AWS 주요 리소스 모니터링 & 비용
-
CPU 계산 연산
- CPUUtilization
- CPUCreditBalance
- CPUCreditUsage
-
Data 저장
- DiskReadBytes
- DiskWriteBytes
- DiskWriteOps
-
통신
- NetworkOut
- NetworkIn
-
상태
- StatusCheckFailed-Instance
- StatusCheckFailed-System
모니터링 메트릭
(1) 사용자 지정 메트릭
- 기본 메트릭 이외에 사용자 지정 메트릭 수집 가능
- ex) 메모리 생성 기능
(2) EC2 모니터링 주요 메트릭
- CPUUtilization: 현재 인스턴스에 사용하고 있는 컴퓨팅 파워
- CPUCreditUsage: 특정 기간 동안 사용된 CPU 크레딧 갯수 (소진시 비용 발생함)
- DiskReadOps: 인스턴스에 연결된 로컬디스크에서 읽어 들인 오퍼레이션의 수
- Network Out Traffic: 인스턴스의 네트워크 인터페이스를 통해 나간 바이트 양
- Status Check
- System status check (재배포를 통한 개입 가능)
- 네트워크 연결이 잘되는지
- 시스템 파워 구동이 잘되는지
- 물리 서비 이슈가 있는지
- Instance status check
- 잘못된 네트워킹 또는 시작 구성이 잘되었는지
- 메모리 부족한지
- 파일 시스템 손상이 있는지
- System status check (재배포를 통한 개입 가능)
(3) EBS 모니터링 주요 메트릭
-
VOLUMEIDELTIME: 지정된 기간 에서 읽기 또는 쓰기 작업이 없는 총 시간
=> 즉, 볼륨이 놀고 있는 시간으로 비용 최적화를 위한 볼륨 제거에 참고함 -
VOLUMEQUEUELENGTH: 디바이스에서 보류 중인 I/O 요청의 수
=> 많은 양을 받아서 초과 시 대기열에 대기하는 방식임 -
BURSTABALANCE: 볼륨에 대한 버스트 버킷의 크레딧의 백분율
-
EBS volumes 모니터링 옵션
- 기본 5분 주기 수집
- 상세 1분 주기 수집
-
Status Check
- OK (정상)
- Warning (성능저하)
- Impaired (중단됨, I/O 비활성화)
- Insufficient-data
(4) ELB 모니터링 주요 메트릭
-
Backend Connection Error
- ELB와 인스턴스 간에 커넥션이 맺어지지 않은 숫자
-
Latency
- 외부 요청을 받아 타겟 그룹을 전달한 ELBrk EC2 인스턴스로부터 응답을 받을 때 까지의 지연시간
-
Surge Queue Length
- 로드밸러서에서 라우팅이 지연되고 있는 총 요청의 수
대기열의 개념
- 로드밸러서에서 라우팅이 지연되고 있는 총 요청의 수
-
Spill Over Count
- 거부된 요청 값으로 0 초과 되는 경우 조치를 권장함
-
Request Count
- ElB에서 수신한 요청 수
-
Healthy Host Count
- 정상 서버 수
-
HTTP Responses
- 5xx: 서버 오류나 예외적인 동작 발생시
- 4xx: 잘못된 요청 또는 파일 찾을 수 없을시
- 2xx: 정상
(5) ECS 모니터링 주요 메트릭
- ECS 시작 유형 별 메트릭: Fargate 시작 유형(CPU, 메모리 사용률 제공), Amazon EC2 시작 유형
- 컨테이너에 가능한 healthStatus
- HEALTHY: 상태 확인 통과
- UNHEALTHY: 상태확인 실패
- UNKNOWN: 상태 확인이 평가 중이거나 정의되지 않은 상태
(6) EKS 모니터링
- 로깅 및 모니터링을 위한 기본 제공 도구를 제공함
- CloudWatch Container Insights 기반: 클러스터, 노드, 포드, 서비스 수준에서 Amazon EKS에 대한 포괄적인 메트릭 제공
- Amazon Devops Grur 기반: 노드 수준의 운영 성능 및 가용성 감지
- Prometheus 기반
비용
(1) Billing and Cost Management
- 잘못 사용시 막대한 비용 발생 가능
- 매달 PDF invoice 메일 전송 가능
- 비용 관련 경보 설정 가능
- 비용 보고서를 S3 Bucket에 저장 가능
(2) 비용 이상 탐지
- 'Cost Anomaly Detection 활성시 기계 학습 알고리즘 적용
- 이상 탐지를 위한 모니터링
- 이상 지출이 탐지 되면 알림 수신
- 비용 및 사용 급증의 근본 원인 식별함
AWS Cost Explorer
- 시간에 따른 AWS 비용과 사용량을 시각화하는 인터페이스 제공
- 비용 및 사용량 데이터를 분석하는 사용자 지정 보고서 작성
- 계정에 연결된 요금과 사용량을 검토
AWS Budgets
- 비용 및 사용량 모니터링
- 예약 보고서 생성
- 임계값 도달 시 작업 실행
AWS Cost Explorer / AWS Budgets 비교
- Cost Explorer
- 비용 사용 관련 사용자 지정 보고서
- 비용 시각화, 분석 중점
- 사용 패턴 파악
- AWS Budgets
- 제한 임계값 초과 비용 발생 방지
- 비용 계획, 예측 집행 중점
- 예산과 지출 비교
쿠버네티스 개요 및 주요 아키텍쳐
컨테이너
- 애플리케이션과 그 실행 환경을 패키징하여 어디서나 일관되게 실행할 수 있게 해주느 가벼운 가상화 기술
- 쿠버네티스는 이 컨테이너들을 자동으로 배포, 확장, 관리하는 오픈소스 플랫폼임
가상머신 vs 컨테이너
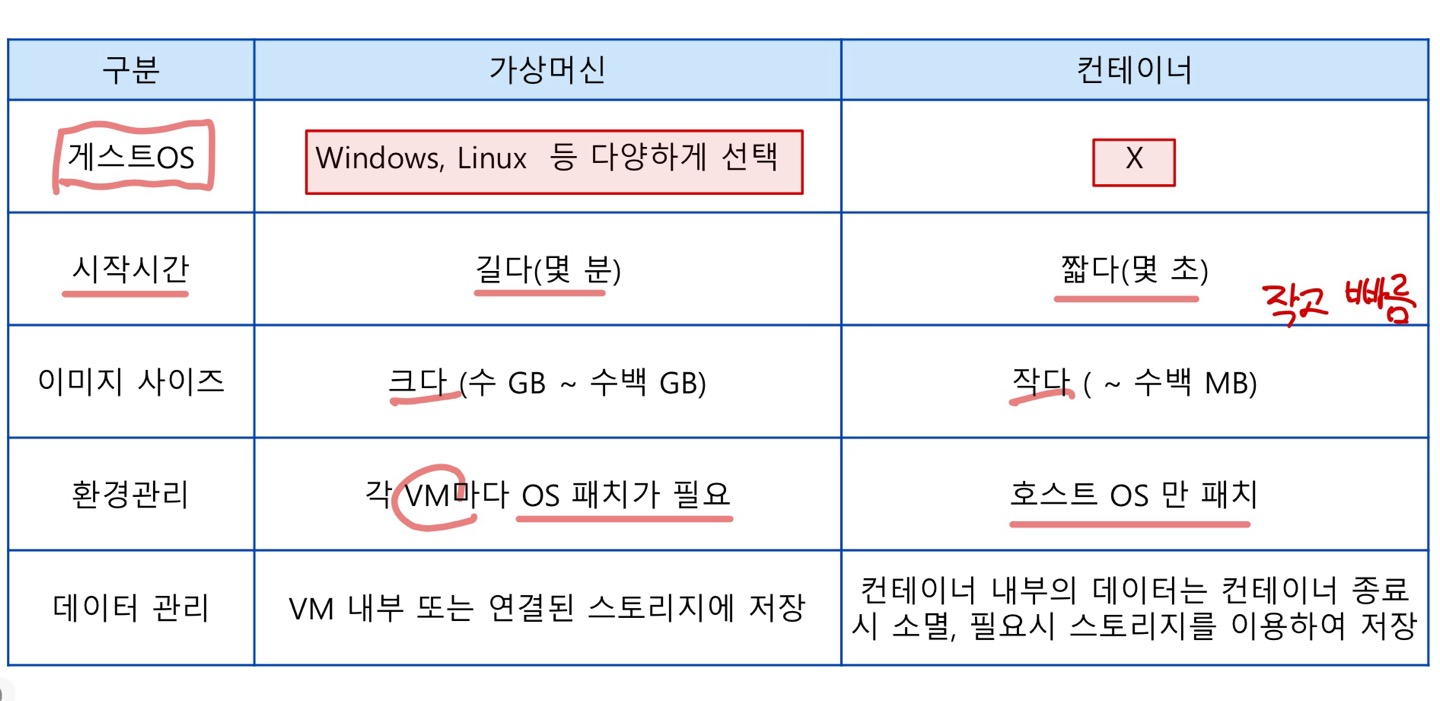
Monolithic vs MicroService
- Monolithic 아키텍처 (MA)
- 고용량 단일 서버로 구성
- 모든 기능이 하나의 애플리케이션으로 결합
- 각 부분이 강하게 결합되어 있어, 하나의 부분에 문제가 생기면 전체 애플리케이션에 영향을 미칠 수 있음
- MicroService 아키텍처 (MSA)
- 작은 서버들의 집합체로 구성
- 각 기능이 독립적인 서비스로 나누어짐
- 서비스의 문제가 다른 서비스에 영향이 적음
=> 쿠버네티스가 주로 이루어진 형태
Docker
- 컨에티너 기술을 만들고 발표한 회사
- 컨테이너 엔진으로 컨테이너를 실행하고 관리하는 도구
- 컨테이너 기반 오픈소스 가상화 플랫폼
Dockerfile
- 컨테이너 이미지를 생성하기 위한 레시피 파일
- 파일에 이미지 생성과정을 문법에 따라 작성하여 저장함
- 명령어: FROM, WORKDIR, RUN, CMD
Docker Image
- 서비스 운영에 필요한 프로그램, 소스코드, 라이브러리 등을 묶는 형태
- Build: 도커 이미지는 Dockerfile을 사용하여 커스텀 생성
- Run: 도커 이미지를 사용하여 다수의 Container 실행
docker build -t <Namespace>/<ImageName>:<tag> ex) - 모두 같은 명령임 docker.io/library/nginx:latest < >nginx:latest => DH(도커허브) 주소 생략 가능 < >nginx( ) => 버전 생략가능
-
Docker Private Image: Private 이미지저장소를 구축, 이미지 관리시 Namespace 안에 서버주소 및 포트번호를 사용함
-
Docker HUB: 컨테이너 이미지들을 서버에 저장하고 관리, 공개 이미지를 무료로 관리
Docker 명령 구조

컨테이너 오케스트레이션
- 다수의 컨테이너를 다수의 시스템에서 각각의 목적에 따라 배포, 복제, 장애복구 등 활동을 총괄적으로 관리함
일반적기능
- 스케줄링
- 자동확장 및 축소로 리소스 효율적 사용 관리
- 장애복구로 서버 정상 운영
- 로깅 및 모니터링으로 장애복구 등 수행
- 검색 및 통신으로 요청을 통해 전달함
- 업데이트 및 롤백으로 기능 추가 디버깅 등 수행
컨테이너 오케스트레이터
컨테이너 오케스트레이션을 해주는 도구
ex)
- Kubernetes (표준처럼 사용함)
- Docker Swarm
- AWS ECS
- Azure Container Instance
- Azure Service Fabric
Kubernetes
-
k8s
-
컨테이너형 애플리케이션의 배포, 확장, 관리를 자동화하는 오픈소스시스템
-
높은 확장성과 원활한 이동성
-
여러 환경에 구축 가능
-
오픈 소스 도구
-
플러그가 가능한 모듈 형식
쿠버네티스 아키텍쳐
Master Node
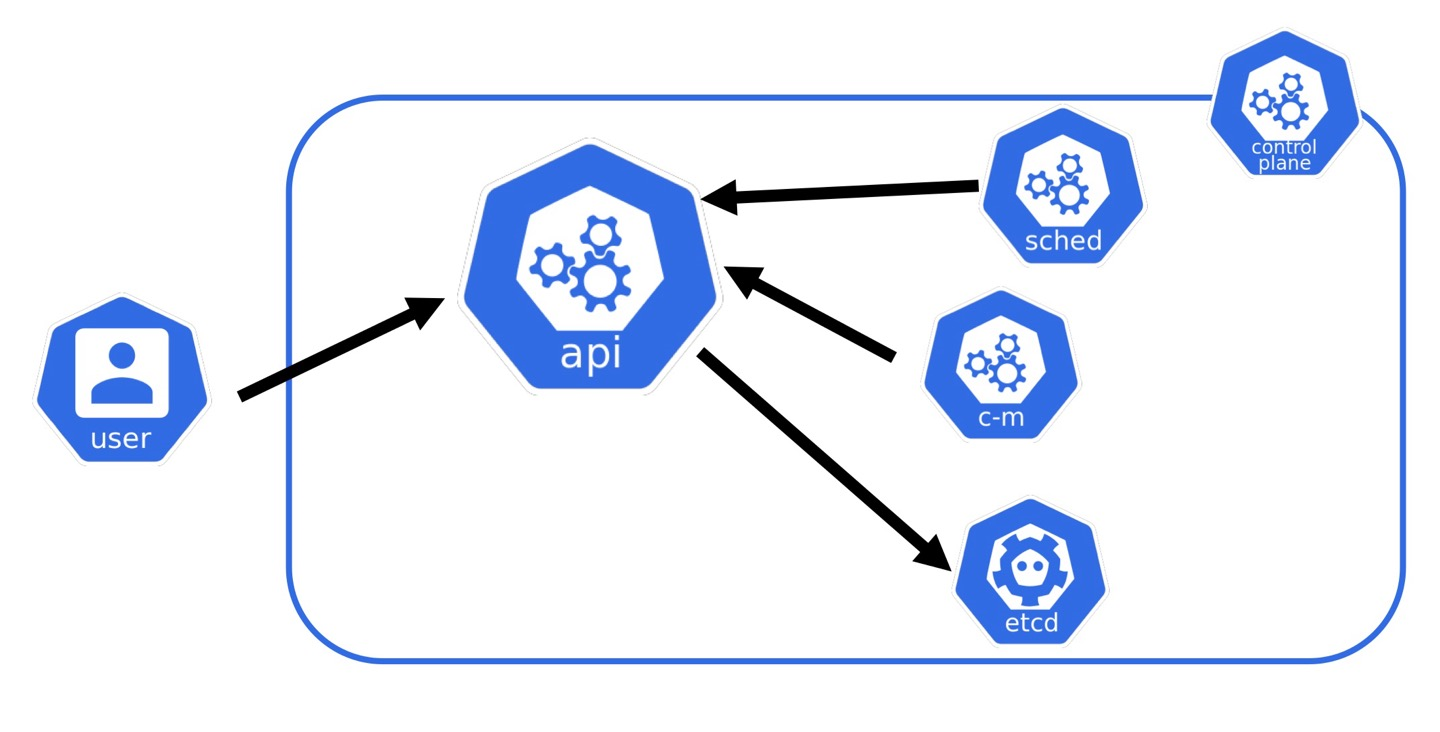
-
API: User에서 명령을 수용할지 요청을 검증하고 필요한 컴포넌트들에게 전달하는 중간다리 역할을 함
-
sched: 명령을 어디에 배포할지 어떤 Node에 설지할지 결정만 함
ex) 1번 Node - 3개, 2번 Node - 1개, 3번 Node - 1개 -
Controller Manager: 클러스터의 상태를 원하는 상태로 유지하기 위해 다양한 컨트롤러들을 실행하는 역할
-
etcd: 쿠버네티스에서 중요한 데이터를 저장하는 고가용성 키-값 저장소로 쿠버네티스 클러스터의 두뇌 역할을 함
Worker Node
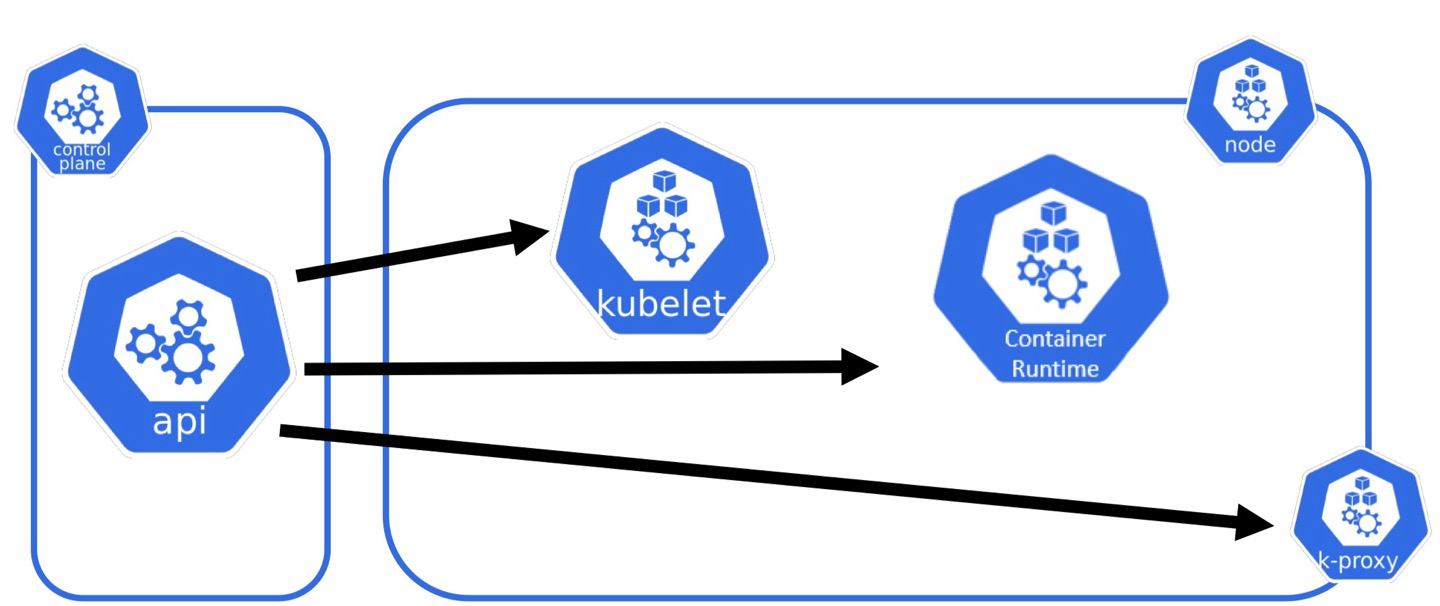
-
Container Runtime: 컨테이너를 실행하고 노드에서 컨테이너 이미지를 관리함
-
Kubelet: 컨테이너의 실행 상태를 모니터링하며 상태 정보를 마스터 노드에 보고하는 에이전트 (팀장 역할임)
-
Kube-proxy: 네트워킹을 담당하는 컴포넌트로 주 역할은 네트워크 규칙을 관리하여 클러스터 내의 서비스 간 통신을 가능하게 함
Addons
- 쿠버네티스에서 추가적으로 설치하여 기능을 확장 시킬 수 있는 도구
쿠버네티스 클러스터 배포
쿠버네티스 배포 유형
All-in-One Single-Node Installation
- 모든 쿠버네티스 컴포넌트가 하나의 노드에서 실행된다.
- 설치와 관리가 간편하며 테스트 환경에 적합함
- 단일 장애 지점으로 인해 신뢰성이 낮음
Single-Node etcd, Single-Master and Multi-Worker Installation
- 하나의 노드에 etcd와 마스터 컴포넌트를 설치하고 여러 워커노드를 둔다.
- 간단한 설정으로 더 나은 성능과 확장성을 제공함
- etcd와 마스터 노드의 단일 장애 지점이 존재
Single-Node etcd, Multi-Master and Multi-Worker Installation
- 하나의 노드에 etcd를 설치하고, 여러 마스터와 워커 노드를 둔다.
- 마스터 노드의 고가용성을 제공하여 신뢰성을 높임
- etcd의 단일 장애 지점이 존재
Multi-Node etcd, Multi-Master and Multi-Worker Installation
- 여러 노드에 걸쳐 etcd, 마스터, 워커 컴포넌트를 분산하여 설치한다.
- 최고 수준의 고가용성과 신뢰성을 제공함
- 설치와 관리가 가장 복잡함
