쿠팡 사이트를 탐색한 결과, 어떤 필터링 조건을 걸어도 항상 최대 17 페이지까지만 있는 것을 확인했다!
아마도 "모든 필터링 조건에 따라서 테이블을 분리해서 관리하는 대신, offset 방식으로 가져오는 게 아닐까?" 추측했다.
나중에 우리도 해당 방법으로 리팩토링을 시도해볼 생각이다!
기타
대용량 더미 데이터를 생성하는 방법
- 프로시저 : 일련의 쿼리를 마치 하나의 함수처럼 실행하기 위한 쿼리의 집합 - 참고
