
1. 파이썬 class
- 웹크롤링을 시작하기 위해서는 파이썬의 class의 개념을 알아야 한다.
- 프로그래밍 언어는 cpu, ram, ssd(hdd) 활용하기 위한 방법이다.
- 그 중 우린 파이썬 프로그래밍 언어를 사용했다.
파이썬에서 사용하는 것들
- 1) 변수선언: ram(메모리)를 사용하는 것
- 2) 데이터타입: ram 효율적 사용을 위한 int, float, bool, str, list 등이 있음 (숫자는 저장공간이 적게 필요, 문자는 저장공간이 많이 필요함)
- 3) 연산자: cpu를 사용함(산술, 비교, 논리, 할당, 멤머)
- 4) 조건문 반복문: 코드 작성의 효율을 높이는 방법 (if, elif, else, while, break, continue 등)
- 5) 함수: 반복되는 코드를 묶어서 코드 작성 실행 (def, return, argumentm parameter, docstring, lambda)
- 6) 클래스: 여러 개의 변수, 함수를 묶어서 코드 작성 실행하는 문법임
- 입출력: ssd(hdd) 저장장치를 사용 (pickle)
클래스 class
- 변수, 함수를 묶어서 코드 작성 및 실행하는 방법
- 객체지향을 구현한 문법임: (사전적의미) 실제 세계를 모델링하여 개발하는 방법론 (협업을 용이하게 하기 위해서 사용)
- 함수 사용법: 함수 선언(코드 작성) > 함수 호출(코드실행)
- 클래스 사용법
- 클래스선언(코드작성)> 객체생성(메모리사용) > 메서드(함수)호출 (코드실행)
- 클래스선언(설계도작성) > 객체생성(제품생산) > 메서드호출(제품사용)
# 클래스 선언: 코드작성
# 은행계좌 설계: Account-클래스 : balance(예금잔고)-변수,
# deposit()입금-함수,
# withdraw() 출금-함수
class Account:
balance = 10000
def deposit(self, amount):
self.balance += amount
def withdraw(self, amount):
self.balance -= amount
# 객체생성 (메모리 사용)
acc1 = Account()
acc2 = Account()
# acc2의 balance 변수 값 변경
acc2.balance = 6000
acc1.balance, acc2.balance
>
(10000, 6000)
# 메서드호출: 코드실행
acc1.deposit(2000) # 1번 계좌 입금
acc2.withdraw(3000) # 2번 계좌 출금
acc1.balance, acc2.balance # 계좌 조회
>
(12000, 3000)dir()
- 객체에 들어있는 변수(함수) 출력
dir(acc1) # 객체에 들어있는(사용할 수 있는) 함수 확인
dir(acc1)[-3:] # 세개만 출력생성자메서드 init
# 클래스 선언: 코드작성
class Account:
# def __init__(self, balance): # 메서드에서 사용되는 변수의 초기값을 설정하거나 검사할때 사용이 된다.
# self.balance = balance
def deposit(self, amount):
self.balance += amount
def withdraw(self, amount):
self.balance -= amount# 객체생성: 메모리 사용: 자원 사용
acc = Account()
# 메서드호출: 코드실행
acc.deposit(1000) # 실행 시 오류남 이유는 balance를 선언하지 않고 진행함- 이처럼 클래스를 선언하고, 메서드를 호출하면 오류가 발생한다.
- 그 이유는 처음 balance라는 변수를 선언하지 않고 진행했기 때문이다.
- 그리고 앞에선 오류가 발생했지만 뒤늦게 발견하여 어려움을 겪을 수 있다.
- 이를 해결하기 위해선 def __init__ 메서드를 사용하는 것이다.
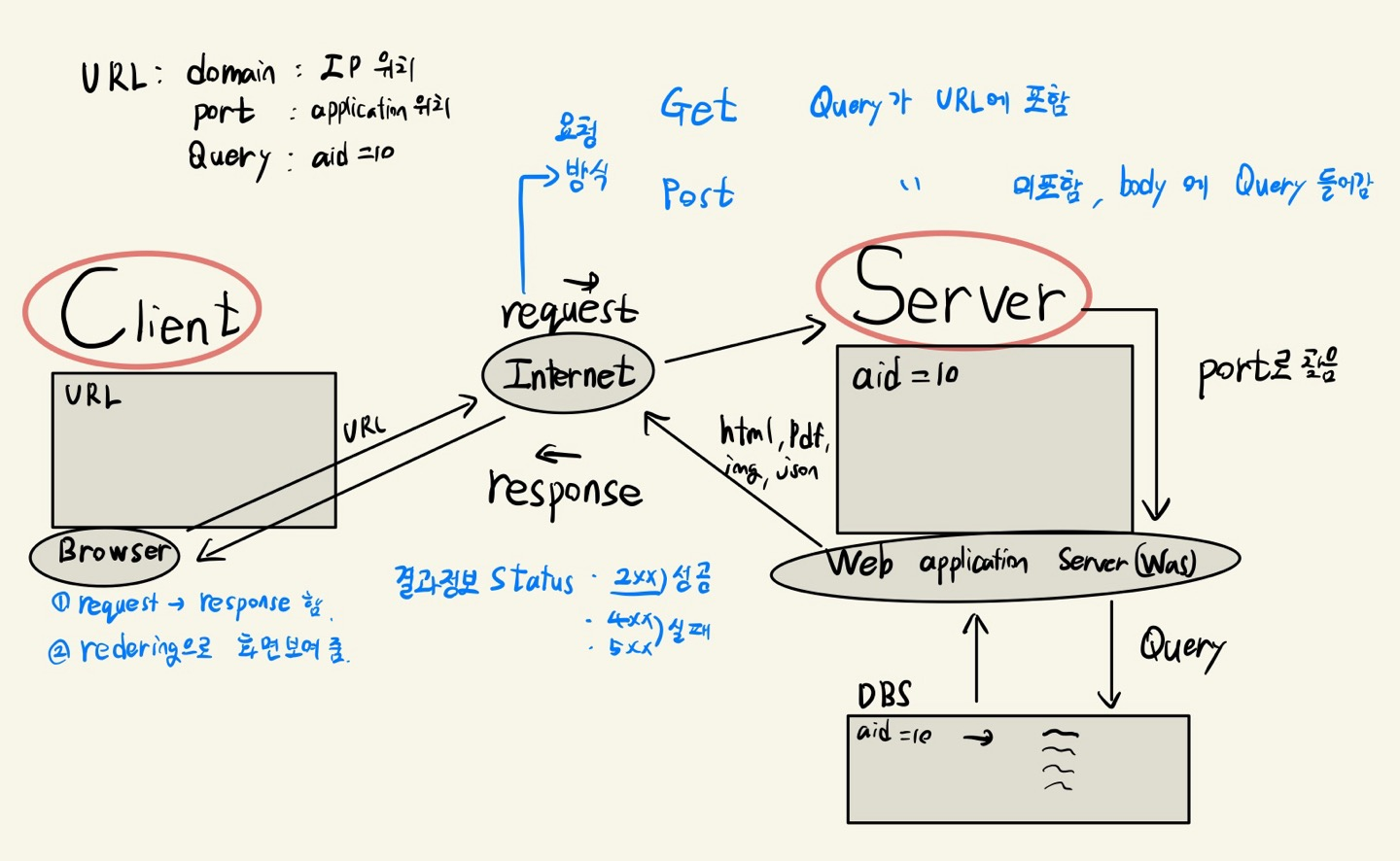
2. Web
(1) 웹 구조
- Client
- request: Browser를 사용하여 Server에 데이터 요청
- Server
- response: 요청에 따라 Client로 전송
(2) URL
- 브라우저에서 Client가 URL을 입력하면 Web Server에서 받는다.
http://news.naver.com:80/main.read.nhn?mode=LSD&mid=shm&sid1=105&oid=001&aid=000984721#da_727145
- http:// - 프로토콜 규칙
- https 는 보안이 조금 더 높다.
- news - 서브 도메인
- naver.com - 주 도메인
- 80 - Port로 Client의 브라우저에서 URL을 통해 요청하여 IP로 Server를 찾지만, 그 안의 application을 찾을 때 사용하여 접속
- /main/ - Path로 Server 컴퓨터의 파일의 경로
- read.nhn - Page로 파일 접근에 사용
- mode=LSD - Query 키와 벨류로 application에서 뭐리를 통해 찾는 것
- #da_727145 - Fragment로 웹페이지에서 클릭했을때 이동할 수 있는 것이다.
(3) request
Get
- request의 방식으로 URL에 Query가 포함된다.
- Query(데이터)는 노출 된다. (노출해도 상관없는 경우 사용)
- Query에 저장하여 전송가능 데이터가 작다.
Post
- request의 방식으로 Body에 Query가 포함된다.
- Query(데이터)가 노출되지 않는다.
- 메모리에 저장하여 전송가능 데이터가 많다.
(4) Status code
- Client와 Server가 데이터를 주고 받은 결과의 정보이다.
# Get
response = requests.get(url)
response
# Post
response = requests.post(url)
response
><Response [200]>- 위 처럼 사용하고 결과 값이
- 2xx 성공
- 4xx 실패
- 5xx 실패
- 라고 생각하면 된다. 위 그림은 200으로 성공이다.
(5) Cookie, Session, Cache
1) Cookie
- Client의 브라우저에 저장하는 문자열 데이터로 ssd(hdd)에 저장한다.
- 로그인 정보, 내가봤던 상품 정보, 팝업 다시보지 않음 등에 사용
2) Session
- Client의 브라우저와 Server의 연결정보이다.
- 자동 로그인이 대표적인 예시이다.
3) Cache
- Client Server의 Ram(메모리)에 저장하는 데이터이다.
- Ram에 데이터를 저장하면 데이터 입출력이 빠르다.
예시
만약 어느 신문사에서 기사를 Client가 작성을하고 Server에 저장시킨다.
일자별 사람이 클릭하는 비율은 D-1(100%)이면 D-2(20%), D-3(1%)로 차이가 난다.
Server를 효율적으로 관리하기 위해서 D-1의 기사는 처리 속도가 빠르고 가격이 비싼 Ram에 저장한다.
반대로 D-2, D-3 .... 의 기사는 처리 속도가 느리고 가격이 싼 ssd에 저장한다.
(6) Scraping & Crawling
- 스크랩핑: 특정 데이터를 수집하는 작업
- 크롤링: 웹서비스의 여러 페이지를 이동하며 데이터를 수집하는 작업
3. 웹 크롤링(Web Crawling)
웹피이지의 종류
- 정적인 페이지: 웹브라우저 화면이 뜨면 이벤트에 의한 화면 변경이 없는 페이지
- URL 변경이 있음
- html 문자열로 받아서 파싱
- 동적인 페이지: 웹브라우저 화면이 뜨고 이벤트가 발생하면 서버에서 데이터를 가져와 화면을 변경하는 페이지
- URL 변경이 없음
- json 문자열로 받아서 파싱
- selenium: 브라우저를 직접 열어서 데이터를 받음 (어뷰징의 경우 사용)
- 크롤링 속도는 requests json > requests html > selenium
- 웹 크롤링을 그림으로 나타냄
(1) requests 이용
네이버 증권 사이트에서 주가 데이터 수집 예시
import warnings
warnings.filterwarnings('ignore') # 경고 문구 출력 x
import pandas as pd # 데이터를 수집 후 엑셀이나 csv파일로 저장하기 위해 불러옴
import requests # 브라우져에서 받아오기 위한 것1) URL 수집
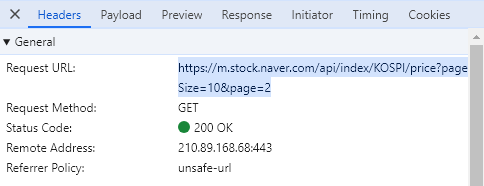
page_size, page = 60, 1
# 최신정보
url = f'https://m.stock.naver.com/api/index/KOSPI/price?pageSize={page_size}&page={page}'
# 기존 URL
# url = 'https://m.stock.naver.com/api/index/KOSPI/price?pageSize=10&page=2'2) 서버에 데이터 요청
# get 방식
response = requests.get(url)
>
<Response [200]>
# 객체안에 저장되어있는 택스트 변수 출력, 200 글자만 출력
response.text[:200] # datatype = str
>
'[{"localTradedAt":"2024-03-07","closePrice":"2,647.62","compareToPreviousClosePrice":"6.13","compareToPreviousPrice":{"code":"2","text":"상승","name":"RISING"},"fluctuationsRatio":"0.23","openPrice":"2,'3) 서버에서 받은 데이터 파싱
# str > list, dict
data = response.json()
# list, dict > DataFrame
df = pd.DataFrame(data)
columns = ['localTradedAt', 'closePrice']
df = df[columns]4) 함수로 만들기
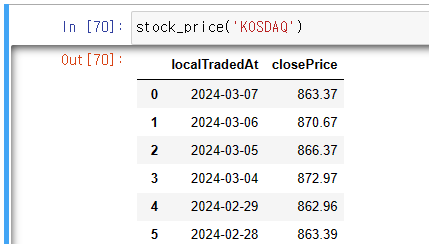
# KOSPI, KOSDAQ 입력시 유동적으로 나옴
def stock_price(code= 'KOSPI', page_size=60, page=1):
# 1. 웹서비스 분석: URL
url = f'https://m.stock.naver.com/api/index/{code}/price?pageSize={page_size}&page={page}'
# 2. request(URL) > response(Json) : Json(str)
response = requests.get(url)
# 3. Json(str) > list,dict > DataFrame: Data
columns = ["localTradedAt", "closePrice"]
return pd.DataFrame(response.json())[['localTradedAt', 'closePrice']]- 최종적으로 얻은 데이터 프레임
(2) headers(User-Agent, Referer)
- Daum 사이트가 어뷰징을 이용하는 사용자들 때문에 403으로 막아놓았음
# 필요 라이브러리
import warnings
warnings.filterwarnings('ignore')
import pandas as pd
import requests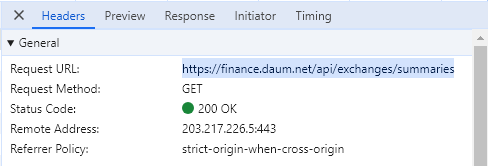
- requests 했지만 403 나옴
# 1. URL
url = 'https://finance.daum.net/api/exchanges/summaries'
# 2. request > response : json(str)
response = requests.get(url, headers = headers)
response
>
<Response [403]>-
이를 해결하는 방법은
- headers를 설정을 통해 User-Agent 추가
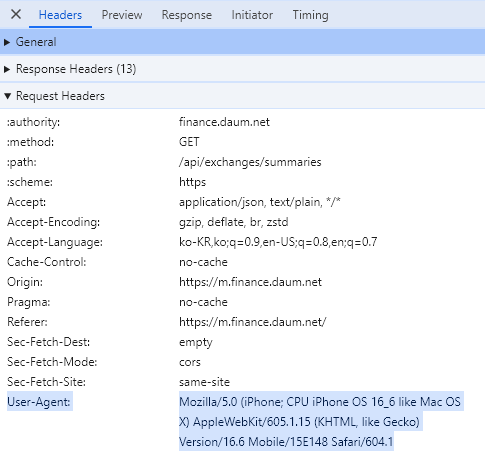
- 그래도 403 오류가 난다면 Referer 추가
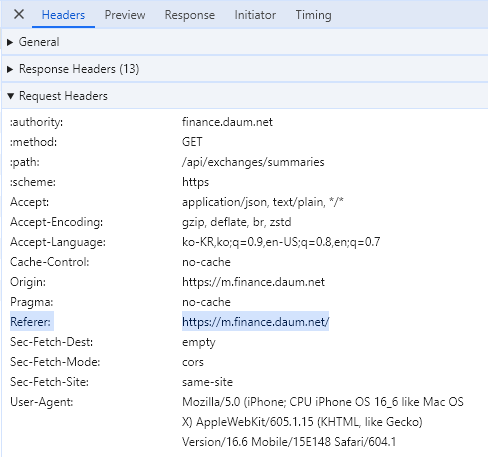
- headers를 설정을 통해 User-Agent 추가
# 1. URL
url = 'https://finance.daum.net/api/exchanges/summaries'
# header 설정
headers = {
'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36',
'Referer' : 'https://m.finance.daum.net/',
}
# 2. request > response : json(str)
response = requests.get(url, headers = headers)
# 3. json(str) > list, dict: DataFrame
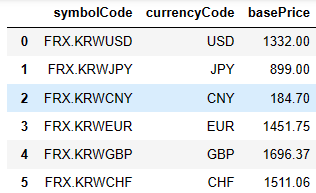
data = response.json()['data']
df = pd.DataFrame(data)[['symbolCode', 'currencyCode', 'basePrice']]- 최종적으로 이 데이터프레임을 얻을 수 있음
(3) REST API (Kakao API)
- Client와 Server가 통신하기 위한 URL 구조에 대한 정의와 디자인이다.
- 카카오 API를 활용함
- 기업에서 제공하는 API를 활용해 데이터를 쓸 수 있음
- 로그인 필요
1) 애플리케이션을 추가 (request토큰 얻기)
# 라이브러리
import warnings
warnings.filterwarnings('ignore')
import pandas as pd
import requests, json
KT라는 이름으로 애플리케이션 추가함
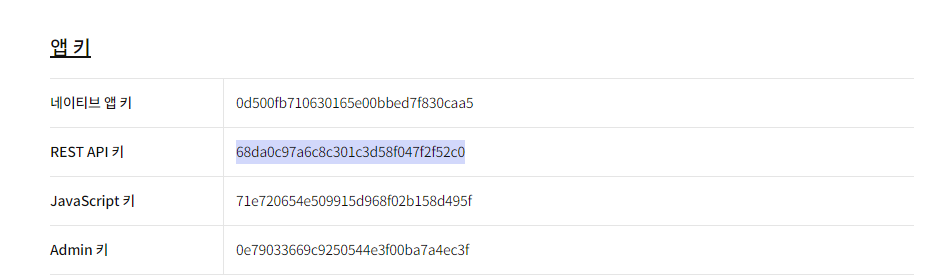
2) key 값 받기
REST API 키 받아옴
# key 값 받기
REST_API_KEY = '68da0c97a6c8c301c3d58f047f2f52c0'3) 문서 > koGPT > KoGPT URL 확인
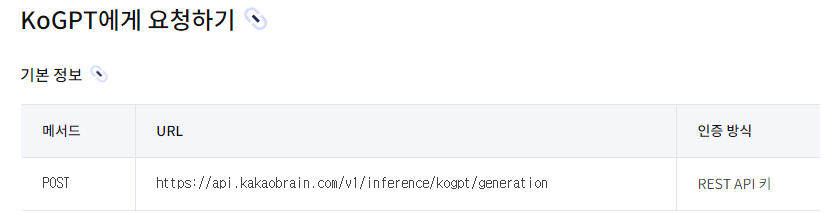
# 1. document : URL
url = 'https://api.kakaobrain.com/v1/inference/kogpt/generation'4) koGPT 사용
# 2. request(URL: headers, params) > response : json(str)
prompt = '원자폭탄을 개발한 사람은'
params = {'prompt': prompt, 'max_tokens': 50, 'n':2}
headers = {'Authorization' : f'KakaoAK {REST_API_KEY}',
'Content-Type' : 'application/json'
}
# json.dumps(): 문자열 인코딩: 한글>영문, 특수문자로 인코딩
response = requests.post(url, json.dumps(params), headers=headers)
response
>
<Response [200]>
# 3. json(str) > parsing: text
texts = response.json()['generations']
texts = [text['text'] for text in texts]
texts[' 누구? Heinrich Hertz 독일의 과학자. \u200b 원자탄과 그 이용이 세계에 야기할,,곧 나타나겠습니다 줄지어 있는 사망자를 바라 본 사람들은 점점 고개를 젓기시작했다. 그리고 이',
" 누구입니까? 오펜하이머라는 과학자입니다. '파퓰러사이언스'지 1996년 11월판에 기재된 저자 소개글에서, 생물학자이기도 한 필자는 가상의 [오펜하이머의 최후의 날]이라는 풍자 글 중"]
이런식으로 출력이 된다.
카카오도 생성형AI가 있는 것을 처음 알았다.
근데 문장만들고, 요약하기 예제 문제를 풀어봤더니 우리가 카카오톡에서 많이 사용하는 단어를 쓰는 것 같았다.

이걸보면 chatGPT와는 좀 다르게 뭔가 인공지능이 하는 말이 아닌 것 같다.
회고
웹 크롤링... 내가 타교육 시험칠때, 배웠던 내용 중 하나다.
그땐, 아무것도 모르는 나에게 그냥 교육자료를 던져주고 2주동안 공부해서 웹페이지를 만들어라. 이런 내용의 시험이었다.
그걸 준비하면서 웹크롤링을 처음 접했는데, 크롤링에 대해 1도 이해를 못했고 단어만 익숙하다ㅋㅋㅋㅋ
하지만 이번에 Web Crawling이 어떤 건지 그 내부엔 어떤 기능을 어떻게 사용하는지 알 수 있는 기회였다.
갑자기 든 생각인데 크롤링으로 돈 버는사람 부럽다 나두,,,할뤠
